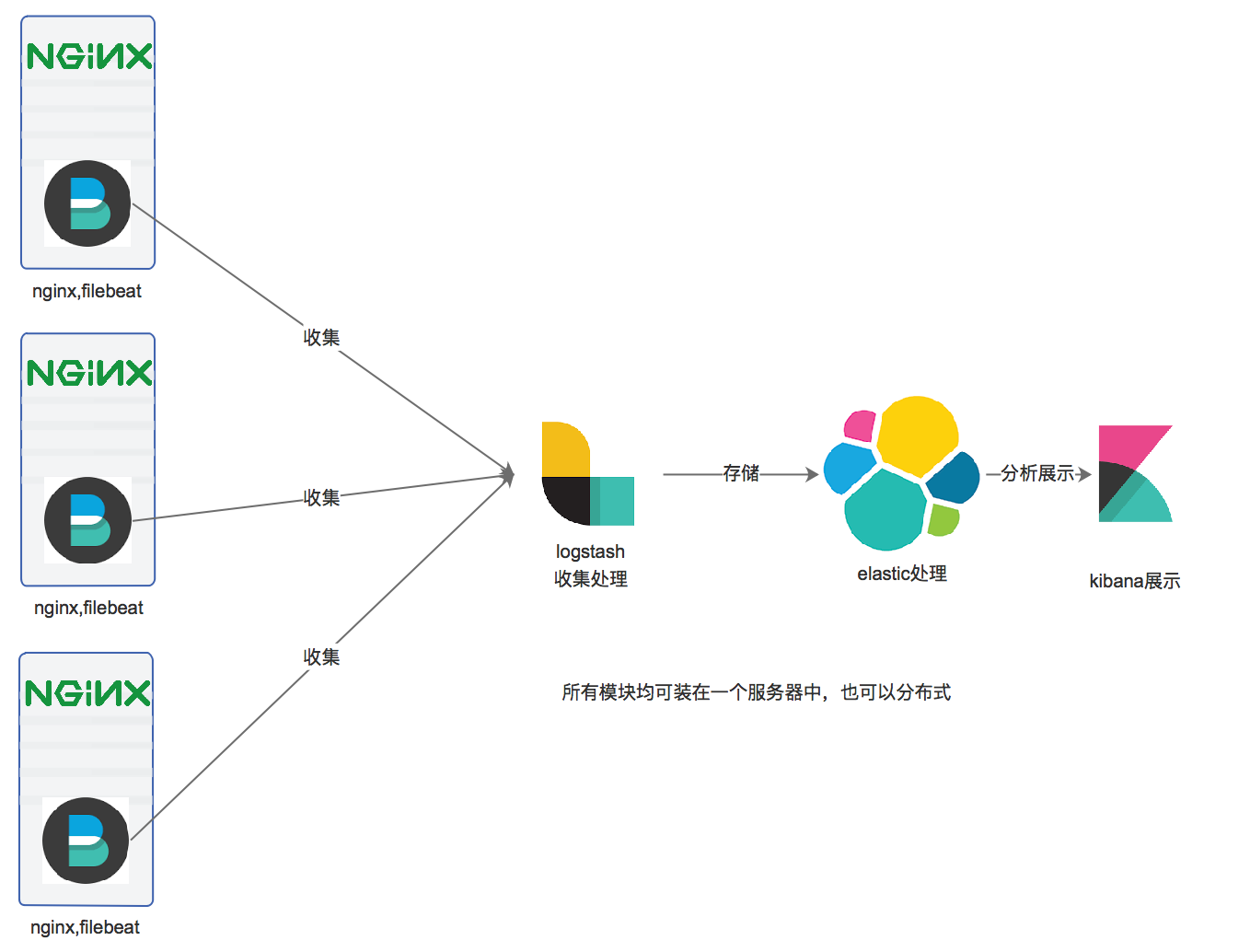
ELASTIC 5.2部署并收集nginx日志

#禁用swap内存交换
##若开启此选项,你需要修改/usr/lib/systemd/system/elasticsearch.service文件,并设置LimitMEMLOCK=infinity,
##修改/etc/sysconfig/elasticsearch文件,设置MAX_LOCKED_MEMORY=unlimited,最后执行systemctl daemon-reloa & systemctl restart elasticsearch
#bootstrap.memory_lock: true
谢土豪
如果有帮到你的话,请赞赏我吧!

ELASTIC 5.2部署并收集nginx日志的更多相关文章
- Docker 部署 ELK 收集 Nginx 日志
一.简介 1.核心组成 ELK由Elasticsearch.Logstash和Kibana三部分组件组成: Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引 ...
- ELK Stack (2) —— ELK + Redis收集Nginx日志
ELK Stack (2) -- ELK + Redis收集Nginx日志 摘要 使用Elasticsearch.Logstash.Kibana与Redis(作为缓冲区)对Nginx日志进行收集 版本 ...
- ELK日志系统之使用Rsyslog快速方便的收集Nginx日志
常规的日志收集方案中Client端都需要额外安装一个Agent来收集日志,例如logstash.filebeat等,额外的程序也就意味着环境的复杂,资源的占用,有没有一种方式是不需要额外安装程序就能实 ...
- ELK 二进制安装并收集nginx日志
对于日志来说,最常见的需求就是收集.存储.查询.展示,开源社区正好有相对应的开源项目:logstash(收集).elasticsearch(存储+搜索).kibana(展示),我们将这三个组合起来的技 ...
- 使用Docker快速部署ELK分析Nginx日志实践
原文:使用Docker快速部署ELK分析Nginx日志实践 一.背景 笔者所在项目组的项目由多个子项目所组成,每一个子项目都存在一定的日志,有时候想排查一些问题,需要到各个地方去查看,极为不方便,此前 ...
- ELK filter过滤器来收集Nginx日志
前面已经有ELK-Redis的安装,此处只讲在不改变日志格式的情况下收集Nginx日志. 1.Nginx端的日志格式设置如下: log_format access '$remote_addr - $r ...
- 安装logstash5.4.1,并使用grok表达式收集nginx日志
关于收集日志的方式,最简单性能最好的应该是修改nginx的日志存储格式为json,然后直接采集就可以了. 但是实际上会有一个问题,就是如果你之前有很多旧的日志需要全部导入elk上查看,这时就有两个问题 ...
- 使用Docker快速部署ELK分析Nginx日志实践(二)
Kibana汉化使用中文界面实践 一.背景 笔者在上一篇文章使用Docker快速部署ELK分析Nginx日志实践当中有提到如何快速搭建ELK分析Nginx日志,但是这只是第一步,后面还有很多仪表盘需要 ...
- 第七章·Logstash深入-收集NGINX日志
1.NGINX安装配置 源码安装nginx 因为资源问题,我们先将nginx安装在Logstash所在机器 #安装nginx依赖包 [root@elkstack03 ~]# yum install - ...
随机推荐
- iOS 远程推送注册的小问题
iOS8有了新方法,用新方法后,用7.0版本运行会奔溃.只要加一句判断就ok: #ifdef __IPHONE_8_0 // 在 iOS 8 下注册苹果推送,申请推送权限. UIUserNotific ...
- Miller_Rabin 素数测试
费马定理的逆定理几乎可以用来判断一个数是否为素数,但是有一些数是判断不出来的,因此,Miller_Rabin测试方法对费马的测试过程做了改进,克服其存在的问题. 推理过程如下(摘自维基百科): 摘自另 ...
- Zookeeper笔记之基于zk的分布式配置中心
一.场景 & 需求 集群上有很多个节点运行同一个任务,这个任务会有一些可能经常改变的配置参数,要求是当配置参数改变之后能够很快地同步到每个节点上,如果将这些配置参数放在本地文件中则每次都要修改 ...
- 非常有助于理解二极管PN结原理的资料
https://www.zhihu.com/question/60053574/answer/174137061 我理解的半导体 pn 结的原理,哪里错了? https://blog.csdn.net ...
- 用于阻止缓冲区溢出攻击的 Linux 内核参数与 gcc 编译选项
先来看看基于 Red Hat 与 Fedora 衍生版(例如 CentOS)系统用于阻止栈溢出攻击的内核参数,主要包含两项: kernel.exec-shield 可执行栈保护,字面含义比较“绕”, ...
- Mysql备份文件
- mysql主键的缺少导致备库hang
最近线上频繁的出现slave延时的情况,经排查发现为用户在删除数据的时候,由于表主键的主键的缺少,同时删除条件没有索引,或或者删除的条件过滤性极差,导致slave出现hang住,严重的影响了生产环境的 ...
- MySQL5.7 GTID在线开启与关闭【转】
当前场景 当前某些业务还有未开启GTID服务组,升级5.7后,如何检测是否符合开启GTID条件,如何在线修改切换使用GTID:已经升级5.7后,已经开启GTID,如何快速回滚后退: 线上gtid如 ...
- 使用Python编写简单的端口扫描器的实例分享【转】
转自 使用Python编写简单的端口扫描器的实例分享_python_脚本之家 http://www.jb51.net/article/76630.htm -*- coding:utf8 -*- #!/ ...
- mysql双主+keepalived【转】
简单原理 1.在两台服务器上分别部署双主keepalived,主keepalived会在当前服务器配置虚拟IP用于mysql对外提供服务 2.在两台服务器上分别部署主主mysql,用于故障切换 3.当 ...