24.API爬天气预报数据
1.免费注册API 地址: https://console.heweather.com/
必须要用IE浏览器打开,注册邮箱激活,打开控制台,如图:

认证key是访问api的钥匙
2.阅读api说明开发文档 地址:https://www.heweather.com/documents/api/v5/url
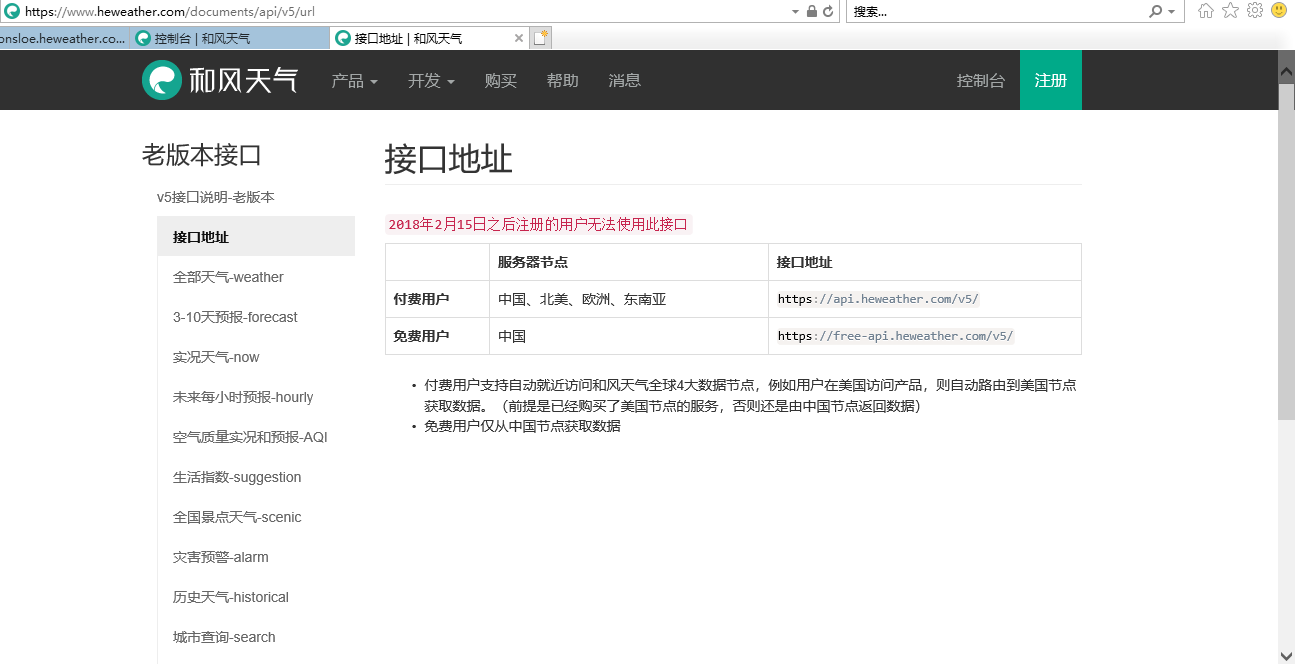
可以看到免费的用户只能访问一个服务器节点:

3.了解调用接口的方法
请求参数如下:

之后就需要拼接参数组成请求urlhttps://free-api.heweather.com/v5/weather?city=yourcity&key=yourkey
4.获取城市ID代码
链接地址:https://cdn.heweather.com/china-city-list.txt
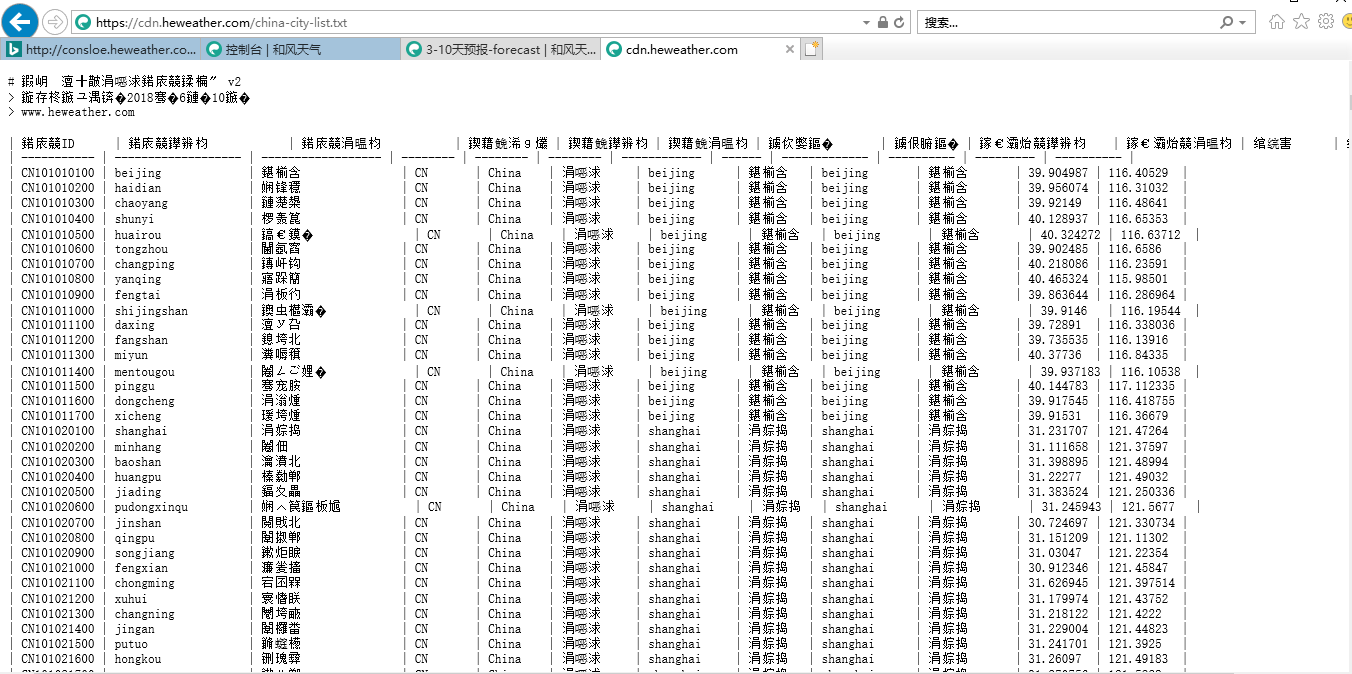
这里数据是乱码的,跟网页编码有关系。
5.获取城市代码
# coding:utf-8
import requests
url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
data = response.text
# print(data)
cont = data.split('\n')
# 去除头部多余标签
for i in range(6):
cont.remove(cont[0])
# print(cont)
#循环遍历,输出id
for j in cont:
print(j[2:14])
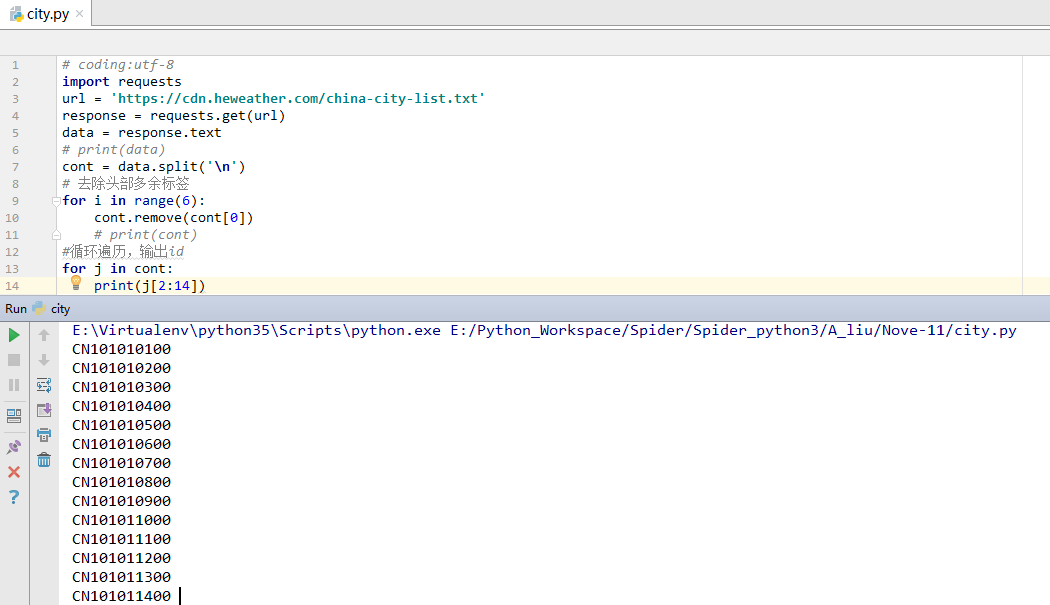
执行效果如下:
6.拼接url完善代码 # coding:utf-8
import requests
import random,time
url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
data = response.text
# print(data)
cont = data.split('\n')
# 去除头部多余标签
for i in range(6):
cont.remove(cont[0])
# print(cont)
#循环遍历,输出id
for j in cont:
# print(j[2:14])=
link_url= 'https://free-api.heweather.com/v5/weather?city={}'.format(j[2:14])+'&key=a3a4f84e9d68491e8b2e9d61c61df7c2'
print(link_url)
html = requests.get(link_url)
time.sleep(random.randint(1,2))
print(html.text)
代码报错:


是由于网站把这个借口给关闭了,已经无法使用,但调用api接口的方式大概就是这样。
模拟获取请求参数拼接请求url去获取数据,其实就和使用代理ip差不多。
24.API爬天气预报数据的更多相关文章
- 和风api爬取天气预报数据
''' 和风api爬取天气预报数据 目标:https://free-api.heweather.net/s6/weather/forecast?key=cc33b9a52d6e48de85247779 ...
- 百度地图POI数据爬取,突破百度地图API爬取数目“400条“的限制11。
1.POI爬取方法说明 1.1AK申请 登录百度账号,在百度地图开发者平台的API控制台申请一个服务端的ak,主要用到的是Place API.检校方式可设置成IP白名单,IP直接设置成了0.0.0.0 ...
- Android访问中央气象台的天气预报API得到天气数据
最新说明:该接口已失效! 2014-03-04 可申请它公布的API,需申请:http://smart.weather.com.cn/wzfw/smart/weatherapi.shtml 在用A ...
- 小试牛刀--利用豆瓣API爬取豆瓣电影top250
最近得赶进度爬点东西,对于豆瓣,它为开发者提供了API,目前是v2版本,目前key不对个人开放,但是可以正常通过其提供的API获取数据.豆瓣V2版API权限分3类:公开.高级.商务,我们用开放基本数据 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 用python+sklearn(机器学习)实现天气预报数据 数据
用python+sklearn机器学习实现天气预报 数据 项目地址 系列教程 勘误表 0.前言 1.爬虫 a.确认要被爬取的网页网址 b.爬虫部分 c.网页内容匹配取出部分 d.写入csv文件格式化 ...
- Python解析Yahoo的XML格式的天气预报数据
以下是Yahoo天气预报接口xml格式数据: <rss xmlns:yweather="http://xml.weather.yahoo.com/ns/rss/1.0" xm ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- 用JSON-server模拟REST API(二) 动态数据
用JSON-server模拟REST API(二) 动态数据 上一篇演示了如何安装并运行 json server , 在这里将使用第三方库让模拟的数据更加丰满和实用. 目录: 使用动态数据 为什么选择 ...
随机推荐
- shell脚本报错:-bash: xxx: /bin/sh^M: bad interpreter: No such file or directory --引用自http://blog.csdn.net/xiaaiwu/article/details/49126777
windows下编辑然后上传到linux系统里执行的..sh文件的格式为dos格式.而linux只能执行格式为unix格式的脚本. 我们可以通过vi编辑器来查看文件的format格式.步骤如下: 1. ...
- Nuke中新建线程的方法
最近维护合成部门的nuke工具包,发现不少工具的使用方法都很个人化,没有说明文档.这也导致artist在使用工具的时候比较感性,调整参数的时候缺少前后逻辑,长此以往,artist会产生这种意识:只要最 ...
- C#如何HttpWebRequest模拟登陆,获取服务端返回Cookie以便登录请求后使用
public static string GetCookie(string requestUrlString, Encoding encoding, ref CookieContainer cooki ...
- g++编译后中文显示乱码解决方案(c++)
g++编译后中文显示乱码解决方案 环境:Windows 10 专业版 GCC版本:5.3.0 测试代码: 1 #include <iostream> 2 using namespace ...
- 解决读取Excel表格中某列数据为空的问题 c#
解决同一列中“字符串”和“数字”两种格式同时存在,读取时,不能正确显示“字符串”格式的问题:set xlsconn=CreateObject("ADODB.Connection") ...
- ALGO-146_蓝桥杯_算法训练_4-2找公倍数
AC代码: #include <stdio.h> int main(void) { int i; ; i <= ; i ++) { == && i% == ) { p ...
- 使用R语言-计算均值,方差等
R语言对于数值计算很方便,最近用到了计算方差,标准差的功能,特记录. 数据准备 height <- c(6.00, 5.92, 5.58, 5.92) 1 计算均值 mean(height) [ ...
- python3学习笔记一(标识符、关键字)
查看Python版本 可以命令窗口,windows使用win+R调出cmd运行框,输入以下命令: python -V 进入python的交互编辑模式,也可查看 D:\Python3.6\Scripts ...
- python之冒泡排序(一)
冒泡排序 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来. 遍历数列的工作是重复地进行直到没有再需要交换, ...
- 阿里云kubernetes被minerd挖矿入侵
阿里云kubernetes被minerd挖矿入侵 # kubectl get rc mysql1 -o yaml apiVersion: v1 kind: ReplicationController ...