jvm运行机制和volatile关键字详解
参考https://www.cnblogs.com/dolphin0520/p/3920373.html
JVM启动流程
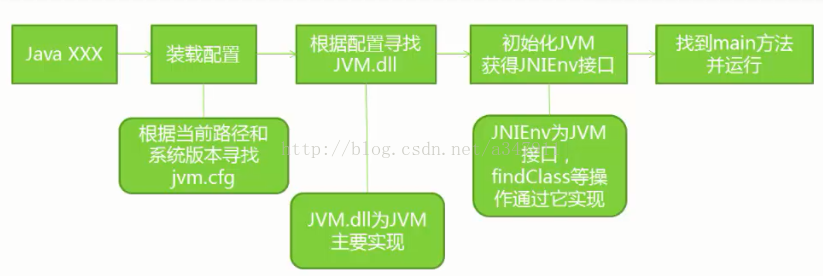
1.java虚拟机启动的命令是通过java +xxx(类名,这个类中要有main方法)或者javaw启动的。
2.执行命令后,系统第一步做的就是装载配置,会在当前路径中寻找jvm的config配置文件。
3.找到jvm的config配置文件之后会去定位jvm.dll这个文件。这个文件就是java虚拟机的主要实现。
4.当找到匹配当前版本的jvm.dll文件后,就会使用这个dll去初始化jvm虚拟机。获得相关的接口。之后找到main方法开始运行。
上面这个过程的描述虽然比较简单,但是jvm的启动流程基本都已经涵盖在里面了。
jvm的基本结构
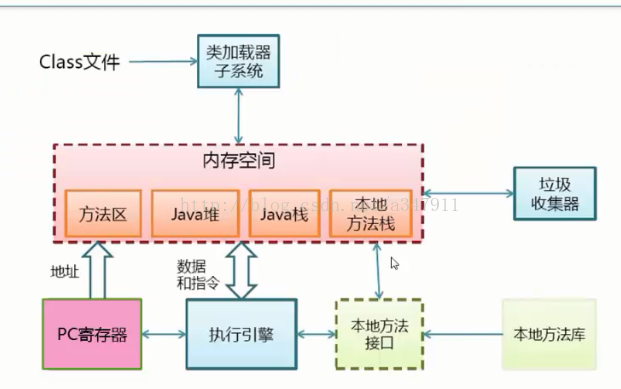
pc寄存器
每个线程拥有一个PC寄存器 在线程创建时 创建 指向下一条指令的地址 执行本地方法时,PC的值为undefined
方法区
java堆
java栈


1)通过在总线加LOCK#锁的方式
2)通过缓存一致性协议
这2种方式都是硬件层面上提供的方式。
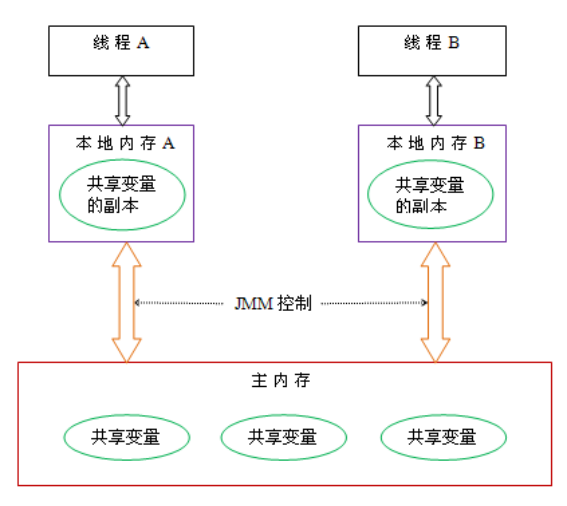
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。

可见性
有序性和指令重排
线程内串行语义 :
写后读 a = 1;b = a; 写一个变量之后,再读这个位置。
写后写 a = 1;a = 2; 写一个变量之后,再写这个变量。
读后写 a = b;b = 1; 读一个变量之后,再写这个变量。
以上语句不可重排 编译器不考虑多线程间的语义 可重排: a=1;b=2;
int a = 10; //语句1int r = 2; //语句2a = a + 3; //语句3r = a*a; //语句4 |
这段代码有4个语句,那么可能的一个执行顺序是:

那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3
不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。
虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
//线程1:context = loadContext(); //语句1inited = true; //语句2//线程2:while(!inited ){ sleep()}doSomethingwithconfig(context);上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。
也就是说,要想并发程序正确地执行,必须要保证并发编程特性(原子性、可见性以及有序性)。只要有一个没有被保证,就有可能会导致程序运行不正确。
1.原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
上面一句话虽然看起来简单,但是理解起来并不是那么容易。看下面一个例子i:
请分析以下哪些操作是原子性操作:
|
1
2
3
4
|
x = 10; //语句1y = x; //语句2x++; //语句3x = x + 1; //语句4 |
咋一看,有些朋友可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及 将x的值写入工作内存 这2个操作都是原子性操作,但是合起来就不是原子性操作了。
同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。
也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
补充: volatile不能保证原子性
下面看一个例子:
public class Test {
public volatile int inc = 0; public void increase() {
inc++;
} public static void main(String[] args) {
final Test test = new Test();
for(int i=0;i<10;i++){
new Thread(){
public void run() {
for(int j=0;j<1000;j++)
test.increase();
};
}.start();
} while(Thread.activeCount()>1) //保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}
大家想一下这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。 上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000次操作,
那么最终inc的值应该是1000*10=10000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的
操作的原子性。 在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,
就有可能导致下面这种情况出现: 假如某个时刻变量inc的值为10,
线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,
所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,
所以线程2会直接去主存读取inc的值,发现inc的值时10,
然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11
,然后将11写入工作内存,最后写入主存。
那么两个线程分别进行了一次自增操作后,inc只增加了1.
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
采用synchronized、lock、ActomicInteger可以达到原子性
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类。atomic是利用CAS来实现原子性操作的(Compare And Swap)
CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。 另外:volatile 不能保证提供操作的原子性,但可以利用其内存屏障(long类型得分两次写入,用valatile修饰后,只有当完全写入了,后面才能去使用),
如读 64 位数据类型,像 long 和 double 都不是原子的,但 volatile 类型的 double 和 long 就是原子的。
2.可见性
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。此外:final修饰的(一旦初始化完成,其他线程也就可见)
public class VolatileTest extends Thread{
private volatile boolean stop = false;
public void stopMe(){
stop=true;//volatile 写操作
}
public void run(){
int i=;
while(!stop){//volatile 读操作,刚开始为false,当前线程本地为false,监听到volatile 写操作,然后去load主存
i++;
}
System.out.println("Stop thread:"+i);//1466907008
//
}
public static void main(String args[]) throws InterruptedException{
VolatileTest t=new VolatileTest();
t.start();
//Thread.sleep(1000);
t.stopMe();
//Thread.sleep(1000);
}
}
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;//一般的读取还是从工作内存读取
第二:使用volatile关键字的话,当线程t进行修改时,会导致main线程的工作内存中缓存变量stop的缓存行无效
第三:由于main线程的工作内存中缓存变量stop的缓存行无效,所以需要再次读取变量stop的值时,这时会去主存读取。
那么在线程t修改stop值时(当然这里包括2个操作,工作内存store+主内存write),会使得main线程的工作内存中缓存变量stop的缓存行无效,然后main线程读取时,发现自己的缓存行无效(无效状态),它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值,那么main线程读取到的就是最新的正确的值。
联想上文中提到的缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时(触发操作),发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
volatile能保证有序性
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1)当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
即volatile是分水岭。
2)在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
//x、y为非volatile变量
//flag为volatile变量 x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。
那么我们回到前面举的一个例子: //线程1:
context = loadContext(); //语句1
inited = true; //语句2 //线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。 这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么就不能保证它们的有序性,虚拟机可以随意地对它们进行重排。
volatile的原理和实现机制
前面讲述了源于volatile关键字的一些使用,下面我们来探讨一下volatile到底如何保证可见性和禁止指令重排序的。
加入volatile关键字时,会多出一个lock前缀指令
lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),内存屏障会提供3个功能:
1)它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成;即分水岭
2)它会强制将对缓存的修改操作立即写入主存;
3)如果是写操作,它会导致其他CPU中对应的缓存行无效。
使用volatile关键字的场景:
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性
1.状态标记量
volatile boolean flag = false;
while(!flag){
doSomething();
}
public void setFlag() {
flag = true;
}
volatile boolean inited = false;
//线程1:
context = loadContext();
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
2.double check
class Singleton{
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();//我的感觉是,虽然构造行为是原子的,但是写入的是当前线程的工作内存,会让其他线程instance==null成立,从而再次构造。
}
}
return instance;
}
}
至于为何需要这么写请参考:
《Java 中的双重检查(Double-Check)》http://blog.csdn.net/dl88250/article/details/5439024
和http://www.iteye.com/topic/652440
解释运行:
解释执行以解释方式运行字节码 解释执行的意思是:读一句执行一句
编译运行(JIT):
将字节码编译成机器码 直接执行机器码 运行时编译 编译后性能有数量级的提升
jvm运行机制和volatile关键字详解的更多相关文章
- Java volatile关键字详解
Java volatile关键字详解 volatile是java中的一个关键字,用于修饰变量.被此关键修饰的变量可以禁止对此变量操作的指令进行重排,还有保持内存的可见性. 简言之它的作用就是: 禁止指 ...
- Java之先行发生原则与volatile关键字详解
volatile关键字可以说是Java虚拟机提供的最轻量级的同步机制,但是它并不容易完全被正确.完整地理解,以至于许多程序员都习惯不去使用它,遇到需要处理多线程数据竞争问题的时候一律使用synchro ...
- Java多线程-----volatile关键字详解
volatile原理 Java语言提供了一种稍弱的同步机制,即volatile变量,用来确保将变量的更新操作通知到其他线程.当把变量声明为volatile类型后, 编译器与运行时都会注意 ...
- Java中Volatile关键字详解 (转自郑州的文武)
java中volatile关键字的含义:http://www.cnblogs.com/aigongsi/archive/2012/04/01/2429166.html 一.基本概念 先补充一下概念:J ...
- C/C++中volatile关键字详解 (转)
1. 为什么用volatile? C/C++ 中的 volatile 关键字和 const 对应,用来修饰变量,通常用于建立语言级别的 memory barrier.这是 BS 在 "The ...
- C/C++中volatile关键字详解
1. 为什么用volatile? C/C++ 中的 volatile 关键字和 const 对应,用来修饰变量,通常用于建立语言级别的 memory barrier.这是 BS 在 "The ...
- Java并发编程:JMM (Java内存模型) 以及与volatile关键字详解
目录 计算机系统的一致性 Java内存模型 内存模型的3个重要特征 原子性 可见性 有序性 指令重排序 volatile关键字 保证可见性和防止指令重排 不能保证原子性 计算机系统的一致性 在现代计算 ...
- volatile关键字详解
本文系转载,原文链接:http://www.cnblogs.com/Chase/archive/2010/07/05/1771700.html,如有侵权,请联系我:534624117@qq.com 引 ...
- javascript运行机制之执行顺序详解(转)
转自http://www.admin10000.com/document/3385.html JavaScript是一种描述型脚本语言,它不同于java或C#等编译性语言,它不需要进行编译成中间语言, ...
随机推荐
- dbcp第一次获取连接的时间问题
最近优化代码,发现第一次调用数据库连接时非常慢,往后便不再发生.经了解,数据库连接是用dbcp管理的,想在网上查找答案,但没有找到.在某人的提醒下决定研究源代码: 部分源代码如下(BasicDataS ...
- 二:python 对象类型概述
1,为什么使用内置类型: a)内置对象使程序更容易编写 b)内置对象是扩展的组件 c)内置对象往往比定制的数据结构更加高效 d)内置对象是语言的标准的一部分 2,python 的主要内置对象 对象类 ...
- Leetcode:LRU Cache,LFU Cache
在Leetcode上遇到了两个有趣的题目,分别是利用LRU和LFU算法实现两个缓存.缓存支持和字典一样的get和put操作,且要求两个操作的时间复杂度均为O(1). 首先说一下如何在O(1)时间复杂度 ...
- poj1850(组合数)
题目链接:http://poj.org/problem;jsessionid=B0D9A01EC0F1043088A37454B6CED469?id=1850 题意:给字符串编号,该字符串必须满足由小 ...
- LibreOJ 6285. 数列分块入门 9
题目链接:https://loj.ac/problem/6285 其实一看到是离线,我就想用莫队算法来做,对所有询问进行分块,但是左右边界移动的时候,不会同时更新数字最多的数,只是后面线性的扫了一遍, ...
- Git 分支 - 分支管理
1 查看每一个分支 git branch 2 查看每一个分支的最后一次提交 git branch -v 3 创建分支 (1)只创建本地分支:git branch <branchname> ...
- gradle项目与maven项目互转
maven to gradle 在maven项目根目录下执行命令: gradle init --type pom 当然你得先下载Gradle,配置完环境变量. gradle to maven grad ...
- Netty---入门程序,搭建Websocket 服务器
Netty 常用的场景: 1.充当HTTP 服务器,但Netty 并没有遵循servlet 的标准,反而实现了自己的一套标准进行Http 服务: 2,RPC 远程调用,在分布式系统中常用的框架 3.S ...
- day 21 封装,多态,类的其他属性
封装 封装:将一些数据,重要的信息等等放到一个地方(空间中) class A: country = 'China' area = '深圳' def __init__(self,name,age): s ...
- SDK Manager 基础下载
双击SDK Manager打开Android SDK Manager. 全选以下几项 创建新项目 更改gradle的地址: 更改app的build.gradle: android { buildToo ...