MapReduce运行原理和过程
一.Map的原理和运行流程
Map的输入数据源是多种多样的,我们使用hdfs作为数据源。文件在hdfs上是以block(块,Hdfs上的存储单元)为单位进行存储的。

1.分片

我们将这一个个block划分成数据分片,即Split(分片,逻辑划分,不包含具体数据,只包含这些数据的位置信息),那么上图中的第一个Split则对应两个个文件块,第二个Split对应一个块。需要注意的是一个Split只会包含一个File的block,不会跨文件
2. 数据读取和处理

当我们把数据块分好的时候,MapReduce(以下简称mr)程序将这些分片以key-value的形式读取出来,并且将这些数据交给用户自定义的Map函数处理。
3.
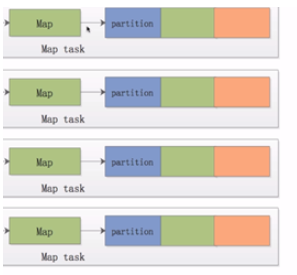
用户处理完这些数据后同样以key-value的形式将这些数据写出来交给mr计算框架。mr框架会对这些数据进行划分,此处用进行表示。不同颜色的partition矩形块表示为不同的partition,同一种颜色的partition最后会分配到同一个reduce节点上进行处理。
Map是如何将这些数据进行划分的?
默认使用Hash算法对key值进行Hash,这样既能保证同一个key值的数据划分到同一个partition中,又能保证不同partition的数据梁是大致相当的。
总结:
1.一个map指挥处理一个Split
2.map处理完的数据会分成不同的partition
3.一类partition对应一个reduce
那么一个mr程序中 map的数量是由split的数量决定的,reduce的数量是由partiton的数量决定的。
二.Shuffle
Shuffle,翻译成中文是混洗。mr没有排序是没有灵魂的,shuffle是mr中非常重要的一个过程。他在Map执行完,Reduce执行前发生。
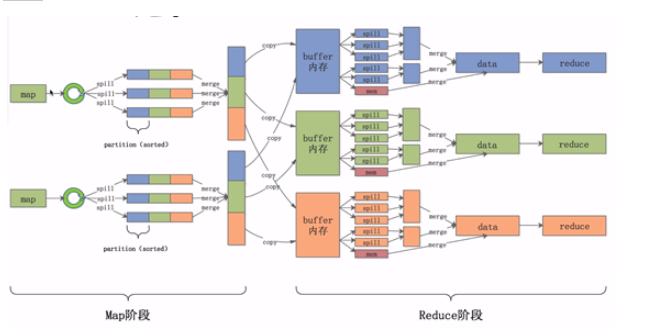
Map阶段的shuffle
数据经过用户自定的map函数处理完成之后,数据会放入内存中的环形缓冲区之内, ,他分为两个部分,数据区和索引区。数据区是存放用户真实的数据,索引区存放数据对应的key值,partition和位置信息。当环形缓冲区数据达到一定的比例后,会将数据溢写到一个文件之中,即途中的spill(溢写)过程。
,他分为两个部分,数据区和索引区。数据区是存放用户真实的数据,索引区存放数据对应的key值,partition和位置信息。当环形缓冲区数据达到一定的比例后,会将数据溢写到一个文件之中,即途中的spill(溢写)过程。
在溢写前,会将数据根据key和partition进行排序,排好序之后会将数据区的数据按照顺序一个个写入文件之中。这样就能保证文件中数据是按照key和parttition进行排序的。最后会将溢写出的一个个小文件合并成一个大的文件,并且保证在每一个partition
中是按照Key值有序的。
总结:
- Collect阶段将数据放进环形缓冲区,缓冲区分为数据区和索引区。
- Sort阶段对在同一partition内的索引按照key排序。
- Spill阶段跟胡排好序的索引将数据按照顺序写到文件中。
- Merge阶段将Spill生成的小文件分批合并排序成一个大文件。
Reduce阶段的shuffle
reduce节点会将数据拷贝到自己的buffer缓存区中,当缓存区中的数据达到一定的比例的时候,同样会发生溢写过程,我们任然要保证每一个溢写的文件是有序的。与此同时,后台会启一个线程,将这些小文件合并成一个大文件,经过一轮又一轮的合并,最后将这些文件合并成一个大的数据集。在这个数据集中,数据是有序的,相同的key值对应的value值是挨在一起的。最后,将这些数据交给reduce程序进行聚合处理。
总结:
- 1. Copy阶段将Map端的数据分批拷贝到Reduce的缓冲区。
- 2. Spill阶段将内存缓存区的数据按顺序写到文件中。
- 3. Merge阶段将溢出的文件合并成一个排序的数据集。
三.Reduce运行过程

在map处理完之后,reduce节点会将各个map节点上属于自己的数据拷贝到内存缓冲区中,最后将数据合并成一个大的数据集,并且按照key值进行聚合,把聚合后的value值作为iterable(迭代器)交给用户使用,这些数据经过用户自定义的reduce函数进行处理之后,同样会以key-value的形式输出出来,默认输出到hdfs上的文件。
四.Combine优化
我们说mr程序最终是要将数据按照key值进行聚合,对value值进行计算,那么我们是不是可以提前对聚合好的value值进行计算?of course,我们将这个过程称为Combine。哪些场景可以进行conbine优化。如下。
Map端:
1. 在数据排序后,溢写到磁盘前,运行combiner。这个时候相同Key值的value值是挨在一起的,可以对这些value值进行一次聚合计算,比如说累加。
2. 溢写出的小文件合并之前,我们也可以执行一次combiner,需要注意的是mr程序默认至少存在三个文件才进行combiner,否则mr会认为这个操作是不值得的。当然这个值可以通过min.num.spills.for.combine设置。
Reduce端:
- 和map端一样,在合并溢出文件输出到磁盘之前,运行combiner
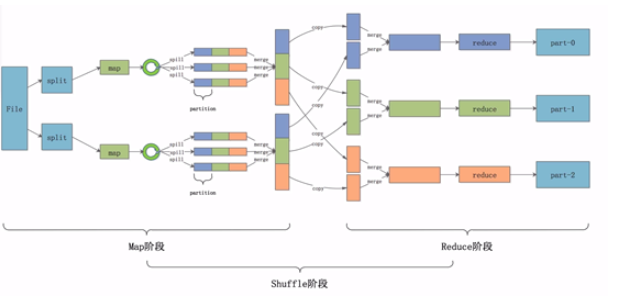
送上整个MR过程图
MapReduce运行原理和过程的更多相关文章
- 【原创】MapReduce运行原理和过程
一.Map的原理和运行流程 Map的输入数据源是多种多样的,我们使用hdfs作为数据源.文件在hdfs上是以block(块,Hdfs上的存储单元)为单位进行存储的. 1.分片 我们将这一个个block ...
- MapReduce运行原理
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各 ...
- MapReduce概述,原理,执行过程
MapReduce概述 MapReduce是一种分布式计算模型,运行时不会在一台机器上运行.hadoop是分布式的,它是运行在很多的TaskTracker之上的. 在我们的TaskTracker上面跑 ...
- Hadoop 2.6 MapReduce运行原理详解
市面上的hadoop权威指南一类的都是老版本的书籍了,索性学习并翻译了下最新版的Hadoop:The Definitive Guide, 4th Edition与大家共同学习. 我们通过提交jar包, ...
- mapreduce运行原理及YARN
mapreduce1回顾 mapreduce1的不足 yarn的基本架构 yarn工作流程
- Web应用运行原理
web应用启动做了什么? 读取web.xml文件 - web.xml常用配置参数: 1).context-param(上下文参数)2).listener(监听器配置参数)3).filter(过滤器 ...
- Linux X Window System运行原理和启动过程
本文主要说明X Window System的基本运行原理,其启动过程,及常见的跨网络运行X Window System. 一) 基本运行原理 X Window System采用C/S结构,但和我们常见 ...
- JSP起源、JSP的运行原理、JSP的执行过程
JSP起源 在很多动态网页中,绝大部分内容都是固定不变的,只有局部内容需要动态产生和改变. 如果使用Servlet程序来输出只有局部内容需要动态改变的网页,其中所有的静态内容也需要程序员用Java程序 ...
- MapReduce on Yarn运行原理
一.概念综述 MapReduce是一种可用于数据处理的编程模型(或计算模型),该模型可以比较简单,但想写出有用的程序却不太容易.MapReduce能将大型数据处理任务分解成很多单个的.可以在服务器集群 ...
随机推荐
- linux03
linux day31.正则表达式 \* ------重复0无数次 \+ ------重复1 无数次 ^ -------开头 $ -------结尾 | ------或 & ----- 与 ( ...
- 面向对象三大特性编写面向对象程序,self到底是谁
一.函数式编程和面向对象的对比 面向过程:根据业务逻辑从上到下写垒代码: 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可: 面向对象:对函数进行分类和封装,让开发“更快更好更强. ...
- [转载]java开发中的23种设计模式
原文链接:http://blog.csdn.net/zhangerqing 设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反 ...
- Spring static 静态属性注入
<bean class="org.springframework.beans.factory.config.MethodInvokingFactoryBean"> &l ...
- 如何执行超过一百兆(100MB)的sql脚本?
最近遇到一个问题,在sqlserver的查询分析器里面执行一个超过100MB的数据库脚本,发现老是报“引发类型为“System.OutOfMemoryException”的异常”,上网查了一下,主要是 ...
- python之ETL数据清洗案例源代码
#python语言 import pandas as pd import time data = pd.read_excel('ETL_数据清洗挑战.xlsx','测试数据',dtype=str)#读 ...
- postgresql-递增uuid优点
递增uuid的优点: https://blog.2ndquadrant.com/on-the-impact-of-full-page-writes/ 减小wal生成
- abp 使用 hangfire结合mysql
abp 官方使用的hangfire 默认使用的是sqlserver的存储 需要引入支持mysql的类库 我这边使用的是Hangfire.MySql.Core 直接用nuget安装即可 首先按照官方文档 ...
- 【disruptor】1、关于disruptor中的SequenceBarrier对象
首先这个类的uml结构在disruptor中是这样的,里面只有部分的属性对象和函数内容,具体有什么作用,用到了再说,用不到我也不会... 1.那么这个对象有什么用呢? 注意我们这个类中有哪些属性: 我 ...
- log4j UdpAppender
package cappender;import org.apache.log4j.AppenderSkeleton;import org.apache.log4j.Layout;import org ...