通过mapreduce把mysql的一张表的数据导到另外一张表中
怎么安装hadoop集群我在这里就不多说了,我这里安装的是三节点的集群
先在主节点安装mysql
启动mysql

登录mysql
创建数据库,创建表格,先把数据加载到表格 t ,表格t2是空的
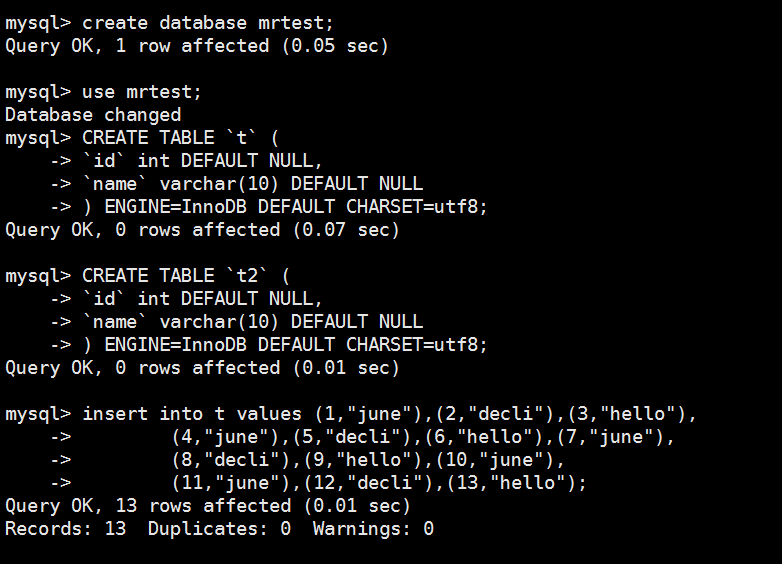
mysql> create database mrtest;
Query OK, 1 row affected (0.05 sec) mysql> use mrtest;
Database changed
mysql> CREATE TABLE `t` (
-> `id` int DEFAULT NULL,
-> `name` varchar(10) DEFAULT NULL
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.07 sec) mysql> CREATE TABLE `t2` (
-> `id` int DEFAULT NULL,
-> `name` varchar(10) DEFAULT NULL
-> ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Query OK, 0 rows affected (0.01 sec) mysql> insert into t values (1,"june"),(2,"decli"),(3,"hello"),
-> (4,"june"),(5,"decli"),(6,"hello"),(7,"june"),
-> (8,"decli"),(9,"hello"),(10,"june"),
-> (11,"june"),(12,"decli"),(13,"hello");
Query OK, 13 rows affected (0.01 sec)
Records: 13 Duplicates: 0 Warnings: 0
配置一下mysql数据库
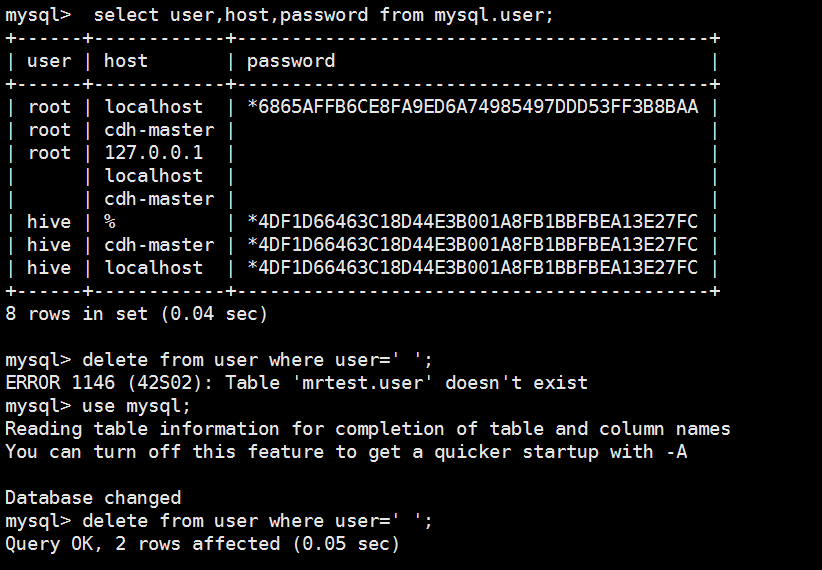
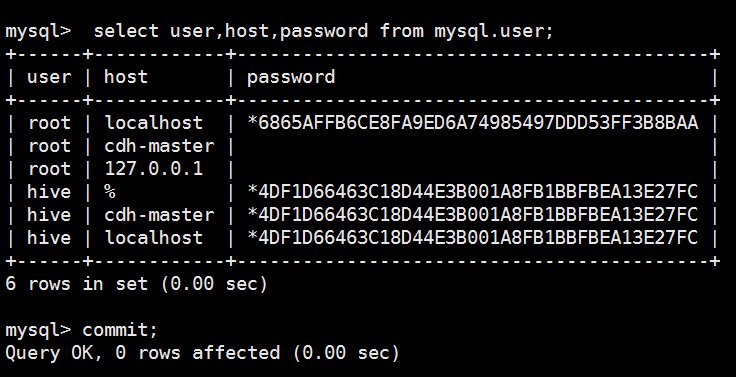
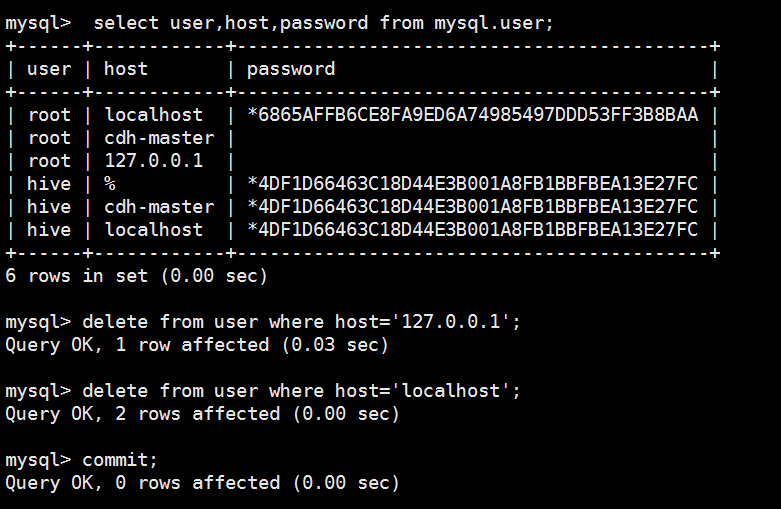
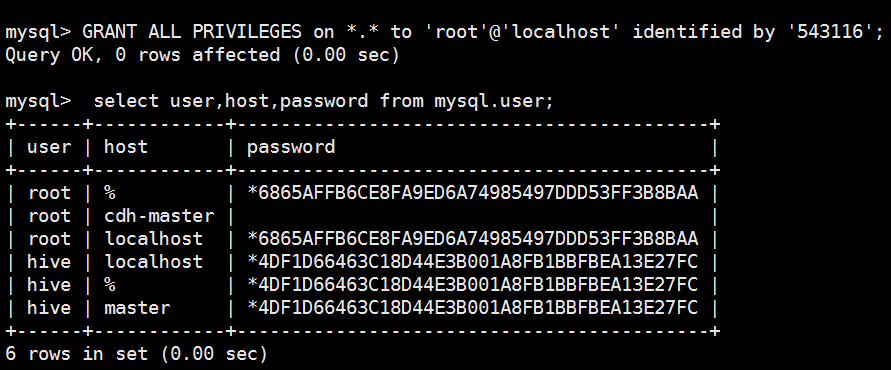
mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | localhost | *6865AFFB6CE8FA9ED6A74985497DDD53FF3B8BAA |
| root | cdh-master | |
| root | 127.0.0.1 | |
| | localhost | |
| | cdh-master | |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | cdh-master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
8 rows in set (0.04 sec) mysql> delete from user where user=' ';
ERROR 1146 (42S02): Table 'mrtest.user' doesn't exist
mysql> use mysql;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A Database changed
mysql> delete from user where user=' ';
Query OK, 2 rows affected (0.05 sec) mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | localhost | *6865AFFB6CE8FA9ED6A74985497DDD53FF3B8BAA |
| root | cdh-master | |
| root | 127.0.0.1 | |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | cdh-master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
6 rows in set (0.00 sec) mysql> commit;
Query OK, 0 rows affected (0.00 sec) mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | localhost | *6865AFFB6CE8FA9ED6A74985497DDD53FF3B8BAA |
| root | cdh-master | |
| root | 127.0.0.1 | |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | cdh-master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
6 rows in set (0.00 sec) mysql> delete from user where host='127.0.0.1';
Query OK, 1 row affected (0.03 sec) mysql> delete from user where host='localhost';
Query OK, 2 rows affected (0.00 sec) mysql> commit;
Query OK, 0 rows affected (0.00 sec) mysql> select user,host,password from mysql.user;
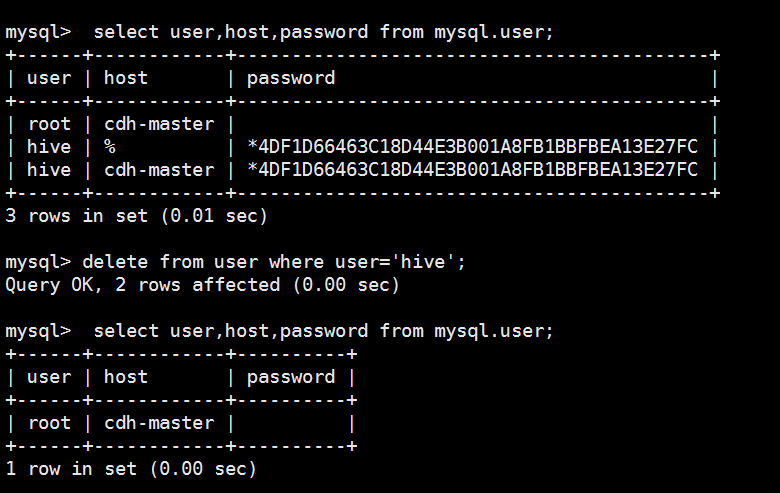
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | cdh-master | |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | cdh-master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
3 rows in set (0.01 sec) mysql> delete from user where user='hive';
Query OK, 2 rows affected (0.00 sec) mysql> select user,host,password from mysql.user;
+------+------------+----------+
| user | host | password |
+------+------------+----------+
| root | cdh-master | |
+------+------------+----------+
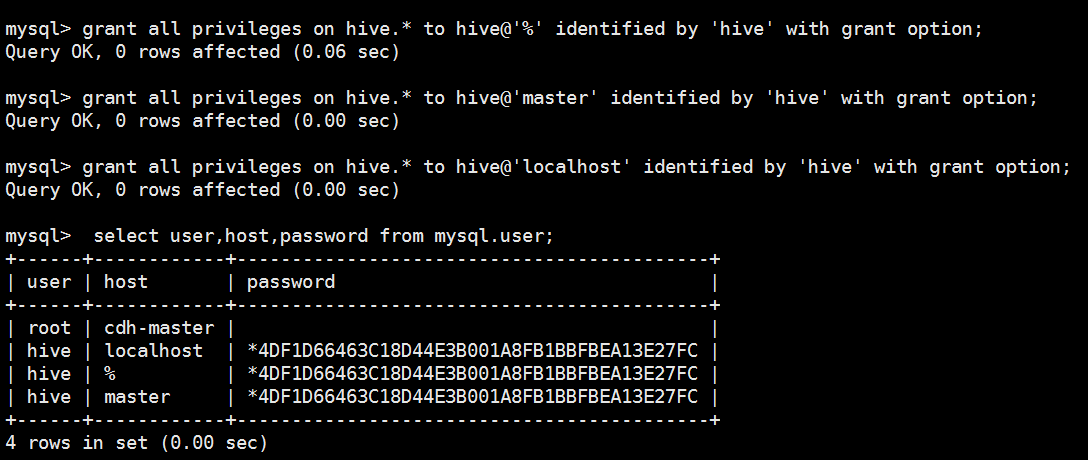
1 row in set (0.00 sec) mysql> grant all privileges on hive.* to hive@'%' identified by 'hive' with grant option;
Query OK, 0 rows affected (0.06 sec) mysql> grant all privileges on hive.* to hive@'master' identified by 'hive' with grant option;
Query OK, 0 rows affected (0.00 sec) mysql> grant all privileges on hive.* to hive@'localhost' identified by 'hive' with grant option;
Query OK, 0 rows affected (0.00 sec) mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | cdh-master | |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
4 rows in set (0.00 sec) mysql> grant all privileges on *.* to root@'%' identified by 'root';
Query OK, 0 rows affected (0.02 sec) mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | % | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
| root | cdh-master | |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
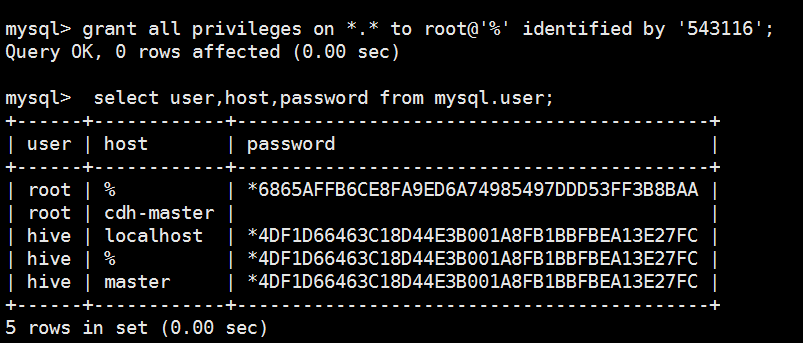
5 rows in set (0.00 sec) mysql> grant all privileges on *.* to root@'%' identified by '543116';
Query OK, 0 rows affected (0.00 sec) mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | % | *6865AFFB6CE8FA9ED6A74985497DDD53FF3B8BAA |
| root | cdh-master | |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
5 rows in set (0.00 sec) mysql> GRANT ALL PRIVILEGES on *.* to 'root'@'localhost' identified by '543116';
Query OK, 0 rows affected (0.00 sec) mysql> select user,host,password from mysql.user;
+------+------------+-------------------------------------------+
| user | host | password |
+------+------------+-------------------------------------------+
| root | % | *6865AFFB6CE8FA9ED6A74985497DDD53FF3B8BAA |
| root | cdh-master | |
| root | localhost | *6865AFFB6CE8FA9ED6A74985497DDD53FF3B8BAA |
| hive | localhost | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | % | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
| hive | master | *4DF1D66463C18D44E3B001A8FB1BBFBEA13E27FC |
+------+------------+-------------------------------------------+
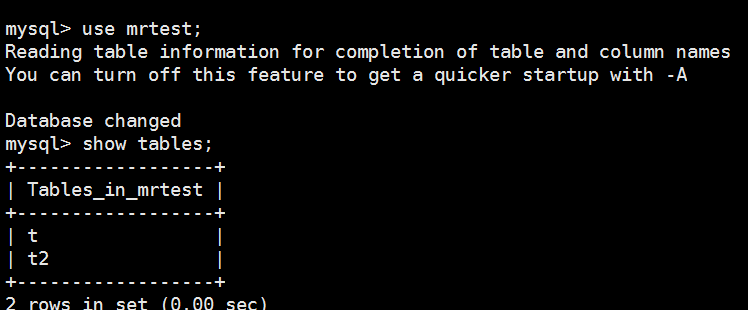
6 rows in set (0.00 sec) mysql> use mrtest;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A Database changed
mysql> show tables;
+------------------+
| Tables_in_mrtest |
+------------------+
| t |
| t2 |
+------------------+
2 rows in set (0.00 sec)
在eclipse创建mapreduce项目
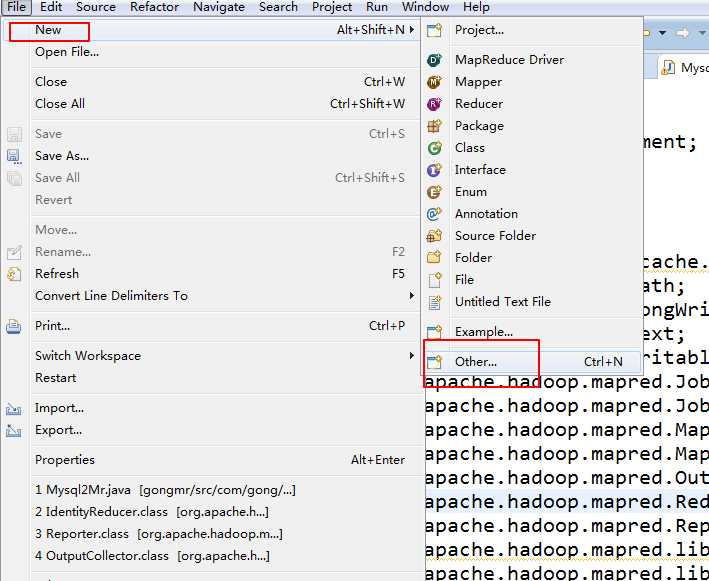
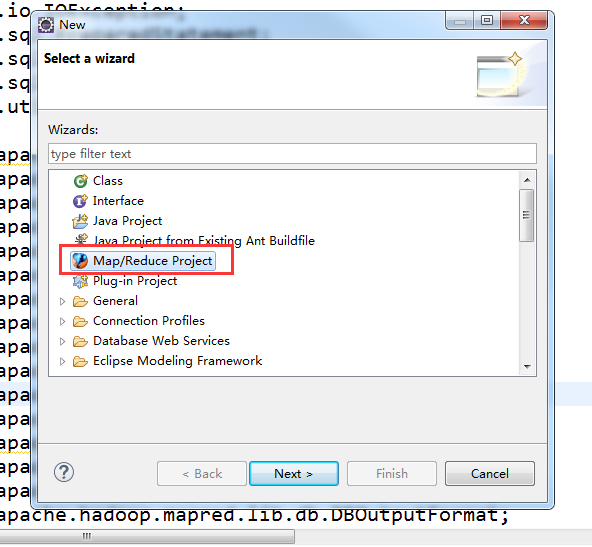
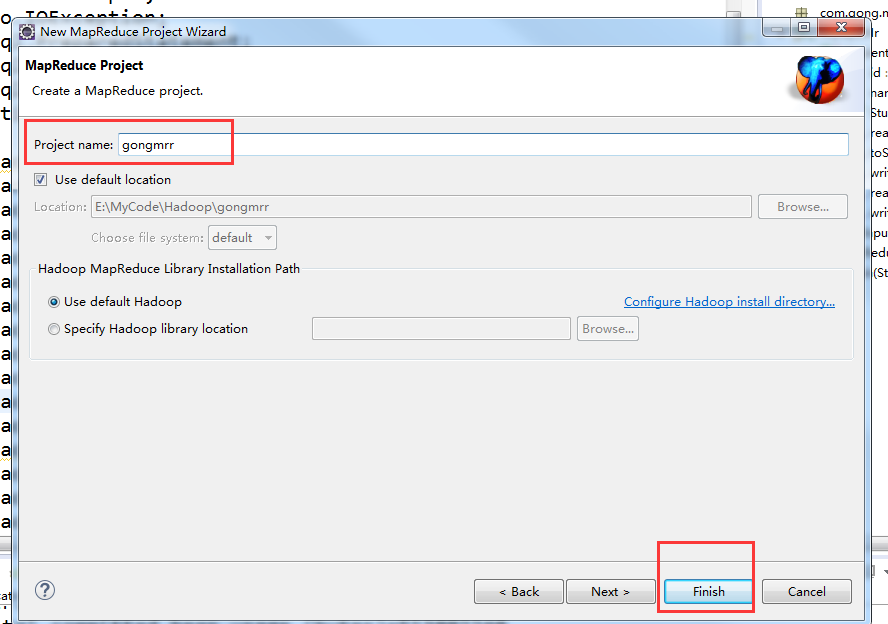
在这里说一下我这里是安装的是hadoop2.6.0版本的
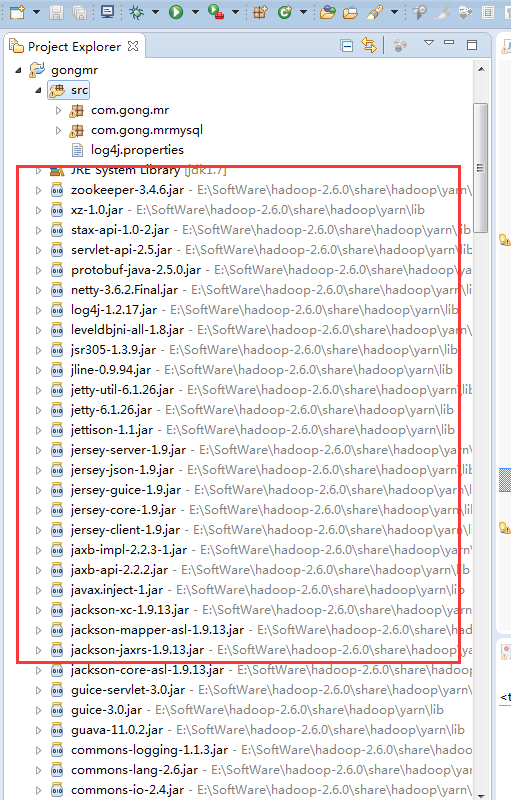
如果没有添加对应的hadoop插件的话就这样添加
现在你本地安装的eclipse的dropins文件夹了放入这个插件,然后重新启动eclipse
重启之后
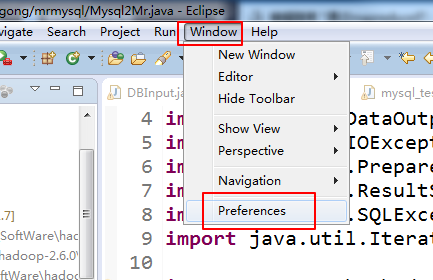
我们可以看到多了这么一项
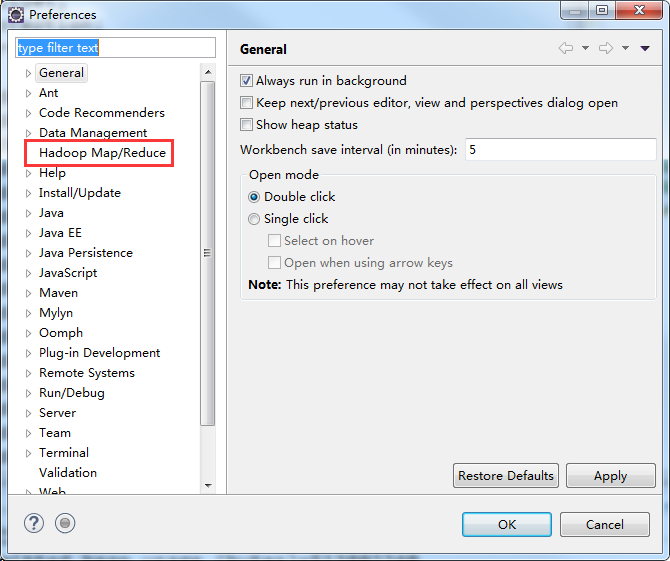
在这里选定本地安装的hadoop
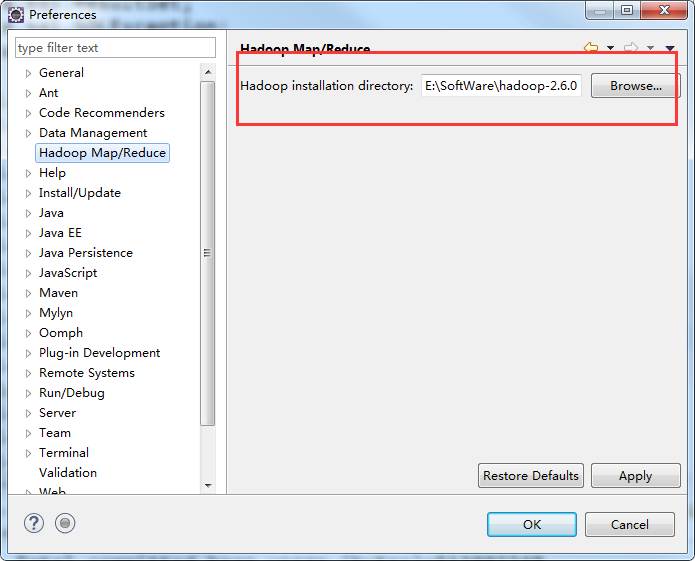
接下来是加载mysql的驱动包
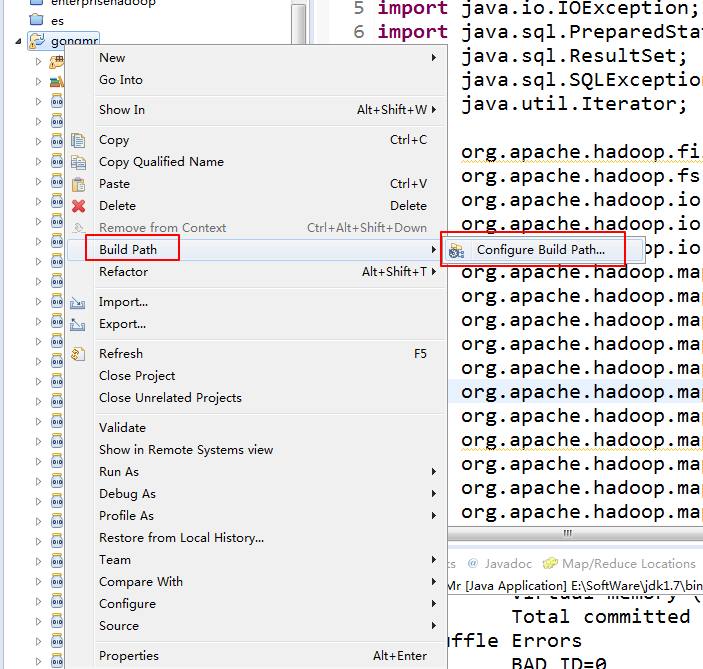
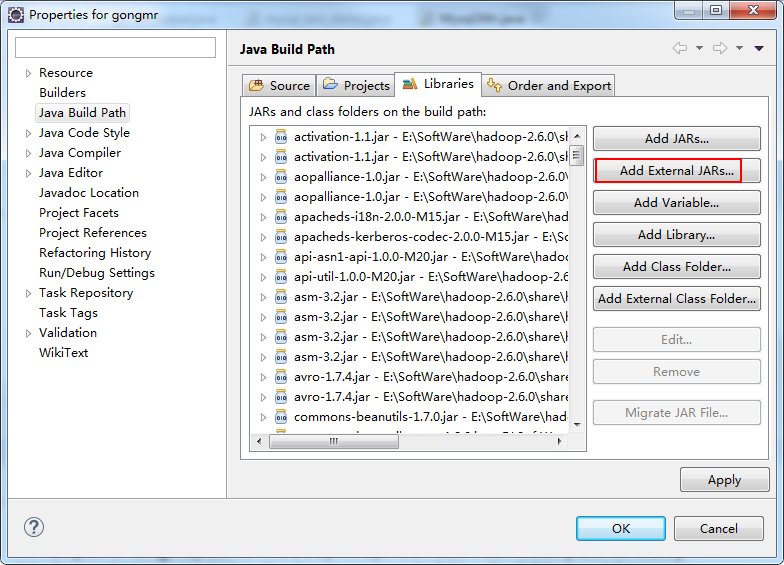
这个是我本地的mysql驱动包
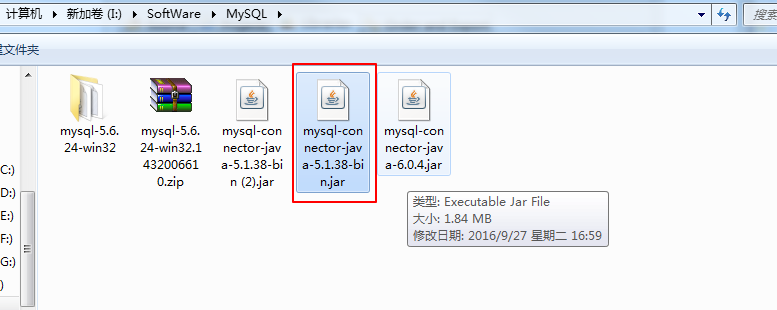
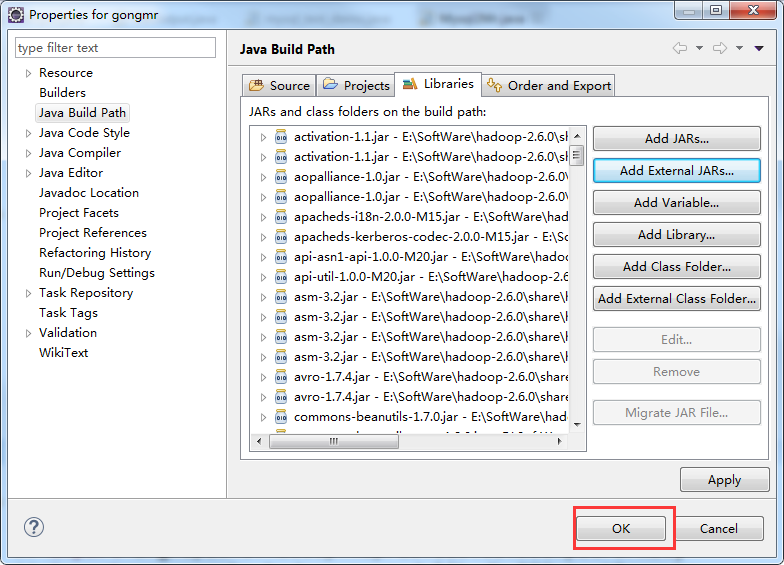
在eclipse加载驱动包之后还需要在集群里加载
把驱动包上传的每个节点的hadoop安装目录的lib目录下,是所有节点
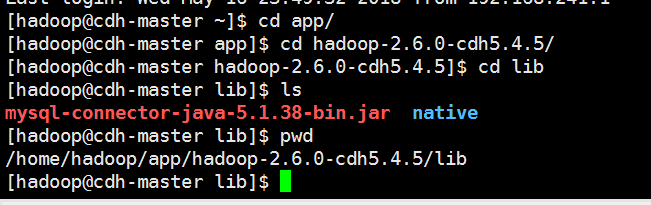
把集群启动一下,我这里只是搭建了分布式的3节点没有搭建HA
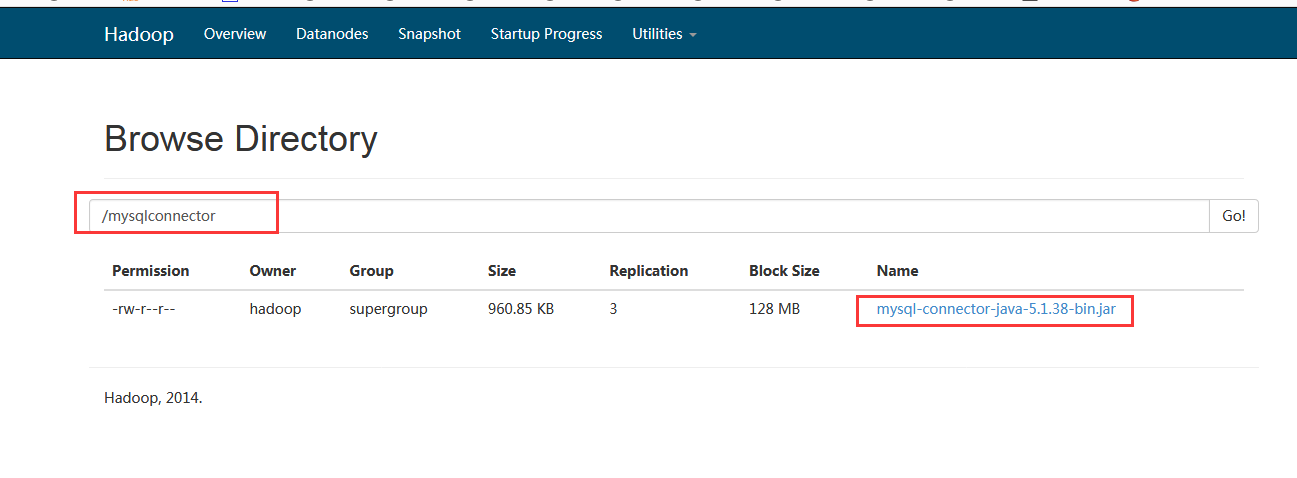
我们现在hdfs上创建一个目录来存放mysql的驱动包

把本地的驱动包上传的hdfs上

在代码里面要加上这句来实现
DistributedCache.addFileToClassPath(new Path("hdfs://192.168.241.13:9000/mysqlconnector/mysql-connector-java-5.1.38-bin.jar"), conf);
下面是运行代码
package com.gong.mrmysql; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Iterator; import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.lib.IdentityReducer;
import org.apache.hadoop.mapred.lib.db.DBConfiguration;
import org.apache.hadoop.mapred.lib.db.DBInputFormat;
import org.apache.hadoop.mapred.lib.db.DBOutputFormat;
import org.apache.hadoop.mapred.lib.db.DBWritable; /**
* Function: 测试 mr 与 mysql 的数据交互,此测试用例将一个表中的数据复制到另一张表中
* 实际当中,可能只需要从 mysql 读,或者写到 mysql 中。
* date: 2013-7-29 上午2:34:04 <br/>
* @author june
*/
public class Mysql2Mr {
// DROP TABLE IF EXISTS `hadoop`.`studentinfo`;
// CREATE TABLE studentinfo (
// id INTEGER NOT NULL PRIMARY KEY,
// name VARCHAR(32) NOT NULL); public static class StudentinfoRecord implements Writable, DBWritable {
int id;
String name; public StudentinfoRecord() { } public void readFields(DataInput in) throws IOException {
this.id = in.readInt();
this.name = Text.readString(in);
} public String toString() {
return new String(this.id + " " + this.name);
} @Override
public void write(PreparedStatement stmt) throws SQLException {
stmt.setInt(1, this.id);
stmt.setString(2, this.name);
} @Override
public void readFields(ResultSet result) throws SQLException {
this.id = result.getInt(1);
this.name = result.getString(2);
} @Override
public void write(DataOutput out) throws IOException {
out.writeInt(this.id);
Text.writeString(out, this.name);
}
} // 记住此处是静态内部类,要不然你自己实现无参构造器,或者等着抛异常:
// Caused by: java.lang.NoSuchMethodException: DBInputMapper.<init>()
// http://stackoverflow.com/questions/7154125/custom-mapreduce-input-format-cant-find-constructor
// 网上脑残式的转帖,没见到一个写对的。。。
public static class DBInputMapper extends MapReduceBase implements
Mapper<LongWritable, StudentinfoRecord, LongWritable, Text> {
public void map(LongWritable key, StudentinfoRecord value,
OutputCollector<LongWritable, Text> collector, Reporter reporter) throws IOException {
collector.collect(new LongWritable(value.id), new Text(value.toString()));
}
} public static class MyReducer extends MapReduceBase implements
Reducer<LongWritable, Text, StudentinfoRecord, Text> {
@Override
public void reduce(LongWritable key, Iterator<Text> values,
OutputCollector<StudentinfoRecord, Text> output, Reporter reporter) throws IOException {
String[] splits = values.next().toString().split(" ");
StudentinfoRecord r = new StudentinfoRecord();
r.id = Integer.parseInt(splits[0]);
r.name = splits[1];
output.collect(r, new Text(r.name));
}
} public static void main(String[] args) throws IOException {
JobConf conf = new JobConf(Mysql2Mr.class);
DistributedCache.addFileToClassPath(new Path("hdfs://192.168.241.13:9000/mysqlconnector/mysql-connector-java-5.1.38-bin.jar"), conf); conf.setMapOutputKeyClass(LongWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(LongWritable.class);
conf.setOutputValueClass(Text.class); conf.setOutputFormat(DBOutputFormat.class);
conf.setInputFormat(DBInputFormat.class);
// // mysql to hdfs
// conf.setReducerClass(IdentityReducer.class);
// Path outPath = new Path("/tmp/1");
// FileSystem.get(conf).delete(outPath, true);
// FileOutputFormat.setOutputPath(conf, outPath); DBConfiguration.configureDB(conf, "com.mysql.jdbc.Driver", "jdbc:mysql://192.168.241.13:3306/mrtest",
"root", "543116");
String[] fields = { "id", "name" };
// 从 t 表读数据
DBInputFormat.setInput(conf, StudentinfoRecord.class, "t", null, "id", fields);
// mapreduce 将数据输出到 t2 表
DBOutputFormat.setOutput(conf, "t2", "id", "name");
// conf.setMapperClass(org.apache.hadoop.mapred.lib.IdentityMapper.class);
conf.setMapperClass(DBInputMapper.class);
conf.setReducerClass(MyReducer.class); JobClient.runJob(conf);
}
}
我们运行一下
通过mysql查看t2表看看有没有数据
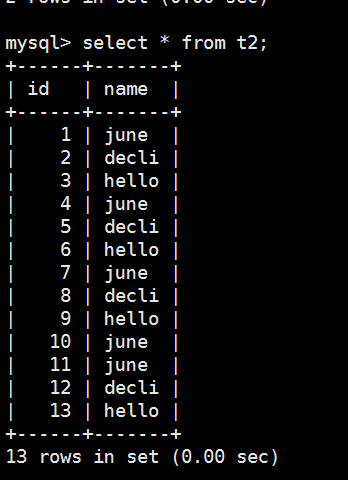
再运行一次,可以看到t2表又一次被加载进数据了
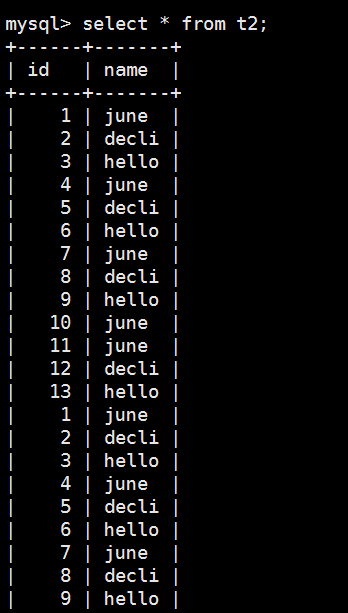
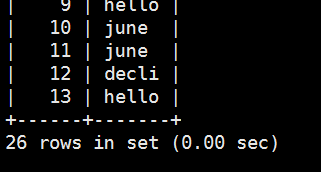
这里我们就实现了怎么用mapreduce把mysql的一张表的数据加载到另外一张表去了。
通过mapreduce把mysql的一张表的数据导到另外一张表中的更多相关文章
- 一条sql解决.一张表的数据复制到另外一张表
如何把一个表的数组复制到一张表?也许很多人会把这个表查出来的数据再插入到另外一张表里面,这样很麻烦又要写代码逻辑去处理,其实一条sql语句就可以把一张表的数据复制到另外一张表,或者一张表的某一条数据复 ...
- hive sql 查询一张表的数据不在另一张表中
有时,我们需要对比两张表的数据,找到在其中一张表,不在另一张表中的数据 hql 如下: SELECT * FROM (SELECT id FROM a WHERE dt = '2019-03-17' ...
- oracle 批量更新之将一个表的数据批量更新至另一个表
oracle 批量更新之将一个表的数据批量更新至另一个表 CreationTime--2018年7月3日17点38分 Author:Marydon Oracle 将一个表的指定字段的值更新至另一个 ...
- mysql 如何用一条SQL将一张表里的数据插入到另一张表 3个例子
1. 表结构完全一样 insert into 表1 select * from 表2 2. 表结构不一样(这种情况下得指定列名) insert into 表1 (列名1,列名2,列名3) selec ...
- mysql 将一张表里的数据插入到另一张表
1. 表结构一样 insert into 表1 select * from 表2 2. 表结构不一样 insert into 表1 (列名1,列名2,列名3) select 列1,列2,列3 from ...
- 两种方法将oracle数据库中的一张表的数据导入到另外一个oracle数据库中
oracle数据库实现一张表的数据导入到另外一个数据库的表中的方法有很多,在这介绍两个. 第一种,把oracle查询的数据导出为sql文件,执行sql文件里的insert语句,如下: 第一步,导出sq ...
- SQL- 将一张表的数据插入到另一张表,表结构不一致(加条件)
公司业务需要,在对表进行操作的时候将操作人和操作记录记录到日志表里.记录下来以供参考和学习. 首先准备两张测试表:Info以及InfoLog 1.表结构相同的情况下: insert into Info ...
- 在oracle中怎么把一张表的数据插入到另一张表中
把table2表的数据插入到table1中 insert into table1 select * from table2
- SQL从一个表查询数据插入/更新到另一个表
示例一: 从数据库表A中查询出数据插入到数据库表B 从数据库DataBaseA的表TDA中查询出数据插入到数据库DataBaseB的表TDB insert into [DataBaseA].[dbo] ...
随机推荐
- MongoDB之 的Rollback讲解及避免
首先,rollback到底是什么意思呢?在关系型数据库中因为有事务的概念,操作数据后在没有commit之前是可以执行rollback命令进行数据回退的. 而在单实例mongodb中,写入就写入了,删除 ...
- ElasticSearch story(二)
调优一个问题,碰到了一个坎:大家看一下下面两个字符串: 2018-10-16 18:01:34.000 abcdewfrwfe 2018-10-16 18:01:50.123 testAmily012 ...
- 设计模式-责任链模式Chain of Responsibility)
一.定义 职责链模式是一种对象的行为模式.在职责链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链.请求在这个链上传递,直到链上的某一个对象决定处理此请求.发出这个请求的客户端并不知道链 ...
- HanLP用户自定义词典源码分析详解
1. 官方文档及参考链接 l 关于词典问题Issue,首先参考:FAQ l 自定义词典其实是基于规则的分词,它的用法参考这个issue l 如果有些数量词.字母词需要分词,可参考:P2P和C2C这种词 ...
- Java生成PDF文档(表格、列表、添加图片等)
需要的两个包及下载地址: (1)iText.jar:http://download.csdn.net/source/296416 (2)iTextAsian.jar(用来进行中文的转换):http:/ ...
- Linux系统下启动tomcat报错【java.util.prefs.BackingStoreException: Couldn't get file lock】的解决方法
Linux环境下,启动tomcat报出如题的警告信息,虽然对系统正常使用没有多大影响,但是会导致tomcat的日志垃圾信息很多,而且看起来很不爽... 具体的警告信息如下: Jan , :: PM j ...
- BT.656 NTSC制式彩条生成模块(verilog)
BT.656 NTSC制式彩条生成模块(verilog) 1.知识储备 隔行扫描是将一副图像分成两场扫描,第一场扫描第1,2,5,7...等奇数行,第二场扫描2,4,6,8...等偶数行,并把扫奇数行 ...
- golang语言并发与并行——goroutine和channel的详细理解(一) 转发自https://blog.csdn.net/skh2015java/article/details/60330785
如果不是我对真正并行的线程的追求,就不会认识到Go有多么的迷人. Go语言从语言层面上就支持了并发,这与其他语言大不一样,不像以前我们要用Thread库 来新建线程,还要用线程安全的队列库来共享数据. ...
- 转 Oracle监听器启动出错:本地计算机上的OracleOraDb11g_home1TNSListener服务启动后又停止了解决方案
今早刚上班.客户打电话过来说系统访问不了,输入用户名.用户号不能加载出来!听到这个问题,第一时间想到的是不是服务器重新启动了,Oracle数据库的相关服务没有启动的原因.查看服务的时候,发现相关的服务 ...
- C#中winform使用相对路径读取文件的方法
http://cache.baiducontent.com/c?m=9f65cb4a8c8507ed4fece763105392230e54f73b6cd0d3027fa3cf1fd579080101 ...