大数据入门第二十二天——spark(一)入门与安装
一、概述
1.什么是spark
从官网http://spark.apache.org/可以得知:
Apache Spark™ is a fast and general engine for large-scale data processing.
主要的特性有:
Speed:快如闪电(HADOOP的100倍+)
Easy to Use:Scala——Perfect、Python——Nice、Java——Ugly、R
Generality:Spark内核上可以跑Spark SQL、Spark Streaming、GraphX等。
Run EveryWhere:HADOOP、HBASE、kubernetes等。
中文简明介绍:
Spark是一种快速、通用、可扩展的大数据分析引擎;
2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
更多介绍,参见官网
二、安装
这里下载的是spark的1.6.3的pre build的版本,对应的是Hadoop2.6以及scala 2.10的版本,这里也是为了兼容之前安装的Hadoop等版本。到今天(2018.4)为止,spark的2.0版本已经发布了有一段时间了,后续将会进行2.0版本新特性的相关补充,此处入门就以1.6.3为例!
1.下载
这里用本机下载好了,通过sftp上传到了mini1
// 前置条件JDK等已经安装完毕!
2.解压
[hadoop@mini1 ~]$ tar -zxvf spark-1.6.-bin-hadoop2..tgz -C apps/
// 这里发现之前安装的时候Home目录只给了2G,而选择软件安装的时候又都安装在Home目录下了,通过df -h和du -sh查看到使用情况。下次需要注意!

基本上,目录下也是常见的套路:sbin里一些起停脚本,bin下一些操作脚本等
3.配置
进入spark的conf目录,常规的套路了:
[hadoop@mini1 spark-1.6.-bin-hadoop2.]$ cd conf/
[hadoop@mini1 conf]$ mv spark-env.sh.template spark-env.sh
vim spark-env.sh
追加以下内容(最简配置):请通过export命令提前查看相关变量值(这里Hosts也已经配置了)
export JAVA_HOME=/opt/java/jdk1..0_151
export SPARK_MASTER_IP=mini1
export SPARK_MASTER_PORT=
配置slaves:
[hadoop@mini1 conf]$ mv slaves.template slaves
vim slaves
配置worker节点:(和Hadoop基本类似套路)
mini2
mini3
4.拷贝到其他节点
scp -r spark-1.6.-bin-hadoop2./ mini2:/home/hadoop/apps/
scp -r spark-1.6.-bin-hadoop2./ mini3:/home/hadoop/apps/
5.启动测试
在mini1上启动(暂时未配置环境变量):
[hadoop@mini1 spark-1.6.-bin-hadoop2.]$ sbin/start-all.sh
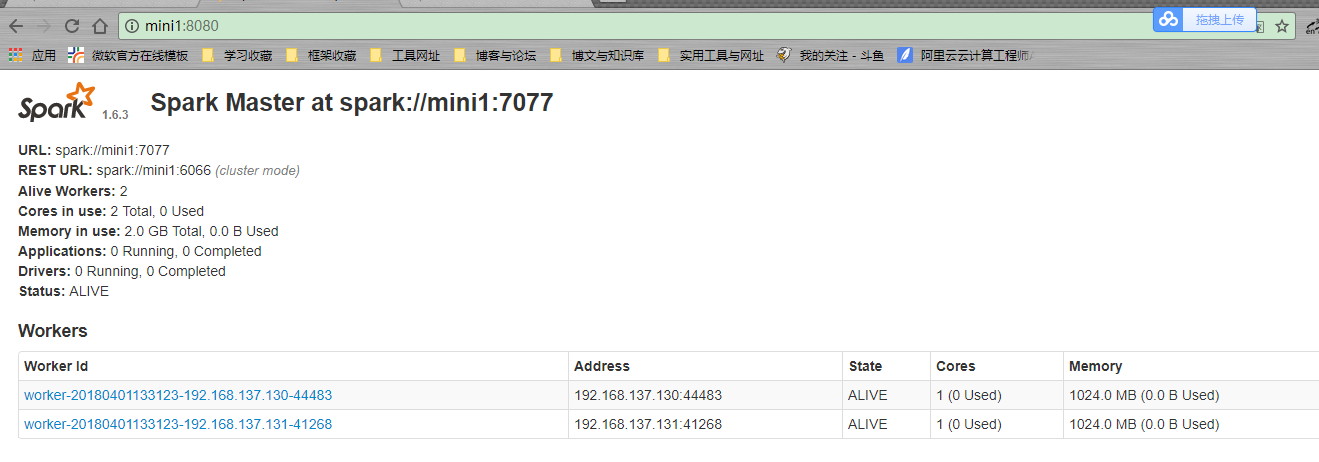
通过jps可以看到Master和Worker等进程;
WEB界面:http://mini1:8080/
6.Master单点问题
到此为止,Spark集群安装完毕,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单:
Spark集群规划:node1,node2是Master;node3,node4,node5是Worker
安装配置zk集群,并启动zk集群
停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=zk1,zk2,zk3 -Dspark.deploy.zookeeper.dir=/spark"
.在node1节点上修改slaves配置文件内容指定worker节点
.在node1上执行sbin/start-all.sh脚本,然后在node2上执行sbin/start-master.sh启动第二个Master
三、执行Spark程序
1.执行spark示例程序
/usr/local/spark-1.5.-bin-hadoop2./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node1.itcast.cn:7077 \
--executor-memory 1G \
--total-executor-cores \
/usr/local/spark-1.5.-bin-hadoop2./lib/spark-examples-1.5.-hadoop2.6.0.jar \
//根据实际安装修改相关命令位置(出现的小错误这里暂时忽略,后续处理)
2.启动spark shell
[hadoop@mini1 ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-shell \
> --master spark://mini1:7077 \
> --executor-memory 1g \
> --total-executor-cores 2
参数说明:
--master spark://node1.itcast.cn:7077 指定Master的地址,如果不指定,则为Local模式了!
--executor-memory 2g 指定每个worker可用内存为2G
--total-executor-cores 指定整个集群使用的cup核数为2个
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
.首先启动hdfs
.向hdfs上传一个文件到hdfs://node1.itcast.cn:9000/words.txt
.在spark shell中用scala语言编写spark程序
sc.textFile("hdfs://node1.itcast.cn:9000/words.txt").flatMap(_.split(" "))
.map((_,)).reduceByKey(_+_).saveAsTextFile("hdfs://node1.itcast.cn:9000/out") .使用hdfs命令查看结果
hdfs dfs -ls hdfs://node1.itcast.cn:9000/out/p* 说明:
sc是SparkContext对象,该对象时提交spark程序的入口
textFile(hdfs://node1.itcast.cn:9000/words.txt)是hdfs中读取数据
flatMap(_.split(" "))先map在压平
map((_,))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("hdfs://node1.itcast.cn:9000/out")将结果写入到hdfs中
大数据入门第二十二天——spark(一)入门与安装的更多相关文章
- 大数据入门第二十二天——spark(二)RDD算子(1)
一.RDD概述 1.什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行计算的 ...
- 大数据入门第二十二天——spark(三)自定义分区、排序与查找
一.自定义分区 1.概述 默认的是Hash的分区策略,这点和Hadoop是类似的,具体的分区介绍,参见:https://blog.csdn.net/high2011/article/details/6 ...
- 大数据入门第二十二天——spark(二)RDD算子(2)与spark其它特性
一.JdbcRDD与关系型数据库交互 虽然略显鸡肋,但这里还是记录一下(点开JdbcRDD可以看到限制比较死,基本是鸡肋.但好在我们可以通过自定义的JdbcRDD来帮助我们完成与关系型数据库的交互.这 ...
- 大数据为什么要选择Spark
大数据为什么要选择Spark Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析. Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发开发,其核心部 ...
- CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
- 决战大数据之三-Apache ZooKeeper Standalone及复制模式安装及测试
决战大数据之三-Apache ZooKeeper Standalone及复制模式安装及测试 [TOC] Apache ZooKeeper 单机模式安装 创建hadoop用户&赋予sudo权限, ...
- 分布式大数据多维分析(OLAP)引擎Apache Kylin安装配置及使用示例【转】
Kylin 麒麟官网:http://kylin.apache.org/cn/download/ 关键字:olap.Kylin Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的 ...
- CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager
CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搭建CM私有仓库 详情请参考我的笔记: http ...
随机推荐
- 企业BI系统应用的切入点及五大策略
从技术的角度来看,BI的技术正在走向成熟,处于一个发展的阶段,但它促使了BI的应用在成本方面开始逐步的降低,越来越多的企业在BI应用方面取得了成功.从实施的角度来出发,实施商业智能系统是一项复杂的系统 ...
- Android--仿一号店货物详情轮播图动画效果
还不是很完全,目前只能点中间图片才能位移,图片外的其他区域没有..(属性动画),对了,图片加载用得是facebook的一款android图片加载库,感觉非常NB啊,完爆一切. 1.先看布局 <? ...
- Linux load average负载量分析与解决思路
一.load average top命令中load average显示的是最近1分钟.5分钟和15分钟的系统平均负载.系统平均负载表示 系统平均负载被定义为在特定时间间隔内运行队列中(在CPU上运行或 ...
- 解决:Tomcat 局域网IP地址 访问不了
解决:Tomcat 局域网IP地址 访问不了 2014年10月17日 ⁄ 综合 ⁄ 共 1000字 ⁄ 字号 小 中 大 ⁄ 评论关闭 如果连最基本的localhost:8080都失败的话. 原因就一 ...
- pycharm的放大和缩小字体的显示 和ubunt的截圖工具使用 ubuntu上安装qq微信等工具
https://www.cnblogs.com/sui776265233/p/9322074.html#_label0 ubuntu: 截圖工具的使用 在ubuntu 10.04 的时候,还可以很方便 ...
- 天河2号-保持使用yhrun/srun时连接不中断 (screen 命令教程 )
问题重述: 当我们使用天河机进行并行程序实验的时候,都会使用到yhrun/srun命令.在超算环境下,yhrun 命令用来进行提交交互式作业,有屏幕输出.但是容易受到网络波动影响导致断网或者关闭窗口最 ...
- Collection中的List,Set的toString()方法
代码: Collection c = new ArrayList(); c.add("hello"); c.add("world"); ...
- SpringBoot部署
Spring Boot 部署到服务器 jar 形式 1.打包 若我们在新建Spring Boot 项目的时候,选择打包方式是 jar,则我们只需要用 mvn package 就可以进行打包. 2.运行 ...
- 《深入理解JVM》读书笔记
目前只是整理了书的前几章,把jvm的内存划分简要说明.垃圾回收算法.垃圾回收器.常用的命令和工具进行说明.命令和工具的使用找个时间需要详细按步骤截图说明. 还有一部分内容是举例说明了一下字节码指令的样 ...
- Apache Kafka系列(一) 起步
Apache Kafka系列(一) 起步 Apache Kafka系列(二) 命令行工具(CLI) Apache Kafka系列(三) Java API使用 Apache Kafka系列(四) 多线程 ...