Hadoop框架
1、Hadoop的整体框架
Hadoop由HDFS、MapReduce、HBase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
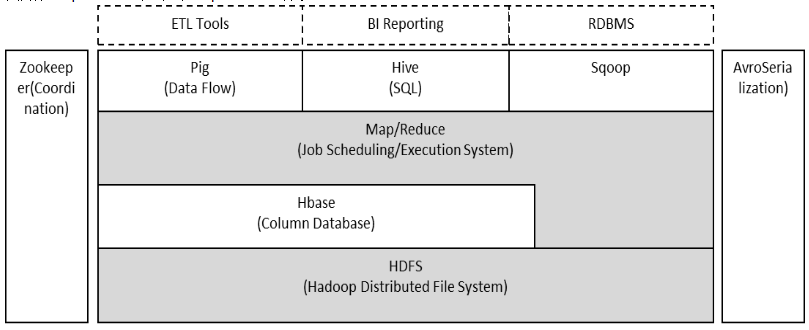
(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
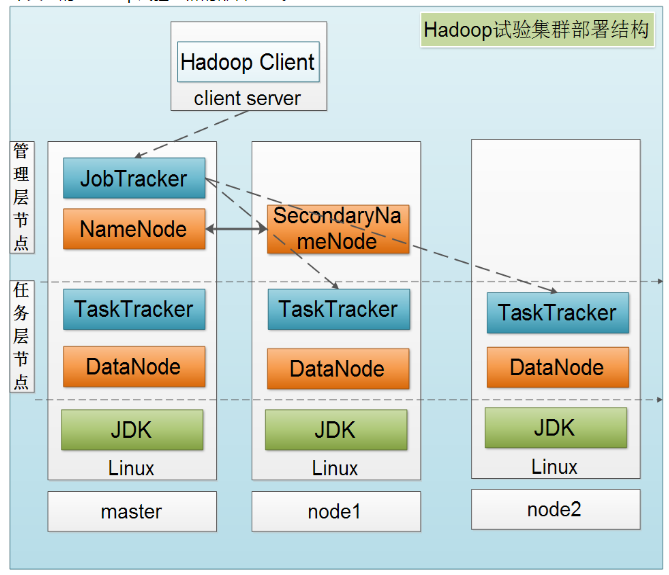
下图是一个典型的Hadoop集群的部署结构:
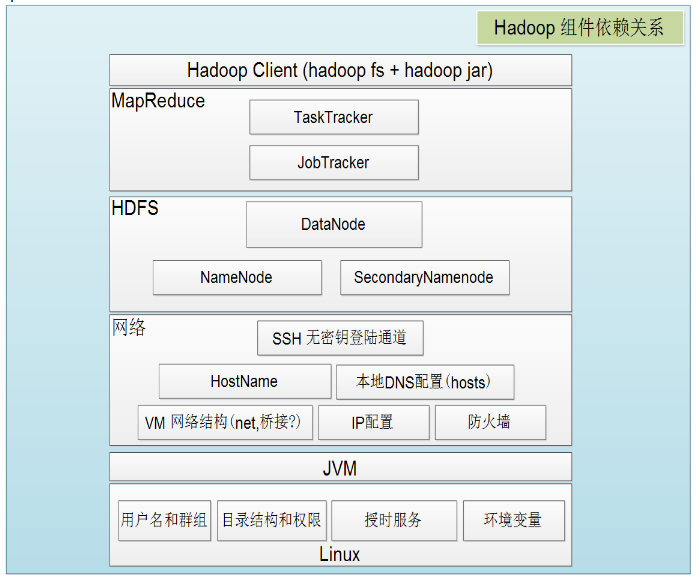
接着给出Hadoop各组件依赖共存关系:
2、Hadoop的核心设计
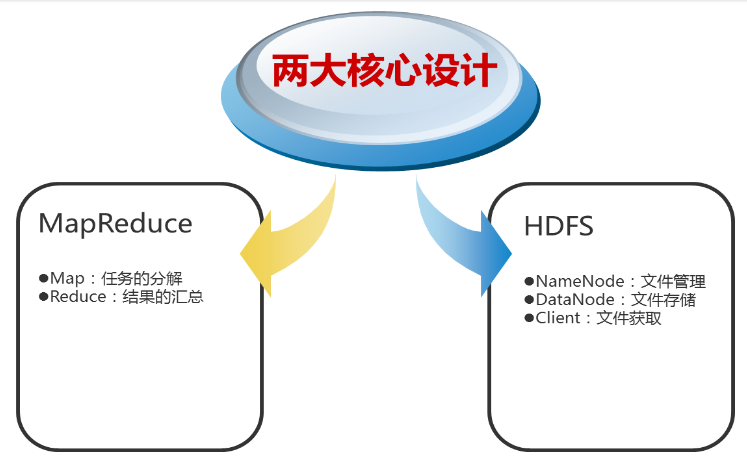
(1)HDFS
HDFS是一个高度容错性的分布式文件系统,可以被广泛的部署于廉价的PC上。它以流式访问模式访问应用程序的数据,这大大提高了整个系统的数据吞吐量,因而非常适合用于具有超大数据集的应用程序中。
HDFS的架构如图所示。HDFS架构采用主从架构(master/slave)。一个典型的HDFS集群包含一个NameNode节点和多个DataNode节点。NameNode节点负责整个HDFS文件系统中的文件的元数据的保管和管理,集群中通常只有一台机器上运行NameNode实例,DataNode节点保存文件中的数据,集群中的机器分别运行一个DataNode实例。在HDFS中,NameNode节点被称为名称节点,DataNode节点被称为数据节点。DataNode节点通过心跳机制与NameNode节点进行定时的通信。
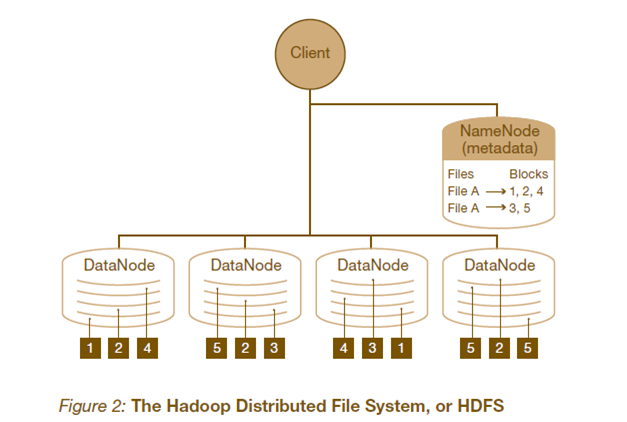
•NameNode
可以看作是分布式文件系统中的管理者,存储文件系统的meta-data,主要负责管理文件系统的命名空间,集群配置信息,存储块的复制。
•DataNode
是文件存储的基本单元。它存储文件块在本地文件系统中,保存了文件块的meta-data,同时周期性的发送所有存在的文件块的报告给NameNode。
•Client
就是需要获取分布式文件系统文件的应用程序。
以下来说明HDFS如何进行文件的读写操作:
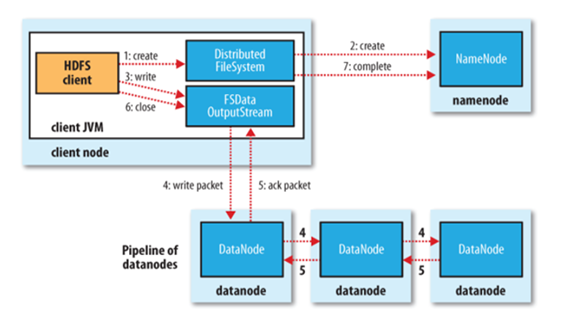
文件写入:
1. Client向NameNode发起文件写入的请求
2. NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
3. Client将文件划分为多个文件块,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
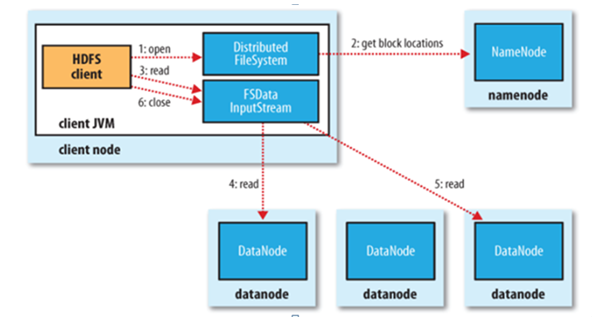
文件读取:
1. Client向NameNode发起文件读取的请求
2. NameNode返回文件存储的DataNode的信息。
3. Client读取文件信息。
(2)MapReduce
MapReduce是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(化简),采用分而治之思想,先把任务分发到集群多个节点上,并行计算,然后再把计算结果合并,从而得到最终计算结果。多节点计算,所涉及的任务调度、负载均衡、容错处理等,都由MapReduce框架完成,不需要编程人员关心这些内容。
下图是MapReduce的处理过程:
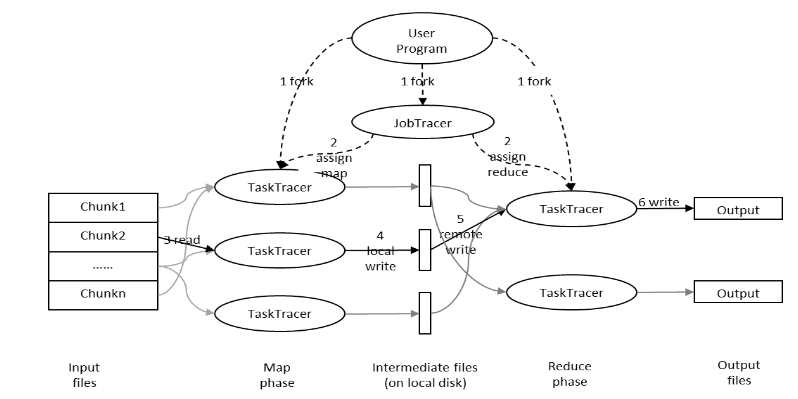
用户提交任务给JobTracer,JobTracer把对应的用户程序中的Map操作和Reduce操作映射至TaskTracer节点中;输入模块负责把输入数据分成小数据块,然后把它们传给Map节点;Map节点得到每一个key/value对,处理后产生一个或多个key/value对,然后写入文件;Reduce节点获取临时文件中的数据,对带有相同key的数据进行迭代计算,然后把终结果写入文件。
如果这样解释还是太抽象,可以通过下面一个具体的处理过程来理解:(WordCount实例)
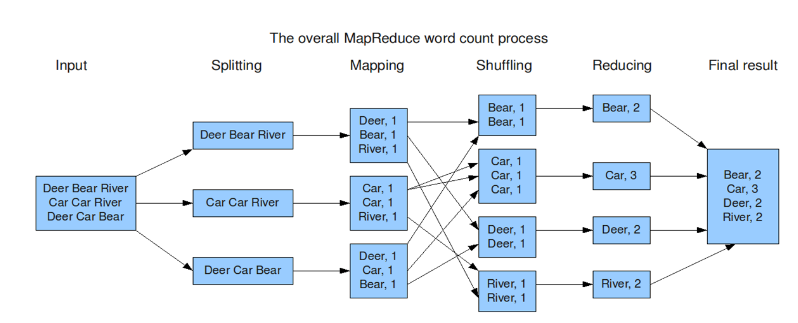
Hadoop的核心是MapReduce,而MapReduce的核心又在于map和reduce函数。它们是交给用户实现的,这两个函数定义了任务本身。
map函数:接受一个键值对(key-value pair)(例如上图中的Splitting结果),产生一组中间键值对(例如上图中Mapping后的结果)。Map/Reduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
reduce函数:接受一个键,以及相关的一组值(例如上图中Shuffling后的结果),将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)(例如上图中Reduce后的结果)
但是,Map/Reduce并不是万能的,适用于Map/Reduce计算有先提条件:
(1)待处理的数据集可以分解成许多小的数据集;
(2)而且每一个小数据集都可以完全并行地进行处理;
若不满足以上两条中的任意一条,则不适合适用Map/Reduce模式。
Hadoop框架的更多相关文章
- 从hadoop框架与MapReduce模式中谈海量数据处理
http://blog.csdn.net/wind19/article/details/7716326 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显 ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- hadoop框架详解
Hadoop框架详解 Hadoop项目主要包括以下四个模块 ◆ Hadoop Common: 为其他Hadoop模块提供基础设施 ◆ Hadoop HDFS: 一个高可靠.高吞吐量的分布式文件系统 ◆ ...
- 大数据系列之Hadoop框架
Hadoop框架中,有很多优秀的工具,帮助我们解决工作中的问题. Hadoop的位置 从上图可以看出,越往右,实时性越高,越往上,涉及到算法等越多. 越往上,越往右就越火…… Hadoop框架中一些简 ...
- Hadoop YARN学习之Hadoop框架演进历史简述
Hadoop YARN学习之Hadoop框架演进历史简述(1) 1. Hadoop在其发展的过程中经历了多个阶段: 阶段0:Ad Hoc集群时代 标志着Hadoop的起源,集群以Ad Hoc.单用户方 ...
- Hadoop框架基础(五)
** Hadoop框架基础(五) 已经部署了Hadoop的完全分布式集群,我们知道NameNode节点的正常运行对于整个HDFS系统来说非常重要,如果NameNode宕掉了,那么整个HDFS就要整段垮 ...
- Hadoop 框架基础(四)
** Hadoop 框架基础(四) 上一节虽然大概了解了一下 mapreduce,徒手抓了海胆,不对,徒手写了 mapreduce 代码,也运行了出来.但是没有做更深入的理解和探讨. 那么…… 本节目 ...
- Hadoop框架基础(三)
** Hadoop框架基础(三) 上一节我们使用eclipse运行展示了hdfs系统中的某个文件数据,这一节我们简析一下离线计算框架MapReduce,以及通过eclipse来编写关于MapReduc ...
- Hadoop框架基础(二)
** Hadoop框架基础(二) 上一节我们讨论了如何对hadoop进行基础配置已经运行一个简单的实例,接下来我们尝试使用eclipse开发. ** maven安装 简单介绍:maven是一个项目管理 ...
- Hadoop框架基础(一)
** Hadoop框架基础(一) 学习一个新的东西,传统而言呢,总喜欢漫无目的的扯来扯去,比如扯扯发展史,扯扯作者是谁,而我认为这些东西对于刚开始接触,并以开发为目的学者是没有什么帮助的,反而 ...
随机推荐
- The attribute required is undefined for the annotation type XmlElementRef
异常描述: 几天没用的项目导进Eclipse中发现有异常 public class BooleanFeatureType extends FeatureBaseType{ @XmlElementRef ...
- Operating System Error Codes
How To Fix Windows Errors Click here follow the steps to fix Windows and related errors. Instruction ...
- 做为一个.net码农,打开公司的一个项目,大叔我哭了
先说下背景,楼主在上海,之前一直是做BS互联网开发的,今年进入这家公司,是做软件产品的小外企. 然后,啥也不说了,直接上图吧: 因为一个屏幕没有办法显示出来,所以我截了3张图,然后拼成一张,这还是我花 ...
- 重置AD用户密码
$cc = import-csv D:\Powershell\Tauba.csv foreach ($c in $cc) { $c.username $pwd = $c.password get-ad ...
- 乘风破浪:LeetCode真题_034_Find First and Last Position of Element in Sorted Array
乘风破浪:LeetCode真题_034_Find First and Last Position of Element in Sorted Array 一.前言 这次我们还是要改造二分搜索,但是想法却 ...
- laravel扩展推荐
1. Intervention/image 图片处理 2.Laravel User Agent 轻松识别客户端信息 3.OAuth 2.0 支持 4.页面面包屑工具 5.计划任务分发器(直接可替换掉 ...
- ICC2 常用命令
1. 关于 data preparation : report_ref_libs : report reference library report_lib lib_aa : report the ...
- Vim2.1-Vim简明教程【CoolShell】【非原创】
vim的学习曲线相当的大(参看各种文本编辑器的学习曲线),所以,如果你一开始看到的是一大堆VIM的命令分类,你一定会对这个编辑器失去兴趣的.下面的文章翻译自<Learn Vim Progress ...
- day11有参装饰器,无参装饰器
今日内容 1.有参装饰器 2.无参装饰器 什么是装饰器? 用来为被装饰对象添加新功能的工具. 注:装饰器可以是任意可调用对象,被装饰对象也可以是任意可调用对象. 为何要用装饰器? 开放封闭原则:对修改 ...
- windows linux hosts文件的配置,开发项目中域名跳转等。
我们通常都知道Windows中hosts文件(C:\Windows\System32\drivers\etc),用来映射域名的.linux上当然也有,一般在/etc/hosts下. 当工作的项目,在开 ...