GBDT多分类示例
相当于每次都是用2分类,然后不停的训练,最后把所有的弱分类器来进行汇总
| 样本编号 | 花萼长度(cm) | 花萼宽度(cm) | 花瓣长度(cm) | 花瓣宽度 | 花的种类 |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | 山鸢尾 |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | 山鸢尾 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 | 杂色鸢尾 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 | 杂色鸢尾 |
| 5 | 6.3 | 3.3 | 6.0 | 2.5 | 维吉尼亚鸢尾 |
| 6 | 5.8 | 2.7 | 5.1 | 1.9 | 维吉尼亚鸢尾 |
Iris数据集
这是一个有6个样本的三分类问题。我们需要根据这个花的花萼长度,花萼宽度,花瓣长度,花瓣宽度来判断这个花属于山鸢尾,杂色鸢尾,还是维吉尼亚鸢尾。具体应用到gbdt多分类算法上面。我们用一个三维向量来标志样本的label。[1,0,0] 表示样本属于山鸢尾,[0,1,0] 表示样本属于杂色鸢尾,[0,0,1] 表示属于维吉尼亚鸢尾。
gbdt 的多分类是针对每个类都独立训练一个 CART Tree。所以这里,我们将针对山鸢尾类别训练一个 CART Tree 1。杂色鸢尾训练一个 CART Tree 2 。维吉尼亚鸢尾训练一个CART Tree 3,这三个树相互独立。
我们以样本 1 为例。针对 CART Tree1 的训练样本是[5.1,3.5,1.4,0.2],label 是 1,最终输入到模型当中的为[5.1,3.5,1.4,0.2,1]。针对 CART Tree2 的训练样本也是[5.1,3.5,1.4,0.2],但是label 为 0,最终输入模型的为[5.1,3.5,1.4,0.2,0]. 针对 CART Tree 3的训练样本也是[5.1,3.5,1.4,0.2],label 也为0,最终输入模型当中的为[5.1,3.5,1.4,0.2,0]。
下面我们来看 CART Tree1 是如何生成的,其他树 CART Tree2 , CART Tree 3的生成方式是一样的。CART Tree的生成过程是从这四个特征中找一个特征做为CART Tree1 的节点。比如花萼长度做为节点。6个样本当中花萼长度 大于5.1 cm的就是 A类,小于等于 5.1 cm 的是B类。生成的过程其实非常简单,问题 1.是哪个特征最合适? 2.是这个特征的什么特征值作为切分点? 即使我们已经确定了花萼长度做为节点。花萼长度本身也有很多值。在这里我们的方式是遍历所有的可能性,找到一个最好的特征和它对应的最优特征值可以让当前式子的值最小。
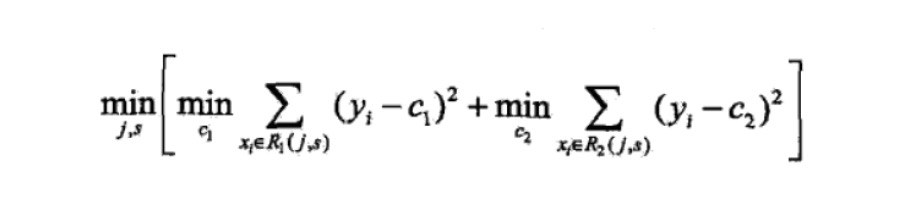
我们以第一个特征的第一个特征值为例。R1 为所有样本中花萼长度小于 5.1 cm 的样本集合,R2 为所有样本当中花萼长度大于等于 5.1cm 的样本集合。所以 R1={2},R2={1,3,4,5,6}.
y1 为 R1 所有样本的label 的均值 1/1=11/1=1。y2 为 R2 所有样本的label 的均值 (1+0+0+0+0)/5=0.2(1+0+0+0+0)/5=0.2。
下面便开始针对所有的样本计算这个式子的值。样本1 属于 R2 计算的值为(1−0.2)2, 样本2 属于R1 计算的值为(1−1)2(1−1)2, 样本 3,4,5,6同理都是 属于 R2的 所以值是(0−0.2)2. 把这六个值加起来,便是 山鸢尾类型在特征1 的第一个特征值的损失值。这里算出来(1-0.2)2+ (1-1)2 + (0-0.2)2+(0-0.2)2+(0-0.2)2 +(0-0.2)2= 0.84
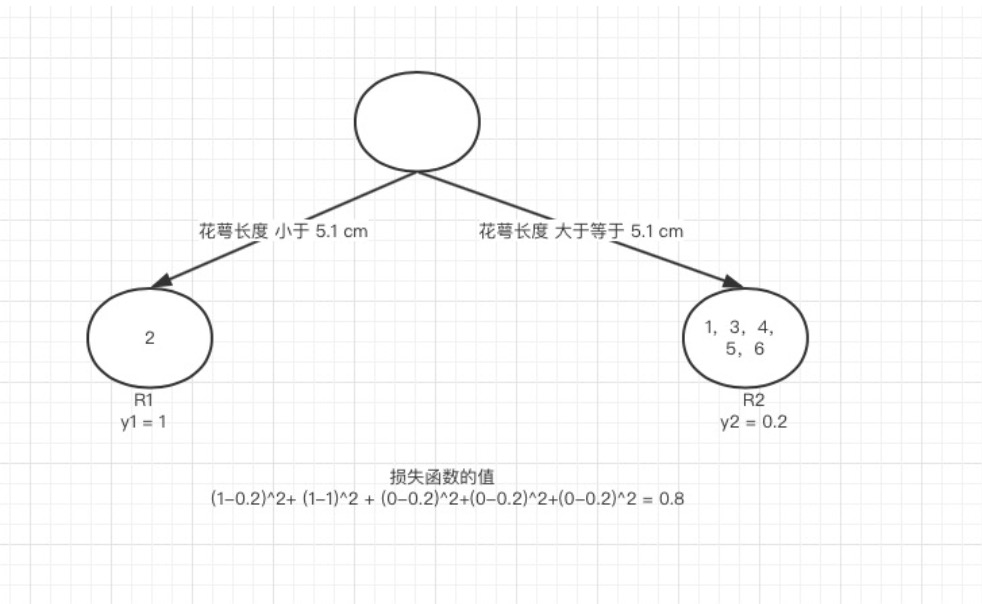
接着我们计算第一个特征的第二个特征值,计算方式同上,R1 为所有样本中 花萼长度小于 4.9 cm 的样本集合,R2 为所有样本当中 花萼长度大于等于 4.9 cm 的样本集合.所以 R1={},R1={1,2,3,4,5,6}. y1 为 R1 所有样本的label 的均值 = 0。y2 为 R2 所有样本的label 的均值 (1+1+0+0+0+0)/6=0.3333。
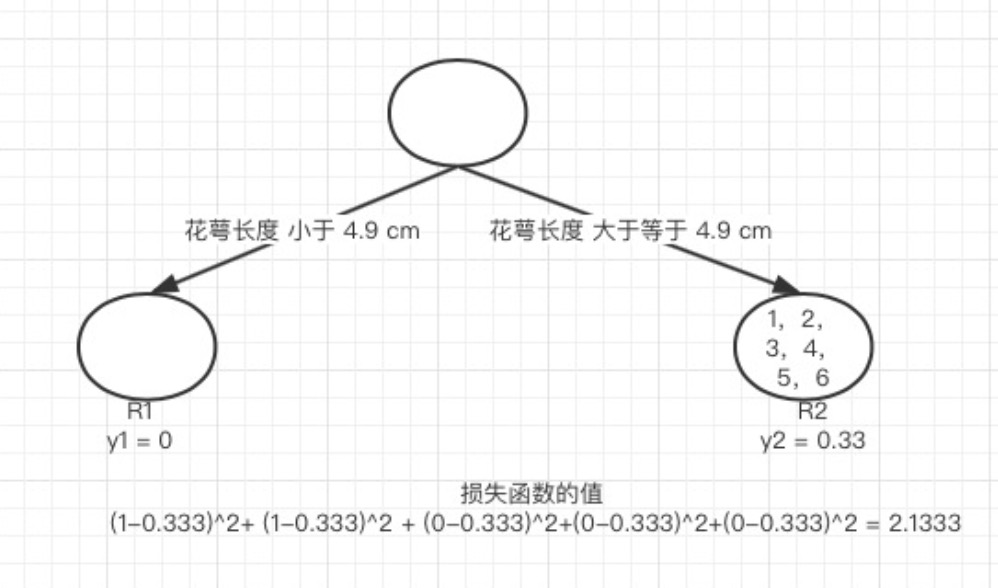
我们需要针对所有的样本,样本1 属于 R2, 计算的值为(1−0.333)2, 样本2 属于R2 ,计算的值为(1−0.333)2, 样本 3,4,5,6同理都是 属于 R2的, 所以值是(0−0.333)2. 把这六个值加起来山鸢尾类型在特征1 的第二个特征值的损失值。这里算出来 (1-0.333)^2+ (1-0.333)^2 + (0-0.333)^2+(0-0.333)^2+(0-0.333)^2 +(0-0.333)^2 = 2.244189. 这里的损失值大于 特征一的第一个特征值的损失值,所以我们不取这个特征的特征值。
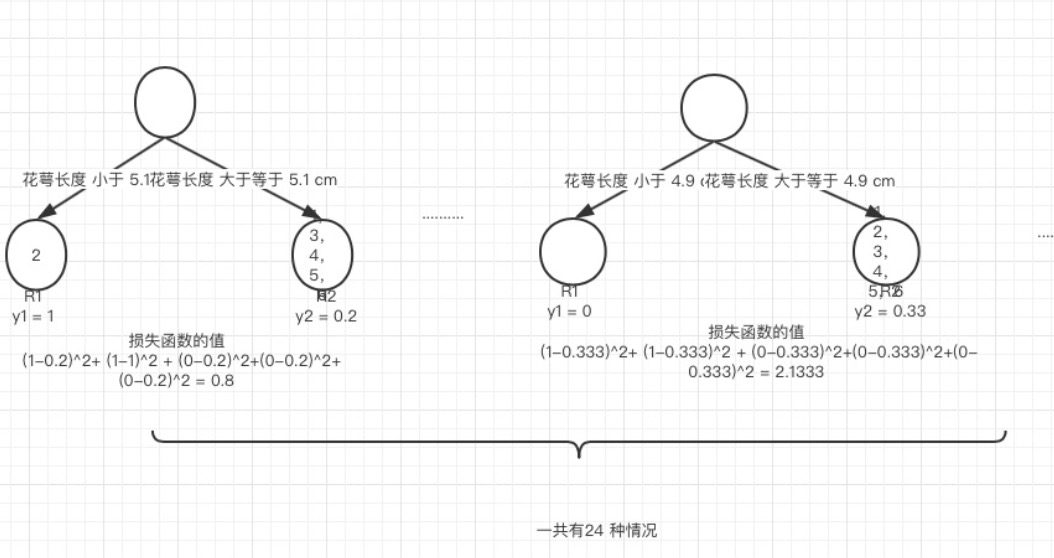
这样我们可以遍历所有特征的所有特征值,找到让这个式子最小的特征以及其对应的特征值,一共有24种情况,4个特征*每个特征有6个特征值。在这里我们算出来让这个式子最小的特征花萼长度,特征值为5.1 cm。这个时候损失函数最小为 0.8。
于是我们的预测函数此时也可以得到:
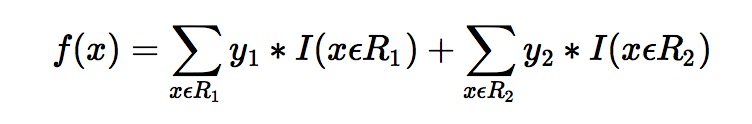
此处 R1 = {2},R2 = {1,3,4,5,6},y1 = 1,y2 = 0.2。训练完以后的最终式子为

借由这个式子,我们得到对样本属于类别1 的预测值 f1(x)=1+0.2∗5=2f1(x)=1+0.2∗5=2。同理我们可以得到对样本属于类别2,3的预测值f2(x)f2(x),f3(x)f3(x).样本属于类别1的概率 即为

GBDT多分类示例的更多相关文章
- GBDT用于分类问题
一.简介 GBDT在传统机器学习算法里面是对真实分布拟合的最好的几种算法之一,在前几年深度学习还没有大行其道之前,gbdt在各种竞赛是大放异彩.原因大概有几个 一:效果确实挺不错. 二:既可以用于分类 ...
- 机器学习 | 详解GBDT在分类场景中的应用原理与公式推导
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第31篇文章,我们一起继续来聊聊GBDT模型. 在上一篇文章当中,我们学习了GBDT这个模型在回归问题当中的原理.GBD ...
- Keras lstm 文本分类示例
#基于IMDB数据集的简单文本分类任务 #一层embedding层+一层lstm层+一层全连接层 #基于Keras 2.1.1 Tensorflow 1.4.0 代码: '''Trains an LS ...
- gbdt在回归方面的基本原理以及实例并且可以做分类
对书法的热爱,和编译器打数学公式很艰难,就这样的正例自己学过的东西,明天更新gbdt在分类方面的应用. 结论,如果要用一个常量来预测y,用log(sum(y)/sum(1-y))是一个最佳的选择. 本 ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- 梯度提升树(GBDT)原理小结
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting De ...
- GBDT的基本原理
这里以二元分类为例子,给出最基本原理的解释 GBDT 是多棵树的输出预测值的累加 GBDT的树都是 回归树 而不是分类树 分类树 分裂的时候选取使得误差下降最多的分裂 计算的技巧 最终分裂收益按照下面 ...
- GBDT基本理论及利用GBDT组合特征的具体方法(收集的资料)
最近两天在学习GBDT,看了一些资料,了解到GBDT由很多回归树构成,每一棵新回归树都是建立在上一棵回归树的损失函数梯度降低的方向. 以下为自己的理解,以及收集到的觉着特别好的学习资料. 1.GBDT ...
- Ensemble Learning 之 Gradient Boosting 与 GBDT
之前一篇写了关于基于权重的 Boosting 方法 Adaboost,本文主要讲述 Boosting 的另一种形式 Gradient Boosting ,在 Adaboost 中样本权重随着分类正确与 ...
随机推荐
- delphi中如何控制listview的每行的颜色
我们可以设定一个字段的值,用以判断用什么颜色显示listview的颜色,例子如下 procedure TMainForm.ListView2CustomDrawItem(Sender: TCustom ...
- JS里关于特殊字符的转义
重定向的url里含有百分号“%”,遇到了apache 找不到该文件的报错.通过查询相关文档,知道了原来是url里含有特殊字符要转码才能定位到正确的地址.比如"%"要转码为" ...
- 【mysql】使用Navicat连接数据库
1 连接数据库 点击左下角测试一下 提示 输入 select host,user,plugin,authentication_string from mysql.user; 查看用户信息 注意这里我们 ...
- 【Cocos2d-Js实战教学(1)横版摇杆八方向移动】
本教程主要通过搭建一个横版摇杆八方向移动的实例,让大家如何用Cocos2dx-Js来做一款游戏,从基础了解Cocos2dx-Js的基本实现原理,从创建工程,到各个知识点的梳理. 教程分为上下两讲: 上 ...
- Redirect与Transfer 的区别
共同点: 都是重定向: 不同点: redirect: 1发生在客户端: 2.发送两次请求,第一次请求原始页面,当调用此方法时,创建一个应答头,返回状态码302,第二次请求重定向的页面: 3.得不到任何 ...
- 面向对象进阶-类的内置方法 __str__ 、__repr__、__len__、__del__、__call__(三)
# 内置的类方法 和 内置的函数之间有着千丝万缕的联系# 双下方法# obj.__str__ str(obj)# obj.__repr__ repr(obj) # def __str__(self): ...
- docker 运行容器,安装Nginx
########################################## #运行容器 #安装Nginx #搜索.下载镜像 docker search nginx docker pull n ...
- 5.python内置函数详解
内置函数 声明,转载至这位大哥,感谢之至 http://blog.csdn.net/oaa608868/article/details/53506188 关于分类 数学运算(7个) 类型转换(24个) ...
- hello lua
http://manual.luaer.cn/ http://www.lua.org/pil/contents.html #include <cstdio> #include <st ...
- php主要用于哪几方面
1,服务端脚本,网站和web应用程序,web服务器,php解析器,web浏览器 2,命令行脚本 3,编写桌面应用程序