python---RabbitMQ(5)消息RPC(远程过程调用)
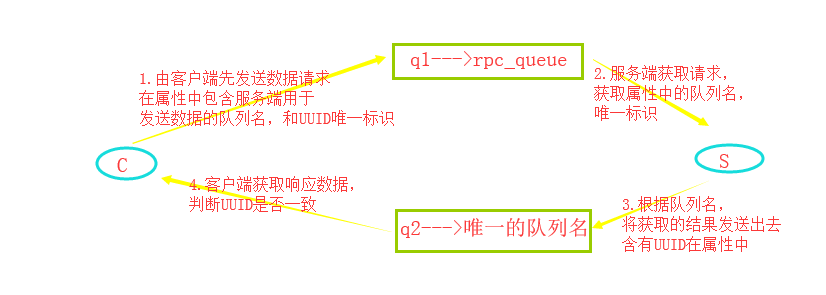
服务器端:
import pika #创建socket
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) #获取通道
channel = connection.channel() #生成队列
channel.queue_declare(queue='rpc_queue') def fib(n):
'''用于获取斐波那契数列'''
if n == :
return
elif n == :
return
else:
return fib(n - ) + fib(n - ) def on_request(ch, method, props, body):
'''获取数据的回调函数'''
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n) ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id= \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag) #设置为空闲的客户端减少压力
channel.basic_qos(prefetch_count=)
#预备开始消费
channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests")
#开始消费,从客户端获取
channel.start_consuming()
客户端:
import pika
import uuid class FibonacciRpcClient(object):
def __init__(self):
#生成socket连接
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#生成管道连接
self.channel = self.connection.channel()
#获取一个唯一队列名
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
#预备消费,设置回调函数,队列名
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
#注意,在这里不使用start_consuming去获取数据,因为这样会堵塞再这里,我们使用了另一种方法self.connection.process_data_events()
def on_response(self, ch, method, props, body):
print("on_response")
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
#生成一个唯一标识符
self.corr_id = str(uuid.uuid4())
#先向服务器端发送数据,传递属性有:唯一队列名和唯一标识符
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
while self.response is None:
print("process_data_events start")
self.connection.process_data_events()
print("process_data_events end")
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call()
print(" [.] Got %r" % response)
注意:
self.connection.process_data_events()会去队列中获取处理数据事件,当数据来临的时候,会直接去调用回调函数去处理数据
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start #事件到来
on_response #调用回调函数去处理数据
process_data_events end #事件结束
[.] Got
python---RabbitMQ(5)消息RPC(远程过程调用)的更多相关文章
- rabbitmq(中间消息代理)在python中的使用
在之前的有关线程,进程的博客中,我们介绍了它们各自在同一个程序中的通信方法.但是不同程序,甚至不同编程语言所写的应用软件之间的通信,以前所介绍的线程.进程队列便不再适用了:此种情况便只能使用socke ...
- [译]RabbitMQ教程C#版 - 远程过程调用(RPC)
先决条件 本教程假定 RabbitMQ 已经安装,并运行在localhost标准端口(5672).如果你使用不同的主机.端口或证书,则需要调整连接设置. 从哪里获得帮助 如果您在阅读本教程时遇到困难, ...
- rabbitmq系列五 之远程过程调用(RPC)
1.远程过程调用(RPC) 在第二篇教程中我们介绍了如何使用工作队列(work queue)在多个工作者(woker)中间分发耗时的任务. 可是如果我们需要将一个函数运行在远程计算机上并且等待从那儿获 ...
- .Net RabbitMQ之消息通信 构建RPC服务器
1.消息投递服务 RabbitMQ是一种消息投递服务,怎么理解这句话呢?即RabbitMQ即不是消息的生产者,也是消息的消费者.他就像现实生活中快递模式,消费者在电商网站上下单买了一件商品,此时对应的 ...
- Python RabbitMQ消息队列
python内的队列queue 线程 queue:不同线程交互,不能夸进程 进程 queue:只能用于父进程与子进程,或者同一父进程下的多个子进程,进行交互 注:不同的两个独立进程是不能交互的. ...
- 【python】-- RabbitMQ 队列消息持久化、消息公平分发
RabbitMQ 队列消息持久化 假如消息队列test里面还有消息等待消费者(consumers)去接收,但是这个时候服务器端宕机了,这个时候消息是否还在? 1.队列消息非持久化 服务端(produc ...
- Python之路-python(rabbitmq、redis)
一.RabbitMQ队列 安装python rabbitMQ module pip install pika or easy_install pika or 源码 https://pypi.pytho ...
- python RabbitMQ队列/redis
RabbitMQ队列 rabbitMQ是消息队列:想想之前的我们学过队列queue:threading queue(线程queue,多个线程之间进行数据交互).进程queue(父进程与子进程进行交互或 ...
- Python—RabbitMQ
RabbitMQ RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统 安装 因为RabbitMQ由erlang实现,先安装erlang #安装配置epel源 rpm -ivh http ...
- twsited(5)--不同模块用rabbitmq传递消息
上一章,我们讲到,用redis共享数据,以及用redis中的队列来实现一个简单的消息传递.其实在真实的过程中,不应该用redis来传递,最好用专业的消息队列,我们python中,用到最广泛的就是rab ...
随机推荐
- Chapter 5 软件工程中的形式化方法
从广义上讲,形式化方法是指将离散数学的方法用于解决软件工程领域的问题,主要包括建立精确的数学模型以及对模型的分析活动.狭义的讲,形式化方法是运用形式化语言,进行形式化的规格描述.模型推理和验证的方法. ...
- 四则运算App--大总结(已完成)
1. 贡献分分配(20分) 欧泽波:14分,Android的学习,代码的编写,等等 杨洁华:1分,提供学习资料,框架的设计等等 赵泽嘉:3分,提供学习资料,框架的设计等等 林扬滨:2分,提供学习资料, ...
- 将通过<input type="file">上传的txt文件存储在localStorage,提取并构建File对象
参考博文: JS 之Blob 对象类型 在本地存储localStorage中保存图片和文件 <input type="file" id="jobData" ...
- NodeJs异步的执行过程
我这里写了一个代码片段,用来模拟一个嵌套的异步过程,下面我总结了下这段代码的执行顺序var fs = require("fs"); fs.stat('a.txt',callback ...
- ASP.NET MVC 5.0 参考源码索引
http://www.projky.com/asp.netmvc/5.0/Microsoft/AspNet/Mvc/Facebook/FacebookAppSettingKeys.cs.htmlhtt ...
- 软工网络15团队作业8——敏捷冲刺日志的集合贴(Beta阶段)
Beta阶段 第 1 篇 Scrum 冲刺博客 第 2 篇 Scrum 冲刺博客 第 3 篇 Scrum 冲刺博客 第 4 篇 Scrum 冲刺博客 第 5 篇 Scrum 冲刺博客 第 6 篇 Sc ...
- 用go实现的一个堆得数据结构
用golang实现的堆,主要提供了两个方法,push和pop及堆的大小,代码如下: package main import ( "errors" "fmt" ) ...
- JS 字符串切割成数组
var cheLin = "字*符*串" // console.log(cheLin) var array = cheLin.split("*"); arra ...
- 对synchronized的一点理解
一.synchronized的使用(一).synchronized同步方法1. “非线程安全”问题存在于“实例变量”中,如果是方法内部的私有变量,则不存在“非线程安全”问题.2. 如果多个线程共同访问 ...
- Python 字节码是什么
了解 Python 字节码是什么,Python 如何使用它来执行你的代码,以及知道它是如何帮到你的. 如果你曾经编写过 Python,或者只是使用过 Python,你或许经常会看到 Python 源代 ...