【Coursera-ML-Notes】线性回归(上)
什么是机器学习
关于机器学习,有以下两种不同的定义。
机器学习是研究如何使电脑具备学习能力,而不用显式编程告诉它该怎么做。
the field of study that gives computers the ability to learn without being explicitly programmed.
机器学习能够使电脑程序从以往的经验(E)中学习并改善自己,从而在处理新的任务(T)时提升它的性能(P)。
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
这里针对第二种定义举个例子:下围棋
E:程序模拟人类下很多盘棋所积累的经验
T:下围棋这个任务
P:程序赢得下次比赛的几率
模型表示
假定我们现有一大批数据,包含房屋的面积和对应面积的房价信息,如果我们能得到房屋面积与房屋价格间的关系,那么,给定一个房屋时,我们只要知道其面积,就能大致推测出其价格了。
以这个问题为例,可以建立一个回归模型,首先明确几个常用的数学符号:
输入变量:\(x^{(i)}\),也叫做输入特征,如这个例子中的面积
输出变量:\(y^{(i)}\),也叫做目标变量,如例子中的我们需要预测的房价
训练样本:\((x^{(i)},y^{(i)})\)是输入变量和输出变量称为一组训练样本
训练集(Training set):\(i=1,...,m\),这么多组训练样本构成训练集
假设(hypothesis):也称预测函数,比如例子中可以建立这样一个线性函数:
\[
h_θ(x)=θ_0+θ_1x_1
\]
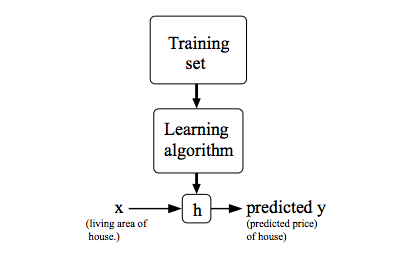
我们的目标是找到满足这样一个线性函数来拟合训练集中的数据,那么,给定一个房屋时,我们只要知道其面积,就能大致推测出其价格了。这个过程可以用下图来表示:

代价函数
有了模型,我们还需要评估模型的准确性。于是代价函数就被引进,它也叫做平方误差函数。
\[
J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2
\]
可以看出,代价函数是采取预测值和真实值差值的平方和取均值的方式来评估数据的拟合程度的,代价函数的值越小,表示模型对于数据的拟合程度越高。
梯度下降
有了模型和评价模型的方式,现在我们要确定模型中的参数\(\theta_0\)和\(\theta_1\),以找到最好的模型。
以\(\theta_0\)为\(x\)轴,\(\theta_1\)为\(y\)轴,代价函数\(J(\theta)\)为\(z\)轴,建立三维坐标系,可以得到如下图所示的图像:
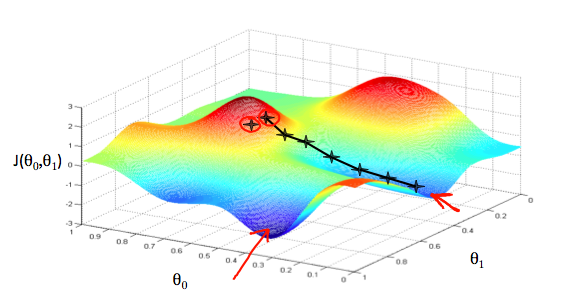
如果把这个图像看作是一座山的话,我们有一个起点\((\theta_0,\theta_1,J(\theta_0,\theta_1))\),现在要从这个点找到一条最快的路径到达山脚下,数学上来说,梯度是最陡峭的方向,所以我们要始终沿着梯度的方向走。
学习率
方向已经确定,但是往这个方向前进的距离是多少呢?这个距离由学习率\(\alpha\)来确定。有了方向和步距,那么\(\theta_0、\theta_1\)的变化规律如下:

那么怎么样确定学习率\(\alpha\)(步距)呢?
如果步距过大,可能接近收敛的时候会越过收敛点,甚至最终无法收敛。
如果步距过小,收敛所花的时间会很久。
所以我们要调节\(\alpha\)的大小,使收敛时间在一个合理的范围里。
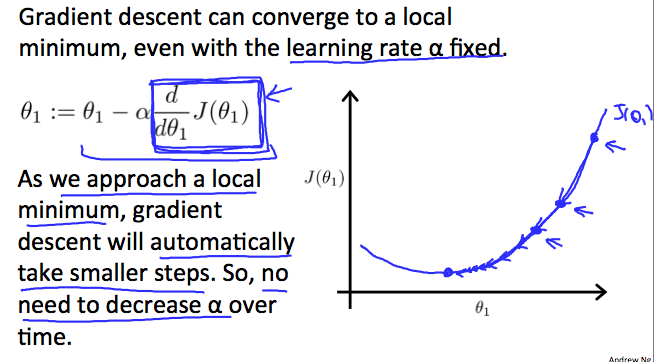
在每一次迭代过程中,需要改变\(\alpha\)的大小吗?如果不需要的话,接近收敛时,会不会因为步距偏大而越过收敛点?
在迭代过程中不需要改变\(\alpha\)的大小,因为接近收敛点时,梯度(斜率)会变小,等价于步距在自动变小,所以没有必要减小\(\alpha\)。
最后,为什么代价函数的表达式中为什么取均值的除数是\(2m\)而不是\(m\)?
我们来看一看参数每一次的迭代过程都发生了什么?
\[
\begin{equation}
θ_0:=θ_0-a\frac{∂}{∂θ_0}J(θ_0,θ_1)
\end{equation}
\]
对上式化简,
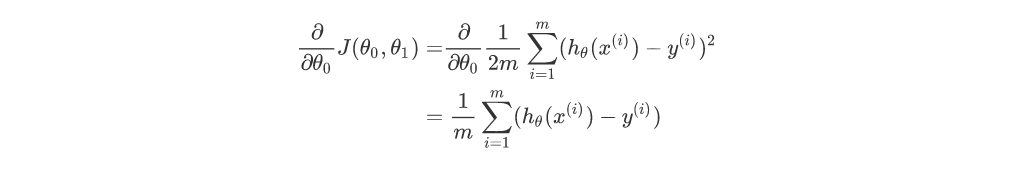
因此,
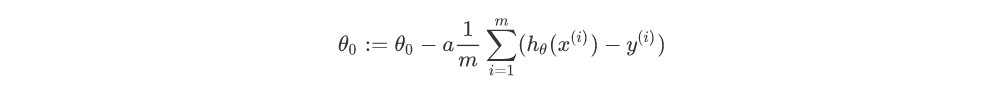
所以取2m的原因其实是为了求导数时化简方便,可以和平方项的2约掉。
【Coursera-ML-Notes】线性回归(上)的更多相关文章
- Coursera ML笔记 - 神经网络(Representation)
前言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自Standford Andrew N ...
- (转载)[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation
[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation http://blog.csdn.net/walilk/articl ...
- [机器学习] Coursera ML笔记 - 逻辑回归(Logistic Regression)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等.主要学习资料来自Standford Andrew N ...
- 如何应用ML的建议-上
本博资料来自andrew ng的13年的ML视频中10_X._Advice_for_Applying_Machine_Learning. 遇到问题-部分(一) 错误统计-部分(二) 正确的选取数据集- ...
- 批量下载Coursera及其他场景上的文件
以下方法同样适用于其他场景的批量下载. 最近在学习Coursera退出的深度学习课程,我希望把课程提供的作业下载下来以备以后复习,但是课程有很多文件,比如说脸部识别一课中的参数就多达226个csv文件 ...
- ml的线性回归应用(python语言)
线性回归的模型是:y=theta0*x+theta1 其中theta0,theta1是我们希望得到的系数和截距. 下面是代码实例: 1. 用自定义数据来看看格式: # -*- coding:utf ...
- ML:多变量线性回归(Linear Regression with Multiple Variables)
引入额外标记 xj(i) 第i个训练样本的第j个特征 x(i) 第i个训练样本对应的列向量(column vector) m 训练样本的数量 n 样本特征的数量 假设函数(hypothesis fun ...
- Coursera连接不上(视频无法播放),修改hosts文件
视频问题 如果Coursera网站连接不上,或者视频加载不出来.可以通过如下方式进行配置: 一.找到hosts文件 Windows 系统, hosts文件位于: [C:\Windows\Syste ...
- 贝叶斯线性回归(Bayesian Linear Regression)
贝叶斯线性回归(Bayesian Linear Regression) 2016年06月21日 09:50:40 Duanxx 阅读数 54254更多 分类专栏: 监督学习 版权声明:本文为博主原 ...
- 机器学习之单变量线性回归(Linear Regression with One Variable)
1. 模型表达(Model Representation) 我们的第一个学习算法是线性回归算法,让我们通过一个例子来开始.这个例子用来预测住房价格,我们使用一个数据集,该数据集包含俄勒冈州波特兰市的住 ...
随机推荐
- 接口自动化平台github开源项目Django
https://github.com/githublitao/api_automation_test
- jQuery----事件绑定之动态添加、删除table行
在jquery中,给元素绑定事件,本文一共介绍三种方法,运用案例,针对最常用的on()方法,进行事件绑定操作. 事件绑定方法: ①$(element).bind() 参数:{ “事件名称1”:func ...
- 关于Linux的交叉编译环境配置中的问题
Linux的交叉编译arm-linux-gcc搭建时,安装结束却无法查看版本.输入以下命令查看Ubuntu的版本: uname -a 可以看到此Ubuntu为64位16.04.1版本,所以需要下载32 ...
- 数据结构与算法之Stack(栈)的应用——in dart
参考教科书上的一个应用例子,用栈来分析一行输入中的括号brackets是否匹配.用stdin读取用户输入,并输出检查结果.exit 退出. 注意这行代码: import 'stack.dart';// ...
- JavaWeb基础—XML学习小结
一.概述 是什么? 指可扩展标记语言 能干什么? 传输和存储数据 怎么干? 需要自行定义标签. XML 独立于硬件.软件以及应用程序 通常.建立完xml文件后首要的任务是:引入约束文件! 二.XML简 ...
- JavaWeb基础—项目名的写法
${pageContext.request.contextPath} //jsp中 request.getContextPath() //Servlet中 两者获取到的都是"/项目名称&qu ...
- 20155237 2016-2017-2 《Java程序设计》第1周学习总结
20155237 2016-2017-2 <Java程序设计>第一周学习总结 一.认真学习考核方式,理解成绩构成 考核方式 首先由100分构成:课堂考核12次,实验5次,团队项目(每周进度 ...
- 20145207 Exp9 web安全基础实践
Exp9 web安全基础实践 实验后回答问题 (1)SQL注入攻击原理,如何防御 攻击原理:修改信息 防御:禁止输入 (2)XSS攻击的原理,如何防御 攻击原理:看别人的博客,感觉就是强制访问. 防御 ...
- Noip前的大抱佛脚----图论
目录 图论 知识点 二分图相关 DFS找环 并查集维护二分图 二分图匹配的不可行边 最小生成树相关 最短路树 最短路相关 负环 多源最短路 差分约束系统 01最短路 k短路 网络流 zkw费用流 做题 ...
- python基础学习1-双层装饰器(实现登陆注册)
LOGIN_USER = {"IsLogin":False} def check_login(func): #检查登陆的装饰器 def inner(*args,**kwargs): ...