集合(二)LinkedList
上一篇中讲解了ArrayList,本篇文章讲解一下LinkedList的实现。
LinkedList是基于链表实现的,所以先讲解一下什么是链表。链表原先是C/C++的概念,是一种线性的存储结构,意思是将要存储的数据存在一个存储单元里面,这个存储单元里面除了存放有待存储的数据以外,还存储有其下一个存储单元的地址(下一个存储单元的地址是必要的,有些存储结构还存放有其前一个存储单元的地址),每次查找数据的时候,通过某个存储单元中的下一个存储单元的地址寻找其后面的那个存储单元。
这么讲可能有点抽象,先提一句,LinkedList是一种双向链表,双向链表我认为有两点含义:
1、链表中任意一个存储单元都可以通过向前或者向后寻址的方式获取到其前一个存储单元和其后一个存储单元
2、链表的尾节点的后一个节点是链表的头结点,链表的头结点的前一个节点是链表的尾节点
LinkedList既然是一种双向链表,必然有一个存储单元,看一下LinkedList的基本存储单元,它是LinkedList中的一个内部类:
private static class Entry<E> {
E element;
Entry<E> next;
Entry<E> previous;
...
}
看到LinkedList的Entry中的"E element",就是它真正存储的数据。"Entry<E> next"和"Entry<E> previous"表示的就是这个存储单元的前一个存储单元的引用地址和后一个存储单元的引用地址。用图表示就是:

四个关注点在LinkedList上的答案
| 关 注 点 | 结 论 |
| LinkedList是否允许空 | 允许 |
| LinkedList是否允许重复数据 | 允许 |
| LinkedList是否有序 | 有序 |
| LinkedList是否线程安全 | 非线程安全 |
添加元素
首先看下LinkedList添加一个元素是怎么做的,假如我有一段代码:
1 public static void main(String[] args)
2 {
3 List<String> list = new LinkedList<String>();
4 list.add("111");
5 list.add("222");
6 }
逐行分析main函数中的三行代码是如何执行的,首先是第3行,看一下LinkedList的源码:
1 public class LinkedList<E>
2 extends AbstractSequentialList<E>
3 implements List<E>, Deque<E>, Cloneable, java.io.Serializable
4 {
5 private transient Entry<E> header = new Entry<E>(null, null, null);
6 private transient int size = 0;
7
8 /**
9 * Constructs an empty list.
10 */
11 public LinkedList() {
12 header.next = header.previous = header;
13 }
14 ...
15 }
看到,new了一个Entry出来名为header,Entry里面的previous、element、next都为null,执行构造函数的时候,将previous和next的值都设置为header的引用地址,还是用画图的方式表示。32位JDK的字长为4个字节,而目前64位的JDK一般采用的也是4字长,所以就以4个字长为单位。header引用地址的字长就是4个字节,假设是0x00000000,那么执行完"List<String> list = new LinkedList<String>()"之后可以这么表示:

接着看第4行add一个字符串"111"做了什么:
1 public boolean add(E e) {
2 addBefore(e, header);
3 return true;
4 }
1 private Entry<E> addBefore(E e, Entry<E> entry) {
2 Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
3 newEntry.previous.next = newEntry;
4 newEntry.next.previous = newEntry;
5 size++;
6 modCount++;
7 return newEntry;
8 }
第2行new了一个Entry出来,可能不太好理解,根据Entry的构造函数,我把这句话"翻译"一下,可能就好理解了:
1、newEntry.element = e;
2、newEntry.next = header.next;
3、newEntry.previous = header.previous;
header.next和header.previous上图中已经看到了,都是0x00000000,那么假设new出来的这个Entry的地址是0x00000001,继续画图表示:
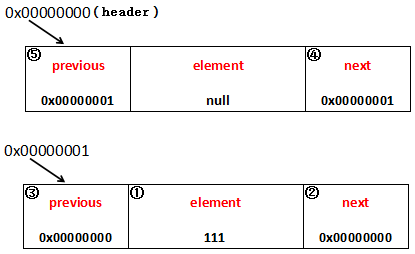
一共五步,每一步的操作步骤都用数字表示出来了:
1、新的entry的element赋值为111;
2、新的entry的next是header的next,header的next是0x00000000,所以新的entry的next即0x00000000;
3、新的entry的previous是header的previous,header的previous是0x00000000,所以新的entry的next即0x00000000;
4、"newEntry.previous.next = newEntry",首先是newEntry的previous,由于newEntry的previous为0x00000000,所以newEntry.previous表示的是header,header的next为newEntry,即header的next为0x00000001;
5、"newEntry.next.previous = newEntry",和4一样,把header的previous设置为0x00000001;
为什么要这么做?还记得双向链表的两个特点吗,一是任意节点都可以向前和向后寻址,二是整个链表头的previous表示的是链表的尾Entry,链表尾的next表示的是链表的头Entry。现在链表头就是0x00000000这个Entry,链表尾就是0x00000001,可以自己看图观察、思考一下是否符合这两个条件。
最后看一下add了一个字符串"222"做了什么,假设新new出来的Entry的地址是0x00000002,画图表示:

还是执行的那5步,图中每一步都标注出来了,只要想清楚previous、next各自表示的是哪个节点就不会出问题了。
至此,往一个LinkedList里面添加一个字符串"111"和一个字符串"222"就完成了。从这张图中应该理解双向链表比较容易:
1、中间的那个Entry,previous的值为0x00000000,即header;next的值为0x00000002,即tail,这就是任意一个Entry既可以向前查找Entry,也可以向后查找Entry
2、头Entry的previous的值为0x00000002,即tail,这就是双向链表中头Entry的previous指向的是尾Entry
3、尾Entry的next的值为0x00000000,即header,这就是双向链表中尾Entry的next指向的是头Entry
查看元素
看一下LinkedList的代码是怎么写的:
public E get(int index) {
return entry(index).element;
}
1 private Entry<E> entry(int index) {
2 if (index < 0 || index >= size)
3 throw new IndexOutOfBoundsException("Index: "+index+
4 ", Size: "+size);
5 Entry<E> e = header;
6 if (index < (size >> 1)) {
7 for (int i = 0; i <= index; i++)
8 e = e.next;
9 } else {
10 for (int i = size; i > index; i--)
11 e = e.previous;
12 }
13 return e;
14 }
这段代码就体现出了双向链表的好处了。双向链表增加了一点点的空间消耗(每个Entry里面还要维护它的前置Entry的引用),同时也增加了一定的编程复杂度,却大大提升了效率。
由于LinkedList是双向链表,所以LinkedList既可以向前查找,也可以向后查找,第6行~第12行的作用就是:当index小于数组大小的一半的时候(size >> 1表示size / 2,使用移位运算提升代码运行效率),向后查找;否则,向前查找。
这样,在我的数据结构里面有10000个元素,刚巧查找的又是第10000个元素的时候,就不需要从头遍历10000次了,向后遍历即可,一次就能找到我要的元素。
删除元素
看完了添加元素,我们看一下如何删除一个元素。和ArrayList一样,LinkedList支持按元素删除和按下标删除,前者会删除从头开始匹配的第一个元素。用按下标删除举个例子好了,比方说有这么一段代码:
1 public static void main(String[] args)
2 {
3 List<String> list = new LinkedList<String>();
4 list.add("111");
5 list.add("222");
6 list.remove(0);
7 }
也就是我想删除"111"这个元素。看一下第6行是如何执行的:
1 public E remove(int index) {
2 return remove(entry(index));
3 }
1 private E remove(Entry<E> e) {
2 if (e == header)
3 throw new NoSuchElementException();
4
5 E result = e.element;
6 e.previous.next = e.next;
7 e.next.previous = e.previous;
8 e.next = e.previous = null;
9 e.element = null;
10 size--;
11 modCount++;
12 return result;
13 }
当然,首先是找到元素在哪里,这和get是一样的。接着,用画图的方式来说明比较简单:
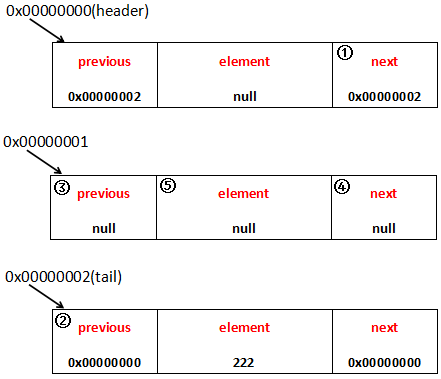
比较简单,只要找对引用地址就好了,每一步的操作也都详细标注在图上了。
这里我提一点,第3步、第4步、第5步将待删除的Entry的previous、element、next都设置为了null,这三步的作用是让虚拟机可以回收这个Entry。
但是,这个问题我稍微扩展深入一点:按照Java虚拟机HotSpot采用的垃圾回收检测算法----根节点搜索算法来说,即使previous、element、next不设置为null也是可以回收这个Entry的,因为此时这个Entry已经没有任何地方会指向它了,tail的previous与header的next都已经变掉了,所以这块Entry会被当做"垃圾"对待。之所以还要将previous、element、next设置为null,我认为可能是为了兼容另外一种垃圾回收检测算法----引用计数法,这种垃圾回收检测算法,只要对象之间存在相互引用,那么这块内存就不会被当作"垃圾"对待。
插入元素
插入元素就不细讲了,看一下删除元素的源代码:
public void add(int index, E element) {
addBefore(element, (index==size ? header : entry(index)));
}
private Entry<E> addBefore(E e, Entry<E> entry) {
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}
如果朋友们理解了前面的内容,我认为这两个方法对你来说,应该是很容易看懂的。
LinkedList和ArrayList的对比
老生常谈的问题了,这里我尝试以自己的理解尽量说清楚这个问题,顺便在这里就把LinkedList的优缺点也给讲了。
1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只要往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将new一个对象出来,如果对象比较大,那么new的时间势必会长一点,再加上一些引用赋值的操作,所以顺序插入LinkedList必然慢于ArrayList
2、基于上一点,因为LinkedList里面不仅维护了待插入的元素,还维护了Entry的前置Entry和后继Entry,如果一个LinkedList中的Entry非常多,那么LinkedList将比ArrayList更耗费一些内存
3、数据遍历的速度,看最后一部分,这里就不细讲了,结论是:使用各自遍历效率最高的方式,ArrayList的遍历效率会比LinkedList的遍历效率高一些
4、有些说法认为LinkedList做插入和删除更快,这种说法其实是不准确的:
(1)LinkedList做插入、删除的时候,慢在寻址,快在只需要改变前后Entry的引用地址
(2)ArrayList做插入、删除的时候,慢在数组元素的批量copy,快在寻址
所以,如果待插入、删除的元素是在数据结构的前半段尤其是非常靠前的位置的时候,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为它是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后面插入一个元素在效率上基本没有差别,但是ArrayList由于要批量copy的元素越来越少,操作速度必然追上乃至超过LinkedList。
从这个分析看出,如果你十分确定你插入、删除的元素是在前半段,那么就使用LinkedList;如果你十分确定你删除、删除的元素在比较靠后的位置,那么可以考虑使用ArrayList。如果你不能确定你要做的插入、删除是在哪儿呢?那还是建议你使用LinkedList吧,因为一来LinkedList整体插入、删除的执行效率比较稳定,没有ArrayList这种越往后越快的情况;二来插入元素的时候,弄得不好ArrayList就要进行一次扩容,记住,ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作,在我的文章Java代码优化中,第9点有详细的解读。
最后一点,一切都是纸上谈兵,在选择了List后,有条件的最好可以做一些性能测试,比如在你的代码上下文记录List操作的时间消耗。
对LinkedList以及ArrayList的迭代
在我的Java代码优化一文中,第19点,专门提到过,ArrayList使用最普通的for循环遍历,LinkedList使用foreach循环比较快,看一下两个List的定义:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
注意到ArrayList是实现了RandomAccess接口而LinkedList则没有实现这个接口,关于RandomAccess这个接口的作用,看一下JDK API上的说法:

为此,我写一段代码证明一下这一点,注意,虽然上面的例子用的Iterator,但是做foreach循环的时候,编译器默认会使用这个集合的Iterator,具体可参见foreach循环原理。测试代码如下:
public class TestMain
{
private static int SIZE = 111111; private static void loopList(List<Integer> list)
{
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++)
{
list.get(i);
}
System.out.println(list.getClass().getSimpleName() + "使用普通for循环遍历时间为" +
(System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis();
for (Integer i : list)
{ }
System.out.println(list.getClass().getSimpleName() + "使用foreach循环遍历时间为" +
(System.currentTimeMillis() - startTime) + "ms");
} public static void main(String[] args)
{
List<Integer> arrayList = new ArrayList<Integer>(SIZE);
List<Integer> linkedList = new LinkedList<Integer>(); for (int i = 0; i < SIZE; i++)
{
arrayList.add(i);
linkedList.add(i);
} loopList(arrayList);
loopList(linkedList);
System.out.println();
}
}
我截取三次运行结果:
ArrayList使用普通for循环遍历时间为6ms
ArrayList使用foreach循环遍历时间为12ms
LinkedList使用普通for循环遍历时间为38482ms
LinkedList使用foreach循环遍历时间为11ms
ArrayList使用普通for循环遍历时间为5ms
ArrayList使用foreach循环遍历时间为12ms
LinkedList使用普通for循环遍历时间为43287ms
LinkedList使用foreach循环遍历时间为9ms
ArrayList使用普通for循环遍历时间为4ms
ArrayList使用foreach循环遍历时间为12ms
LinkedList使用普通for循环遍历时间为22370ms
LinkedList使用foreach循环遍历时间为5ms
有了JDK API的解释,这个结果并不让人感到意外,最最想要提出的一点是:如果使用普通for循环遍历LinkedList,其遍历速度将慢得令人发指。
感谢原作:http://www.cnblogs.com/xrq730/p/5005347.html
集合(二)LinkedList的更多相关文章
- 【Java集合】LinkedList详解前篇
[Java集合]LinkedList详解前篇 一.背景 最近在看一本<Redis深度历险>的书籍,书中第二节讲了Redis的5种数据结构,其中看到redis的list结构时,作者提到red ...
- JDK集合框架--LinkedList
上一篇讲了ArrayList,它有一个"孪生兄弟"--LinkedList,这两个集合类总是经常会被拿来比较,今天就分析一下LinkedList,然后总结一下这俩集合类的不同 首先 ...
- Java自学-集合框架 LinkedList
Java集合框架 LinkedList 序列分先进先出FIFO,先进后出FILO FIFO在Java中又叫Queue 队列 FILO在Java中又叫Stack 栈 示例 1 : LinkedList ...
- 集合框架——LinkedList集合源码分析
目录 示例代码 底层代码 第1步(初始化集合) 第2步(往集合中添加一个元素) 第3步(往集合中添加第二个元素) 第4步(往集合中添加第三个元素) LinkedList添加元素流程示意图 第5步(删除 ...
- 集合总结二(LinkedList的实现原理)
一.概述 先来看看源码中的这一段注释,我们先尝试从中提取一些信息: Doubly-linked list implementation of the List and Deque interfaces ...
- 【源码阅读】Java集合之二 - LinkedList源码深度解读
Java 源码阅读的第一步是Collection框架源码,这也是面试基础中的基础: 针对Collection的源码阅读写一个系列的文章; 本文是第二篇LinkedList. ---@pdai JDK版 ...
- 集合之LinkedList源码分析
转载请注明出处:http://www.cnblogs.com/qm-article/p/8903893.html 一.介绍 在介绍该源码之前,先来了解一下链表,接触过数据结构的都知道,有种结构叫链表, ...
- 集合之LinkedList(含JDK1.8源码分析)
一.前言 LinkedList是基于链表实现的,所以先讲解一下什么是链表.链表原先是C/C++的概念,是一种线性的存储结构,意思是将要存储的数据存在一个存储单元里面,这个存储单元里面除了存放有待存储的 ...
- Java集合:LinkedList源码解析
Java集合---LinkedList源码解析 一.源码解析1. LinkedList类定义2.LinkedList数据结构原理3.私有属性4.构造方法5.元素添加add()及原理6.删除数据re ...
- Java集合(五)--LinkedList源码解读
首先看一下LinkedList基本源码,基于jdk1.8 public class LinkedList<E> extends AbstractSequentialList<E> ...
随机推荐
- Python—— *与** 参数说明
Python *与** 参数说明 '''*用来传递任意个无名字参数,这些参数会一个Tuple的形式访问''' def fall(*z): print sum(z) print "keys t ...
- org.springframework.stereotype 注解
org.springframework.stereotype 1.@controller 控制器(注入服务) 2.@service 服务(注入dao) 3.@repository dao(实现dao访 ...
- FastDFSClient工具类 文件上传下载
package cn.itcast.fastdfs.cliennt; import org.csource.common.NameValuePair; import org.csource.fastd ...
- codeblocks 更换颜色主题
关闭codeblocks,下载主题文件(colour_themes.conf).在关闭codeblocks的情况下,linux下的~/.config/codeblocks/下有个conf文件,将其备份 ...
- scanf与printf
scanf格式控制的完整格式: % * m l或h 格式字符 ①格式字符与printf函数中的使用方式相同,以%d.%o.%x.%c.%s.%f.%e,无%u格式.%g ...
- 早上突然看明白 shader和材质球的关系
计算机的世界不外乎 指令+数据 shader即Gpu指令,材质即数据
- 创建第一个Maven项目
-----------------------siwuxie095 创建第一个 Maven 项目 1.打开 Ec ...
- ios 点击Home问题
应用可以在后台运行或者挂起,该场景的状态跃迁过程见图2-22,共经历3个阶段4个状态:Active → Inactive → Background→Suspended. q 在Active→Ina ...
- 【校招面试 之 C/C++】第17题 C 中的malloc相关
1.malloc (1)原型:extern void *malloc(unsigned int num_bytes); 头文件:#include <malloc.h> 或 #include ...
- HttpApplicationState与HttpApplication
HttpApplicationState 类的单个实例在客户端第一次从某个特定的 ASP.NET 应用程序虚拟目录中请求任何 URL 资源时创建.对于 Web 服务器上的每个 ASP.NET 应用程序 ...