Hadoop HA 深度解析
社区hadoop2.2.0 release版本开始支持NameNode的HA,本文将详细描述NameNode HA内部的设计与实现。
为什么要Namenode HA?
1. NameNode High Availability即高可用。
2. NameNode 很重要,挂掉会导致存储停止服务,无法进行数据的读写,基于此NameNode的计算(MR,Hive等)也无法完成。
Namenode HA 如何实现,关键技术难题是什么?
1. 如何保持主和备NameNode的状态同步,并让Standby在Active挂掉后迅速提供服务,namenode启动比较耗时,包括加载fsimage和editlog(获取file to block信息),处理所有datanode第一次blockreport(获取block to datanode信息),保持NN的状态同步,需要这两部分信息同步。
2. 脑裂(split-brain),指在一个高可用(HA)系统中,当联系着的两个节点断开联系时,本来为一个整体的系统,分裂为两个独立节点,这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏。
3. NameNode切换对外透明,主Namenode切换到另外一台机器时,不应该导致正在连接的客户端失败,主要包括Client,Datanode与NameNode的链接。
社区NN的HA架构,实现原理,各部分的实现机制,解决了哪些问题?
1. 非HA的Namenode架构,一个HDFS集群只存在一个NN,DN只向一个NN汇报,NN的editlog存储在本地目录。
2. 社区NN HA的架构
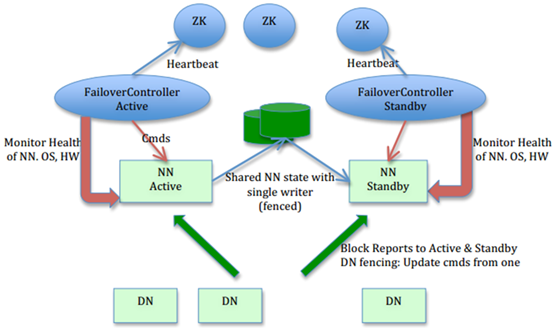
图1,NN HA架构(从社区复制)
社区的NN HA包括两个NN,主(active)与备(standby),ZKFC,ZK,share editlog。流程:集群启动后一个NN处于active状态,并提供服务,处理客户端和datanode的请求,并把editlog写到本地和share editlog(可以是NFS,QJM等)中。另外一个NN处于Standby状态,它启动的时候加载fsimage,然后周期性的从share editlog中获取editlog,保持与active的状态同步。为了实现standby在sctive挂掉后迅速提供服务,需要DN同时向两个NN汇报,使得Stadnby保存block to datanode信息,因为NN启动中最费时的工作是处理所有datanode的blockreport。为了实现热备,增加FailoverController和ZK,FailoverController与ZK通信,通过ZK选主,FailoverController通过RPC让NN转换为active或standby。
2.关键问题:
(1) 保持NN的状态同步,通过standby周期性获取editlog,DN同时想standby发送blockreport。
(2) 防止脑裂
共享存储的fencing,确保只有一个NN能写成功。使用QJM实现fencing,下文叙述原理。
datanode的fencing。确保只有一个NN能命令DN。HDFS-1972中详细描述了DN如何实现fencing
(a) 每个NN改变状态的时候,向DN发送自己的状态和一个序列号。
(b) DN在运行过程中维护此序列号,当failover时,新的NN在返回DN心跳时会返回自己的active状态和一个更大的序列号。DN接收到这个返回是认为该NN为新的active。
(c) 如果这时原来的active(比如GC)恢复,返回给DN的心跳信息包含active状态和原来的序列号,这时DN就会拒绝这个NN的命令。
(d) 特别需要注意的一点是,上述实现还不够完善,HDFS-1972中还解决了一些有可能导致误删除block的隐患,在failover后,active在DN汇报所有删除报告前不应该删除任何block。
客户端fencing,确保只有一个NN能响应客户端请求。让访问standby nn的客户端直接失败。在RPC层封装了一层,通过FailoverProxyProvider以重试的方式连接NN。通过若干次连接一个NN失败后尝试连接新的NN,对客户端的影响是重试的时候增加一定的延迟。客户端可以设置重试此时和时间。
ZKFC的设计
1. FailoverController实现下述几个功能
(a) 监控NN的健康状态
(b) 向ZK定期发送心跳,使自己可以被选举。
(c) 当自己被ZK选为主时,active FailoverController通过RPC调用使相应的NN转换为active。
2. 为什么要作为一个deamon进程从NN分离出来
(1) 防止因为NN的GC失败导致心跳受影响。
(2) FailoverController功能的代码应该和应用的分离,提高的容错性。
(3) 使得主备选举成为可插拔式的插件。
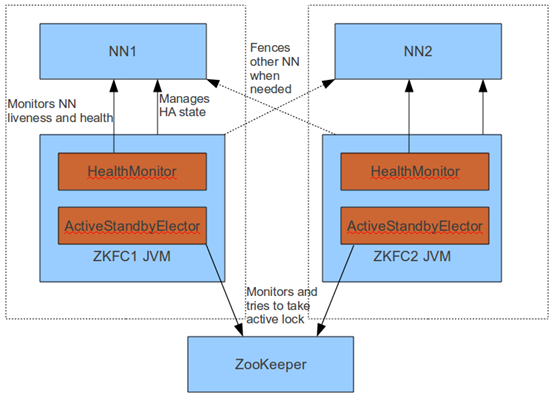
图2 FailoverController架构(从社区复制)
3. FailoverController主要包括三个组件,
(1) HealthMonitor 监控NameNode是否处于unavailable或unhealthy状态。当前通过RPC调用NN相应的方法完成。
(2) ActiveStandbyElector 管理和监控自己在ZK中的状态。
(3) ZKFailoverController 它订阅HealthMonitor 和ActiveStandbyElector 的事件,并管理NameNode的状态。
QJM的设计
- Namenode记录了HDFS的目录文件等元数据,客户端每次对文件的增删改等操作,Namenode都会记录一条日志,叫做editlog,而元数据存储在fsimage中。为了保持Stadnby与active的状态一致,standby需要尽量实时获取每条editlog日志,并应用到FsImage中。这时需要一个共享存储,存放editlog,standby能实时获取日志。这有两个关键点需要保证, 共享存储是高可用的,需要防止两个NameNode同时向共享存储写数据导致数据损坏。
- 是什么,Qurom Journal Manager,基于Paxos(基于消息传递的一致性算法)。这个算法比较难懂,简单的说,Paxos算法是解决分布式环境中如何就某个值达成一致,(一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个"一致性算法"以保证每个节点看到的指令一致)
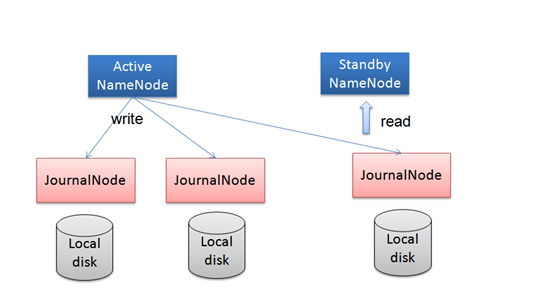
图3 QJM架构
- 如何实现,
(1) 初始化后,Active把editlog日志写到2N+1上JN上,每个editlog有一个编号,每次写editlog只要其中大多数JN返回成功(即大于等于N+1)即认定写成功。
(2) Standby定期从JN读取一批editlog,并应用到内存中的FsImage中。
(3) 如何fencing: NameNode每次写Editlog都需要传递一个编号Epoch给JN,JN会对比Epoch,如果比自己保存的Epoch大或相同,则可以写,JN更新自己的Epoch到最新,否则拒绝操作。在切换时,Standby转换为Active时,会把Epoch+1,这样就防止即使之前的NameNode向JN写日志,也会失败。
(4) 写日志:
(a) NN通过RPC向N个JN异步写Editlog,当有N/2+1个写成功,则本次写成功。
(b) 写失败的JN下次不再写,直到调用滚动日志操作,若此时JN恢复正常,则继续向其写日志。
(c) 每条editlog都有一个编号txid,NN写日志要保证txid是连续的,JN在接收写日志时,会检查txid是否与上次连续,否则写失败。
(5) 读日志:
(a) 定期遍历所有JN,获取未消化的editlog,按照txid排序。
(b) 根据txid消化editlog。
(6) 切换时日志恢复机制
(a) 主从切换时触发
(b) 准备恢复(prepareRecovery),standby向JN发送RPC请求,获取txid信息,并对选出最好的JN。
(c) 接受恢复(acceptRecovery),standby向JN发送RPC,JN之间同步Editlog日志。
(d) Finalized日志。即关闭当前editlog输出流时或滚动日志时的操作。
(e) Standby同步editlog到最新
(7) 如何选取最好的JN
(a) 有Finalized的不用in-progress
(b) 多个Finalized的需要判断txid是否相等
(c) 没有Finalized的首先看谁的epoch更大
(d) Epoch一样则选txid大的。
参考:
1.https://issues.apache.org/jira/secure/attachment/12480489/NameNode%20HA_v2_1.pdf
2.https://issues.apache.org/jira/secure/attachment/12521279/zkfc-design.pdf
3.https://issues.apache.org/jira/secure/attachment/12547598/qjournal-design.pdf
4. https://issues.apache.org/jira/browse/HDFS-1972
5.https://issues.apache.org/jira/secure/attachment/12490290/DualBlockReports.pdf
6.http://svn.apache.org/viewvc/hadoop/common/branches/branch-2.2.0/
7.http://yanbohappy.sinaapp.com/?p=205
Hadoop HA 深度解析的更多相关文章
- Kafka深度解析
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/01/02/Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅 ...
- Kafka深度解析(如何在producer中指定partition)(转)
原文链接:Kafka深度解析 背景介绍 Kafka简介 Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能 ...
- 全网最详细的Hadoop HA集群启动后,两个namenode都是active的解决办法(图文详解)
不多说,直接上干货! 这个问题,跟 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解) 是大同小异. 欢迎大家,加入我的微信公众号:大数据躺过的坑 ...
- 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解)
不多说,直接上干货! 解决办法 因为,如下,我的Hadoop HA集群. 1.首先在hdfs-site.xml中添加下面的参数,该参数的值默认为false: <property> < ...
- Spark RDD深度解析-RDD计算流程
Spark RDD深度解析-RDD计算流程 摘要 RDD(Resilient Distributed Datasets)是Spark的核心数据结构,所有数据计算操作均基于该结构进行,包括Spark ...
- Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
前言 如今,许多用于分析大型数据集的开源系统都是用 Java 或者是基于 JVM 的编程语言实现的.最着名的例子是 Apache Hadoop,还有较新的框架,如 Apache Spark.Apach ...
- Spring源码深度解析之Spring MVC
Spring源码深度解析之Spring MVC Spring框架提供了构建Web应用程序的全功能MVC模块.通过策略接口,Spring框架是高度可配置的,而且支持多种视图技术,例如JavaServer ...
- 使用Nginx+Lua代理Hadoop HA
一.Hadoop HA的Web页面访问 Hadoop开启HA后,会同时存在两个Master组件提供服务,其中正在使用的组件称为Active,另一个作为备份称为Standby,例如HDFS的NameNo ...
- [WebKit内核] JavaScript引擎深度解析--基础篇(一)字节码生成及语法树的构建详情分析
[WebKit内核] JavaScript引擎深度解析--基础篇(一)字节码生成及语法树的构建详情分析 标签: webkit内核JavaScriptCore 2015-03-26 23:26 2285 ...
随机推荐
- Truck History(prime)
Truck History Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 31871 Accepted: 12427 D ...
- .net core中automapper的使用
automapper 是将两个类中的相同字段进行映射,也可以指定字段进行映射:将 UserDao的id 映射为 User 的age CreateMap<UserDao, User>() . ...
- codeforces 914 D 线段树+数学
题意 给出一个长度为\(n\)的数列\(a\),两种询问,第一种给出三个数\(l,r,x\),区间\([l,r]\)的\(gcd\)值是否和\(x\)相似,若最多改变区间\([l,r]\)中的一个数使 ...
- Flutter - > Android dependency 'com.android.support:support-v4' has different version for the compile (26.1.0) and runtime (27.1.1) classpath.
Launching lib\main.dart on Nokia X6 in debug mode... Initializing gradle... Resolving dependencies.. ...
- jquery inArray()函数详解
jquery inarray()函数详解 jquery.inarray(value,array)确定第一个参数在数组中的位置(如果没有找到则返回 -1 ). determine the index o ...
- Object Relational Mapping框架之Hibernate
hibernate框架简介: hibernate框架就是开发中在持久层中应用居多的ORM框架,它对JDBC做了轻量级的封装. (百度介绍,感觉不错) 什么是ORM:Object Relational ...
- Using the Console[译]
由于最近的项目需要大量用到浏览器端的js编码和调试,所以仔细阅读了一下Chrome对于开发者工具中js部分的说明.虽然原来也用这个工具,但读后仍然觉得受益匪浅.于是抽空翻译一下,与大家分享. 本人英文 ...
- Java实现Oracle的to_char函数
/** * 将int.long.double.float.String.Date等类型format成字符类型 * * 一.数字format格式处理: * 01)99.99的实现,小数位四舍五入不够位数 ...
- 自动化运维工具saltstack04 -- 之jinja模板
jinjia模板 需求:想让saltstack的file模块分发到minion端的配置文件监听minion端的IP和端口,如何用变量实现?看下面!! 1.jinja模板加grains使apache监听 ...
- c语言数字图像处理(十):阈值处理
定义 全局阈值处理 假设某一副灰度图有如下的直方图,该图像由暗色背景下的较亮物体组成,从背景中提取这一物体时,将阈值T作为分割点,分割后的图像g(x, y)由下述公式给出,称为全局阈值处理 多阈值处理 ...