Hive安装与应用过程
1. 参考说明
参考文档:
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
2. 安装环境说明
2.1. 环境说明
CentOS7.4+ Hadoop2.7.5的伪分布式环境
|
主机名 |
NameNode |
SecondaryNameNode |
DataNodes |
|
centoshadoop.smartmap.com |
192.168.1.80 |
192.168.1.80 |
192.168.1.80 |
Hadoop的安装目录为:/opt/hadoop/hadoop-2.7.5
3. 安装
3.1. Hive下载
https://hive.apache.org/downloads.html
3.2. Hive解压
将下载的apache-hive-2.3.3-bin.tar.gz解压到/opt/hadoop/hive-2.3.3目录下
4. 配置
4.1. 修改profile文件
vi
/etc/profile
export HIVE_HOME=/opt/hadoop/hive-2.3.3
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:$HIVE_HOME/lib
4.2. 将JDK升级为1.8版本
将JDK切换成1.8的版本,并修改所有与JAVA_HOME相关的变量
4.3. 安装MySQL数据库
4.3.1. 下载MySQL源
[root@centoshadoop soft]# wget
http://repo.mysql.com/mysql57-community-release-el7-8.noarch.rpm
4.3.2. 安装MySQL源
[root@centoshadoop soft]# yum install
mysql57-community-release-el7-8.noarch.rpm
4.3.3. 安装MySQL
[root@centoshadoop soft]# yum install mysql-server
4.3.4. 启动mysql服务
[root@centoshadoop soft]# systemctl start mysqld
[root@centoshadoop soft]# systemctl enable mysqld
4.3.5. 重置root密码
MySQL5.7会在安装后为root用户生成一个随机密码, MySQL为root用户生成的随机密码通过mysqld.log文件可以查找到
[root@centoshadoop soft]# grep 'temporary password'
/var/log/mysqld.log
2018-05-22T09:23:43.115820Z 1 [Note] A temporary
password is generated for root@localhost: 2&?SYJpBOdwo
[root@centoshadoop soft]#
[ambari@master opt]$ mysql -u root -p
Enter
password:
Welcome
to the MySQL monitor. Commands end with
; or \g.
Your
MySQL connection id is 2
Server
version: 5.7.22
…....
mysql> set global
validate_password_policy=0;
Query
OK, 0 rows affected (0.00 sec)
mysql> set global
validate_password_length=3;
Query
OK, 0 rows affected (0.00 sec)
mysql> set global
validate_password_mixed_case_count=0;
Query
OK, 0 rows affected (0.00 sec)
mysql> set global
validate_password_number_count=0;
Query
OK, 0 rows affected (0.00 sec)
mysql> set global
validate_password_special_char_count=0;
Query
OK, 0 rows affected (0.00 sec)
mysql> alter user
'root'@'localhost' identified by 'gis123';
Query
OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query
OK, 0 rows affected (0.01 sec)
mysql> SHOW VARIABLES LIKE
'validate_password%';
+--------------------------------------+-------+
|
Variable_name | Value |
+--------------------------------------+-------+
|
validate_password_check_user_name | OFF |
|
validate_password_dictionary_file | |
|
validate_password_length | 4 |
|
validate_password_mixed_case_count | 0 |
|
validate_password_number_count | 0 |
|
validate_password_policy | LOW |
|
validate_password_special_char_count | 0 |
+--------------------------------------+-------+
7 rows
in set (0.01 sec)
mysql> set global
validate_password_length=3;
Query
OK, 0 rows affected (0.00 sec)
mysql> alter user
'root'@'localhost' identified by 'gis';
Query
OK, 0 rows affected (0.00 sec)
mysql> flush
privileges;
Query
OK, 0 rows affected (0.00 sec)
mysql> quit
Bye
[ambari@master opt]$ mysql -u root -p
Enter
password:
4.3.6. 开放数据库访问权限
[root@localsource ~]# mysql -u root
-p
Enter
password:
Welcome
to the MySQL monitor. Commands end with
; or \g.
……
Type
'help;' or '\h' for help. Type '\c' to clear the current input
statement.
mysql> GRANT ALL PRIVILEGES
ON *.* TO 'root'@'%' IDENTIFIED BY 'gis' WITH GRANT OPTION;
Query
OK, 0 rows affected, 1 warning (0.00 sec)
mysql> FLUSH
PRIVILEGES;
Query
OK, 0 rows affected (0.00 sec)
mysql> quit

4.3.7. 安装mysql jdbc驱动
4.3.7.1. 上传软件包到/opt/java/目录下
上传软件包mysql-connector-java-5.1.46.jar到/opt/java/jdk1.8.0_171/lib/目录下
4.3.7.2. 测试
import
java.sql.*;
public
class SqlTest {
public static void main(String[]
args) throws Exception {
try {
String
driver="com.mysql.jdbc.Driver";
String
url="jdbc:mysql://127.0.0.1:3306/mysql?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false";
String user="root";
String password="gis";
Class.forName(driver);
Connection
conn=DriverManager.getConnection(url,user,password);
Statement
stmt=conn.createStatement();
System.out.println("mysql test
successful!");
stmt.close();
conn.close();
} catch (Exception e) {
e.printStackTrace();
System.out.println("mysql test
fail!");
}
}
}
编译执行
javac
SqlTest.java
java
SqlTest
4.4. 修改Hive的配置文件
cd
/opt/hadoop/hive-2.3.3/conf/
cp
hive-env.sh.template hive-env.sh
4.5. 配置Hive的Metastore
[root@centoshadoop conf]# cp /opt/hadoop/hive-2.3.3/conf/hive-default.xml.template
/opt/hadoop/hive-2.3.3/conf/hive-site.xml
[root@centoshadoop conf]# vi
/opt/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
[root@centoshadoop conf]# mkdir -p
/opt/hadoop/hive-2.3.3/temp/hadoopUser
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name
for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>
jdbc:mysql://127.0.0.1:3306/hive?createDatabaseIfNotExist=true&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf8&useSSL=false
</value>
<description>
JDBC connect string for a JDBC metastore.
</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use
against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>gis</value>
<description>password to use
against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of
default database for the warehouse</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/opt/hadoop/hive-2.3.3/temp/${system:user.name}</value>
<description>Local scratch
space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/hadoop/hive-2.3.3/temp/${hive.session.id}_resources</value>
<description>Temporary local
directory for added resources in the remote file
system.</description>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hadoop/hive-2.3.3/temp/${system:user.name}</value>
<description>Location of Hive
run time structured log file</description>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/opt/hadoop/hive-2.3.3/temp/${system:user.name}/operation_logs</value>
<description>Top level directory where operation
logs are stored if logging functionality is
enabled</description>
</property>
5. 启动Hadoop
5.1. 启动YARN与HDFS
cd
/opt/hadoop/hadoop-2.7.5/sbin
start-all.sh
5.2. 启动historyserver
cd
/opt/hadoop/hadoop-2.7.5/sbin
mr-jobhistory-daemon.sh start historyserver
6. 初始化元数据
[root@centoshadoop bin]# cp
/opt/java/jdk1.8.0_171/lib/mysql-connector-java-5.1.46.jar
/opt/hadoop/hive-2.3.3/lib/
[root@centoshadoop bin]# schematool -dbType mysql -initSchema
7. 应用Hive工具
7.1. 启动运行Hive的交互式Shell环境
cd
/opt/hadoop/hive-2.3.3/bin
hive
7.2. 列出表格
hive>
show
tables;
7.3. 创建表格
hive>
CREATE
TABLE records (year STRING, temperature INT, quality INT) ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
OK
Time
taken: 3.755 seconds
7.4. 加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/ncdc/micro-tab/sample.txt' OVERWRITE
INTO TABLE records;
Loading
data to table default.records
OK
Time
taken: 1.412 seconds
[root@centoshadoop micro-tab]# hadoop fs -ls /user/hive/warehouse
Found 1
items
drwxr-xr-x - hadoop supergroup 0 2018-05-22 19:12 /user/hive/warehouse/records
[root@centoshadoop micro-tab]# hadoop fs -ls
/user/hive/warehouse/records
Found 1
items
7.5. 查询数据
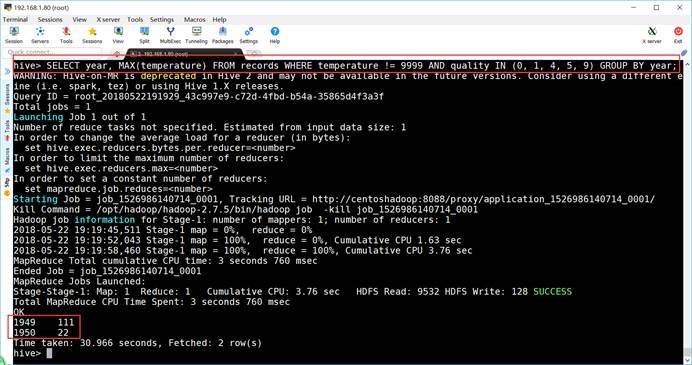
hive>
SELECT
year, MAX(temperature) FROM records WHERE temperature != 9999 AND quality IN
(0, 1, 4, 5, 9) GROUP BY year;
WARNING:
Hive-on-MR is deprecated in Hive 2 and may not be available in the future
versions. Consider using a different execution engine (i.e. spark, tez) or using
Hive 1.X releases.
Query ID
= root_20180522191929_43c997e9-c72d-4fbd-b54a-35865d4f3a3f
Total
jobs = 1
Launching Job 1 out of 1
7.6. 退出
hive>
exit;
7.7. 分区与桶
7.7.1. 分区
7.7.1.1. 创建分区表
hive>
DROP
TABLE IF EXISTS logs;
hive>
CREATE
TABLE logs (ts BIGINT, line STRING) PARTITIONED BY (dt STRING, country
STRING);
7.7.1.2. 加载数据到分区表
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/partitions/file1' INTO TABLE
logs PARTITION (dt='2001-01-01', country='GB');
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/partitions/file2' INTO TABLE
logs PARTITION (dt='2001-01-01', country='GB');
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/partitions/file3' INTO TABLE
logs PARTITION (dt='2001-01-01', country='US');
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/partitions/file4' INTO TABLE
logs PARTITION (dt='2001-01-02', country='GB');
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/partitions/file5' INTO TABLE
logs PARTITION (dt='2001-01-02', country='US');
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/partitions/file6' INTO TABLE
logs PARTITION (dt='2001-01-02', country='US');
7.7.1.3. 显示分区表的分区
hive>
SHOW
PARTITIONS logs;
OK
dt=2001-01-01/country=GB
dt=2001-01-01/country=US
dt=2001-01-02/country=GB
dt=2001-01-02/country=US
Time
taken: 4.439 seconds, Fetched: 4 row(s)
7.7.1.4. 查询数据
hive>
SELECT
ts, dt, line FROM logs WHERE country='GB';
OK
1 2001-01-01 Log line 1
2 2001-01-01 Log line 2
4 2001-01-02 Log line 4
Time
taken: 1.922 seconds, Fetched: 3 row(s)
7.7.2. 桶
7.7.2.1. 创建一般的表
hive>
DROP
TABLE IF EXISTS users;
hive>
CREATE
TABLE users (id INT, name STRING);
7.7.2.2. 为表加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/tables/users.txt' OVERWRITE INTO
TABLE users;
hive>
dfs -cat
/user/hive/warehouse/users/users.txt;
0Nat
2Joe
3Kay
4Ann
hive>
7.7.2.3. 创建分桶表
hive>
CREATE
TABLE bucketed_users (id INT, name STRING) CLUSTERED BY (id) INTO 4
BUCKETS;
OK
Time
taken: 0.081 seconds
hive>
DROP
TABLE bucketed_users;
OK
Time
taken: 1.118 seconds
7.7.2.4. 创建分桶排序表
hive>
CREATE TABLE bucketed_users (id INT, name
STRING) CLUSTERED BY (id) SORTED
BY (id) INTO 4 BUCKETS;
7.7.2.5. 为分桶排序表加载数据
hive>
SELECT *
FROM users;
OK
0 Nat
2 Joe
3 Kay
4 Ann
Time
taken: 1.366 seconds, Fetched: 4 row(s)
hive>
SET
hive.enforce.bucketing=true;
hive>
INSERT
OVERWRITE TABLE bucketed_users SELECT * FROM users;
7.7.2.6. 查看分分桶排序表中的HDFS的文件
hive>
dfs -ls
/user/hive/warehouse/bucketed_users;
Found 4
items
-rwxr-xr-x 1 hadoop supergroup 12 2018-05-22 21:07
/user/hive/warehouse/bucketed_users/000000_0
-rwxr-xr-x 1 hadoop supergroup 0 2018-05-22 21:07
/user/hive/warehouse/bucketed_users/000001_0
-rwxr-xr-x 1 hadoop supergroup 6 2018-05-22 21:07
/user/hive/warehouse/bucketed_users/000002_0
-rwxr-xr-x 1 hadoop supergroup 6 2018-05-22 21:07
/user/hive/warehouse/bucketed_users/000003_0
hive>
dfs -cat
/user/hive/warehouse/bucketed_users/000000_0;
0Nat
4Ann
7.7.2.7. 从指定的桶中进行取样
hive> SELECT * FROM bucketed_users TABLESAMPLE(BUCKET 1 OUT
OF 4 ON id);
OK
0 Nat
4 Ann
Time
taken: 0.393 seconds, Fetched: 2 row(s)
hive>
SELECT *
FROM bucketed_users TABLESAMPLE(BUCKET 1 OUT OF 2 ON id);
OK
0 Nat
4 Ann
2 Joe
hive>
SELECT *
FROM users TABLESAMPLE(BUCKET 1 OUT OF 4 ON rand());
OK
Time
taken: 0.072 seconds
7.8. 索引
7.8.1. 创建表
hive>
DROP
TABLE IF EXISTS users_extended;
hive>
CREATE
TABLE users_extended (id INT, name STRING, gender STRING);
7.8.1.1. 加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/tables/users_extended.txt'
OVERWRITE INTO TABLE users_extended;
7.8.1.2. 创建索引
hive>
DROP
INDEX IF EXISTS users_index;
hive>
CREATE
INDEX users_index
ON
TABLE users_extended (gender)
AS
'BITMAP' WITH DEFERRED REBUILD;
OK
Time
taken: 0.342 seconds
7.8.1.3. 应用索引重新构建数据
hive>
ALTER
INDEX users_index ON users_extended REBUILD;
7.8.1.4. 查询数据
hive>
SELECT *
FROM users_extended WHERE gender = 'F';
OK
3 Kay F
4 Ann F
Time
taken: 0.135 seconds, Fetched: 2 row(s)
7.9. 存贮格式
7.9.1. 创建一般的表
hive>
DROP
TABLE IF EXISTS users;
hive>
CREATE
TABLE users (id INT, name STRING);
7.9.2. 为表加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/tables/users.txt' OVERWRITE INTO
TABLE users;
7.9.3. SequenceFile文件
7.9.3.1. 创建SequenceFile文件与加载数据
hive>
DROP
TABLE IF EXISTS users_seqfile;
hive>
SET
hive.exec.compress.output=true;
hive>
SET
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DeflateCodec;
hive>
SET
mapreduce.output.fileoutputformat.compress.type=BLOCK;
hive>
CREATE
TABLE users_seqfile STORED AS SEQUENCEFILE AS SELECT id, name FROM
users;
7.9.3.2. 查询数据
hive>
SELECT *
from users_seqfile;
OK
0 Nat
2 Joe
3 Kay
4 Ann
Time
taken: 0.409 seconds, Fetched: 4 row(s)
7.9.4. Avro文件
7.9.4.1. 创建Avro文件
hive>
DROP
TABLE IF EXISTS users_avro;
hive>
SET
hive.exec.compress.output=true;
hive>
SET
avro.output.codec=snappy;
hive>
CREATE
TABLE users_avro (id INT, name STRING) STORED AS AVRO;
OK
Time
taken: 0.234 seconds
7.9.4.2. 加载数据
hive>
INSERT
OVERWRITE TABLE users_avro SELECT * FROM users;
7.9.4.3. 查询数据
hive>
SELECT *
from users_avro;
OK
0 Nat
2 Joe
3 Kay
4 Ann
Time
taken: 0.21 seconds, Fetched: 4 row(s)
7.9.5. Parquet文件
7.9.5.1. 创建Parquet文件
hive>
DROP
TABLE IF EXISTS users_parquet;
7.9.5.2. 创建Parquet文件与加载数据
hive>
CREATE
TABLE users_parquet STORED AS PARQUET AS SELECT * FROM users;
7.9.5.3. 查询数据
hive>
SELECT *
from users_parquet;
OK
SLF4J:
Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J:
Defaulting to no-operation (NOP) logger implementation
SLF4J:
See http://www.slf4j.org/codes.html#StaticLoggerBinder for further
details.
0 Nat
2 Joe
3 Kay
4 Ann
7.9.6. ORCFile文件
7.9.6.1. 创建ORCFile文件
hive>
DROP
TABLE IF EXISTS users_orc;
7.9.6.2. 创建ORCFile文件与加载数据
hive>
CREATE
TABLE users_orc STORED AS ORCFILE AS SELECT * FROM users;
7.9.6.3. 查询数据
hive> SELECT * from users_orc;
OK
0 Nat
2 Joe
3 Kay
4 Ann
Time
taken: 0.086 seconds, Fetched: 4 row(s)
7.9.7. 定制系列化
7.9.7.1. 创建文件
hive>
DROP
TABLE IF EXISTS stations;
hive>
CREATE
TABLE stations (usaf STRING, wban STRING, name STRING)
ROW FORMAT SERDE
'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
WITH
SERDEPROPERTIES (
"input.regex" = "(\\d{6}) (\\d{5}) (.{29})
.*"
);
7.9.7.2. 加载数据
hive>
LOAD
DATA LOCAL INPATH
"/root/hapood/data/input/ncdc/metadata/stations-fixed-width.txt" INTO TABLE
stations;
7.9.7.3. 查询数据
hive>
SELECT *
FROM stations LIMIT 4;
OK
010000 99999 BOGUS NORWAY
010003 99999 BOGUS NORWAY
010010 99999 JAN MAYEN
010013 99999 ROST
Time
taken: 0.103 seconds, Fetched: 4 row(s)
hive>
7.10. 多表插入
7.10.1. 创建一般的表
hive> DROP TABLE IF exists records2;
hive>
CREATE
TABLE records2 (station STRING, year STRING, temperature INT, quality INT) ROW
FORMAT DELIMITED FIELDS TERMINATED BY '\t';
7.10.2. 为表加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/ncdc/micro-tab/sample2.txt' OVERWRITE
INTO TABLE records2;
7.10.3. 创建其它的多张表
hive>
DROP
TABLE IF exists stations_by_year;
OK
Time
taken: 0.03 seconds
hive> DROP TABLE IF exists records_by_year;
OK
Time
taken: 0.016 seconds
hive>
DROP
TABLE IF exists good_records_by_year;
OK
Time
taken: 0.012 seconds
hive>
CREATE
TABLE stations_by_year (year STRING, num INT);
OK
Time
taken: 0.101 seconds
hive>
CREATE
TABLE records_by_year (year STRING, num INT);
OK
Time
taken: 0.166 seconds
hive>
CREATE
TABLE good_records_by_year (year STRING, num INT);
OK
Time
taken: 0.073 seconds
7.10.4. 将一张表中的数据插入到其它多张表中
hive>
FROM
records2
INSERT
OVERWRITE TABLE stations_by_year SELECT year, COUNT(DISTINCT station) GROUP BY
year
INSERT
OVERWRITE TABLE records_by_year SELECT year, COUNT(1) GROUP BY year
INSERT
OVERWRITE TABLE good_records_by_year SELECT year, COUNT(1) WHERE temperature !=
9999 AND quality IN (0, 1, 4, 5, 9) GROUP BY year;
7.10.4.1. 查询数据
hive>
SELECT *
FROM stations_by_year;
OK
1949 2
1950 2
Time
taken: 0.207 seconds, Fetched: 2 row(s)
hive>
SELECT *
FROM records_by_year;
OK
1949 2
1950 3
Time
taken: 0.133 seconds, Fetched: 2 row(s)
hive>
SELECT *
FROM good_records_by_year;
OK
1949 2
1950 3
Time
taken: 0.091 seconds, Fetched: 2 row(s)
7.10.4.2. 多表联接查询数据
hive>
SELECT
stations_by_year.year, stations_by_year.num, records_by_year.num,
good_records_by_year.num FROM stations_by_year
JOIN
records_by_year ON (stations_by_year.year = records_by_year.year)
JOIN
good_records_by_year ON (stations_by_year.year =
good_records_by_year.year);
Stage-Stage-4: Map: 1 Cumulative CPU: 2.19 sec HDFS Read: 7559 HDFS Write: 133 SUCCESS
Total
MapReduce CPU Time Spent: 2 seconds 190 msec
OK
1949 2 2 2
1950 2 3 3
Time
taken: 29.217 seconds, Fetched: 2 row(s)
7.11. 类型转换
7.11.1.1. 创建表
hive>
DROP
TABLE IF EXISTS dummy;
hive>
CREATE
TABLE dummy (value STRING);
hive>
DROP TABLE IF EXISTS simple;
hive>
CREATE TABLE simple ( col1 TIMESTAMP );
7.11.1.2. 加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/dummy.txt' OVERWRITE INTO TABLE
dummy;
7.11.1.3. 插入记录
hive>
INSERT
OVERWRITE TABLE simple SELECT '2012-01-02 03:04:05.123456789' FROM
dummy;
7.11.1.4. String转Int
hive>
SELECT CAST('X' AS INT) from dummy;
hive>
SELECT 2 + '2' FROM dummy;
7.11.1.5. Bool转Int
hive>
SELECT * from dummy;
hive>
SELECT 2 + CAST(TRUE AS INT) FROM dummy;
7.11.1.6. 字符连接
hive>
SELECT concat('Truth: ', TRUE) FROM simple;
hive>
SELECT concat('Date: ', col1) FROM simple;
7.11.1.7. Date转BigInt
hive>
SELECT 2 + CAST(col1 AS BIGINT) FROM simple;
7.11.1.8. Date计算
hive>
SELECT 2 + col1 FROM simple;
hive>
SELECT 2L + col1 FROM simple;
hive>
SELECT 2.0 + col1 FROM simple;
7.12. 复杂数据类型(Array、Map、Struct、Union)
7.12.1.1. 创建表
hive>
DROP
TABLE IF EXISTS complex;
hive>
CREATE
TABLE complex (
c1 ARRAY<INT>,
c2 MAP<STRING, INT>,
c3 STRUCT<a:STRING, b:INT, c:DOUBLE>,
c4 UNIONTYPE<STRING, INT>
);
7.12.1.2. 加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/hive/types/complex.txt' OVERWRITE
INTO TABLE complex;
7.12.1.3. 查询数据
hive> SELECT c1[0], c2['b'], c3.c, c4 FROM
complex;
OK
1 2 1.0 {1:63}
Time
taken: 0.179 seconds, Fetched: 1 row(s)
7.13. 排序
7.13.1.1. 创建表
hive>
DROP
TABLE IF EXISTS records2;
hive>
CREATE
TABLE records2 (station STRING, year STRING, temperature INT, quality INT) ROW
FORMAT DELIMITED FIELDS TERMINATED BY '\t';
7.13.1.2. 加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/ncdc/micro-tab/sample2.txt' OVERWRITE INTO
TABLE records2;
7.13.1.3. 查询排序
hive>
FROM
records2 SELECT year, temperature DISTRIBUTE BY year SORT BY year ASC,
temperature DESC;
7.14. 连接
7.14.1.1. 创建表
hive>
DROP TABLE IF EXISTS sales;
hive>
CREATE TABLE sales (name STRING, id INT) ROW FORMAT DELIMITED FIELDS TERMINATED
BY '\t';
hive>
DROP TABLE IF EXISTS things;
hive>
CREATE TABLE things (id INT, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED
BY '\t';
7.14.1.2. 加载数据
hive> LOAD DATA LOCAL INPATH
'/root/hapood/data/input/hive/joins/sales.txt' OVERWRITE INTO TABLE
sales;
Loading
data to table default.sales
OK
Time
taken: 1.445 seconds
hive> LOAD DATA LOCAL INPATH
'/root/hapood/data/input/hive/joins/things.txt' OVERWRITE INTO TABLE
things;
Loading
data to table default.things
OK
Time
taken: 0.485 seconds
7.14.1.3. 单表查询
hive> SELECT * FROM sales;
OK
Joe 2
Hank 4
Ali 0
Eve 3
Hank 2
Time
taken: 1.36 seconds, Fetched: 5 row(s)
hive>
SELECT *
FROM things;
OK
2 Tie
4 Coat
3 Hat
1 Scarf
Time
taken: 0.137 seconds, Fetched: 4 row(s)
7.14.1.4. 内连接查询
hive>
SELECT sales.*, things.* FROM sales JOIN things ON (sales.id =
things.id);
Total
MapReduce CPU Time Spent: 2 seconds 50 msec
OK
Joe 2 2 Tie
Hank 4 4 Coat
Eve 3 3 Hat
Hank 2 2 Tie
Time
taken: 21.643 seconds, Fetched: 4 row(s)
7.14.1.5. 左外连接查询
hive>
SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id =
things.id);
Total
MapReduce CPU Time Spent: 1 seconds 450 msec
OK
Joe 2 2 Tie
Hank 4 4 Coat
Ali 0 NULL NULL
Eve 3 3 Hat
Hank 2 2 Tie
Time
taken: 20.529 seconds, Fetched: 5 row(s)
7.14.1.6. 右外连接查询
hive>
SELECT sales.*, things.* FROM sales RIGHT OUTER JOIN things ON (sales.id =
things.id);
Total
MapReduce CPU Time Spent: 1 seconds 650 msec
OK
Joe 2 2 Tie
Hank 2 2 Tie
Hank 4 4 Coat
Eve 3 3 Hat
NULL NULL 1 Scarf
Time
taken: 19.049 seconds, Fetched: 5 row(s)
7.14.1.7. 全连接查询
hive>
SELECT
sales.*, things.* FROM sales FULL OUTER JOIN things ON (sales.id =
things.id);
Total
MapReduce CPU Time Spent: 4 seconds 20 msec
OK
Ali 0 NULL NULL
NULL NULL 1 Scarf
Hank 2 2 Tie
Joe 2 2 Tie
Eve 3 3 Hat
Hank 4 4 Coat
Time
taken: 20.584 seconds, Fetched: 6 row(s)
7.14.1.8. 半连接
hive>
SELECT *
FROM things LEFT SEMI JOIN sales ON (sales.id = things.id);
Total
MapReduce CPU Time Spent: 2 seconds 80 msec
OK
2 Tie
4 Coat
3 Hat
Time
taken: 27.454 seconds, Fetched: 3 row(s)
7.14.1.9. Map连接
hive>
SELECT sales.*, things.* FROM sales JOIN things ON (sales.id =
things.id);
Total
MapReduce CPU Time Spent: 2 seconds 50 msec
OK
Joe 2 2 Tie
Hank 4 4 Coat
Eve 3 3 Hat
Hank 2 2 Tie
Time
taken: 20.329 seconds, Fetched: 4 row(s)
7.15. 应用外部编写的MapReduce
7.15.1.1. 创建表
hive>
DROP
TABLE IF EXISTS records2;
hive>
CREATE
TABLE records2 (station STRING, year STRING, temperature INT, quality INT) ROW
FORMAT DELIMITED FIELDS TERMINATED BY '\t';
7.15.1.2. 加载数据
hive>
LOAD
DATA LOCAL INPATH '/root/hapood/data/input/ncdc/micro-tab/sample2.txt' OVERWRITE
INTO TABLE records2;
7.15.1.3. 数据变换的Python代码
is_good_quality.py
#!/usr/bin/env python
import
re
import
sys
for line
in sys.stdin:
(year,
temp, q) = line.strip().split()
if
(temp != "9999" and re.match("[01459]", q)):
print
"%s\t%s" % (year, temp)
7.15.1.4. MapReduce的Python代码
max_temperature_reduce.py
#!/usr/bin/env python
import
sys
(last_key, max_val) = (None, 0)
for line
in sys.stdin:
(key,
val) = line.strip().split("\t")
if
last_key and last_key != key:
print
"%s\t%s" % (last_key, max_val)
(last_key,
max_val) = (key, int(val))
else:
(last_key,
max_val) = (key, max(max_val, int(val)))
if
last_key:
"%s\t%s" % (last_key, max_val)
7.15.1.5. 在Hive中应用Python代码
7.15.1.5.1. 加载代码
hive>
ADD FILE
/root/hapood/data/input/hive/python/is_good_quality.py;
Added
resources: [/root/hapood/data/input/hive/python/is_good_quality.py]
7.15.1.5.2. 执行查询
hive>
FROM
records2 SELECT TRANSFORM(year, temperature, quality) USING
'is_good_quality.py' AS year, temperature;
Total
MapReduce CPU Time Spent: 1 seconds 640 msec
OK
1950 0
1950 22
1950 -11
1949 111
1949 78
Time
taken: 12.134 seconds, Fetched: 5 row(s)
7.15.1.6. MapReduce的Python代码
7.15.1.6.1. 加载代码
hive>
ADD FILE
/root/hapood/data/input/hive/python/max_temperature_reduce.py;
Added
resources:
[/root/hapood/data/input/hive/python/max_temperature_reduce.py]
7.15.1.6.2. 执行查询
hive>
FROM
(
FROM
records2 MAP year, temperature, quality USING 'is_good_quality.py' AS year,
temperature
)
map_output
REDUCE
year, temperature USING 'max_temperature_reduce.py' AS year,
temperature;
Total
MapReduce CPU Time Spent: 1 seconds 730 msec
OK
1950 22
1949 111
Time
taken: 12.574 seconds, Fetched: 2 row(s)
hive> FROM (
FROM
records2 SELECT TRANSFORM(year, temperature, quality) USING 'is_good_quality.py'
AS year, temperature
)
map_output
SELECT
TRANSFORM(year, temperature) USING 'max_temperature_reduce.py' AS year,
temperature;
Total
MapReduce CPU Time Spent: 1 seconds 180 msec
OK
1950 22
1949 111
Time
taken: 12.839 seconds, Fetched: 2 row(s)
Hive安装与应用过程的更多相关文章
- Hadoop之hive安装过程以及运行常见问题
Hive简介 1.数据仓库工具 2.支持一种与Sql类似的语言HiveQL 3.可以看成是从Sql到MapReduce的映射器 4.提供shall.Jdbc/odbc.Thrift.Web等接口 Hi ...
- hive安装--设置mysql为远端metastore
作业任务:安装Hive,有条件的同学可考虑用mysql作为元数据库安装(有一定难度,可以获得老师极度赞赏),安装完成后做简单SQL操作测试.将安装过程和最后测试成功的界面抓图提交 . 已有的当前虚拟机 ...
- 【大数据系列】Hive安装及web模式管理
一.什么是Hive Hive是建立在Hadoop基础常的数据仓库基础架构,,它提供了一系列的工具,可以用了进行数据提取转化加载(ETL),这是一种可以存储.查询和分析存储在Hadoop中的按规模数据的 ...
- Hive学习之路 (二)Hive安装
Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ 选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3 Hive ...
- Hive安装-windows(转载)
1.安装hadoop 2.从maven中下载mysql-connector-java-5.1.26-bin.jar(或其他jar版本)放在hive目录下的lib文件夹 3.配置hive环境变量,HIV ...
- Apache Hive (二)Hive安装
转自:https://www.cnblogs.com/qingyunzong/p/8708057.html Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ ...
- Hive总结(四)hive安装记录
本篇为安装篇较简单: 前提: 1: 安装了hadoop-1.0.4(1.0.3也能够)正常执行 2:安装了hbase-0.94.3, 正常执行 接下来,安装Hive,基于已经安装好的hadoop.过程 ...
- 第1节 hive安装:2、3、4、5、(多看几遍)
第1节 hive安装: 2.数据仓库的基本概念: 3.hive的基本介绍: 4.hive的基本架构以及与hadoop的关系以及RDBMS的对比等 5.hive的安装之(使用mysql作为元数据信息存储 ...
- Mac上Hive安装配置
Mac上Hive安装配置 1.安装 下载hive,地址:http://mirror.bit.edu.cn/apache/hive/ 之前我配置了集群,tjt01.tjt02.tjt03,这里hive安 ...
随机推荐
- iOS下载图片失败
一.具体问题 开发的过程中,发现某个界面部分图片的显示出现了问题只显示占位图片,取出图片的url在浏览器却是能打开的,各种尝试甚至找同行的朋友帮忙在他们项目里展示都会存在问题,最终发现通过第三方框架S ...
- POJ 1063
#include <iostream> using namespace std; int main() { //freopen("acm.acm","r&qu ...
- Visual Studio和eclipse的大小写转换快捷键
Visual Studio: 转小写:ctrl + u 转大写: ctrl + shift + u eclipse: 转小写: ctrl + shift + y 转大写: ctrl + shif ...
- vue-Treeselect 使用备注
<head> <!-- include Vue 2.x --> <script src="https://cdn.jsdelivr.net/npm/vue@@^ ...
- android动态权限获取
android动态权限获取 Android6.0采用新的权限模型,只有在需要权限的时候,才告知用户是否授权,是在runtime时候授权,而不是在原来安装的时候 ,同时默认情况下每次在运行时打开页面时候 ...
- python中的sort方法使用详解
Python中的sort()方法用于数组排序,本文以实例形式对此加以详细说明: 一.基本形式 列表有自己的sort方法,其对列表进行原址排序,既然是原址排序,那显然元组不可能拥有这种方法,因为元组是不 ...
- Mapreduce部署与第三方依赖包管理
Mapreduce部署是总会涉及到第三方包依赖问题,这些第三方包配置的方式不同,会对mapreduce的部署便捷性有一些影响,有时候还会导致脚本出错.本文介绍几种常用的配置方式: 1. HADOOP_ ...
- CentOS7.4安装Java8
官网下载Jdk8Linux64位版本: 使用MobaXterm工具连接远程Linux系统: 上传刚才下载好的文件到远程系统下 /usr/local/ 文件夹: 先进入压缩包所在目录再输入命令解压jdk ...
- android activity和fragment的生命周期图
Activity的生命周期: Fragment的生命周期:
- android-zip解压缩方法
/** * 解压缩文件到指定的目录. * * @param unZipfileName * 需要解压缩的文件(带路径) * @param mDestPath * 解压缩后存放的路径 **/ publi ...