PostgreSQL内核分析——BTree索引
文中附图参考至《PostgreSQL数据库内核分析》
(一)概念描述
B+树是一种索引数据结构,其一个特征在于非叶子节点用于描述索引,而叶子节点指向具体的数据存储位置。在PostgreSQL中,存在结构相似的BTree索引,该数据结构最先引用于《Effiicient Locking for Concurrent Operations on B-Trees》论文,一个新特征在于,引入了“High Key”(下述HK)用于描述当前节点子节点的最大值。如下图所示:

其中K1代表一个HK,其值等于P0及P0子节点的最大值,对于上述存在的2n个节点,每个节点都存在一个指针指向右兄弟节点,Pi的子节点取值范围为(Ki-1,Ki]
(二)PostgreSQL的BTree索引结构
在PostgreSQL中,普通表的表文件组织结构如下图
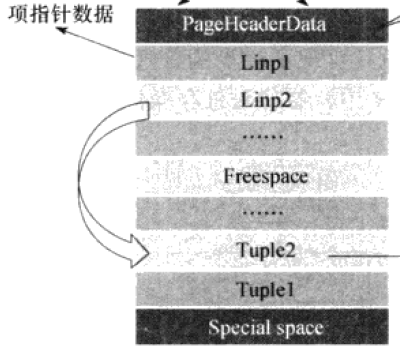
其中Linp结构用来指向文件块中的一个元组。Freespace是未分配的空闲空间,对于新插入页面的元组及其对应的Linp元素从该空间进行分配,分配方式是Linp元素从Freespace的头部分配,tuple从尾部分配。而PostgreSQL的索引结构,也是按照上述页面结构进行存储的。如下图:
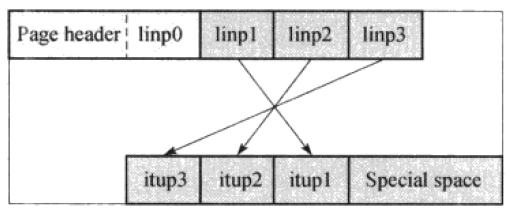
itup是排好序的索引元组,对于其如何完成排序将在之后的代码分析中进行介绍。linp用于索引itup,其存储了每个itup在页面中的实际位置。根据PostgreSQL中对BTree索引结构的描述,分为当前节点是否是最右节点两种类型。由于非最右节点需要一个字段来保存HK,故当对一个页面进行填充时,存在着以下两种方式:
(1)当前节点为非最右节点
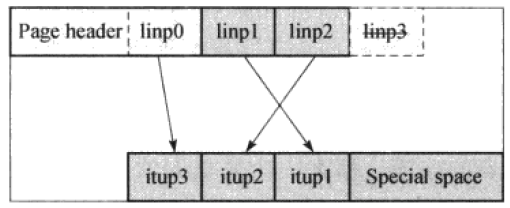
a.首先将itup3(最大的索引元组)复制到当前节点的右兄弟节点,然后将linp0指向itup3(HK)
b.去掉linp3。使用linp0来指向页面中的HK。
(2)当前节点为最右节点
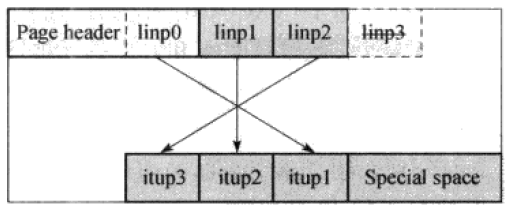
对于最右节点,其并不需要HK,故将每个linp递减一个位置,linp3不再使用。
基于上述,PostgreSQL所实现的BTree索引组织结构如下图:
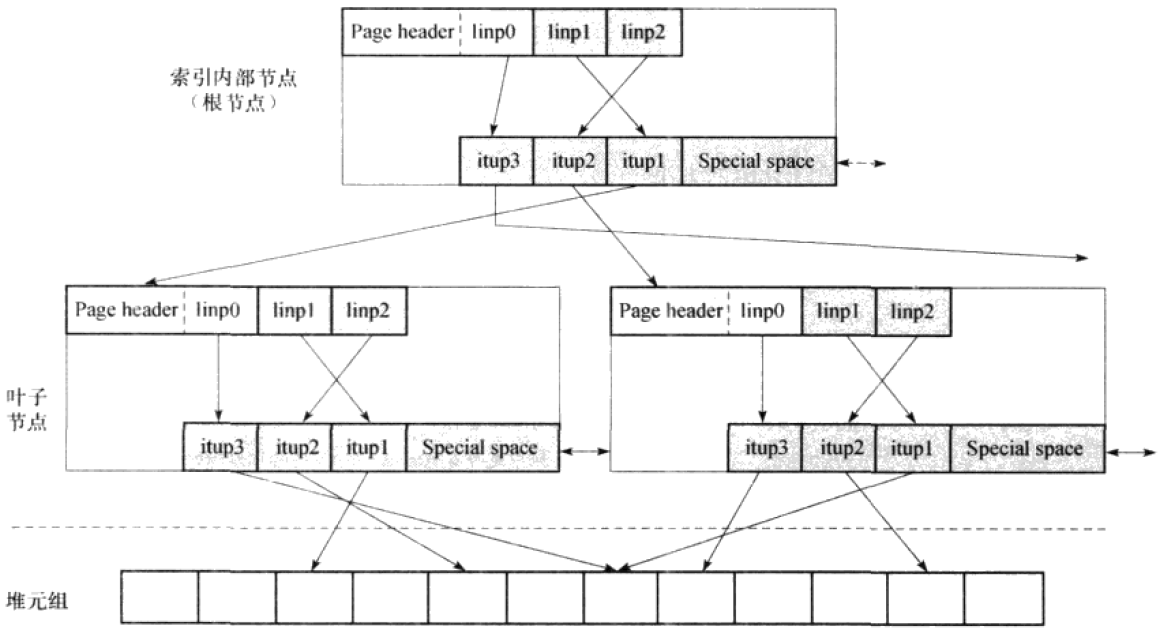
总结上图:
(1)对于非叶子节点,itup指向下一个节点,而对于叶子节点,itup指向实际物理存储的位置。
(2)Special space中,实现了两个指针,分配用于指向左右兄弟节点。
(3)根据BTree的特性,索引元组为有序,第一个叶子节点中itup3实际为最大索引元组,即HK,第二个叶子节点中itup1实际为最小索引元组,两者相同,故指向了同一物理存储位置。
(三)源码分析
- btbuild
索引创建的入口函数- BTBuildState buildstate
定义并初始化buildstate结构。用于保存索引元组 - IndexBuildHeapScan
扫描表元组,并将其封装为索引元组。函数返回构建好的索引元组个数,返回函数指针buildstate- while(... != NULL)
依次遍历基表的所有元组
- while(... != NULL)
- _bt_leafbuild
将buildstate中得到的索引元组构建为索引结构- BTWriteState wstate
定义并初始化该结构。用于保存整个索引创建过程的信息。 - tuplesort_performsort
对索引元组进行排序- qsort_ssup or qsort_tuple
在内存中对索引元组进行排序。
- qsort_ssup or qsort_tuple
- _bt_load
对已排好序的索引元组,顺序读出将其插入到btree索引结构中- BTPageState *state
定义并初始化该结构,在btree中,每一层仅有一个BTPageState结构,记录每层节点的信息 - if (merge)
如果spool2不为空,即if条件成立,则将spool与spool2进行归并排序 - else
spool2为空,则索引元组都存放在spool结构中- while(依次取出spool中的每个索引元组)
- _bt_buildadd
将每个索引元组添加到索引结构- if(页面已满)
- Page opage = npage, npage = _bt_blnewpage()
设置旧页面为当前页面,并重新分配新页面作为右兄弟节点 - _bt_buildadd
这里比较巧妙的利用递归,从当前已分配的页面开始,完成后续索引数组的插入 - _bt_blwritepage
将旧页面的信息写入索引文件。流程到这里,肯定是递归函数已返回,由于旧页面已完成填充,不会再进行修改,则将其写入到索引文件中
- Page opage = npage, npage = _bt_blnewpage()
- 页面未满
- _bt_sortaddup
将当前索引元组插入到页面中 - state->btps_page = npage
设置当前页面 - state->btps_blkno = nblko
设置当前磁盘块 - state->btps_lastoff = last_off
设置当前页面内偏移位置
- _bt_sortaddup
- if(页面已满)
- _bt_uppershutdown
构建每层节点的最右节点与父节点的链接关系- _bt_initmetapage
在最右节点与父节点关系构建完成后,定义元页,每个btree索引结构由一个元页结构记录信息
- _bt_initmetapage
- BTPageState *state
- BTWriteState wstate
- BTBuildState buildstate
- btinsert
在已建立的索引基础上,插入一个新元素- index_form_tuple
将表元组首先封装为索引元组 - _bt_doinsert
将索引元组插入到索引- _bt_mkscankey
计算元组的扫描键值scan_key - _bt_search
查找包含索引元组的页面- _bt_getroot
获取索引结构的根节点 - for()
- _bt_moveright
并发性考虑 - if (当前节点为叶子节点)
跳出循环 - _bt_binsrch
不为叶子节点,在当前页面找到合适的元组itup - new_stack
分配新的BTStack结构,将当前页面信息入栈
- _bt_moveright
- _bt_getroot
- if (唯一索引)
进行唯一性检查 - _bt_findinsertloc
在当前页面查找索引元素合适的插入位置 - _bt_insertonpg
插入索引元组 - if (当前页面没有足够的剩余空间)
- _bt_findsplitloc
遍历当前页面节点,查找最佳分裂点 - _bt_split
查找到该分裂点,对其进行分裂 - _bt_insert_parent
把新节点信息插入到父节点中
- _bt_findsplitloc
- else(当前页面有存够的剩余空间)
直接插入节点
- _bt_mkscankey
- index_form_tuple
总结:上述给出了关于btree构建与在已构建的btree中插入新元素时的函数实现流程。实现逻辑思想参考(一)(二)。其中对于函数_bt_moveright,其用于解决并发访问下的问题,如当前所操作页面正好是另一事务操作被分裂的页面,则在当前页面返回所得结果后,需要查找其右兄弟页面,来返回所得的正确结果。
PostgreSQL内核分析——BTree索引的更多相关文章
- 《Windows内核分析》专题-索引目录
该篇博客整理了<Windows内核分析>专题的各篇博文,方便查找. 一.保护模式 二.进程与线程 [Windows内核分析]KPCR结构体介绍 (CPU控制区 Processor Cont ...
- mysql索引之一:索引基础(B-Tree索引、哈希索引、聚簇索引、全文(Full-text)索引区别)(唯一索引、最左前缀索引、前缀索引、多列索引)
没有索引时mysql是如何查询到数据的 索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储10 ...
- 0103MySQL中的B-tree索引 USINGWHERE和USING INDEX同时出现
转自博客http://www.amogoo.com/article/4 前提1,为了与时俱进,文中数据库环境为MySQL5.6版本2,为了通用,更为了避免造数据的痛苦,文中所涉及表.数据,均来自于My ...
- oracle中的B-TREE索引
在字段值情况不同的条件下测试B-TREE索引效率 清空共享池和数据缓冲区alter system flush shared_pool;alter system flush buffer_cache; ...
- Linux内核分析(四)----进程管理|网络子系统|虚拟文件系统|驱动简介
原文:Linux内核分析(四)----进程管理|网络子系统|虚拟文件系统|驱动简介 Linux内核分析(四) 两天没有更新了,上次博文我们分析了linux的内存管理子系统,本来我不想对接下来的进程管理 ...
- 深入浅出分析MySQL索引设计背后的数据结构
在我们公司的DB规范中,明确规定: 1.建表语句必须明确指定主键 2.无特殊情况,主键必须单调递增 对于这项规定,很多研发小伙伴不理解.本文就来深入简出地分析MySQL索引设计背后的数据结构和算法,从 ...
- PostgreSQL自学笔记:9 索引
9 索引 9.1 索引简介 索引是对数据库表中一列或多列值进行排序的一种结构,使用 索引可提高数据库中特定数据的查询速度 9.1.1 索引的含义和特点 索引是一种单独的.存储在磁盘上的数据库结构,他们 ...
- 《Linux内核分析》实践4
<Linux内核分析> 实践四--ELF文件格式分析 20135211李行之 一.概述 1.ELF全称Executable and Linkable Format,可执行连接格式,ELF格 ...
- windows7内核分析之x86&x64第二章系统调用
windows7内核分析之x86&x64第二章系统调用 2.1内核与系统调用 上节讲到进入内核五种方式 其中一种就是 系统调用 syscall/sysenter或者int 2e(在 64 位环 ...
随机推荐
- Ubuntu修改中文目录为英文
1.安装需要的软件 sudo apt install xdg-user-dirs-gtk 2.临时转换系统语言为英文,重启后会自动恢复原值的 export LANG=en_US 3.执行转换命令,弹出 ...
- MT【123】利用第一次的技巧
已知 \(r_1=0,r_{100}=0.85,(r_k\) 表示投 k 次投中的概率.) 求证:(1)是否存在\(n_0\)使得\(r_{n_0}=0.5\) (2)是否存在\(n_1\)使得\(r ...
- Java考试题之四
QUESTION 73 Given: 10: public class Hello { 11: String title; 12: int value; 13: public Hello() { 14 ...
- logger.debug的用处
原文:https://www.cnblogs.com/xiangkejin/p/6426761.html logger.debug的用处 简单的说,就是配合log的等级过滤输出 根据你log4j的配置 ...
- shell 中的操作符
1.算术操作符 2.关系操作符 3.布尔操作符 4.字符串操作符 5.文件相关操作符 算术操作符 bash shell 没有提供任何机制来执行简单的算术运算,不过我们可以借助于一些其他程序,如 exp ...
- Kubernetes之利用prometheus监控K8S集群
prometheus它是一个主动拉取的数据库,在K8S中应该展示图形的grafana数据实例化要保存下来,使用分布式文件系统加动态PV,但是在本测试环境中使用本地磁盘,安装采集数据的agent使用Da ...
- Django templates and models
models templates models and databases models 如何理解models A model is the single, definitive source of ...
- IOS方形头像如何变成圆形
方法一:直接使用UIView对应图层的cornerRadius self.layer.cornerRadius = CGRectGetWidth(self.bounds)/2.f; self. ...
- opencv 图像处理函数大全
.cvLoadImage:将图像文件加载至内存: .cvNamedWindow:在屏幕上创建一个窗口: .cvShowImage:在一个已创建好的窗口中显示图像: .cvWaitKey:使程序暂停,等 ...
- 《Science》:对年轻科学家的忠告