【转】Hadoop vs Spark性能对比
原文地址:http://www.cnblogs.com/jerrylead/archive/2012/08/13/2636149.html
基于Spark-0.4和Hadoop-0.20.2
1. Kmeans
数据:自己产生的三维数据,分别围绕正方形的8个顶点
{0, 0, 0}, {0, 10, 0}, {0, 0, 10}, {0, 10, 10},
{10, 0, 0}, {10, 0, 10}, {10, 10, 0}, {10, 10, 10}
|
Point number |
189,918,082 (1亿9千万个三维点) |
|
Capacity |
10GB |
|
HDFS Location |
/user/LijieXu/Kmeans/Square-10GB.txt |
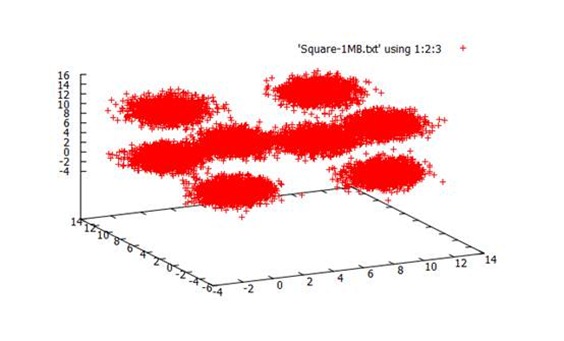
程序逻辑:
|
读取HDFS上的block到内存,每个block转化为RDD,里面包含vector。 然后对RDD进行map操作,抽取每个vector(point)对应的类号,输出(K,V)为(class,(Point,1)),组成新的RDD。 然后再reduce之前,对每个新的RDD进行combine,在RDD内部算出每个class的中心和。使得每个RDD的输出只有最多K个KV对。 最后进行reduce得到新的RDD(内容的Key是class,Value是中心和,再经过map后得到最后的中心。 |
先上传到HDFS上,然后在Master上运行
|
root@master:/opt/spark# ./run spark.examples.SparkKMeans master@master:5050 hdfs://master:9000/user/LijieXu/Kmeans/Square-10GB.txt 8 2.0 |
迭代执行Kmeans算法。
一共160个task。(160 * 64MB = 10GB)
利用了32个CPU cores,18.9GB的内存。
每个机器的内存消耗为4.5GB (共40GB)(本身points数据10GB*2,Map后中间数据(K, V) => (int, (vector, 1)) (大概10GB)
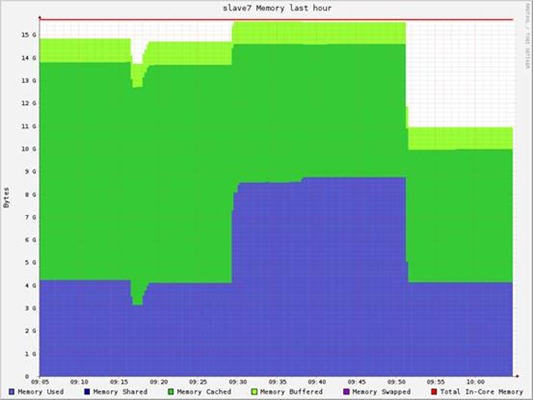
最后结果:
|
0.505246194 s Final centers: Map(5 -> (13.997101228817169, 9.208875044622895, -2.494072457488311), 8 -> (-2.33522333047955, 9.128892414676326, 1.7923150585737604), 7 -> (8.658031587043952, 2.162306996983008, 17.670646829079146), 3 -> (11.530154433698268, 0.17834347219956842, 9.224352885937776), 4 -> (12.722903153986868, 8.812883284216143, 0.6564509961064319), 1 -> (6.458644369071984, 11.345681702383024, 7.041924994173552), 6 -> (12.887793408866614, -1.5189406469928937, 9.526393664105957), 2 -> (2.3345459304412164, 2.0173098597285533, 1.4772489989976143)) |
50MB/s 10GB => 3.5min
10MB/s 10GB => 15min
在20GB的数据上测试
|
Point number |
377,370,313 (3亿7千万个三维点) |
|
Capacity |
20GB |
|
HDFS Location |
/user/LijieXu/Kmeans/Square-20GB.txt |
运行测试命令:
|
root@master:/opt/spark# ./run spark.examples.SparkKMeans master@master:5050 hdfs://master:9000/user/LijieXu/Kmeans/Square-20GB.txt 8 2.0 | tee mylogs/sqaure-20GB-kmeans.log |
得到聚类结果:
|
Final centers: Map(5 -> (-0.47785701742763115, -1.5901830956323306, -0.18453046159033773), 8 -> (1.1073911553593858, 9.051671594514225, -0.44722211311446924), 7 -> (1.4960397239284795, 10.173412443492643, -1.7932911100570954), 3 -> (-1.4771114031182642, 9.046878176063172, -2.4747981387714444), 4 -> (-0.2796747780312184, 0.06910629855122015, 10.268115903887612), 1 -> (10.467618592186486, -1.168580362309453, -1.0462842137817263), 6 -> (0.7569895433952736, 0.8615441990490469, 9.552726007309518), 2 -> (10.807948500515304, -0.5368803187391366, 0.04258123037074164)) |
基本就是8个中心点
内存消耗:(每个节点大约5.8GB),共50GB左右。
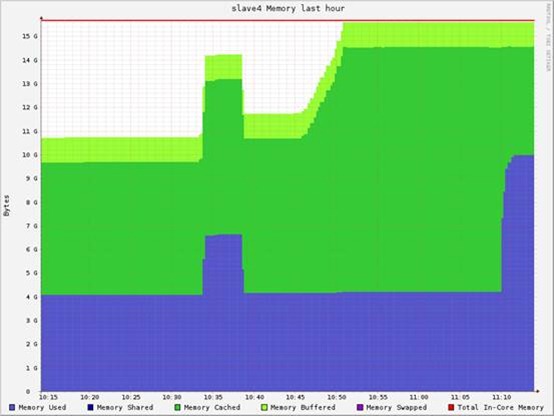
内存分析:
20GB原始数据,20GB的Map输出
|
迭代次数 |
时间 |
|
1 |
108 s |
|
2 |
0.93 s |
12/06/05 11:11:08 INFO spark.CacheTracker: Looking for RDD partition 2:302
12/06/05 11:11:08 INFO spark.CacheTracker: Found partition in cache!
在20GB的数据上测试(迭代更多的次数)
|
root@master:/opt/spark# ./run spark.examples.SparkKMeans master@master:5050 hdfs://master:900 0/user/LijieXu/Kmeans/Square-20GB.txt 8 0.8 |
Task数目:320
时间:
|
迭代次数 |
时间 |
|
1 |
100.9 s |
|
2 |
0.93 s |
|
3 |
4.6 s |
|
4 |
3.9 s |
|
5 |
3.9 s |
|
6 |
3.9 s |
迭代轮数对内存容量的影响:
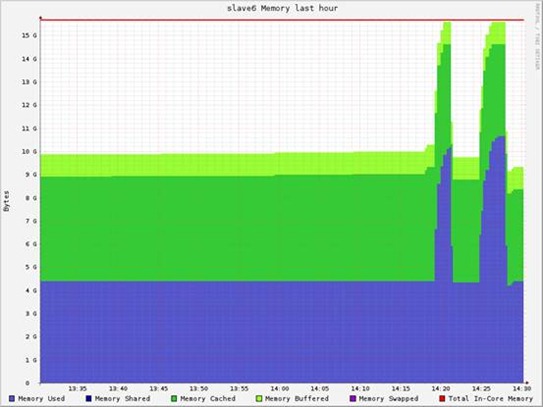
基本没有什么影响,主要内存消耗:20GB的输入数据RDD,20GB的中间数据。
|
Final centers: Map(5 -> (-4.728089224526789E-5, 3.17334874733142E-5, -2.0605806380414582E-4), 8 -> (1.1841686358289191E-4, 10.000062966002101, 9.999933240005394), 7 -> (9.999976672588097, 10.000199556926772, -2.0695123602840933E-4), 3 -> (-1.3506815993198176E-4, 9.999948270638338, 2.328148782609023E-5), 4 -> (3.2493629851483764E-4, -7.892413981250518E-5, 10.00002515017671), 1 -> (10.00004313126956, 7.431996896171192E-6, 7.590402882208648E-5), 6 -> (9.999982611661382, 10.000144597573051, 10.000037734639696), 2 -> (9.999958673426654, -1.1917651103354863E-4, 9.99990217533504)) |
结果可视化
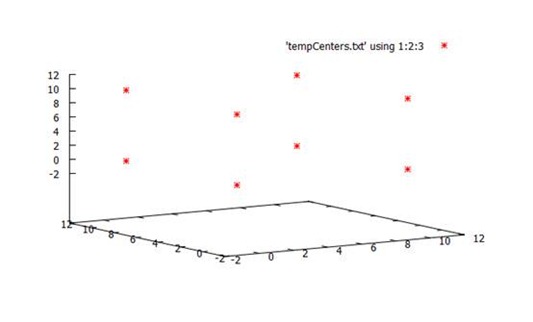
2. HdfsTest
测试逻辑:
|
package spark.examples import spark._ object HdfsTest { def main(args: Array[String]) { val sc = new SparkContext(args(0), "HdfsTest") val file = sc.textFile(args(1)) val mapped = file.map(s => s.length).cache() for (iter <- 1 to 10) { val start = System.currentTimeMillis() for (x <- mapped) { x + 2 } // println("Processing: " + x) val end = System.currentTimeMillis() println("Iteration " + iter + " took " + (end-start) + " ms") } } } |
首先去HDFS上读取一个文本文件保存在file
再次计算file中每行的字符数,保存在内存RDD的mapped中
然后读取mapped中的每一个字符数,将其加2,计算读取+相加的耗时
只有map,没有reduce。
测试10GB的Wiki
实际测试的是RDD的读取性能。
|
root@master:/opt/spark# ./run spark.examples.HdfsTest master@master:5050 hdfs://master:9000:/user/LijieXu/Wikipedia/txt/enwiki-20110405.txt |
测试结果:
|
Iteration 1 took 12900 ms = 12s Iteration 2 took 388 ms Iteration 3 took 472 ms Iteration 4 took 490 ms Iteration 5 took 459 ms Iteration 6 took 492 ms Iteration 7 took 480 ms Iteration 8 took 501 ms Iteration 9 took 479 ms Iteration 10 took 432 ms |
每个node的内存消耗为2.7GB (共9.4GB * 3)
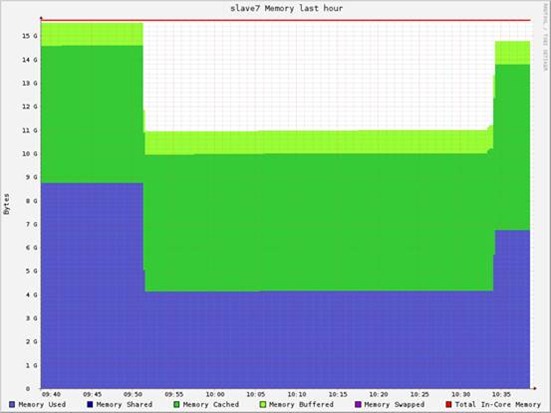
实际测试的是RDD的读取性能。
|
root@master:/opt/spark# ./run spark.examples.HdfsTest master@master:5050 hdfs://master:9000/user/LijieXu/Wikipedia/txt/enwiki-20110405.txt |
测试90GB的RandomText数据
|
root@master:/opt/spark# ./run spark.examples.HdfsTest master@master:5050 hdfs://master:9000/user/LijieXu/RandomText90GB/RandomText90GB |
耗时:
|
迭代次数 |
耗时 |
|
1 |
111.905310882 s |
|
2 |
4.681715228 s |
|
3 |
4.469296148 s |
|
4 |
4.441203887 s |
|
5 |
1.999792125 s |
|
6 |
2.151376037 s |
|
7 |
1.889345699 s |
|
8 |
1.847487668 s |
|
9 |
1.827241743 s |
|
10 |
1.747547323 s |
内存总消耗30GB左右。
单个节点的资源消耗:
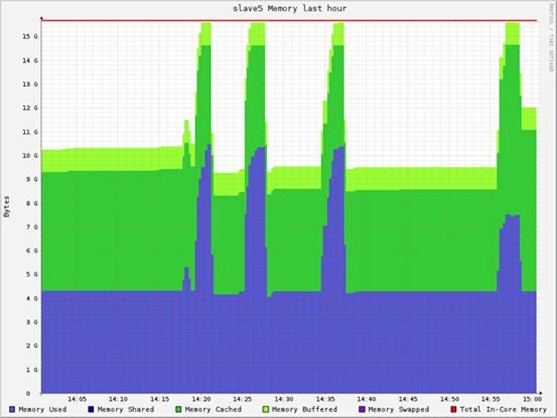
3. 测试WordCount
写程序:
|
import spark.SparkContext import SparkContext._ object WordCount { def main(args: Array[String]) { if (args.length < 2) { System.err.println("Usage: wordcount <master> <jar>") System.exit(1) } val sp = new SparkContext(args(0), "wordcount", "/opt/spark", List(args(1))) val file = sp.textFile("hdfs://master:9000/user/LijieXu/Wikipedia/txt/enwiki-20110405.txt"); val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) counts.saveAsTextFile("hdfs://master:9000/user/Output/WikiResult3") } } |
打包成mySpark.jar,上传到Master的/opt/spark/newProgram。
运行程序:
|
root@master:/opt/spark# ./run -cp newProgram/mySpark.jar WordCount master@master:5050 newProgram/mySpark.jar |
Mesos自动将jar拷贝到执行节点,然后执行。
内存消耗:(10GB输入file + 10GB的flatMap + 15GB的Map中间结果(word,1))
还有部分内存不知道分配到哪里了。
耗时:50 sec(未经过排序)
Hadoop WordCount耗时:120 sec到140 sec
结果未排序
单个节点:
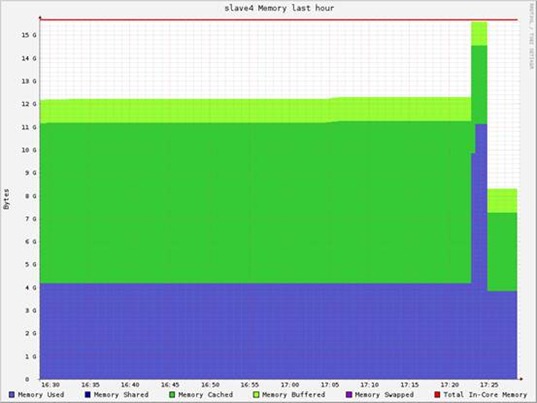
Hadoop测试
Kmeans
运行Mahout里的Kmeans
|
root@master:/opt/mahout-distribution-0.6# bin/mahout org.apache.mahout.clustering.syntheticcontrol.kmeans.Job -Dmapred.reduce.tasks=36 -i /user/LijieXu/Kmeans/Square-20GB.txt -o output -t1 3 -t2 1.5 -cd 0.8 -k 8 -x 6 |
在运行(320个map,1个reduce)
Canopy Driver running buildClusters over input: output/data
时某个slave的资源消耗情况
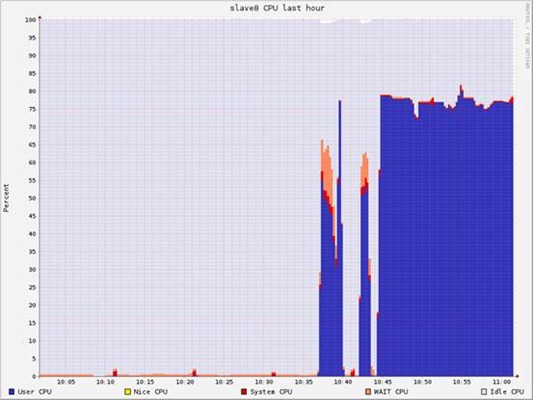
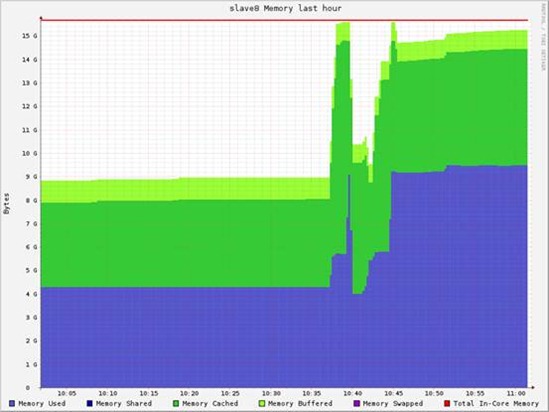
Completed Jobs
|
Jobid |
Name |
Map Total |
Reduce Total |
Time |
|
Input Driver running over input: /user/LijieXu/Kmeans/Square-10GB.txt |
160 |
0 |
1分2秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-0/part-randomSeed |
160 |
1 |
1分6秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-1 |
160 |
1 |
1分7秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-2 |
160 |
1 |
1分7秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-3 |
160 |
1 |
1分6秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-4 |
160 |
1 |
1分6秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-5 |
160 |
1 |
1分5秒 |
|
|
KMeans Driver running clusterData over input: output/data |
160 |
0 |
55秒 |
|
|
Input Driver running over input: /user/LijieXu/Kmeans/Square-20GB.txt |
320 |
0 |
1分31秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-0/part-randomSeed |
320 |
36 |
1分46秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-1 |
320 |
36 |
1分46秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-2 |
320 |
36 |
1分46秒 |
|
|
KMeans Driver running runIteration over clustersIn: output/clusters-3 |
320 |
36 |
1分47秒 |
|
|
KMeans Driver running clusterData over input: output/data |
320 |
0 |
1分34秒 |
运行多次10GB、20GB上的Kmeans,资源消耗
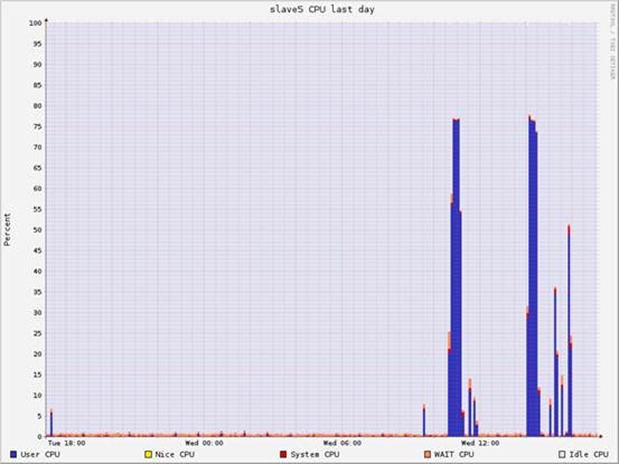
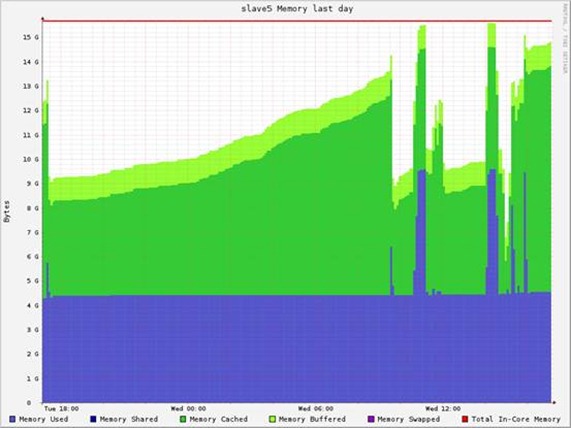
Hadoop WordCount测试
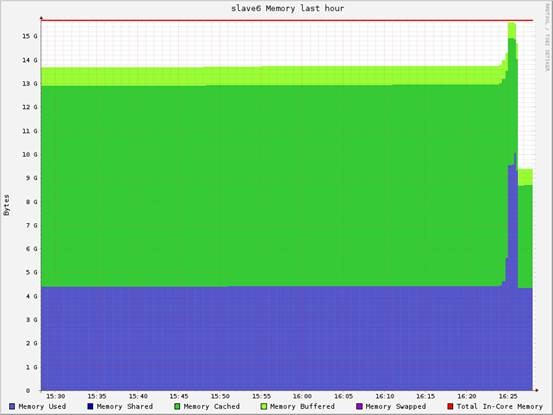
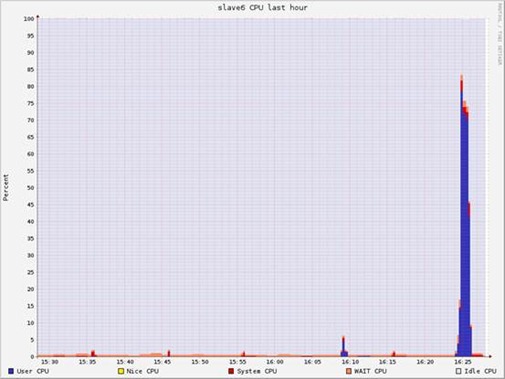
Spark交互式运行
进入Master的/opt/spark
运行
|
MASTER=master@master:5050 ./spark-shell |
打开Mesos版本的spark
在master:8080可以看到framework
Active Frameworks
|
ID |
User |
Name |
Running Tasks |
CPUs |
MEM |
Max Share |
Connected |
|
201206050924-0-0018 |
root |
0 |
0 |
0.0 MB |
0.00 |
2012-06-06 21:12:56 |
|
scala> val file = sc.textFile("hdfs://master:9000/user/LijieXu/Wikipedia/txt/enwiki-20110405.txt") scala> file.first scala> val words = file.map(_.split(' ')).filter(_.size < 100) //得到RDD[Array[String]] scala> words.cache scala> words.filter(_.contains("Beijing")).count 12/06/06 22:12:33 INFO SparkContext: Job finished in 10.862765819 s res1: Long = 855 scala> words.filter(_.contains("Beijing")).count 12/06/06 22:12:52 INFO SparkContext: Job finished in 0.71051464 s res2: Long = 855 scala> words.filter(_.contains("Shanghai")).count 12/06/06 22:13:23 INFO SparkContext: Job finished in 0.667734427 s res3: Long = 614 scala> words.filter(_.contains("Guangzhou")).count 12/06/06 22:13:42 INFO SparkContext: Job finished in 0.800617719 s res4: Long = 134 |
由于GC的问题,不能cache很大的数据集。
【转】Hadoop vs Spark性能对比的更多相关文章
- Hadoop vs Spark性能对比
http://www.cnblogs.com/jerrylead/archive/2012/08/13/2636149.html Hadoop vs Spark性能对比 基于Spark-0.4和Had ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- PageRank在Hadoop和spark下的实现以及对比
关于PageRank的地位,不必多说. 主要思想:对于每个网页,用户都有可能点击网页上的某个链接,例如 A:B,C,D B:A,D C:AD:B,C 由这个我们可以得到网页的转移矩阵 A ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Hadoop和Spark的Shuffer过程对比解析
Hadoop Shuffer Hadoop 的shuffer主要分为两个阶段:Map.Reduce. Map-Shuffer: 这个阶段发生在map阶段之后,数据写入内存之前,在数据写入内存的过程就已 ...
- [Big Data]从Hadoop到Spark的架构实践
摘要:本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过程. 当下,Spark已经在国内得到了广泛的 ...
- [转载] 从Hadoop到Spark的架构实践
转载自http://www.csdn.net/article/2015-06-08/2824889 http://www.zhihu.com/question/26568496 当下,Spark已经在 ...
- [Spark性能调优] 第二章:彻底解密Spark的HashShuffle
本課主題 Shuffle 是分布式系统的天敌 Spark HashShuffle介绍 Spark Consolidated HashShuffle介绍 Shuffle 是如何成为 Spark 性能杀手 ...
- 从Hadoop到Spark的架构实践
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆:同年,Spark Meetup在北京.上海.深圳和杭州四个城市举办,其中仅北京就 ...
随机推荐
- python5-常用模块
collection 模块 # pypi 可以查询python的模块在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counte ...
- MDX示例:求解中位数、四分位数(median、quartile)
一个人力资源咨询集团通过网络爬虫采集手段将多个知名招聘网站上发布的求职和招聘等信息准实时采集到自己的库里,形成一个数据量浩大的招聘信息库,跟踪全国招聘和求职的行业.工种.职位.待遇等信息,并通过商业智 ...
- Ansible配置文件
官方配置文件文档 Ansible安装完成之后默认配置文件为:/etc/asnible/ansible.cfg Ansible配置文件内容: cat ansible.cfg # config file ...
- 我的成长比价系列:java web开发过程中遇到的错误一:sql语句换行错误
字符串换行导致的错误,确切的说是马虎的错误,自己在编写简单的servlet项目时,在StudentDao.java 中的 查询语句:String sql= "SELECT Type,fl ...
- VSTO学习笔记
文档类型程序发布: 安装.NetFrameWork Visual Studio 2010 Tools for Office Runtime 4.0下载地址: http://www.microsoft. ...
- 【WinRT】多语言化应用程序名称
在Windows Phone 8的时候,要对应用程序在列表中显示的名称和锁定到开始屏幕的磁贴的名称进行多语言化是十分困难的,需要使用C++建立一个多语言资源库.但是,在WinRT中,这变得简单多了,无 ...
- Sharepoint/Project Server 看不到“安全性”菜单以及子菜单
在Sharepoint/Project Server 构建后,左侧看不到看不到“服务器设置”菜单,在设置菜单后左侧出现“服务器设置”菜单,但是依然在右侧看不到“安全性”菜单以及子菜单. (这个图是借的 ...
- .net core grpc consul 实现服务注册 服务发现 负载均衡(二)
在上一篇 .net core grpc 实现通信(一) 中,我们实现的grpc通信在.net core中的可行性,但要在微服务中真正使用,还缺少 服务注册,服务发现及负载均衡等,本篇我们将在 .net ...
- deepin mysql安装
1.安装mysql 更新仓库:sudo apt-get update 安装:sudo apt-get install mysql-server mysql-client 问题:安装mysql5. ...
- 第五章 ReentrantLock源码解析1--获得非公平锁与公平锁lock()
最常用的方式: int a = 12; //注意:通常情况下,这个会设置成一个类变量,比如说Segement中的段锁与copyOnWriteArrayList中的全局锁 final Reentrant ...