SQL Server-聚焦查询计划Stream Aggregate VS Hash Match Aggregate(二十)
前言
之前系列中在查询计划中一直出现Stream Aggregate,当时也只是做了基本了解,对于查询计划中出现的操作,我们都需要去详细研究下,只有这样才能对查询计划执行的每一步操作都了如指掌,所以才有了本文的出现,简短的内容,深入的理解,Always to review the basics。
Stream Aggregate
Stream Aggregate通过单列或者多列来对行进行分组并且对指定的查询来计算聚合表达式。最常见的聚合类型如SUM、COUNT、SUM、AVG、MIN、MAX,当我们执行这些聚合函数时在查询计划中就会出现Stream Aggregate,Stream Aggregate是非常快的,因为它需要在输入时通过在GROUP BY中指定的列进行排序。如果聚合中的数据没有进行排序此时会通过Sort进行预排序或者使用索引查找或者索引扫描来提前预排序数据。之前我们讨论过出现Stream Aggregate有三种方式分别为:聚合函数聚合,分组聚合,DISTINCT聚合,实际上只有两种,DISTINCT内部就用到了分组,这里我们将Stream Aggregate分为两种类型,一种是标量聚合,另外一种则是分组聚合。我们举一个标量聚合的例子,也就是返回单值聚合。
标值聚合
USE TSQL2012
GO SELECT COUNT(*)
FROM Sales.Orders

下面我们再来分组聚合的例子
USE TSQL2012
GO SELECT custid
FROM Sales.Orders
GROUP BY custid

上述就是Stream Aggregate两种类型的例子,关于标量聚合比较简单直接利用聚合函数就行,下面我们主要详细讲解这两种类型中的分组聚合。
分组聚合
我们来结合SQL Server 2012基础教程来看一个简单的例子
USE TSQL2012
GO SELECT custid, COUNT(shipcity) AS [shipcity_count]
FROM Sales.Orders
GROUP BY custid

上述查询计划比较简单我们来解释下,首先通过默认主键创建的聚集索引来读取表中行数据,接着通过GROUP BY上指定的列custid来进行排序,我们看到其排序操作具体信息就知道,如下。接着遍历所有custid,所有行被读取,开始一行行读取并计算其聚合表达式的值。重复处理直到完成为止。

对于通过流聚合对custid进行分组的示意图大概如下:

上述由于未对custid创建索引导致所以会通过Sort来进行排序,毫无疑问导致查询缓慢,这里我们对custid创建非聚集索引再来看看情况
CREATE NONCLUSTERED INDEX idx_nc_custid ON Sales.Orders(custid)

此时查询将会充分利用索引,它会通过使用索引排序来进行聚合计算,所以就不会再利用Sort来排序导致性能低下,通过上述我们知道,在进行Stream Aggregate之前事实上在指定的分组列上创建索引来预先排序会提高查询性能,而不需要再去利用Sort进行排序而耗费不必要的时间。上述我们已经说过在进行排序要么在GROUP BY上指定的列通过创建索引查找或者索引排序,如果GROUP BY中的列没有创建索引此时利用Sort来进行显示排序,如下显示指定ORDER BY custid来排序和没有指定的话结果依然都是使用Sort来排序,此时Stream Aggregate,其实这种说法不太准确,因为在SQL Server中有两种聚合方式,一种是Stream Aggregate,另外一种则是Hash Match Aggregate。
USE TSQL2012
GO SELECT custid, COUNT(shipcity) AS [shipcity_count]
FROM Sales.Orders
GROUP BY custid
ORDER BY custid
自从SQL Server 7之后就出现了Stream Aggregate和Hash Aggregate两种聚合方式,也就是说上述我们稍作修改查询计划就变成了Hash Aggregate的形式。
USE TSQL2012
GO DBCC RULEOFF('GbAggToStrm');
GO SELECT custid, COUNT(shipcity) AS [shipcity_count]
FROM Sales.Orders
GROUP BY custid
OPTION(RECOMPILE)
GO DBCC RULEON('GbAggToStrm');
上述GbAggToStrm是什么鬼,其实如果查询计划中走的Stream Aggregate操作的话,也就说它走的是GbAggToStrm规则(GROUP BY Aggregate To Stream ),但是这里我们关闭了查询计划本该走的Stream Aggregate操作即GbAggToStrm规则,所以此时它将只能走Hash Aggregate。所以到这里说明在排序时即使指定了ORDER BY操作有可能是多余的,但是如果我们不指定的话,要是我们希望返回的结果集是排序的,此时要是走的Hash Aggregate,结果返回的结果集将是无序的,导致我们得不到想要的结果集,所以还是希望在排序时指定ORDER BY操作,这样能够避免不必要的情况发生。
DISTINCT在Hash Match Aggregate和Stream Aggregate和DISTINCT Sort中的使用
当查询中用到了DISTINCT关键字时,此时查询计划有可能走Stream Aggregate,也有可能走的是Hash Match Aggregate。所以在这里我们分析下什么时候会用Hash Match Aggregate,什么时候又会用到Stream Aggregate。说到底DISTINCT关键字时用来去重的,在SQL Server中利用DISTINCT关键字来去重其查询计划走的方式分为两种,一种是在哈希表中建立唯一值,另外一种则是将行进行排序分配到组中然后只返回组中的一个值即可。所以在SQL Server中使用Hash Match Aggregate来实现哈希表,使用Stream Aggregate或者DISTINCT Sort来对数据进行排序去重。
使用DISTINCT关键字走DISTINCT Sort
当我们如下直接利用DISTINCT来查询时就是利用的DISTINCT Sort来排序去重。
USE TSQL2012
GO select DISTINCT custid
FROM Sales.Orders
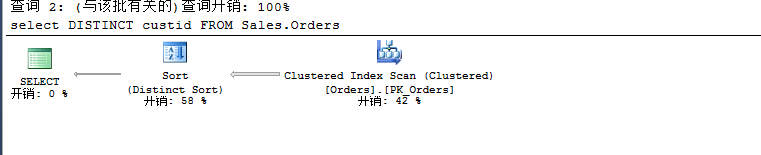
虽然很明确走的Sort,但是这是经过SQL查询引擎优化过后才有的,最原始的情况是先进行Sort接着进行Stream Aggregate,下面我们关闭Sort的规则看看。
USE TSQL2012
GO DBCC RULEOFF('GbAggToSort')
SELECT DISTINCT custid
FROM Sales.Orders
OPTION(RECOMPILE)
DBCC RULEON('GbAggToSort')

使用DISTINCT关键字走Hash Match Aggregate
当未在列SomeColumn创建索引时我们进行如下查询
USE TSQL2012
GO SELECT DISTINCT SomeColumn
FROM dbo.BigTable

接下来我们在列上创建索引
CREATE NONCLUSTERED INDEX idx_noncls_somecolumn ON dbo.BigTable(SomeColumn)

在创建索引时此时查询计划走的却是Stream Aggregate,也就是说当利用DISTINCT关键字查询时且列已经进行了排序,此时查询计划走Stream Aggregate。那什么时候用Hash Match Aggregate呢,上述对列未创建索引时走的是Hash Match Aggregate因为数据量比较大此时还利用了并行计算,换句话说当对列未创建索引时且数据量非常大同时分组比较少时,查询计划更加更倾向于走Hash Match Aggregate,输入大量的数据通过Hash Match Aggregate结合并行计算效率也非常高,当然分组较少更好,此时不会太占用哈希表。接下来我们限制查询结果集的条数。
USE TSQL2012
GO SELECT DISTINCT TOP SomeColumn
FROM dbo.BigTable

此时查询计划不再是Hash Match Aggregate代替的是Hash Match(Flow Distinct)我们看下msdn关于Flow Distinct的解释:Flow Distinct逻辑运算符用于通过扫描输入来删除重复项。虽然Distinct 运算符在生成任何输入前消耗所有的输入,但FlowDistinct 运算符在从输入获得行时返回每行(除非该行是一个重复项,若是这样则删除该行)
也就是说DISTINCT直接就过滤了重复行,而Flow Distict则获得每行时并返回每一行,这就是Flow Distinct,它的出现依赖于在查询计划中估计唯一值的数量,当我们将TOP的数量设置为接近100万或者比100万还少一点时此时走的是Hash Match Aggregate。到此我们关于Hash Match Aggregate和Stream Aggregate的分析算是结束了,我们下个基本结论:
Hash Match Aggregate和Stream Aggregate分析结论:
(1)查询中有DISTINCT关键字时:当在查询列上创建索引时即列进行了排序时此时走Stream Aggregate,当数据量非常大时且未创建索引时此时一般走的是Hash Match Aggregate并结合并行计算,其余情况则是走的Distinct Sort。
(2)查询中没有DISTINCT关键字时,对于标量聚合和分组聚合走的是Stream Aggregate。
总结
好了本节关于Hash Match Aggregate和Stream Aggregate的介绍就到此为止,基本算是了解,太复杂的也没去过多探讨,这是DBA的事情了,下一节我们穿插讲讲关于计算列持久化系列文章,简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦查询计划Stream Aggregate VS Hash Match Aggregate(二十)的更多相关文章
- [译]SQL Server 之 查询计划的简单参数化
SQL Server能把一些常量自动转化为参数,以重用这些部分的查询计划. SELECT FirstName, LastName, Title FROM Employees WHERE Employe ...
- [译]SQL Server 之 查询计划缓存和重编译
查询优化是一个复杂而且耗时的操作,所以SQL Server需要重用现有的查询计划.查询计划的缓存和重用在多数情况下是有益的的,但是在某些特殊的情况下,重编译一个查询计划可能能够改善性能. SELECT ...
- 50种方法优化SQL Server数据库查询
查询速度慢的原因很多,常见如下几种: 1.没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷) 2.I/O吞吐量小,形成了瓶颈效应. 3.没有创建计算列导致查询不优化. 4.内存不足 ...
- 转载 50种方法优化SQL Server数据库查询
原文地址 http://www.cnblogs.com/zhycyq/articles/2636748.html 50种方法优化SQL Server数据库查询 查询速度慢的原因很多,常见如下几种: 1 ...
- Sql Server参数化查询之where in和like实现详解
where in 的参数化查询实现 首先说一下我们常用的办法,直接拼SQL实现,一般情况下都能满足需要 string userIds = "1,2,3,4"; using (Sql ...
- SQL Server 优化-执行计划
对于SQL Server的优化来说,优化查询可能是很常见的事情.由于数据库的优化,本身也是一个涉及面比较的广的话题, 因此本文只谈优化查询时如何看懂SQL Server查询计划.毕竟我对SQL Ser ...
- 【转】Sql Server参数化查询之where in和like实现详解
转载至:http://www.cnblogs.com/lzrabbit/archive/2012/04/22/2465313.html 文章导读 拼SQL实现where in查询 使用CHARINDE ...
- 了解Sql Server的执行计划
前一篇总结了Sql Server Profiler,它主要用来监控数据库,并跟踪生成的sql语句.但是只拿到生成的sql语句没有什么用,我们可以利用这些sql语句,然后结合执行计划来分析sql语句的性 ...
- 理解SQL Server的查询内存授予(译)
此文描述查询内存授予(query memory grant)在SQL Server上是如何工作的,适用于SQL 2005 到2008. 查询内存授予(下文缩写为QMG)是用于存储当数据进行排序和连接时 ...
随机推荐
- accept_mutex与性能的关系 (nginx)
注:运行环境CentOS 6+ 背景 在对启动了20个worker的nginx进行压力测试的时候发现:如果把配置文件中event配置块中的accept_mutex开关打开(1.11.3版 ...
- Connect() 2016 大会的主题 ---微软大法好
文章首发于微信公众号"dotnet跨平台",欢迎关注,可以扫页面左面的二维码. 今年 Connect 大会的主题是 Big possibilities. Bold technolo ...
- mybatis plugins实现项目【全局】读写分离
在之前的文章中讲述过数据库主从同步和通过注解来为部分方法切换数据源实现读写分离 注解实现读写分离: http://www.cnblogs.com/xiaochangwei/p/4961807.html ...
- Java—恶心的java.lang.NumberFormatException解决
项目中要把十六进制字符串转化为十进制, 用到了到了Integer.parseInt(str1.trim(), 16):这个是不是后抛出java.lang.NumberFormatException异常 ...
- 给缺少Python项目实战经验的人
我们在学习过程中最容易犯的一个错误就是:看的多动手的少,特别是对于一些项目的开发学习就更少了! 没有一个完整的项目开发过程,是不会对整个开发流程以及理论知识有牢固的认知的,对于怎样将所学的理论知识应用 ...
- git基本操作
一.在Windows平台上安装Git,可以下载一个msysGit的安装包,点击exe即可安装运行.安装包下载地址:https://git-for-windows.github.io/备注:git命令行 ...
- cmd窗口编码设置
问题描述:不知道误操作了什么,导致cmd窗口的鼠标显示位置出现错位,如下: 现在要将鼠标位置调整回来. 使用工具:cmd. 操作步骤: 1.查看cmd属性可以看到 可以看到是UTF-8编码格式的,我们 ...
- BZOJ 3110: [Zjoi2013]K大数查询 [树套树]
3110: [Zjoi2013]K大数查询 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 6050 Solved: 2007[Submit][Sta ...
- Java集合---ConcurrentHashMap原理分析
集合是编程中最常用的数据结构.而谈到并发,几乎总是离不开集合这类高级数据结构的支持.比如两个线程需要同时访问一个中间临界区(Queue),比如常会用缓存作为外部文件的副本(HashMap).这篇文章主 ...
- mono for android 自定义titleBar Actionbar 顶部导航栏 修改 样式 学习
以前的我是没有做笔记的习惯的,学习了后觉得自己能记住,但是最近发现很多学的东西都忘记了,所有现在一有新的知识,就记下来吧. 最近又做一个mono for android 的项目 这次调整比较大,上次做 ...