【教程】手把手教你如何利用工具(IE9的F12)去分析模拟登陆网站(百度首页)的内部逻辑过程
【前提】
想要实现使用某种语言,比如Python,C#等,去实现模拟登陆网站的话,首先要做的事情就是使用某种工具,去分析本身使用浏览器去登陆网页的时候,其内部的执行过程,内部逻辑。
此登陆的逻辑过程,主要指的是,需要访问哪些地址,提交哪些http请求,其中包含了有哪些查询关键字,涉及到哪些post的数据,涉及到哪些cookie等等。
只有知道了内部逻辑过程,才能谈及,使用某种语言去实现,模拟,此套登陆网站的过程。
关于分析工具,其实有很多种,此处选用,之前在
【总结】浏览器中的开发人员工具(IE9的F12和Chrome的Ctrl+Shift+I)-网页分析的利器
所介绍的IE9的F12。
在分析之前,虽然不需要你有太多的网络相关的基础,但是,如果真正想要熟悉分析网站抓取,模拟网站登陆的话,还是需要了解相关的知识的。
其中,和cookie相关的内容,可参考:
【经验总结】Http,网页访问,request,response相关的知识
【使用IE9的F12分析登陆百度首页的内部逻辑过程】
1.准备好工具,配置好工具
打开IE9,打开百度首页:
按F12,调出F12工具,再切换到Network界面:
然后点击“Start capturing”开始调试:
下面就来利用F12来调试,分析登陆的内部逻辑。
不过,在调试之前,先去做一些配置上的准备工作:
(1)设置网页跳转时,已抓取的数据不被清除掉
即设置:
Tools -> Clear entries on navigate中的Console和Network,都取消掉:
![]()
这样,在网页分析过程中,由于从一个页面跳转到另外一个页面,所抓取的到内容,就不会被清空掉了。
(2)清除旧的cookie和缓存
为了后续的调试,不被之前的已登陆的账户的(缓存和cookie等)信息所影响,所以去都清除掉:
![]()
其中,简单解释一下是:
A。2个和清除cookie有关的:
Cache->Clear session cookies:清除当前会话,即访问当前这么一堆网页所涉及的cookie
Cache->Clear cookies for domain:清楚和当前网页所属的domain,此处为.baidu.com相关的cookie;
B。2个和缓存cache有关的
另外,为了清除的更彻底,往往也顺带把cache,即缓存的网页,也顺带都清理了:
Cache->Clear browser cache
Cache->Clear browser cache for this domain
更多关于F12如何使用的事情,还是去参考之前所写的:
【总结】浏览器中的开发人员工具(IE9的F12和Chrome的Ctrl+Shift+I)-网页分析的利器
接下来的所有操作,实际上就是,在IE9中,手动操作一遍,登陆百度首页的过程而已。
2.模拟操作过程,利用工具抓取所需的整个过程
点击“登陆”:
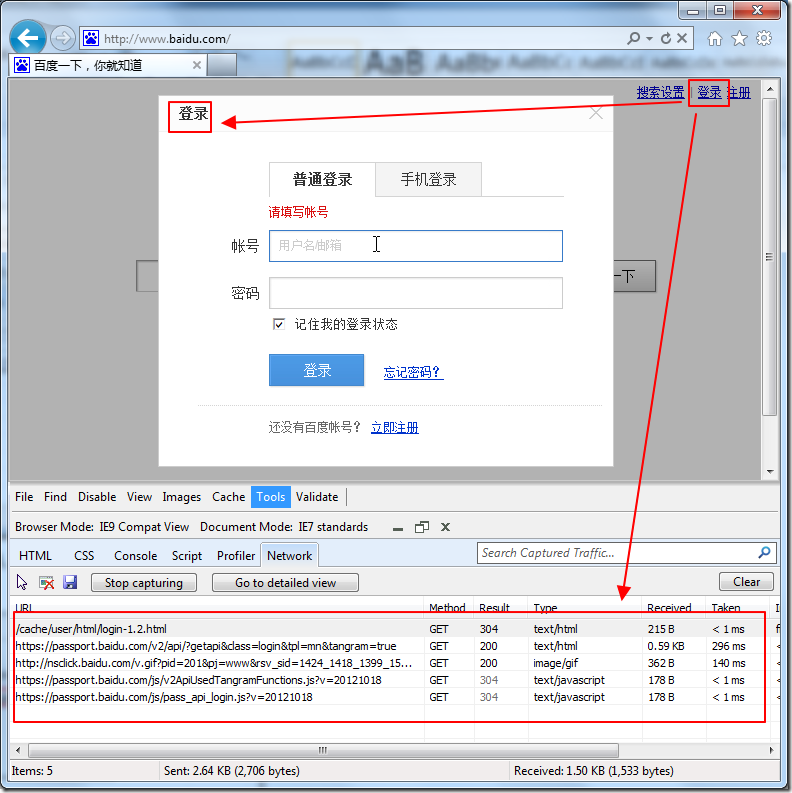
可以看到,除了网页中跳出你所熟悉的登陆对话框之外,F12调试窗口中,就已经抓取到很多内容了。
然后输入用户名和密码,正常登陆:
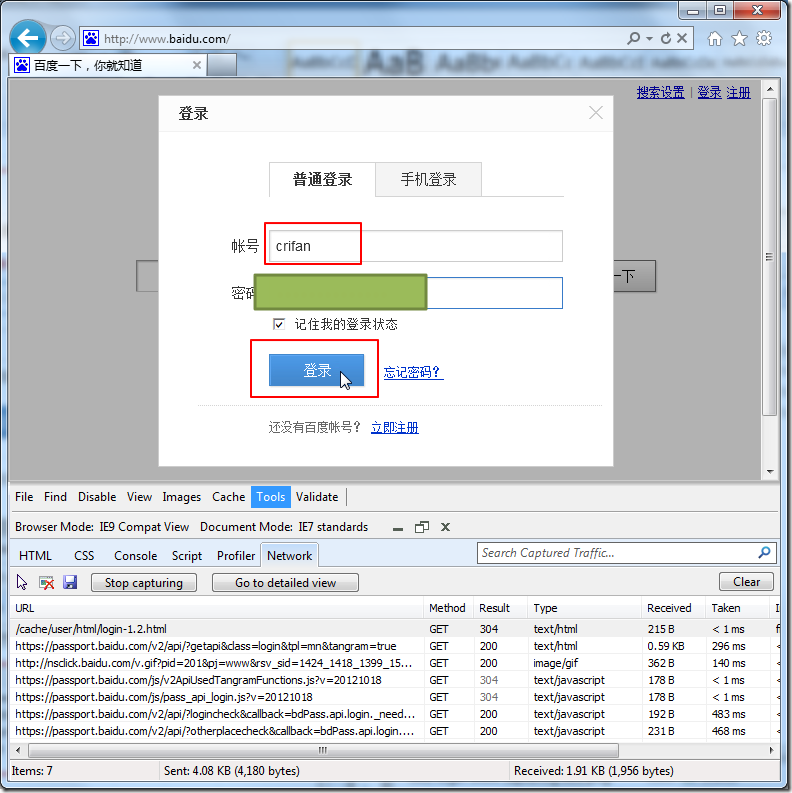
然后,就可以看到网页调转到了:
http://www.baidu.com/index.php
以及,对应的抓取到了很多内容:
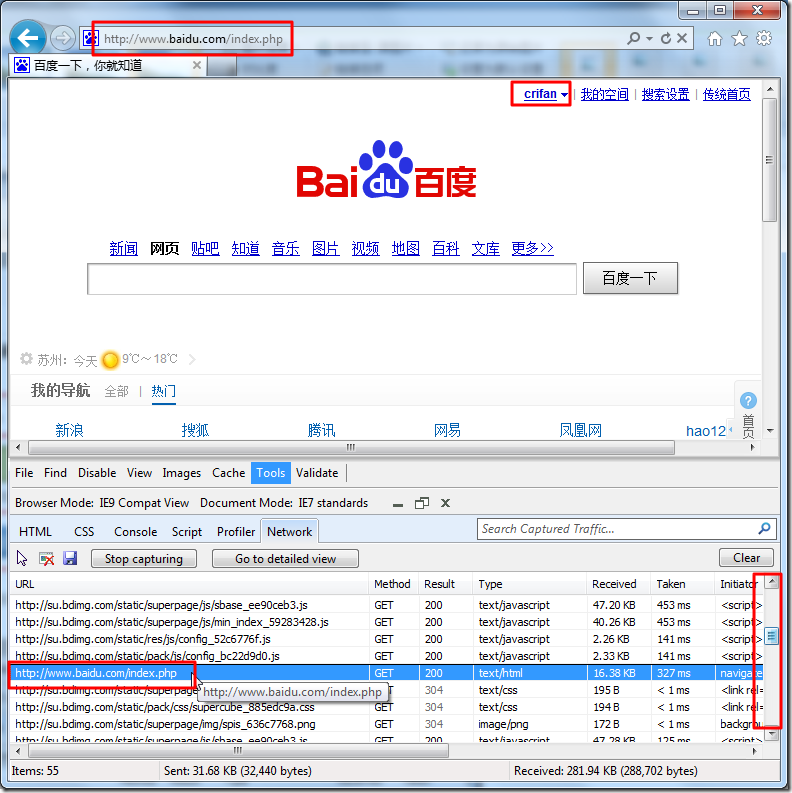
好了,到此为止,我们的操作,基本就结束了。
剩下的,就是从我们所已经抓取到的信息中,找到是如何登陆的。
3.分析网站登陆的内部逻辑过程
3.1找到登陆网站所涉及的最核心的地址
对于熟悉的人,可以直接从那一堆的url中,找到哪个是登陆的页面。
而现在假定你不熟悉,教你如何找到真正的有价值的信息。
对于此处,我们可以想到的一种办法是,通过直接搜索密码,而搜到哪里发送了我们的密码:
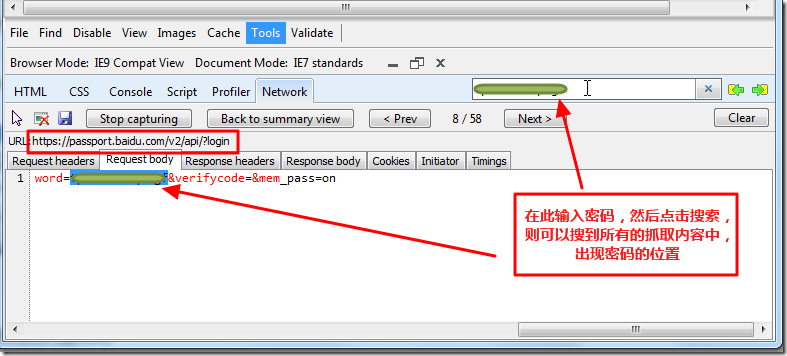
【小提示:显示内容时,设置为 自动换行】
当抓取出来的Request Body,Response Body等部分的内容中,单行内容太长,一行显示不下,不方便查看时,可以点击右键,选择Word wrap:
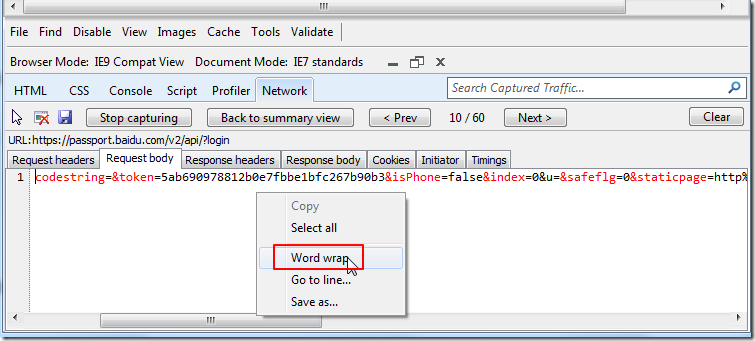
即可实现自动换行显示的效果了,方便查看了:
此处,很容易看到,此处和我们密码相关的url地址为:
https://passport.baidu.com/v2/api/?login
即,以后如果想要写代码的话,所要访问的url地址,就是这个地址了。
3.2分析所提交的数据(post data)中的参数和值
而且,此处的Request Body,就是对应的http的POST请求中所要提交的数据,简称为post data。
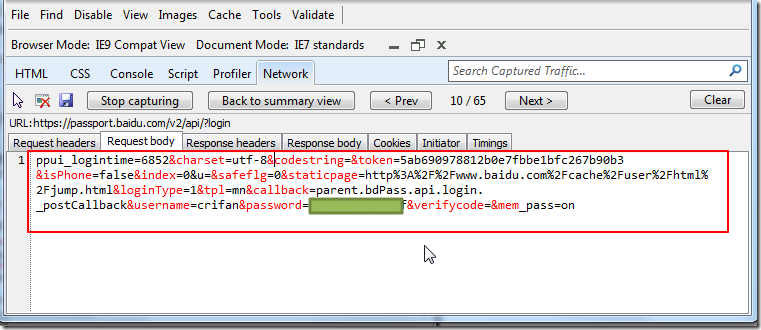
此处Request Body中完整的数据为(注:以下数据,是另外一次分析出来的结果,对解释分析过程无影响):
| ppui_logintime=6852&charset=utf-8&codestring=&token=5ab690978812b0e7fbbe1bfc267b90b3&isPhone=false&index=0&u=&safeflg=0&staticpage=http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fhtml%2Fjump.html&loginType=1&tpl=mn&callback=parent.bdPass.api.login._postCallback&username=crifan&password=xxxxxx&verifycode=&mem_pass=on |
然后处理一下就是:
| ppui_logintime=6852& charset=utf-8& codestring=& token=5ab690978812b0e7fbbe1bfc267b90b3& isPhone=false& index=0& u=& safeflg=0& staticpage=http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fhtml%2Fjump.html& loginType=1& tpl=mn& callback=parent.bdPass.api.login._postCallback& username=crifan& password=xxxxxx& verifycode=& mem_pass=on |
再去掉后面的那个&字符,变为:
| ppui_logintime=6852 charset=utf-8 codestring= token=5ab690978812b0e7fbbe1bfc267b90b3 isPhone=false index=0 u= safeflg=0 staticpage=http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fhtml%2Fjump.html loginType=1 tpl=mn callback=parent.bdPass.api.login._postCallback username=crifan password=xxxxxx verifycode= mem_pass=on |
很明显,此处就是模拟网站登录的核心数据了,是在写代码时,对于
url=https://passport.baidu.com/v2/api/?login
提交POST请求时,所以要发送的一些参数和值了。
此处,再重新简要的介绍一下,模拟登陆网站的基本逻辑:
想要模拟网站登陆,就要知道,要向什么url地址,发送什么样的数据,GET请求还是POST请求。
- GET请求只从服务器请求数据,不需要所谓的post data,但是往往需要在url后面添加上对应的?para1=val1¶2=value2之类的形式,此部分叫做query parameter,其本质上,有点类似于post data;
- POST请求,在发送请求时,还需要提供对应的post data,此处即对应着IE9的F12中的Request Body。
- 而余下的,发送请求时的其他相关参数设置,主要就是设置很多基本的参数,包括user-agent等,此处对应着那个Request Headers
而提交请求后,网站的服务器会给你反馈,返回数据和信息给你。
此处对应的就是Response Headers和Response Body。
经常地,其中还涉及到cookie等信息。在发送之前,准备好,发送给服务器,服务器返回的信息中,往往也包含,更新后,cookie的值。
对应的这部分内容,是Cookies部分。
此处,把所有的内容,分别截图如下:
Request Headers
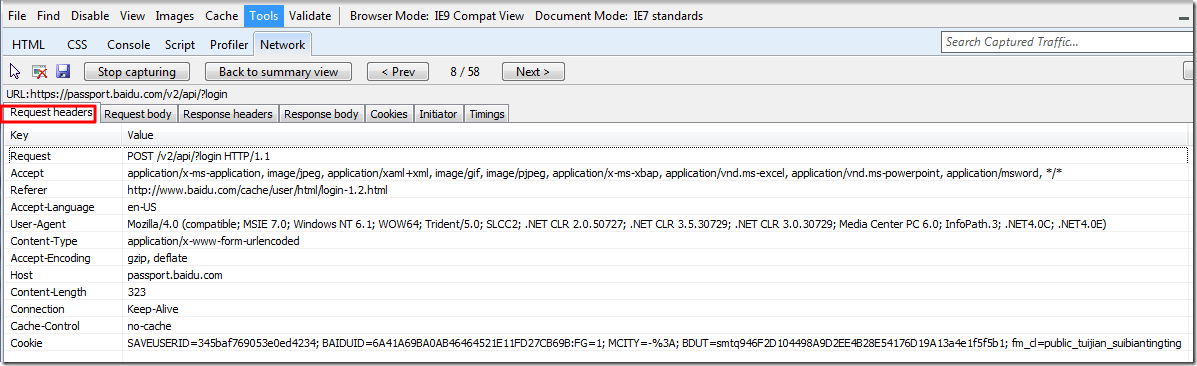
Request Body:

Response Headers:
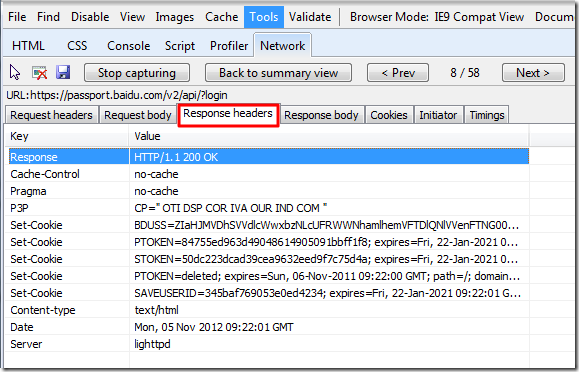
Response body:
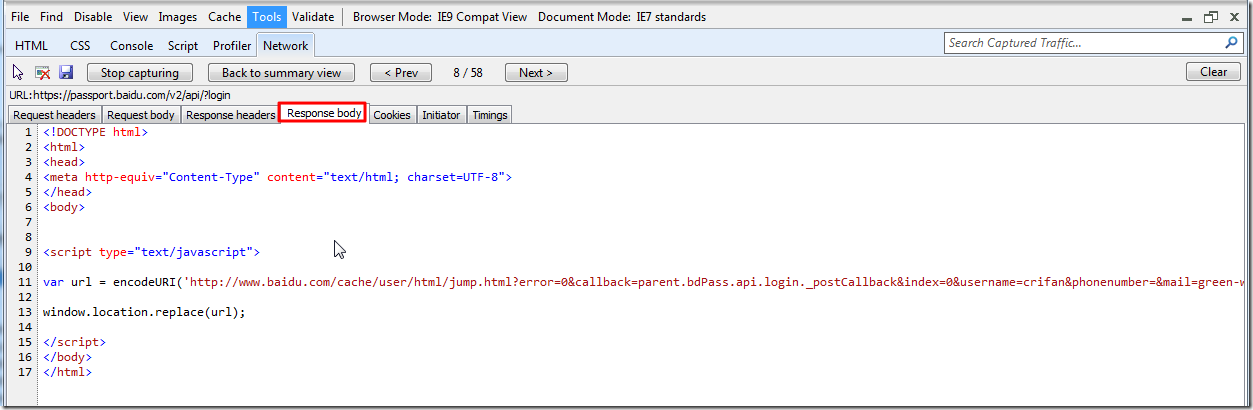
Cookies:
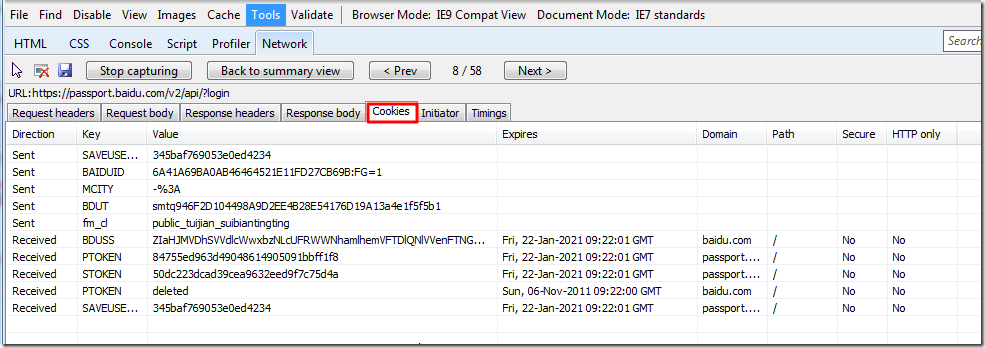
接下来,就是分析,如何获得所需的信息。
先分析上述的post data中的值:
| ppui_logintime=6852 charset=utf-8 codestring= token=5ab690978812b0e7fbbe1bfc267b90b3 isPhone=false index=0 u= safeflg=0 staticpage=http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fhtml%2Fjump.html loginType=1 tpl=mn callback=parent.bdPass.api.login._postCallback username=crifan password=xxxxxx verifycode= mem_pass=on |
都是怎么来的。
分析值是如何来的,以及顺带说说,写代码时,如何设置这些值。
在此之前,先解释一下,在代码中关于如何设置这些参数的值的规律和经验:
(1)对于有参数,但是值为空的哪些参数,一般来说,都是可以省略的。
即写代码时,是可以去掉,忽略掉,这些参数的;
当然,如果你抓取出来的参数是有值的,则需要考虑其值是怎么得到的,是否有意义,否则随便忽略掉某些参数,可能会导致模拟登陆失败的。
(2)对于,看不太懂的参数的值的情况下,不妨先使用抓取出来的数据
尤其是一些参数,看不太懂,而且其值又明显不是那种,很可能会变化的数字之类的值,则一般情况下,也都是固定的值,所以,即使对于参数和值本身不太了解,也无所谓,也都可以直接在代码中,直接使用抓取出来的数据即可。
即使会导致出错,一般来说,也可以通过后续的多次抓取和分析,看出来该值真正的规律。
在上面那一堆参数和值中:
(1)一些很明显,是固定的值,不需要考虑太多的值有:
charset=utf-8 -> 表示当前网页的编码是utf-8,我们写代码照着写即可,不需要改;
codestring= ->此处为空,所以也可以不理会;
isPhone=false -> 很明显,此处是通过PC登陆百度的,不是通过手机类的移动设备登陆的,所以是false。所以写代码时,也设置为false即可;
细心的读者,也很容易回想起,此处是对应着之前的登陆界面中的“手机登陆”:
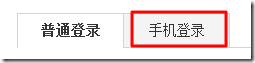
如果是我们是通过“手机登陆”百度时,不出意外的话,肯定参数是isPhone=true
index=0 -> 未知,但是也没看出来是什么含义,所以也直接设置为0即可;
u=-> 空值,同样设置空值即可;
safeflg=0 -> 未知,所以也可以暂且不管,同样设置为0即可。
username=crifan -> 很明显,是我们的账号,不多解释;
password=xxxxxx -> 同理,是对应的密码;
verifycode= ->此处为空,所以也可以不管;
mem_pass=on -> 很明显,是memory password的所写,即记住密码,对应的页面是,我们已经勾选的"记住我的登陆状态":
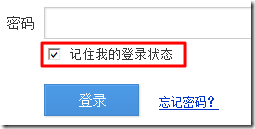
(2)另外一些就是不太容易一眼就看出来的值,需要简单解释一下的:
staticpage=http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fhtml%2Fjump.html ->
此处,等有了一定的调试经验,和本身具有一定的url的encode,decode基础的话,可以直接看出来,这个值
http%3A%2F%2Fwww.baidu.com%2Fcache%2Fuser%2Fhtml%2Fjump.html
是原先某个url地址,编码之后的值。
而对应的原始的值,可以在代码中去解码而获得;
此处先直接给出原始值:
http://www.baidu.com/cache/user/html/jump.html
关于如何通过此,被编码的url地址中,获得原始的url地址,详细解释在这里:
【整理】关于http(GET或POST)请求中的url地址的编码(encode)和解码(decode)
loginType=1 -> 未知,但是一般不知道的值,都可以先按照原先的值去设置即可;
tpl=mn -> 未知,也还是同样设置即可;
callback=parent.bdPass.api.login._postCallback -> 未知,也同样设置即可;
(3)再剩下的,就是需要去分析调查,才知道为何是这样值的了:
ppui_logintime=6852
此值6852,看起来就像是会变化的。但是到底如何得到的,则需要去分析分析了。
所以就去搜索6852:
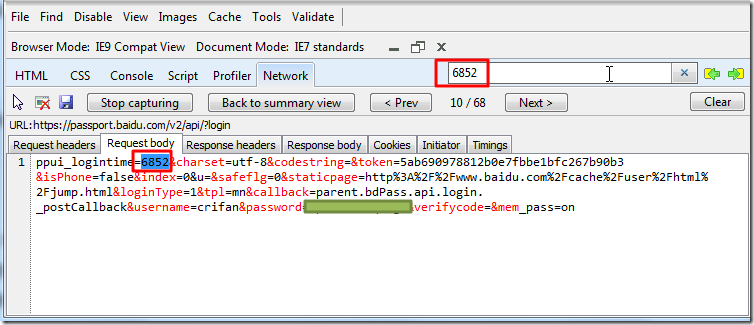
经过搜索,发现结果只能搜到此单独一处的6852,貌似没办法找到此数据如何得到的。
但是,我们可以再去搜其参数ppui_logintime,然后另外在别的文件中也可以找到2处,其中一处是:
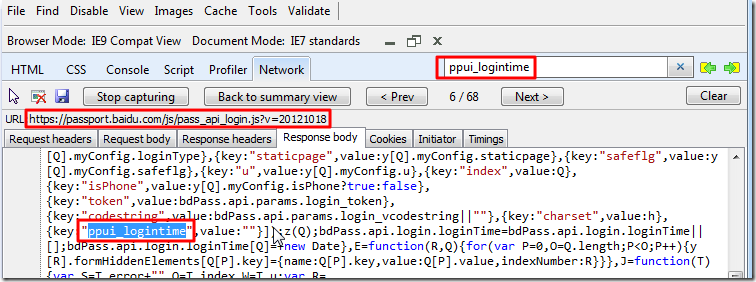
很明显,此处是javascript脚本:
https://passport.baidu.com/js/pass_api_login.js?v=20121018
在其中根据实际情况计算出来的。
【小提示:对于参数的处理策略】
对于涉及的很多参数,总的说,有两种策略:
一是,直接忽略此值,暂时不管。因为很多时候,有些参数,至少是这样看起来,不是那么重要的参数(重要的参数,相信我不说你自己也能看出来,是那些username,password之类的参数)。
然后就去写程序去模拟了。而真的等到程序运行出错,服务器没有返回你所期望的信息的时候,再回来分析此参数,看看是不是这个参数所导致的。
然后再试图去分析其真正的值;
二是,继续分析,甚至调试javascript代码,以便找到此值到底是如何一点点计算出来的。此过程可能会极其繁琐,也可能相对简单。要取决于此值被计算出来所经历的过程的复杂度。
此处,在表面看起来,这个参数ppui_logintime,大概意思是登陆的时间,所以推测是服务器为了记录你本地登陆百度的时间,和能否登陆百度这个过程本身,应该不会产生根本的影响,所以此处就可以采用策略一,暂时忽略不管。
万一真的有影响,再回来继续分析也不迟。
token=5ab690978812b0e7fbbe1bfc267b90b3 ->
此值5ab690978812b0e7fbbe1bfc267b90b3,很明显,是需要从别的地方找到的。所以就去分析此值是如何来的。
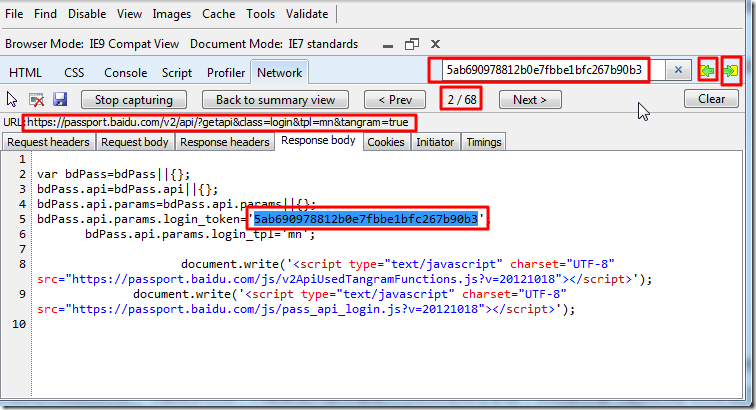
同理,继续去搜5ab690978812b0e7fbbe1bfc267b90b3,然后是可以搜到的,然后通过点击搜索框中的向前和向后的按钮,是可以找到这个
2/68 条记录,对应url是:
https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true
的这处的:
【小提示:在两种视图模式:Detailed View和Summary View之间切换】
对应的,可以通过点击“Back to summary view”,而更加清楚的看到,是哪条记录,以及对应的视图模式中,显示出:
Go to detailed view
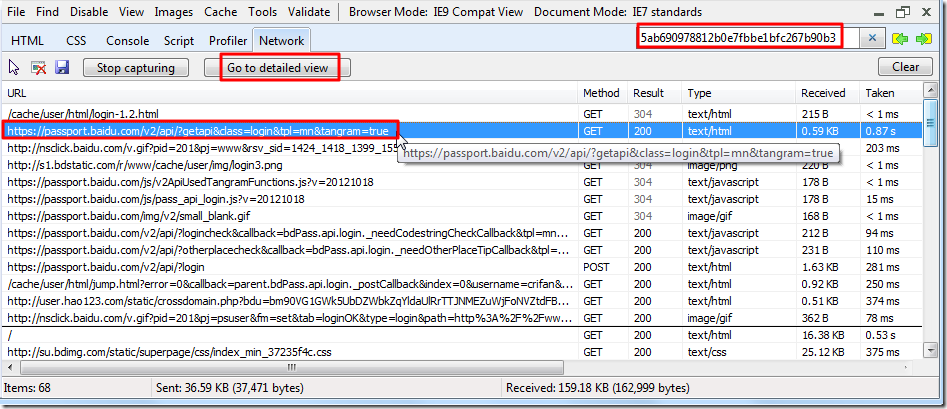
对于上述所搜到的内容,很明显可以看出,就是我们在通过网页登陆百度首页过程中,通过IE9的F12抓取出来的记录知道了,其内部还是会先去访问:
https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true
然后会获得Response Body,即(服务器所返回的)html源码,其中包括了:
|
1
|
bdPass.api.params.login_token='5ab690978812b0e7fbbe1bfc267b90b3'; |
的,此时,你应该就明白了,到时候我们去写代码时,想要获得上述token的值的话,就需要先去
对于
url=https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true
发送GET请求,获得对应的html代码,然后从中分析出token的值5ab690978812b0e7fbbe1bfc267b90b3;
而写到此,基本逻辑过程,也相对清楚了。
但是有人很快会想到,即使上述代码写出来了,又如何能确保的确已经模拟登陆成功了,即如何验证此处模拟登陆百度首页成功了呢?
此处,根据经验,主要通过两方面来验证:
【小提示:如何验证模拟登陆网站已成功】
一是返回的html代码
返回的html代码,即对应着F12中的Response Body,此处为截图如下:
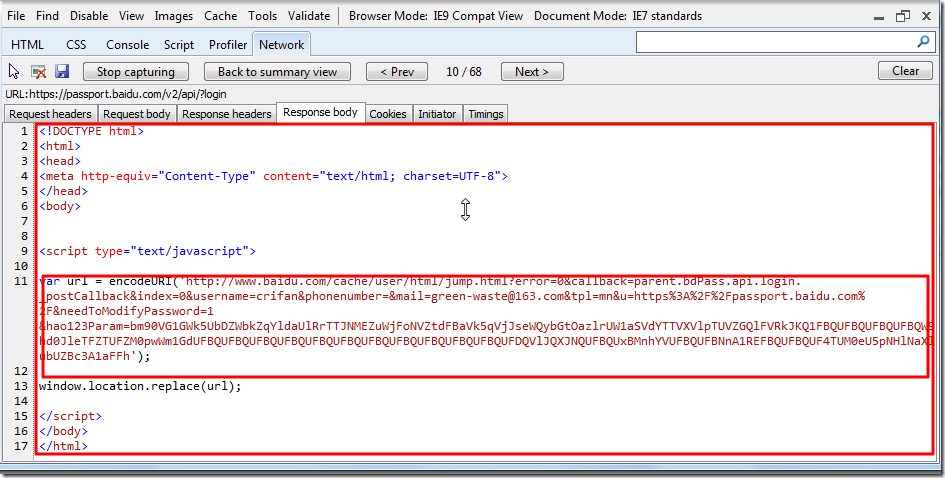
如果你登陆成功了,那么代码中所获得的返回的html中,至少也应该是类似的html了。
二是cookie
如果你成功登陆了服务器,那么其所返回的值中中,对于cookie,一般都是会有对应的,和成功登陆有关的新的cookie返回给你的,以及另外更新一些原先发送的一些cookie的值。
此处F12中的Cookies的截图如下:
![]()
很容易看出,当登陆成功后,会返回那一堆的cookie,拷贝出来如下:
|
1
2
3
4
5
6
|
Direction Key Value Expires Domain Path Secure HTTP onlyReceived BDUSS WpNYWFNSGFub0t6YU9PMW1tVzNIUGRya35TQk5pM0JnflI2fndrT3UtQmdESVpSQVFBQUFBJCQAAAAAAAAAAAoavCuy1YMAY3JpZmFuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAYIArMAAAALDmT5YqAAAA6p5DAAAAAAAxMC4yNi4xOWC-mFBgvphQM Sat, 23-Jan-2021 07:38:08 GMT baidu.com / No NoReceived PTOKEN b42a396ff9c7efb80c08beecd040f032 Sat, 23-Jan-2021 07:38:08 GMT passport.baidu.com / No NoReceived STOKEN f38612b7866cfb0357877b8ca3c4faa6 Sat, 23-Jan-2021 07:38:08 GMT passport.baidu.com / No NoReceived PTOKEN deleted Mon, 07-Nov-2011 07:38:07 GMT baidu.com / No NoReceived SAVEUSERID 345baf769053e0ed4234 Sat, 23-Jan-2021 07:38:08 GMT passport.baidu.com / No No |
而当代码模拟登陆成功后,则也肯定会收到类似的cookie的。
【小提示:关于cookie,需要注意的事情】
此处,需要特别提示一句,如果你在最开始没有去清除cookie,则很可能看到的cookie结果是这样的:

即,登陆前后的cookie,都有BDUSS,PTOKEN,STOKEN,SAVEUSERID。
这是因为,之前通过别的账号,以及同样的账号crifan,登陆过,所以IE9已经在本地记录了相关的cookie。
所以,在访问该url时,能看到Sent中已经存在了类似的cookie。
所以,总的来说,可以通过返回的html和cookie,来验证是否登录成功了。
而一般来说,通过验证cookie,是最有效的。因为很多时候,某些网站登陆成功和登陆失败,所显示的页面可能是同一个;
但是登陆成功的话,基本都会有对应的,新的,和登陆有关的cookie,返回的。
一般来说,实际上,对于很多不是很复杂的网站,到这一步,就完全就够了,就能够成功模拟登陆了。
但是,后来经过代码的证实,如上的流程,实际上是行不通的,因为对于去访问:
https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true
实际上,返回的html是:
|
1
2
3
4
5
6
7
8
|
var bdPass=bdPass||{};bdPass.api=bdPass.api||{};bdPass.api.params=bdPass.api.params||{};bdPass.api.params.login_token='the fisrt two args should be string type:0,1!'; bdPass.api.params.login_tpl='mn'; document.write('<script type="text/javascript" charset="UTF-8" src="https://passport.baidu.com/js/v2ApiUsedTangramFunctions.js?v=20121018"></script>'); document.write('<script type="text/javascript" charset="UTF-8" src="https://passport.baidu.com/js/pass_api_login.js?v=20121018"></script>'); |
其中的:
bdPass.api.params.login_token=’the fisrt two args should be string type:0,1!’;
是无法正确获得我们所需要耳朵token的值的。
所以,接下来,就是继续去想办法,找到此处没有正确获得返回的html的原因。
不过,首先要知道的,无论何时,从抓取出来的数据来看,只要你程序是完整模拟了整个浏览器所发送的所有的数据,此处即IE9所发送的request headers:
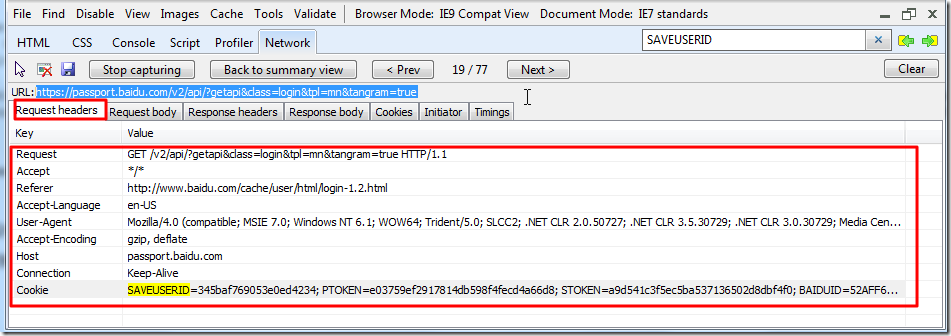
和post data(Request body),此处为空:
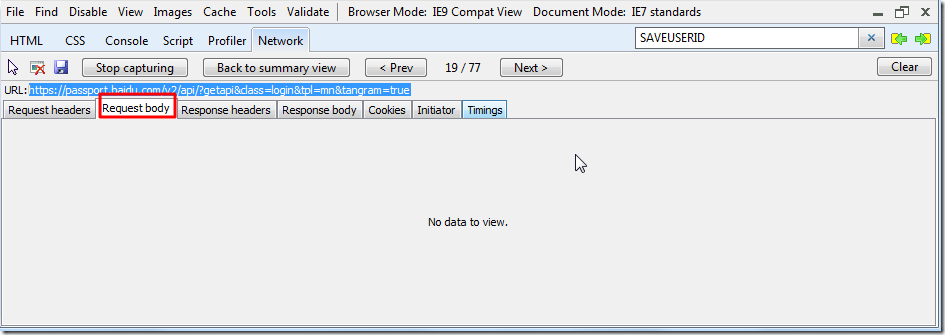
那么,程序所获得的返回值,就应该也和所抓取到的数据一样,即应该就可以从返回的html(response body)中获得所需的token的值了。
而此处之所有没有获得,对照上述所抓取的数据去看,则很可能是,request headers中某些值,比如cookie值,referer等值,没有赋值正确,导致返回的html不对。
所以,接下来,就是想办法,尝试一点点,完全找到上那些cookie的值,referer等的值,都是从哪里来的。
具体寻找的办法,其实还是那些笨办法,就是去搜索,然后一点点找线索,对于某个值,最初是哪里获得的。
好的,现在接着就以其中一个最复杂的cookie:SAVEUSERID,来说明,到底是如何分析出来的,找到最开始的SAVEUSERID是从哪里来的:
不过,此部分内容,相对比较复杂,所以单独写到这里了:
【教程】如何利用IE9的F12去分析网站登陆过程中的复杂的(参数,cookie等)值(的来源)
最终,才分析出来,SAVEUSERID是通过访问:
https://passport.baidu.com/v2/api/?login
而获得的。
而相应的,访问https://passport.baidu.com/v2/api/?login之前,需要用到BAIDUID。
所以又用同样的分析方法,去找到BAIDUID这个cookie的最开始的来源(又重新打开浏览器,重新分析了一次):
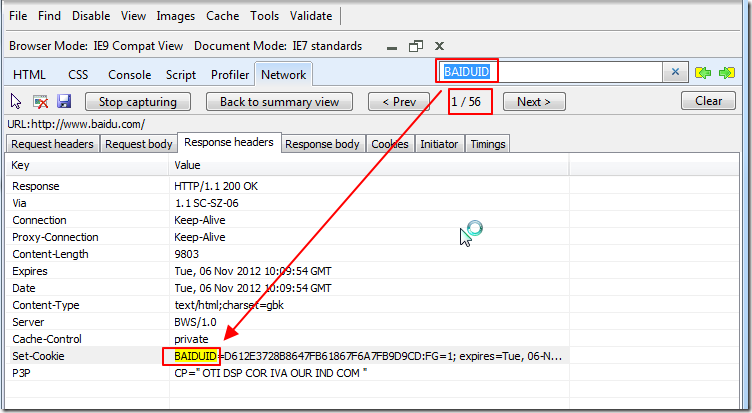
因此,即为:
先访问:
去获得对应的BAIDUID,接着去访问:
https://passport.baidu.com/v2/api/?login
其中发送的数据中,包括BAIDUID,返回数据中,得到SAVEUSERID。
而此时,其实访问
https://passport.baidu.com/v2/api/?login
本身就是我们所追求的目标,模拟登陆百度。
所以后续的SAVEUSERID,其实此处是可以不用,只是去通过校验cookie,而验证登陆是否成功时,会涉及到而已。
然后再去回头看之前所说的:
https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true
再次重现抓取所看到的结果为:
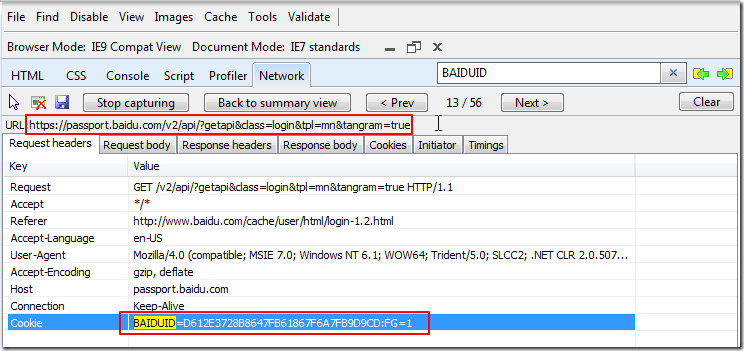
就容易看懂了,即需要在访问:
https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true
时,提供BAIDUID这个cookie。
另外,再确认一下,访问:
https://passport.baidu.com/v2/api/?login
正确登陆时,所返回的cookie:
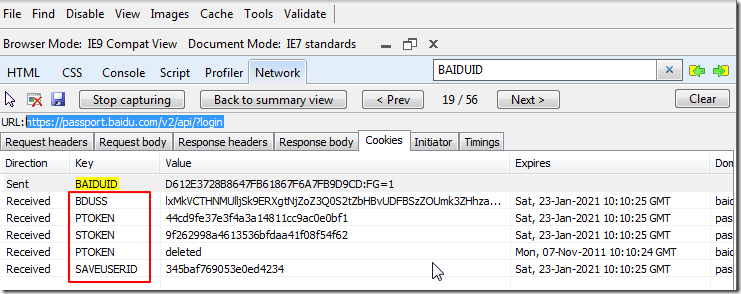
其中的cookie的详细的值为:
|
1
2
3
4
5
6
7
|
Direction Key Value Expires Domain Path Secure HTTP onlySent BAIDUID D612E3728B8647FB61867F6A7FB9D9CD:FG=1 Received BDUSS lxMkVCTHNMUlljSk9ERXgtNjZoZ3Q0S2tZbHBvUDFBSzZOUmk3ZHhza1JNSVpSQVFBQUFBJCQAAAAAAAAAAApRIA6y1YMAY3JpZmFuAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAYIArMAAAALA2xXUAAAAA6p5DAAAAAAAxMC4yNi4xORHimFAR4phQbW Sat, 23-Jan-2021 10:10:25 GMT baidu.com / No NoReceived PTOKEN 44cd9fe37e3f4a3a14811cc9ac0e0bf1 Sat, 23-Jan-2021 10:10:25 GMT passport.baidu.com / No NoReceived STOKEN 9f262998a4613536bfdaa41f08f54f62 Sat, 23-Jan-2021 10:10:25 GMT passport.baidu.com / No NoReceived PTOKEN deleted Mon, 07-Nov-2011 10:10:24 GMT baidu.com / No NoReceived SAVEUSERID 345baf769053e0ed4234 Sat, 23-Jan-2021 10:10:25 GMT passport.baidu.com / No No |
可见,其中至少包括:
BDUSS,PTOKEN,STOKEN,SAVEUSERID
(其中,对于原先域名为baidu.com的PTOKEN,是被删除掉的,此处暂可忽略)
3.3 总结出模拟登陆网站的基本流程
至此,对于想要模拟登陆百度首页:
的内部逻辑过程,基本上就很清楚了:
| 顺序 | 访问地址 | 访问类型 | 发送的数据 | 需要获得/提取的返回的值 |
| 1 | http://www.baidu.com/ | GET | 无 | 返回的cookie中的BAIDUID |
| 2 | https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true | GET | 包含BAIDUID这个cookie | 从返回的html中提取出token的值 |
| 3 | https://passport.baidu.com/v2/api/?login | POST | 一堆的post data,其中token的值是之前提取出来的 | 需要验证返回的cookie中,是否包含BDUSS,PTOKEN,STOKEN,SAVEUSERID |
【小提示:分析模拟登陆时,未必非得要完全搞懂和在代码中用到所有的参数】
对于上述流程,按理来说,去使用代码,Python或C#等,去实现出来,即可。
不过,关于模拟登陆时所需要的数据,多解释一下。
按理来说,完整的模拟网站登陆的话,其实应该是从头到尾的,分析出浏览器(IE9)本身是如何访问网站的,然后把所有的逻辑搞懂,数据的来源都分析清楚,即如上述过程,对于访问
https://passport.baidu.com/v2/api/?login
所需要的那么一堆参数,都去搞懂具体的含义,以及参数的值,是怎么获得的。
而实际上,很多时候,模拟网站登陆,或者是抓取网页信息的时候,只需要最关心的那些核心参数即可。
因为,服务器,很可能,只是去判断那些核心参数,比如上述的username,password,及其他几个参数,
然后就可以正确返回你所需要的信息,即html,cookie等,就可以成功实现模拟登陆的目的了。
但是,话说回来,具体需要哪些,最基本的参数,还是需要通过写程序,去一点点测试出来的。
而之所以给大家介绍上述的概念,目的是为了,在你觉得自己能看懂参数的大概含义的时候,很多时候,能看出该参数不要也无所谓的时候,那就可以先去测试基本的参数,而暂时忽略其他相对次要的参数。
由此,在一定程度上,提高做事情的效率而已。
当然,在忽略参数的时候,也要注意,不要轻易忽略很多参数,否则也是很可能影响到程序模拟登陆的正确性的。
具体的尺度的把握,就一点:根据情况而定,自己看着办。
【总结】
至此,关于模拟登陆网站,如何一步步的分析出内部逻辑过程,就完成了。
总结下来就是,先去用工具“录制”你所有的操作,然后再去利用工具去分析和登陆有关那些url的相关的信息,主要是post data有哪些参数,以及其值是如何获得的。
【教程】手把手教你如何利用工具(IE9的F12)去分析模拟登陆网站(百度首页)的内部逻辑过程的更多相关文章
- 【教程】模拟登陆百度之Java代码版
[背景] 之前已经写了教程,分析模拟登陆百度的逻辑: [教程]手把手教你如何利用工具(IE9的F12)去分析模拟登陆网站(百度首页)的内部逻辑过程 然后又去用不同的语言: Python的: [教程]模 ...
- 手把手教你如何利用 HeroKu 免费获取一个 Scrapyd 集群
手把手教你如何利用 HeroKu 免费获取一个 Scrapyd 集群 本文原始地址:https://sitoi.cn/posts/48724.html 准备环境 一个 GitHub 的账号 一个 He ...
- 手把手教你掌握——性能工具Jmeter之参数化(含安装教程 )
本节大纲 Jmeter 发送get/post请求 Jmeter 之文件参数化-TXT/Csv Jmeter之文件参数化-断言 JMeter简介 Apache JMeter是一款基于JAVA的压力测试T ...
- 手把手教你如何利用Meterpreter渗透Windows系统
在这篇文章中,我们将跟大家介绍如何使用Meterpreter来收集目标Windows系统中的信息,获取用户凭证,创建我们自己的账号,启用远程桌面,进行屏幕截图,以及获取用户键盘记录等等. 相关Payl ...
- [ionic开源项目教程] - 手把手教你使用移动跨平台开发框架Ionic开发一个新闻阅读APP
前言 这是一个系列文章,从环境搭建开始讲解,包括网络数据请求,将持续更新到项目完结.实战开发中遇到的各种问题的解决方案,也都将毫无保留的分享给大家. 关注订阅号:TongeBlog ,查看移动端跨平台 ...
- 学以致用:手把手教你撸一个工具库并打包发布,顺便解决JS浮点数计算精度问题
本文讲解的是怎么实现一个工具库并打包发布到npm给大家使用.本文实现的工具是一个分数计算器,大家考虑如下情况: \[ \sqrt{(((\frac{1}{3}+3.5)*\frac{2}{9}-\fr ...
- 人人都能看懂的卡西欧fx991cnx玩机指南,手把手教你如何利用计算器的漏洞爆机
专业术语说明 你是VerB还是VerC 别人问你这个问题的时候不要慌,帮你看你的计算器是Ver几: 同时按住shift.7.开机键 9 5次shift 第一行后半句即是 紧接着可以顺便看看计算器的序列 ...
- 手把手教你用C++ 写ACM自动刷题神器(冲入HDU首页)
转载注明原地址:http://blog.csdn.net/nk_test/article/details/49497017 少年,作为苦练ACM,通宵刷题的你 是不是想着有一天能够荣登各大OJ榜首,俯 ...
- 利用selenium库自动执行滑动验证码模拟登陆
破解流程 #1.输入账号.密码,然后点击登陆 #2.点击按钮,弹出没有缺口的图 #3.针对没有缺口的图片进行截图 #4.点击滑动按钮,弹出有缺口的图 #5.针对有缺口的图片进行截图 #6.对比两张图片 ...
随机推荐
- 微分方程——包络和奇解
对某些微分方程,存在一条(也可能多条)特殊的积分曲线,它并不属于方程的积分曲线族.但是,在这条特殊的积分曲线上的每一点处,都有积分曲线族中的一条曲线和它在此点相切.在几何学上,这条特殊的积分曲线称为上 ...
- php include require
includ和require都是把其他页面加载当前页面,不过不同的是,require如果没有找到,或者所包含的页面里面有错误就不会往下执行了 <?php include 'form.php'; ...
- 每天一个 Linux 命令(4):mkdir
linux mkdir 命令用来创建指定的名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前目录中已有的目录. 1.命令格式: mkdir [选项] 目录- 2.命令功能 ...
- Karma:1. 集成 Karma 和 Jasmine 进行单元测试
关于 Karma 会是一个系列,讨论在各种环境下,使用 Karma 进行单元测试. 本文讨论 karma 集成 Jasmine 进行单元测试. 初始化 NPM 实现初始化 NPM 包管理,创建 pac ...
- JS生成雪花
<script type="text/javascript"> (function(){ function snow(left,height,src){ var div ...
- Linux网络状态工具ss命令使用详解
ss命令用于显示socket状态. 他可以显示PACKET sockets, TCP sockets, UDP sockets, DCCP sockets, RAW sockets, Unix dom ...
- 优雅的设计单线程范围内的数据共享(ThreadLocal)
单线程范围内数据共享使用ThreadLocal /** * @Description TODO * @author zhanghw@chinatelecom.cn * @since 2015年12月1 ...
- cursor
BeginWaitCursor(); // display the hourglass cursor // do some lengthy processing Sleep(3000); EndWai ...
- CSS-页面布局
介绍 几个实现多栏布局的方法.主要介绍使用内部div来创建浮动的栏. 多栏布局有三种基本的实现方案:固定宽度.流动.弹性. 固定宽度布局的大小是随用户调整浏览器窗口大小而变化,一般是900至1100像 ...
- noip2006 2^k进制数
设r是个2k进制数,并满足以下条件: (1)r至少是个2位的2k进制数. (2)作为2k进制数,除最后一位外,r的每一位严格小于它右边相邻的那一位. (3)将r转换为2进制数q后,则q的总位数不超过w ...