基于kafka_2.11-2.1.0实现的生产者和消费者代码样例
1、搭建部署好zookeeper集群和kafka集群,这里省略。
启动zk:
bin/zkServer.sh start conf/zoo.cfg。
验证zk是否启动成功:
bin/zkServer.sh status conf/zoo.cfg。
启动kafka:
bin/kafka-server-start.sh -daemon config/server.properties。
2、生产者和消费者代码如下所示:
package com.bie.kafka.producer; import java.util.Properties; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
//import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord; /**
*
* @Description TODO
* @author biehl
* @Date 2019年4月6日 上午11:27:34
*
*/
public class ProducerTest { public static void main(String[] args) {
// 构造一个java.util.Properties对象
Properties props = new Properties();
// 指定bootstrap.servers属性。必填,无默认值。用于创建向kafka broker服务器的连接。
props.put("bootstrap.servers", "192.168.110.130:9092,192.168.110.131:9092,192.168.110.132:9092");
// 指定key.serializer属性。必填,无默认值。被发送到broker端的任何消息的格式都必须是字节数组。
// 因此消息的各个组件都必须首先做序列化,然后才能发送到broker。该参数就是为消息的key做序列化只用的。
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 指定value.serializer属性。必填,无默认值。和key.serializer类似。此被用来对消息体即消息value部分做序列化。
// 将消息value部分转换成字节数组。
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//acks参数用于控制producer生产消息的持久性(durability)。参数可选值,0、1、-1(all)。
props.put("acks", "-1");
//props.put(ProducerConfig.ACKS_CONFIG, "1");
//在producer内部自动实现了消息重新发送。默认值0代表不进行重试。
props.put("retries", );
//props.put(ProducerConfig.RETRIES_CONFIG, 3);
//调优producer吞吐量和延时性能指标都有非常重要作用。默认值16384即16KB。
props.put("batch.size", );
//props.put(ProducerConfig.BATCH_SIZE_CONFIG, 323840);
//控制消息发送延时行为的,该参数默认值是0。表示消息需要被立即发送,无须关系batch是否被填满。
props.put("linger.ms", );
//props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
//指定了producer端用于缓存消息的缓冲区的大小,单位是字节,默认值是33554432即32M。
props.put("buffer.memory", );
//props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
props.put("max.block.ms", );
//props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 3000);
//设置producer段是否压缩消息,默认值是none。即不压缩消息。GZIP、Snappy、LZ4
//props.put("compression.type", "none");
//props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "none");
//该参数用于控制producer发送请求的大小。producer端能够发送的最大消息大小。
//props.put("max.request.size", 10485760);
//props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);
//producer发送请求给broker后,broker需要在规定时间范围内将处理结果返还给producer。默认30s
//props.put("request.timeout.ms", 60000);
//props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000); // 使用上面创建的Properties对象构造KafkaProducer对象
//如果采用这种方式创建producer,那么就不需要显示的在Properties中指定key和value序列化类了呢。
// Serializer<String> keySerializer = new StringSerializer();
// Serializer<String> valueSerializer = new StringSerializer();
// Producer<String, String> producer = new KafkaProducer<String, String>(props,
// keySerializer, valueSerializer);
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = ; i < ; i++) {
//构造好kafkaProducer实例以后,下一步就是构造消息实例。
producer.send(new ProducerRecord<>("topic1", Integer.toString(i), Integer.toString(i)));
// 构造待发送的消息对象ProduceRecord的对象,指定消息要发送到的topic主题,分区以及对应的key和value键值对。
// 注意,分区和key信息可以不用指定,由kafka自行确定目标分区。
//ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("my-topic",
// Integer.toString(i), Integer.toString(i));
// 调用kafkaProduce的send方法发送消息
//producer.send(producerRecord);
}
System.out.println("消息生产结束......");
// 关闭kafkaProduce对象
producer.close();
System.out.println("关闭生产者......");
} }
消费者代码如下所示:
package com.bie.kafka.consumer; import java.util.Arrays;
import java.util.Properties; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer; /**
*
* @Description TODO
* @author biehl
* @Date 2019年4月6日 下午8:12:28
*
*/
public class ConsumerTest { public static void main(String[] args) {
String topicName = "topic1";
String groupId = "group1";
//构造java.util.Properties对象
Properties props = new Properties();
// 必须指定属性。
props.put("bootstrap.servers", "192.168.110.130:9092,192.168.110.131:9092,192.168.110.132:9092");
// 必须指定属性。
props.put("group.id", groupId);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "");
// 从最早的消息开始读取
props.put("auto.offset.reset", "earliest");
// 必须指定
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 必须指定
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 使用创建的Properties实例构造consumer实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
// 订阅topic。调用kafkaConsumer.subscribe方法订阅consumer group所需的topic列表
consumer.subscribe(Arrays.asList(topicName));
try {
while (true) {
//循环调用kafkaConsumer.poll方法获取封装在ConsumerRecord的topic消息。
ConsumerRecords<String, String> records = consumer.poll();
//获取到封装在ConsumerRecords消息以后,处理获取到ConsumerRecord对象。
for (ConsumerRecord<String, String> record : records) {
//简单的打印输出
System.out.println(
"offset = " + record.offset()
+ ",key = " + record.key()
+ ",value =" + record.value());
}
}
} catch (Exception e) {
//关闭kafkaConsumer
System.out.println("消息消费结束......");
consumer.close();
}
System.out.println("关闭消费者......");
}
}
遇到的坑,一开始报的错误莫名其妙,一开始以为使用的jar包版本问题,又是报slf4j的错误,又是报log4j的错误,又是报空指针的异常。最后百度意外遇到了可能是本地没有将ip地址放到hosts文件里面,果然是这个问题。
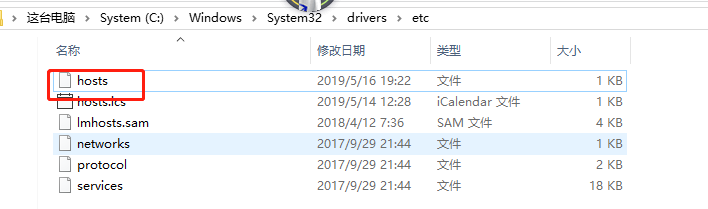
添加如下所示即可:
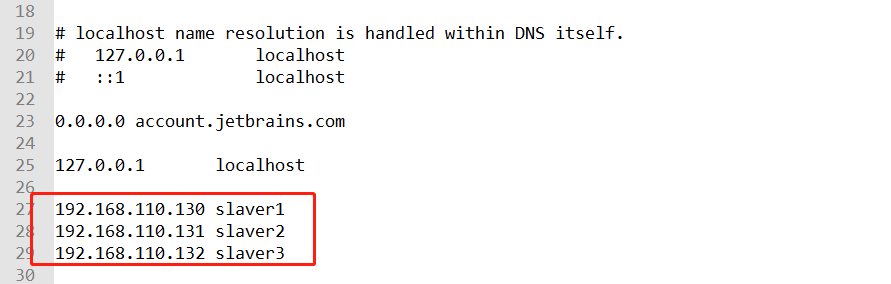
然后就可以开心的生产消息和消费消息了啊。开心。
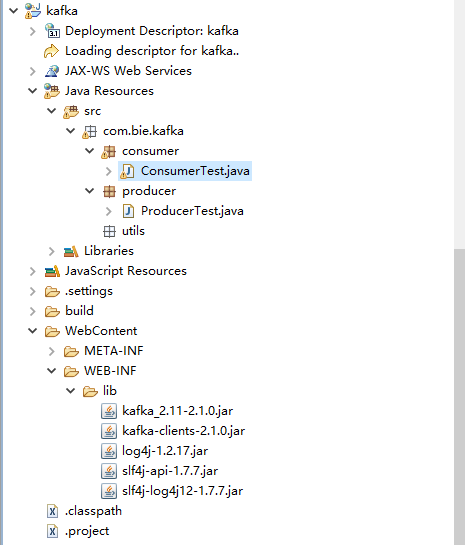
项目结构如下所示:
3、生产者生产消息异步或者同步发送消息的案例使用:
Synchronization 同步
package com.bie.kafka.producer; import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future; import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
//import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata; /**
*
* @Description TODO
* @author biehl
* @Date 2019年4月6日 上午11:27:34
* 同步发送
* Synchronization 同步
*/
public class ProducerSynchronization { public static void main(String[] args) {
// 构造一个java.util.Properties对象
Properties props = new Properties();
// 指定bootstrap.servers属性。必填,无默认值。用于创建向kafka broker服务器的连接。
props.put("bootstrap.servers", "192.168.110.130:9092,192.168.110.131:9092,192.168.110.132:9092");
// 指定key.serializer属性。必填,无默认值。被发送到broker端的任何消息的格式都必须是字节数组。
// 因此消息的各个组件都必须首先做序列化,然后才能发送到broker。该参数就是为消息的key做序列化只用的。
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 指定value.serializer属性。必填,无默认值。和key.serializer类似。此被用来对消息体即消息value部分做序列化。
// 将消息value部分转换成字节数组。
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//acks参数用于控制producer生产消息的持久性(durability)。参数可选值,0、1、-1(all)。
props.put("acks", "-1");
//props.put(ProducerConfig.ACKS_CONFIG, "1");
//在producer内部自动实现了消息重新发送。默认值0代表不进行重试。
props.put("retries", );
//props.put(ProducerConfig.RETRIES_CONFIG, 3);
//调优producer吞吐量和延时性能指标都有非常重要作用。默认值16384即16KB。
props.put("batch.size", );
//props.put(ProducerConfig.BATCH_SIZE_CONFIG, 323840);
//控制消息发送延时行为的,该参数默认值是0。表示消息需要被立即发送,无须关系batch是否被填满。
props.put("linger.ms", );
//props.put(ProducerConfig.LINGER_MS_CONFIG, 10);
//指定了producer端用于缓存消息的缓冲区的大小,单位是字节,默认值是33554432即32M。
props.put("buffer.memory", );
//props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
props.put("max.block.ms", );
//props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 3000);
//设置producer段是否压缩消息,默认值是none。即不压缩消息。GZIP、Snappy、LZ4
//props.put("compression.type", "none");
//props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "none");
//该参数用于控制producer发送请求的大小。producer端能够发送的最大消息大小。
//props.put("max.request.size", 10485760);
//props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);
//producer发送请求给broker后,broker需要在规定时间范围内将处理结果返还给producer。默认30s
//props.put("request.timeout.ms", 60000);
//props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000); // 使用上面创建的Properties对象构造KafkaProducer对象
//如果采用这种方式创建producer,那么就不需要显示的在Properties中指定key和value序列化类了呢。
// Serializer<String> keySerializer = new StringSerializer();
// Serializer<String> valueSerializer = new StringSerializer();
// Producer<String, String> producer = new KafkaProducer<String, String>(props,
// keySerializer, valueSerializer);
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = ; i < ; i++) {
//构造好kafkaProducer实例以后,下一步就是构造消息实例。
// producer.send(new ProducerRecord<>("topic1", Integer.toString(i), Integer.toString(i))); try {
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("topic1",Integer.toString(i),"biehl基于kafka_2.11-2.1.0实现的生产者和消费者代码样例的更多相关文章
- kafka_2.9.2-0.8.1.1分布式集群搭建代码开发实例
准备3台虚拟机, 系统是RHEL64服务版. 1) 每台机器配置如下:$ cat /etc/hosts # zookeeper hostnames: 192.168.8.182 ...
- 对Linux0.11 中 进程0 和 进程1分析
1. 背景 进程的创建过程无疑是最重要的操作系统处理过程之一,很多书和教材上说的最多的还是一些原理的部分,忽略了很多细节.比如,子进程复制父进程所拥有的资源,或者子进程和父进程共享相同的物理页面,拥有 ...
- 基于C++11实现线程池的工作原理
目录 基于C++11实现线程池的工作原理. 简介 线程池的组成 1.线程池管理器 2.工作线程 3.任务接口, 4.任务队列 线程池工作的四种情况. 1.主程序当前没有任务要执行,线程池中的任务队列为 ...
- 基于C++11的100行实现简单线程池
基于C++11的100行实现简单线程池 1 线程池原理 线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务.线程池线程都是后台线程.每个线程都使用默认的堆栈大小, ...
- 【C++11应用】基于C++11及std::thread实现的线程池
目录 基于C++11及std::thread实现的线程池 基于C++11及std::thread实现的线程池 线程池源码: #pragma once #include <functional&g ...
- SpringMVC快速使用——基于XML配置和Servlet3.0
SpringMVC快速使用--基于XML配置和Servlet3.0 1.官方文档 https://docs.spring.io/spring-framework/docs/5.2.8.RELEASE/ ...
- 基于C++11的线程池实现
1.线程池 1.1 线程池是什么? 一种线程管理方式. 1.2 为什么用线程池? 线程的创建和销毁都需要消耗系统开销,当线程数量过多,系统开销过大,就会影响缓存局部性和整体性能.而线程池能够在充分利用 ...
- 基于C++11的数据库连接池实现
0.注意 该篇文章为了让大家尽快看到效果,代码放置比较靠前,看代码前务必看下第4部分的基础知识. 1.数据库连接池 1.1 是什么? 数据库连接池负责分配.管理和释放数据库连接,属于池化机制的一种,类 ...
- Oracle 11.2.4.0 ACTIVE DATAGUARD 单实例安装(COPY创建备库)
Oracle 11.2.4.0 ADG 单实例安装(COPY创建备库) 规划: 主: OS: Linux Centos 6.5 X64 hostname:ORA11G-DG1 ipaddress:19 ...
随机推荐
- WDA入门教程Ⅰ:Web Dynpro for ABAP 入门(转)
转自:https://www.jianshu.com/p/68c1592f1a87 WDA全称Web Dynpro for ABAP,也写作WD4A或WDA,是用于在ABAP环境中开发Web应用程序的 ...
- XAML属性和事件
1.元素属性 XAML是一种声明性语言,XAML编译器会为每一个标签创建一个与之对应的对象.对象创建出来之后要对它的属性进行必要的初始化之后才有使用意义.因为XAML语言不能写程序运行逻辑,所以一份X ...
- go-面向对象编程(下)
面向对象编程思想-抽象 抽象的介绍 我们在前面去定义一个结构体时候,实际上就是把一类事物的共有的 属性( 字段)和 行为( 方法)提取 出来,形成一个 物理模型(结构体).这种研究问题的方法称为抽象 ...
- jsp表单更新数据库
和插入语句相似,表单传值,在另一个页面接收数据并连接数据库进行更新: 语句如下: <% request.setCharacterEncoding("UTF-8"); Stri ...
- Junit4模板
模板 MallApplicationTests import org.junit.runner.RunWith; import org.springframework.boot.test.contex ...
- Chrome保存的HAR文件怎么打开?
- Chrome保存HAR 在Chrome中,在需要抓包的任意一个浏览器窗口,按F12,点Network页面,即可进入抓包界面,之后的所有网页交互操作产生的报文,都会在此列出. 在抓包的报文界面上右键 ...
- 第三方库Mantle的简单实用
1. 测试时, 可以使用下面这个网址及代码来测试, 里面有模型,数组,以及字典, 还可以有long long 转NSDate, string 转 int等. NSURL *url = [NSURLU ...
- Material 风格的搜索框MaterialSearchView的使用
大多数App中都有搜索的功能,虽然国内实实在在的遵循Google material design设计语言来设计的App实在不多,但个人感觉MD真的是非常值得研究,这次给大家介绍的是 Material ...
- tomcat配置通过域名访问项目
tomcat配置通过域名访问项目,是修改conf/server.xml里面的配置信息实现.具体如下: (1)修改Connector节点的port属性值 <Connector port=" ...
- vue操作select获取option值
如何实时的获取你选中的值 只用@change件事 @change="changeProduct($event)" 动态传递参数 vue操作select获取option的ID值 如果 ...