百万年薪python之路 -- MySQL数据库之 常用数据类型
MySQL常用数据类型
一. 常用数据类型概览
# 1. 数字:
整型: tinyint int bigint
小数: float: 在位数比较短的情况下不精确
double: 在位数比较长的情况下不精确
0.000001230123123123
存成: 0.000001230000
decimal: (如果用小数,则推荐使用decimal)
精准
内部原理是以字符串形式去存
# 2. 字符串:
char(10): 简单粗暴,浪费空间,存取速度快.
root存成root000000
varchar: 精准,节省空间,存取速度慢
sql优化: 创建表时,定长的类型往前放,变长的往后放
比如性别 比如地址或描述信息
>255个字符,超过了就把文件路径存放到数据库中.
比如图片,视频等找一个文件服务器,数据库中只存放路径或url.
# 3. 时间类型
常用的: datatime data time
# 4. 枚举类型与集合类型二. 数值类型
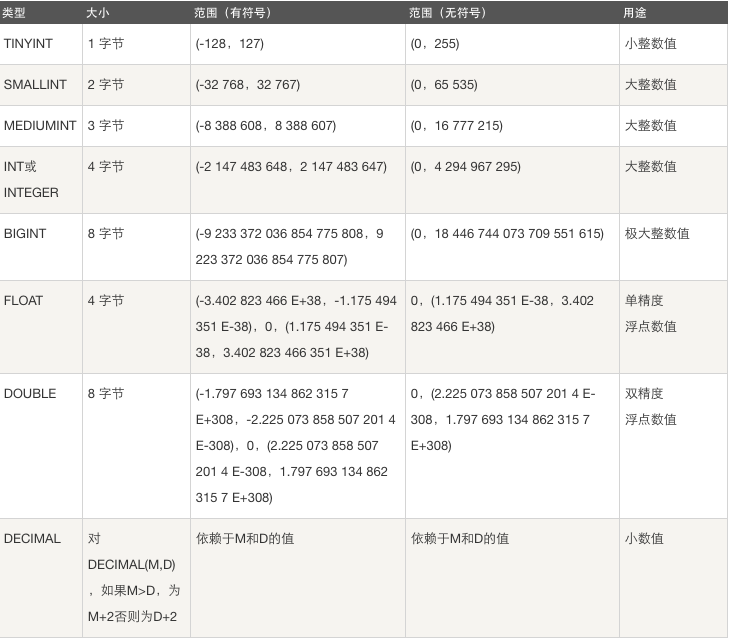
1. 整数类型
整数类型: tinyint, smallint, mediumint, int, bigint
作用: 存储年龄, 等级, id , 各种号码等.
整数类型分类
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-128 ~ 127
无符号:
0 ~ 255
PS: MySQL中无布尔值,使用tinyint(1)构造。
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-2147483648 ~ 2147483647
无符号:
0 ~ 4294967295
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
0 ~ 18446744073709551615
整数类型范围验证
有符号和无符号tinyint
1.tinyint默认为有符号
mysql> create table t1(x tinyint); #默认为有符号,即数字前有正负号
mysql> desc t1;
mysql> insert into t1 values
-> (-129),
-> (-128),
-> (127),
-> (128);
mysql> select * from t1;
+------+
| x |
+------+
| -128 | #-129存成了-128
| -128 | #有符号,最小值为-128
| 127 | #有符号,最大值127
| 127 | #128存成了127
+------+
2.设置无符号tinyint
mysql> create table t2(x tinyint unsigned);
mysql> insert into t2 values
-> (-1),
-> (0),
-> (255),
-> (256);
mysql> select * from t2;
+------+
| x |
+------+
| 0 | -1存成了0
| 0 | #无符号,最小值为0
| 255 | #无符号,最大值为255
| 255 | #256存成了255
+------+
有符号和无符号int
1.int默认为有符号
mysql> create table t3(x int); #默认为有符号整数
mysql> insert into t3 values
-> (-2147483649),
-> (-2147483648),
-> (2147483647),
-> (2147483648);
mysql> select * from t3;
+-------------+
| x |
+-------------+
| -2147483648 | #-2147483649存成了-2147483648
| -2147483648 | #有符号,最小值为-2147483648
| 2147483647 | #有符号,最大值为2147483647
| 2147483647 | #2147483648存成了2147483647
+-------------+
2.设置无符号int
mysql> create table t4(x int unsigned);
mysql> insert into t4 values
-> (-1),
-> (0),
-> (4294967295),
-> (4294967296);
mysql> select * from t4;
+------------+
| x |
+------------+
| 0 | #-1存成了0
| 0 | #无符号,最小值为0
| 4294967295 | #无符号,最大值为4294967295
| 4294967295 | #4294967296存成了4294967295
+------------+
有符号和无符号bigint
1.有符号bigint
mysql> create table t6(x bigint);
mysql> insert into t5 values
-> (-9223372036854775809),
-> (-9223372036854775808),
-> (9223372036854775807),
-> (9223372036854775808);
mysql> select * from t5;
+----------------------+
| x |
+----------------------+
| -9223372036854775808 |
| -9223372036854775808 |
| 9223372036854775807 |
| 9223372036854775807 |
+----------------------+
2.无符号bigint
mysql> create table t6(x bigint unsigned);
mysql> insert into t6 values
-> (-1),
-> (0),
-> (18446744073709551615),
-> (18446744073709551616);
mysql> select * from t6;
+----------------------+
| x |
+----------------------+
| 0 |
| 0 |
| 18446744073709551615 |
| 18446744073709551615 |
+----------------------+
用zerofill测试整数类型的显示宽度
mysql> create table t7(x int(3) zerofill);
mysql> insert into t7 values
-> (1),
-> (11),
-> (111),
-> (1111);
mysql> select * from t7;
+------+
| x |
+------+
| 001 |
| 011 |
| 111 |
| 1111 | #超过宽度限制仍然可以存
+------+
整数类型范围验证 注意:对于整型来说,数据类型后面的宽度并不是存储长度限制,而是显示限制,假如:int(8),那么显示时不够8位则用0来填充,够8位则正常显示,通过zerofill来测试,存储长度还是int的4个字节长度。默认的显示宽度就是能够存储的最大的数据的长度,比如:int无符号类型,那么默认的显示宽度就是int(10),有符号的就是int(11),因为多了一个符号,所以我们没有必要指定整数类型的数据,没必要指定宽度,因为默认的就能够将你存的原始数据完全显示
int的存储宽度是4个Bytes,即32个bit,即2**32
无符号最大值为:4294967296-1
有符号最大值:2147483648-1
有符号和无符号的最大数字需要的显示宽度均为10,而针对有符号的最小值则需要11位才能显示完全,所以int类型默认的显示宽度为11是非常合理的
最后:整形类型,其实没有必要指定显示宽度,使用默认的就ok
说到这里我想提一下MySQL的mode设置,看这篇博客:https://www.cnblogs.com/clschao/articles/9962347.html,看完博客应该就能理解MySQL的mode了。
2. 浮点型
定点数类型: dec, 等同于decimal
浮点数类型: float, double
作用: 存储薪资,身高,温度,体重,体质参数等
1.FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
单精度浮点数(非准确小数值),m是整数部分+小数部分的总个数,d是小数点后个数。m最大值为255,d最大值为30,例如:float(255,30)
有符号:
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
无符号:
1.175494351E-38 to 3.402823466E+38
精确度:
**** 随着小数的增多,精度变得不准确 ****
2.DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]
定义:
双精度浮点数(非准确小数值),m是整数部分+小数部分的总个数,d是小数点后个数。m最大值也为255,d最大值也为30
有符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308
无符号:
2.2250738585072014E-308 to 1.7976931348623157E+308
精确度:
****随着小数的增多,精度比float要高,但也会变得不准确 ****
3.decimal[(m[,d])] [unsigned] [zerofill]
定义:
准确的小数值,m是整数部分+小数部分的总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。比float和double的整数个数少,但是小数位数都是30位
精确度:
**** 随着小数的增多,精度始终准确 ****
对于精确数值计算时需要用此类型
decimal能够存储精确值的原因在于其内部按照字符串存储。
精度从高到低:decimal、double、float
decimal精度高,但是整数位数少
float和double精度低,但是整数位数多
float已经满足绝大多数的场景了,但是什么导弹、航线等要求精度非常高,所以还是需要按照业务场景自行选择,如果又要精度高又要整数位数多,那么你可以直接用字符串来存。浮点型测试
mysql> create table t1(x float(256,31));
ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30.
mysql> create table t1(x float(256,30));
ERROR 1439 (42000): Display width out of range for column 'x' (max = 255)
mysql> create table t1(x float(255,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> create table t2(x double(255,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> create table t3(x decimal(66,31));
ERROR 1425 (42000): Too big scale 31 specified for column 'x'. Maximum is 30.
mysql> create table t3(x decimal(66,30));
ERROR 1426 (42000): Too-big precision 66 specified for 'x'. Maximum is 65.
mysql> create table t3(x decimal(65,30)); #建表成功
Query OK, 0 rows affected (0.02 sec)
mysql> show tables;
+---------------+
| Tables_in_db1 |
+---------------+
| t1 |
| t2 |
| t3 |
+---------------+
3 rows in set (0.00 sec)
mysql> insert into t1 values(1.1111111111111111111111111111111); #小数点后31个1
Query OK, 1 row affected (0.01 sec)
mysql> insert into t2 values(1.1111111111111111111111111111111);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t3 values(1.1111111111111111111111111111111);
Query OK, 1 row affected, 1 warning (0.01 sec)
mysql> select * from t1; #随着小数的增多,精度开始不准确
+----------------------------------+
| x |
+----------------------------------+
| 1.111111164093017600000000000000 |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select * from t2; #精度比float要准确点,但随着小数的增多,同样变得不准确
+----------------------------------+
| x |
+----------------------------------+
| 1.111111111111111200000000000000 |
+----------------------------------+
1 row in set (0.00 sec)
mysql> select * from t3; #精度始终准确,d为30,于是只留了30位小数
+----------------------------------+
| x |
+----------------------------------+
| 1.111111111111111111111111111111 |
+----------------------------------+
1 row in set (0.00 sec)3. 位类型(了解,基本用不到)
bit(M)可以用来存放多位二进制数,M范围从1~64,如果不写默认为1位。
注意:对于位字段需要使用函数读取
bin()显示为二进制
hex()显示为十六进制
mysql> create table t9(id bit);
mysql> desc t9; #bit默认宽度为1
+-------+--------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+-------+
| id | bit(1) | YES | | NULL | |
+-------+--------+------+-----+---------+-------+
mysql> insert into t9 values(8);
mysql> select * from t9; #直接查看是无法显示二进制位的
+------+
| id |
+------+
| |
+------+
mysql> select bin(id),hex(id) from t9; #需要转换才能看到
+---------+---------+
| bin(id) | hex(id) |
+---------+---------+
| 1 | 1 |
+---------+---------+
mysql> alter table t9 modify id bit(5);
mysql> insert into t9 values(8);
mysql> select bin(id),hex(id) from t9;
+---------+---------+
| bin(id) | hex(id) |
+---------+---------+
| 1 | 1 |
| 1000 | 8 |
+---------+---------+三. 日期类型
类型: data, time, datatime, timestamp, year
作用: 存储用户注册时间,文章发布时间, 员工入职时间, 出生时间, 过期时间等.
year:
YYYY(范围:1901/2155)2018
data:
YYYY-MM-DD(范围:1000-01-01/9999-12-31)例:2018-01-01
time:
HH:MM:SS(范围:'-838:59:59'/'838:59:59')例:12:09:32
datatime:
YYYY-MM-DD HH:MM:SS(范围:1000-01-01 00:00:00/9999-12-31 23:59:59 Y)例: 2018-01-01 12:09:32
timestamp:
YYYY-MM-DD HH:MM:SS(范围:1970-01-01 00:00:00/2037 年某时)日期类型测试
year:
mysql> create table t10(born_year year); #无论year指定何种宽度,最后都默认是year(4)
mysql> insert into t10 values
-> (1900),
-> (1901),
-> (2155),
-> (2156);
mysql> select * from t10;
+-----------+
| born_year |
+-----------+
| 0000 |
| 1901 |
| 2155 |
| 0000 |
+-----------+
date,time,datetime:
mysql> create table t11(d date,t time,dt datetime);
mysql> desc t11;
+-------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------+------+-----+---------+-------+
| d | date | YES | | NULL | |
| t | time | YES | | NULL | |
| dt | datetime | YES | | NULL | |
+-------+----------+------+-----+---------+-------+
mysql> insert into t11 values(now(),now(),now());
mysql> select * from t11;
+------------+----------+---------------------+
| d | t | dt |
+------------+----------+---------------------+
| 2017-07-25 | 16:26:54 | 2017-07-25 16:26:54 |
+------------+----------+---------------------+
timestamp:
mysql> create table t12(time timestamp);
mysql> insert into t12 values();
mysql> insert into t12 values(null);
mysql> select * from t12;
+---------------------+
| time |
+---------------------+
| 2017-07-25 16:29:17 |
| 2017-07-25 16:30:01 |
+---------------------+
============注意啦,注意啦,注意啦===========
1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入
2. 插入年份时,尽量使用4位值
3. 插入两位年份时,<=69,以20开头,比如50, 结果2050
>=70,以19开头,比如71,结果1971
mysql> create table t12(y year);
mysql> insert into t12 values
-> (50),
-> (71);
mysql> select * from t12;
+------+
| y |
+------+
| 2050 |
| 1971 |
+------+
============综合练习===========
mysql> create table student(
-> id int,
-> name varchar(20),
-> born_year year,
-> birth date,
-> class_time time,
-> reg_time datetime);
mysql> insert into student values
-> (1,'sb1',"1995","1995-11-11","11:11:11","2017-11-11 11:11:11"),
-> (2,'sb2',"1997","1997-12-12","12:12:12","2017-12-12 12:12:12"),
-> (3,'sb3',"1998","1998-01-01","13:13:13","2017-01-01 13:13:13");
mysql> select * from student;
+------+------+-----------+------------+------------+--------------------+
| id | name | born_year | birth | class_time | reg_time |
+------+------+-----------+------------+------------+--------------------+
| 1 | sb1 | 1995 | 1995-11-11 | 11:11:11 | 2017-11-11 11:11:11 |
| 2 | sb2 | 1997 | 1997-12-12 | 12:12:12 | 2017-12-12 12:12:12 |
| 3 | sb3 | 1998 | 1998-01-01 | 13:13:13 | 2017-01-01 13:13:13 |
+------+------+-----------+------------+------------+--------------------+mysql的日期格式对字符串采用的是'放松'政策,可以以字符串的形式插入。
在实际应用的很多场景中,MySQL的这两种日期类型(datatime,timestamp)都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。下面就来总结一下两种日期类型的区别。
1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。
2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。
3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。
4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
工作中一般都用datetime就可以了。
对上面的datatime与timestamp的区别的第四条的验证
mysql> create table t1(x datetime not null default now()); # 需要指定传入空值时默认取当前时间
Query OK, 0 rows affected (0.01 sec)
mysql> create table t2(x timestamp); # 无需任何设置,在传空值的情况下自动传入当前时间
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t1 values();
Query OK, 1 row affected (0.00 sec)
mysql> insert into t2 values();
Query OK, 1 row affected (0.00 sec)
mysql> select * from t1;
+---------------------+
| x |
+---------------------+
| 2018-07-07 01:26:14 |
+---------------------+
1 row in set (0.00 sec)
mysql> select * from t2;
+---------------------+
| x |
+---------------------+
| 2018-07-07 01:26:17 |
+---------------------+
1 row in set (0.00 sec)
四. 字符串类型
类型: char, varchar
作用: ,名字, 信息等等
#官网:https://dev.mysql.com/doc/refman/5.7/en/char.html
#注意:char和varchar括号内的参数指的都是字符的长度
#char类型:定长,简单粗暴,浪费空间,存取速度快
字符长度范围:0-255(一个中文是一个字符,是utf8编码的3个字节)
存储:
存储char类型的值时,会往右填充空格来满足长度
例如:指定长度为10,存>10个字符则报错(严格模式下),存<10个字符则用空格填充直到凑够10个字符存储
检索:
在检索或者说查询时,查出的结果会自动删除尾部的空格,如果你想看到它补全空格之后的内容,除非我们打开pad_char_to_full_length SQL模式(SET sql_mode = 'strict_trans_tables,PAD_CHAR_TO_FULL_LENGTH';)
#varchar类型:变长,精准,节省空间,存取速度慢
字符长度范围:0-65535(如果大于21845会提示用其他类型 。mysql行最大限制为65535字节,字符编码为utf-8:https://dev.mysql.com/doc/refman/5.7/en/column-count-limit.html)
存储:
varchar类型存储数据的真实内容,不会用空格填充,如果'ab ',尾部的空格也会被存起来
强调:varchar类型会在真实数据前加1-2Bytes的前缀,该前缀用来表示真实数据的bytes字节数(1-2Bytes最大表示65535个数字,正好符合mysql对row的最大字节限制,即已经足够使用)
如果真实的数据<255bytes则需要1Bytes的前缀(1Bytes=8bit 2**8最大表示的数字为255)
如果真实的数据>255bytes则需要2Bytes的前缀(2Bytes=16bit 2**16最大表示的数字为65535)
检索:
尾部有空格会保存下来,在检索或者说查询时,也会正常显示包含空格在内的内容
下面我们来进行一些测试,在测试之前,我们需要学一下mysql给我们提供的两个方法:
length(字段):查看该字段数据的字节长度
char_length(字段):查看该字段数据的字符长度
char和varchar测试
创建一个t1表,包含一个char类型的字段
create table t1(id int,name char(4));
超过长度:
严格模式下(报错):
mysql> insert into t1 values('xiaoshabi');
ERROR 1406 (22001): Data too long for column 'name' at row 1
非严格模式下(警告):
mysql> set sql_mode='NO_ENGINE_SUBSTITUTION';
Query OK, 0 rows affected (0.00 sec)
mysql> create table t1(id int,name char(4));
Query OK, 0 rows affected (0.40 sec)
mysql> insert into t2 values('xiaoshabi');
Query OK, 1 row affected, 1 warning (0.11 sec)
查看一下结果:
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | xiao | #只有一个xiao
+------+------+
1 row in set (0.00 sec)
varchar类型和上面的效果是一样的,严格模式下也会报错。
如果没有超过长度,那么char类型时mysql会使用空格来补全自己规定的char(4)的4个字符,varchar不会,我们来做个对比
例如:
#再创建一个含有varchar类型的表t2
然后插入几条和t1里面相同的数据
mysql>insert into t1 values(2,'a'),(3,'bb'),(4,'ccc'),(5,'d');
mysql>create table t2(id int,name varchar(4));
mysql> insert into t2 values(1,'xiao'),(2,'a'),(3,'bb'),(4,'ccc'),(5,'d');
查看一下t1表和t2表的内容
mysql> select * from t1;
+------+------+
| id | name |
+------+------+
| 1 | xiao |
| 2 | a |
| 3 | bb |
| 4 | ccc |
| 5 | d |
+------+------+
5 rows in set (0.00 sec)
mysql> select * from t2;
+------+------+
| id | name |
+------+------+
| 1 | xiao |
| 2 | a |
| 3 | bb |
| 4 | ccc |
| 5 | d |
+------+------+
5 rows in set (0.00 sec)
好,两个表里面数据是一样的,每一项的数据长度也是一样的,那么我们来验证一下char的自动空格在后面补全的存储方式和varchar的不同
通过mysql提供的一个char_length()方法来查看一下所有数据的长度
mysql> select char_length(name) from t1;
+-------------------+
| char_length(name) |
+-------------------+
| 4 |
| 1 |
| 2 |
| 3 |
| 1 |
+-------------------+
5 rows in set (0.00 sec)
mysql> select char_length(name) from t2;
+-------------------+
| char_length(name) |
+-------------------+
| 4 |
| 1 |
| 2 |
| 3 |
| 1 |
+-------------------+
5 rows in set (0.00 sec)
通过查看结果可以看到,两者显示的数据长度是一样的,不是说好的char会补全吗,我设置的字段是char(4),那么长度应该都是4才对啊?这是因为mysql在你查询的时候自动帮你把结果里面的空格去掉了,如果我们想看到它存储数据的真实长度,需要设置mysql的模式,通过一个叫做PAD_CHAR_TO_FULL_LENGTH的模式,就可以看到了,所以我们把这个模式加到sql_mode里面:
mysql> set sql_mode='PAD_CHAR_TO_FULL_LENGTH';
Query OK, 0 rows affected (0.00 sec)
然后我们在查看一下t1和t2数据的长度:
mysql> select char_length(name) from t1;
+-------------------+
| char_length(name) |
+-------------------+
| 4 |
| 4 |
| 4 |
| 4 |
| 4 |
+-------------------+
5 rows in set (0.00 sec)
mysql> select char_length(name) from t2;
+-------------------+
| char_length(name) |
+-------------------+
| 4 |
| 1 |
| 2 |
| 3 |
| 1 |
+-------------------+
5 rows in set (0.00 sec)
通过结果可以看到,char类型的数据长度都是4,这下看到了两者的不同了吧,至于为什么mysql会这样搞,我们后面有解释的,先看现象就可以啦。
现在我们再来看一个问题,就是当你设置的类型为char的时候,我们通过where条件来查询的时候会有一个什么现象:
mysql> select * from t1 where name='a';
+------+------+
| id | name |
+------+------+
| 2 | a |
+------+------+
1 row in set (0.00 sec)
ok,结果没问题,我们在where后面的a后面加一下空格再来试试:
mysql> select * from t1 where name='a ';
+------+------+
| id | name |
+------+------+
| 2 | a |
+------+------+
1 row in set (0.00 sec)
ok,能查到,再多加一些空格试试,加6个空格,超过了设置的char(4)的4:
mysql> select * from t1 where name='a ';
+------+------+
| id | name |
+------+------+
| 2 | a |
+------+------+
1 row in set (0.00 sec)
ok,也是没问题的
总结:通过>,=,>=,<,<=作为where的查询条件的时候,char类型字段的查询是没问题的。
但是,当我们将where后面的比较符号改为like的时候,(like是模糊匹配的意思,我们前面见过,show variables like '%char%';来查看mysql字符集的时候用过)
其中%的意思是匹配任意字符(0到多个字符都可以匹配到),还有一个符号是_(匹配1个字符),这两个字符其实就像我们学的正则匹配里面的通配符,那么我们通过这些符号进行一下模糊查询,看一下,char类型进行模糊匹配的时候,是否还能行,看例子:
mysql> select * from t1 where name like 'a';
Empty set (0.00 sec)
发现啥也没查到,因为char存储的数据是4个字符长度的,不满4个是以空格来补全的,你在like后面就只写了一个'a',是无法查到的。
我们试一下上面的通配符来查询:
mysql> select * from t1 where name like 'a%';
+------+------+
| id | name |
+------+------+
| 2 | a |
+------+------+
1 row in set (0.00 sec)
这样就能看到查询结果了
试一下_是不是匹配1个字符:
mysql> select * from t1 where name like 'a_';
Empty set (0.00 sec)
发现一个_果然不行,我们试试三个_。
mysql> select * from t1 where name like 'a___';
+------+------+
| id | name |
+------+------+
| 2 | a |
+------+------+
1 row in set (0.00 sec)
发现果然能行,一个_最多匹配1个任意字符。
如果多写了几个_呢?
mysql> select * from t1 where name like 'a_____';
Empty set (0.00 sec)
查不到结果,说明_匹配的是1个字符,但不是0-1个字符。
测试结果总结:
针对char类型,mysql在存储的时候会将不足规定长度的数据使用后面(右边补全)补充空格的形式进行补全,然后存放到硬盘中,但是在读取或者使用的时候会自动去掉它给你补全的空格内容,因为这些空格并不是我们自己存储的数据,所以对我们使用者来说是无用的。
char和varchar性能对比:
以char(5)和varchar(5)来比较,加入我要存三个人名:sb,ssb1,ssbb2
char:
优点:简单粗暴,不管你是多长的数据,我就按照规定的长度来存,5个5个的存,三个人名就会类似这种存储:sb ssb1 ssbb2,中间是空格补全,取数据的时候5个5个的取,简单粗暴速度快
缺点:貌似浪费空间,并且我们将来存储的数据的长度可能会参差不齐
varchar:
varchar类型不定长存储数据,更为精简和节省空间
例如存上面三个人名的时候类似于是这样的:sbssb1ssbb2,连着的,如果这样存,请问这三个人名你还怎么取出来,你知道取多长能取出第一个吗?
不知道从哪开始从哪结束,遇到这样的问题,你会想到怎么解决呢?还记的吗?想想?socket?tcp?struct?把数据长度作为消息头。
所以,varchar在存数据的时候,会在每个数据前面加上一个头,这个头是1-2个bytes的数据,这个数据指的是后面跟着的这个数据的长度,1bytes能表示2 ** 8=256,两个bytes表示2**16=65536,能表示0-65535的数字,所以varchar在存储的时候是这样的:1bytes+sb+1bytes+ssb1+1bytes+ssbb2,所以存的时候会比较麻烦,导致效率比char慢,取的时候也慢,先拿长度,再取数据。
优点:节省了一些硬盘空间,一个acsii码的字符用一个bytes长度就能表示,但是也并不一定比char省,看一下官网给出的一个表格对比数据,当你存的数据正好是你规定的字段长度的时候,varchar反而占用的空间比char要多。
| Value | CHAR(4) |
Storage Required | VARCHAR(4) |
Storage Required |
|---|---|---|---|---|
'' |
' ' |
4 bytes | '' |
1 byte |
'ab' |
'ab ' |
4 bytes | 'ab' |
3 bytes |
'abcd' |
'abcd' |
4 bytes | 'abcd' |
5 bytes |
'abcdefgh' |
'abcd' |
4 bytes | 'abcd' |
5 bytes |
缺点:存取速度都慢
总结:
所以需要根据业务需求来选择用哪种类型来存
其实在多数的用户量少的工作场景中char和varchar效率差别不是很大,最起码给用户的感知不是很大,并且其实软件级别的慢远比不上硬件级别的慢,所以你们公司的运维发现项目慢的时候会加内存、换nb的硬盘,项目的效率提升的会很多,但是我们作为专业人士,我们应该提出来这样的技术点来提高效率。
但是对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列(所有数据行都使用指向数据列值的头指针),因此在本质上,使用固定长度的CHAR列不一定比使用可变长度VARCHAR列性能要好。因而,主要的性能因素是数据行使用的存储总量。由于CHAR平均占用的空间多于VARCHAR,因此使用VARCHAR来最小化需要处理的数据行的存储总量和磁盘I/O是比较好的。
所以啊,两个选哪个都可以,如果是大型并发项目,追求高性能的时候,需要结合你们服务器的硬件环境来进行测试,看一下char和varchar哪个更好,这也能算一个优化的点吧~~~~
其他的字符串类型:BINARY、VARBINARY、BLOB、TEXT
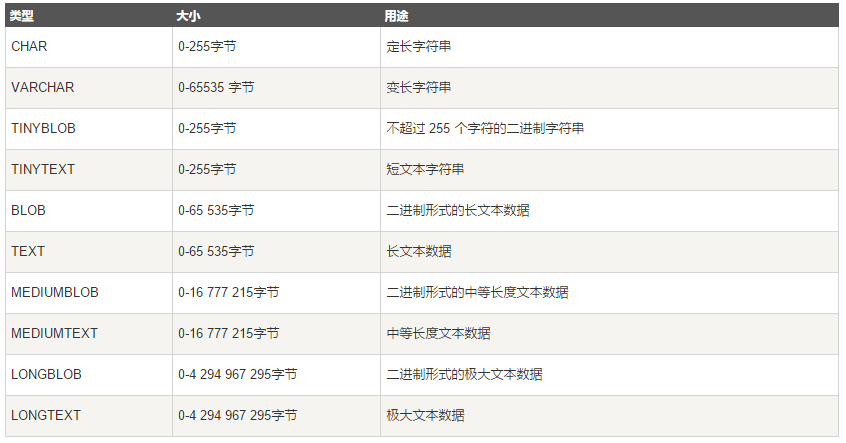
其他类型简单介绍:
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
BLOB:
1._BLOB和_text存储方式不同,_TEXT以文本方式存储,英文存储区分大小写,而_Blob是以二进制方式存储,不分大小写。
2._BLOB存储的数据只能整体读出。
3._TEXT可以指定字符集,_BLO不用指定字符集。
五. 枚举类型与集合类型
字段的值只能在给定范围中选择,如单选框,多选框,如果你在应用程序或者前端不做选项限制,在MySQL的字段里面也能做限制
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
枚举类型(enum)
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:
CREATE TABLE shirts (
name VARCHAR(40),
size enum('x-small', 'small', 'medium', 'large', 'x-large')
);
INSERT INTO shirts (name, size) VALUES ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small');
集合类型(set)
A SET column can have a maximum of 64 distinct members.
示例:
CREATE TABLE myset (col SET('a', 'b', 'c', 'd'));
INSERT INTO myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d');
枚举类型与集合类型测试
mysql> create table consumer(
-> name varchar(50),
-> sex enum('male','female'),
-> level enum('vip1','vip2','vip3','vip4','vip5'), #在指定范围内,多选一
-> hobby set('play','music','read','study') #在指定范围内,多选多
-> );
mysql> insert into consumer values
-> ('xiaogui','male','vip5','read,study'),
-> ('taibai','female','vip1','girl');
mysql> select * from consumer;
+------+--------+-------+------------+
| name | sex | level | hobby |
+------+--------+-------+------------+
| xiaogui | male | vip5 | read,study |
| taibai | female | vip1 | |
+------+--------+-------+------------+
百万年薪python之路 -- MySQL数据库之 常用数据类型的更多相关文章
- 百万年薪python之路 -- MySQL数据库之 永久修改字符串编码 与 忘了密码和修改密码
永久修改字符集编码的方法: 在mysql安装目录下创建一个my.ini(Windows下)文件,写入下面的配置,然后重启服务端. [client] #设置mysql客户端默认字符集 default-c ...
- 百万年薪python之路 -- MySQL数据库之 存储引擎
MySQL之存储引擎 一. 存储引擎概述 定义: 存储引擎是mysql数据库独有的存储数据.为数据建立索引.更新数据.查询数据等技术的实现方法 首先声明一点: 存储引擎这个概念只有MySQL才有. ...
- 百万年薪python之路 -- MySQL数据库之 Navicat工具和pymysql模块
一. IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navicat工具,这个工具本质上就是一个socket客户端,可视化的连接 ...
- 百万年薪python之路 -- MySQL数据库之 MySQL行(记录)的操作(一)
MySQL的行(记录)的操作(一) 1. 增(insert) insert into 表名 value((字段1,字段2...); # 只能增加一行记录 insert into 表名 values(字 ...
- 百万年薪python之路 -- MySQL数据库之 完整性约束
MySQL完整性约束 一. 介绍 为了防止不符合规范的数据进入数据库,在用户对数据进行插入.修改.删除等操作时,DBMS自动按照一定的约束条件对数据进行监测,使不符合规范的数据不能进入数据库,以确保数 ...
- 百万年薪python之路 -- MySQL数据库之 用户权限
MySQL用户授权 (来自于https://www.cnblogs.com/dong-/p/9667787.html) 一. 对新用户的增删改 1. 增加用户 : ①. 指定某一个用户使用某一个ip登 ...
- 百万年薪python之路 -- MySQL数据库之 MySQL行(记录)的操作(二) -- 多表查询
MySQL行(记录)的操作(二) -- 多表查询 数据的准备 #建表 create table department( id int, name varchar(20) ); create table ...
- 百万年薪python之路 -- JS基础介绍及数据类型
JS代码的引入 方式1: <script> alert('兽人永不为奴!') </script> 方式2:外部文件引入 src属性值为js文件路径 <script src ...
- python之路——MySQL数据库
1 MySQL相关概念介绍 MySQL为关系型数据库(Relational Database Management System), 这种所谓的"关系型"可以理解为"表格 ...
随机推荐
- Linux版本号的数值含义
Linux内核版本有两种:稳定版和开发版 ,Linux内核版本号由3组数字组成:第一个组数字.第二组数字.第三组数字.第一个组数字:目前发布的内核主版本.第二个组数字:偶数表示稳定版本:奇数表示开发中 ...
- hbase配置-集群无法启动问题
root@cslave2:/]#jps 2834 NodeManager 2487 DataNode 12282 Jps 2415 QuorumPeerMain root@cslave2:/]#sud ...
- Two progressions CodeForce 125D 思维题
An arithmetic progression is such a non-empty sequence of numbers where the difference between any t ...
- 在创建activiti5..22所需的25张表时 ,所用的方法和遇到的问题。
最近在学习关于activiti流程设计的相关内容,首先第一步就需要了解25张activiti相关的表,具体的每张表的含义 请自行百度. 这里讲一下 用java代码生成所需要的25张表,很简单: pub ...
- Python攻破淘宝网各类反爬手段,采集淘宝网ZDB(女用)的销量!
声明: 由于某些原因,我这里会用手机代替,其实是一样的! 环境: windows python3.6.5 模块: time selenium re 环境与模块介绍完毕后,就可以来实行我们的操作了. 第 ...
- JS/jQuery点击某元素之外触发事件
JQuery // 第一步:点击任何地方都触发事件 $(document).click(function(){ alert("点击当前页面的任何地方都触发此点击事件:"); }); ...
- vimrc配置文件
目录 vimrc配置文件 参考 主要功能 使用方法 配置文件 文件下载 vimrc配置文件
- C++——多文件结构和编译预处理命令
[toc] 一.多文件结构 1.一个工程可以划分为多个源文件 类声明文件(.h文件) 类实现文件(.cpp文件) 类的使用文件(main函数所在的.cpp文件) 2.利用工程来组合各个文件 //Poi ...
- Java 学习笔记之 Synchronized锁对象
Synchronized锁对象: Synchronized取得的锁都是对象锁,而不是把一段代码或方法当作锁,哪个线程执行带synchronized关键字的方法,哪个线程就持有该方法所属对象的锁,那么其 ...
- FutureTask是怎样获取到异步执行结果的?
所谓异步任务,就是不在当前线程中进行执行,而是另外起一个线程让其执行.那么当前线程如果想拿到其执行结果,该怎么办呢? 如果我们使用一个公共变量作为结果容器,两个线程共用这个值,那么应该是可以拿到结果的 ...