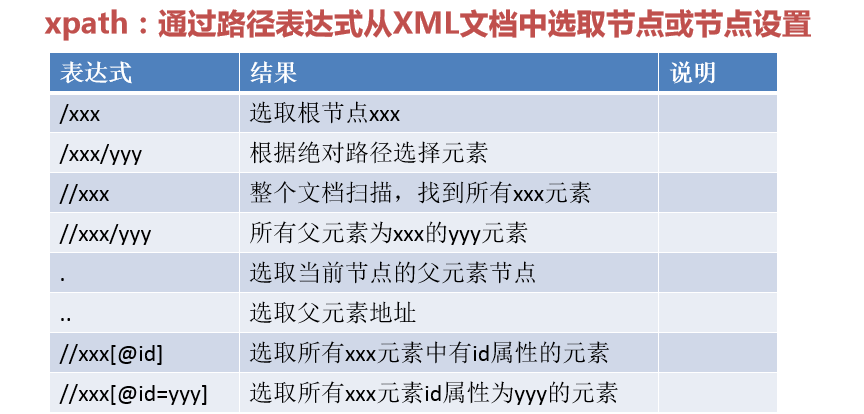
xpath:




from selenium import webdriver
b = webdriver.Firefox()
#路径读取方式一:
# b.get(r"C:\我的代码\selenium自动化测试\test.html")
#路径读取方式二:
# b.get("C:\\我的代码\\selenium自动化测试\\test.html")
#路径读取方式三:
b.get('file://C:\\我的代码\\selenium自动化测试\\test.html')
#打印选取根节点:
ele = b.find_element_by_xpath("/html")
print(ele)
#打印所有的文本:
print(ele.text)
#根据绝对路径选择元素:
ele1 = b.find_element_by_xpath("/html/body/form/input")
print(ele1)
#get_attribute查看type属性:
print(ele1.get_attribute("type"))
#同级定位输入框:
ele2 = b.find_element_by_xpath("/html/body/form/input[2]")
print(ele2.get_attribute("name"))
#遍历整个文档找到元素:
ele3 = b.find_element_by_xpath("//input")
print(ele3)
#遍历整个元素索引匹配:
ele4 = b.find_element_by_xpath("//input[2]")
print(ele4.get_attribute("name"))
#关闭页面:
# b.close()
#所有父元素为xxx的yyy元素:
ele5 = b.find_element_by_xpath("//form//input")
print(ele5.get_attribute("name"))
#获取id属性元素:
ele6 = b.find_element_by_xpath("//input[@id]")
print(ele6.id)
#找到所有的元素:
ele7 = b.find_element_by_xpath("//*")
print(ele7.tag_name)
#两个反斜杠是遍历整个文档、*是遍历整个元素、count元素统计标签个数
ele8 = b.find_element_by_xpath("//*[count(input)=2]")
print(ele8.tag_name)
#找到tag为某某的元素:
ele9 = b.find_element_by_xpath("//*[local-name()='input']")
print(ele9.tag_name)
#找到所有tag以某某开头的元素:
ele10 = b.find_element_by_xpath("//*[starts-with(local-name(),'i')]")
print(ele10.tag_name)
# 找到所有tag包含x的元素:
ele11 = b.find_element_by_xpath("//*[contains(local-name(),'i')]")
print(ele11.get_attribute("name"))
print(ele11.tag_name)
# 找到所有tag长度为3的元素:
# ele12 = b.find_element_by_xpath("//*[string-length(local-name())=5")
# print(ele12.get_attribute("name"))
# print(ele12.tag_name)
#多个路径查找:
ele13 = b.find_element_by_xpath("//title | //input")
print(ele13.tag_name)
#直接查找xpath:
ele14 = b.find_element_by_xpath("/html/body/p/input")
print(ele14.tag_name)
print(ele14.get_attribute("name"))
xpath:的更多相关文章
- json的xpath:简易数据查询
class JsonQuery(object): def __init__(self, data): super(JsonQuery, self).__init__() self.data = dat ...
- 爬虫系列3:Requests+Xpath 爬取租房网站信息并保存本地
数据保存本地 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 爬虫系列2:https://www ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 爬虫解析:XPath总结
1.加载 XML 文档 所有现代浏览器都支持使用 XMLHttpRequest 来加载 XML 文档的方法. 针对大多数现代浏览器的代码: var xmlhttp=new XMLHttpRequest ...
- (三)XML基础(3):Xpath
五.XPath:快速定位到节点 5.1 简介 5.2 语法 5.3 案例 XPath对有命名空间的xml文件和没有命名空间的xml定位节点的方法是不一样的,所以再对不同的xml需要进行不同的处理. 使 ...
- Web自动化测试:xpath & CSS Selector定位
Xpath 和 CSS Selector简介 CSS Selector CSS Selector和Xpath都可以用来表示XML文档中的位置.CSS (Cascading Style Sheets)是 ...
- 网页解析:Xpath 与 BeautifulSoup
1. Xpath 1.1 Xpath 简介 1.2 Xpath 使用案例 2. BeautifulSoup 2.1 BeautifulSoup 简介 2.2 BeautifulSoup 使用案例 1) ...
- xpath轴的正确使用姿势
网上看了许多关于轴的介绍,只介绍了语法,而没有明说具体实际中该怎么使用,百思不得其解. 背景--python中使用xpath: ----------------------------------- ...
- Selenium脚本编写环境的搭建/XPath
编写环境主要分为三个部分: JUnit : java单元测试框架: Firebug: firefox 附加组件,Firebug是firefox下的一个扩展,能够调试所有网站语言,如Html,Css等, ...
随机推荐
- .Net Core 使用 NPOI 导入Excel
由于之前在网上查阅一些资料发现总是不能编译通过,不能正常使用,现把能正常使用的代码贴出: /// <summary> /// Excel导入帮助类 /// </summary> ...
- 关于python中的增量赋值的理解
增量赋值运算符 += 和 *= 的表现取决于它们的第一个操作对象 += 操作首先会尝试调用对象的 __ iadd__方法,如果没有该方法,那么尝试调用__add__方法,所以+= 与 + 的区别实质是 ...
- Git实战指南----跟着haibiscuit学Git(第七篇)
笔名: haibiscuit 博客园: https://www.cnblogs.com/haibiscuit/ Git地址: https://github.com/haibiscuit?tab=re ...
- QT--动态人流量监测系统
QT--动态人流量监测系统 简介: 本项目使用了百度AI的动态人流量监测api,以人体头肩为主要识别目标,适用于低空俯拍,出入口场景,可用于统计当前图像的锁定人数和经过的人数 项目功能 本项目分为相机 ...
- 关于ssh的几个功能
这个有许多介绍的. 通过ssh可以实现远程shell命令行登录,x window登录,端口转发,scp文件复制,本地与远程命令间的管道连接,sftp文件传输与管理,包括同步,以及rsync文件同步,还 ...
- 截取字符串substr和substring两者的区别
两者有相同点: 如果只是写一个参数,两者的作用都是一样的:就是截取字符串当前下标以后直到字符串最后的字符串片段. 不同点:第二个参数: substr(startIndex,lenth): 第二个参数是 ...
- 使OrangePi Zero+支持U盘启动
以下步骤均在Armbian系统中完成 一.无内存卡启动 1.使用armbian-config启动SPI 输入sudo armbian-config→选中System并回车→选中Hardware并回车→ ...
- 蓝牙spp协议分析
基本概念 蓝牙串口是基于 SPP 协议(Serial Port Profile),能在蓝牙设备之间创建串口进行数据传输的一种设备. 蓝牙串口的目的是针对如何在两个不同设备(通信的两端)上的应用之间保证 ...
- Linux之自动化部署
No.1 自动化部署git项目 一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一一 ...
- 用户APC的执行过程
Windows内核分析索引目录:https://www.cnblogs.com/onetrainee/p/11675224.html 用户APC的执行过程 一.一个启发式问题 有一个问题,线程什么时候 ...