小白学 Python 爬虫(8):网页基础

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
先赞后看是个好习惯
网页的组成
我们的数据来源是网页,那么我们在真正抓取数据之前,有必要先了解一下一个网页的组成。
网页是由 HTML 、 CSS 、JavaScript 组成的。
HTML 是用来搭建整个网页的骨架,而 CSS 是为了让整个页面更好看,包括我们看到的颜色,每个模块的大小、位置等都是由 CSS 来控制的, JavaScript 是用来让整个网页“动起来”,这个动起来有两层意思,一层是网页的数据动态交互,还有一层是真正的动,比如我们都见过一些网页上的动画,一般都是由 JavaScript 配合 CSS 来完成的。
我们打开 Chrome 浏览器,访问博客站的首页,打开 F12 开发者工具,可以看到:
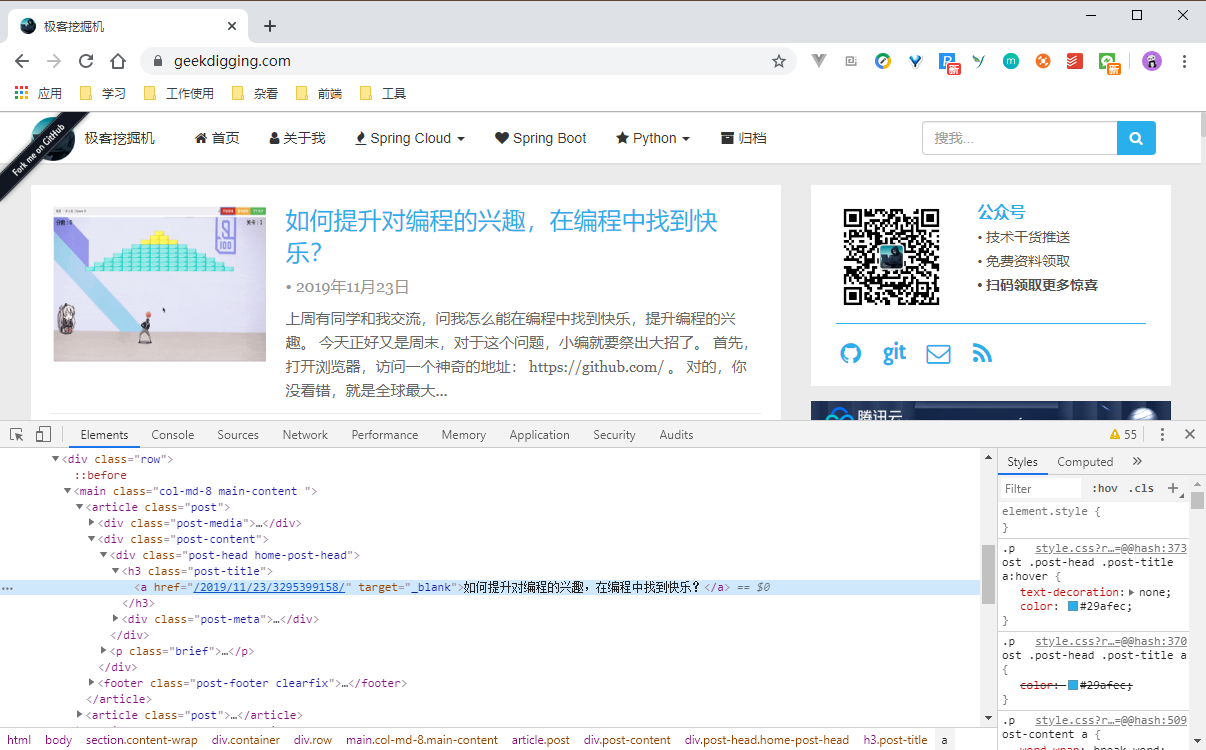
在选项 Elements 中可以看到网页的源代码,这里展示的就是 HTML 代码。
不同类型的文字通过不同类型的标签来表示,如图片用 <img> 标签表示,视频用 <video> 标签表示,段落用 <p> 标签表示,它们之间的布局又常通过布局标签 <div> 嵌套组合而成,各种标签通过不同的排列和嵌套才形成了网页的框架。
在右边 Style 标签页中,显示的就是当前选中的 HTML 代码标签的 CSS 层叠样式,“层叠”是指当在HTML中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理。“样式”指网页中文字大小、颜色、元素间距、排列等格式。
而 JavaScript 就厉害了,它在 HTML 代码中通常使用 <script> 进行包裹,可以直接书写在 HTML 页面中,也可以以文件的形式引入。
网页结构
我们来手写一个简单 HTML 页面来感受下。
首先创建一个文本文件,将后缀名改为 .html ,名字可以自取,写入如下内容:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h1>Hello World</h1>
<div>Hello Python.</div>
</div>
</div>
</body>
</html>
首先,整个文档是以 DOCTYPE 来开头的,这里定义了文档类型是 html ,整个文档最外层的标签是 <html> ,并且结尾还以 </html> 来表示闭和。
这里简单讲一下,浏览器解析 HTML 的时候,并不强制需要每个标签都一定要有闭和标签,但是为了语义明确,最好每个标签都跟上对应的闭和标签。各位同学可以尝试删除其中的闭和标签进行尝试,并不会影响浏览器的解析。
整个 HTML 文档一般分为 head 和 body 两个部分,在 head 头中,我们一般会指定当前的编码格式为 UTF-8 ,并且使用 title 来定义网页的标题,这个会显示在浏览器的标签上面。
body 中的内容一般为整个 html 文档的正文,这里小编简单写了几个 div 的嵌套。
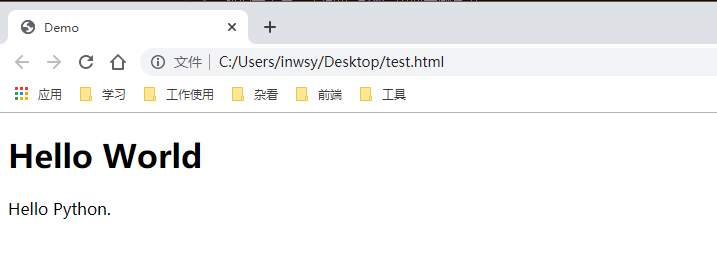
这个页面的显示如下:
HTML DOM
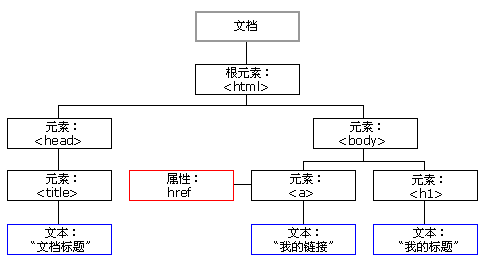
在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
- 整个文档是一个文档节点
- 每个 HTML 元素是元素节点
- HTML 元素内的文本是文本节点
- 每个 HTML 属性是属性节点
- 注释是注释节点
HTML DOM 将 HTML 文档视作树结构。这种结构被称为节点树:
通过 HTML DOM,树中的所有节点均可通过 JavaScript 进行访问。所有 HTML 元素(节点)均可被修改,也可以创建或删除节点。
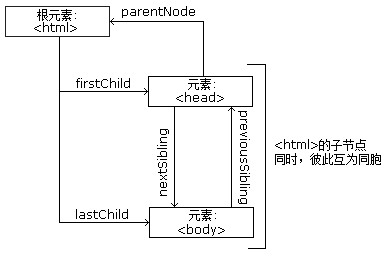
节点树中的节点彼此拥有层级关系。
父(parent)、子(child)和同胞(sibling)等术语用于描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
- 在节点树中,顶端节点被称为根(root)
- 每个节点都有父节点、除了根(它没有父节点)
- 一个节点可拥有任意数量的子
- 同胞是拥有相同父节点的节点
下面的图片展示了节点树的一部分,以及节点之间的关系:
CSS
前面我们介绍到 CSS 可以用来美化网页,那么我们简单加一点 CSS 修改下页面的显示效果。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
<style type="text/css">
.wrapper {
text-align: center;
}
</style>
</head>
<body>
<div id="container">
<div class="wrapper">
<h1>Hello World</h1>
<div>Hello Python.</div>
</div>
</div>
</body>
</html>
我们在 head 中添加了 style 标签,并注明其中的内容解析方式为 CSS 。其中的内容的含义是让文本居中显示,先看下增加 CSS 后的页面效果吧:
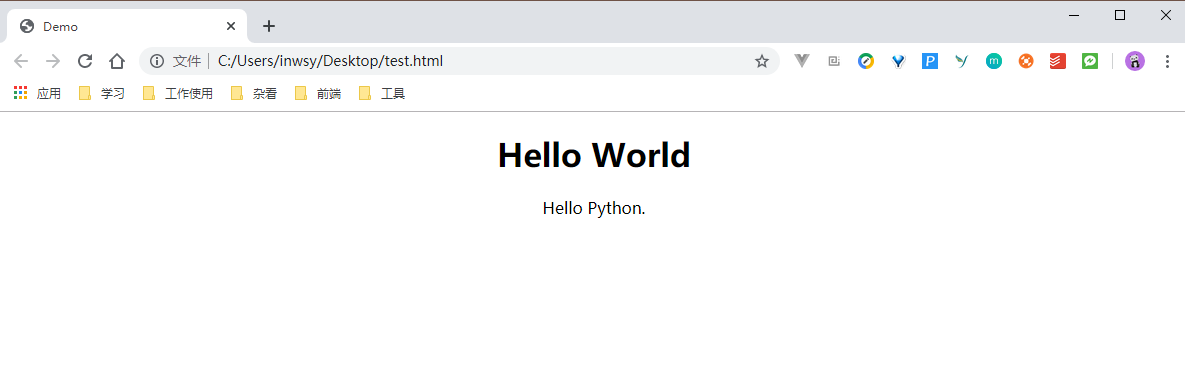
可以看到,原来居左的文字已经居中显示了。
那么,CSS 是如何表示它要修饰的文档结构的呢?这就要说到 CSS 选择器了。
在CSS中,我们使用CSS选择器来定位节点。例如,上例中 div 节点的 id 为 container ,那么就可以表示为 #container ,其中 # 开头代表选择 id ,其后紧跟 id 的名称。另外,如果我们想选择 class 为 wrapper 的节点,便可以使用 .wrapper ,这里以点 . 开头代表选择 class ,其后紧跟 class 的名称。
另外, CSS 选择器还支持嵌套选择,各个选择器之间加上空格分隔开便可以代表嵌套关系,如 #container .wrapper p 则代表先选择 id 为 container 的节点,然后选中其内部的 class 为 wrapper 的节点,然后再进一步选中其内部的 p 节点。另外,如果不加空格,则代表并列关系,如 div#container .wrapper p.text 代表先选择 id 为 container 的 div 节点,然后选中其内部的 class 为 wrapper 的节点,再进一步选中其内部的 class 为 text 的 p 节点。这就是 CSS 选择器,其筛选功能还是非常强大的。
参考
https://www.w3school.com.cn/htmldom/dom_nodes.asp
https://cuiqingcai.com/5476.html
小白学 Python 爬虫(8):网页基础的更多相关文章
- 小白学 Python 爬虫(7):HTTP 基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(9):爬虫基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(11):urllib 基础使用(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(12):urllib 基础使用(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(13):urllib 基础使用(三)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(14):urllib 基础使用(四)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(15):urllib 基础使用(五)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(17):Requests 基础使用
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(30):代理基础
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- fenby C语言 P32
a[0] a[0][0] a[0][1] a[0][2] a[1] a[1][0] a[1][1] a[1][2]//一维数组 int a[2][3]//二维数组int (*p)[3]=a; #inc ...
- Golang 实现华为云 DMS 签名
构造请求 首先构造请求,也就是要对哪个具体接口进行访问,需要提供什么必要的参数.在构造请求(点击查看中可以看到,对 DMS 服务来说必要的请求构成包括以下部分 请求URI,例如 https://dms ...
- 【原创】基于.NET的轻量级高性能 ORM - TZM.XFramework 之让代码更优雅
[前言] 大家好,我是TANZAME.出乎意料的,我们在立冬的前一天又见面了,天气慢慢转凉,朋友们注意添衣保暖,愉快撸码.距离 TZM.XFramework 的首秀已数月有余,期间收到不少朋友的鼓励. ...
- MYSQL结构修改
mysql改表结构主要是5大操作 ADD 添加字段 MODIFY 修改字段类型 CHANGE 修改字段名(也可以修改字段名) DROP 删除字段 RENAME 修改表名 ADD添加新字段:(新字段默认 ...
- 说说Java中你不知道switch关键字
Switch语法 switch作为Java内置关键字,却在项目中真正使用的比较少.关于switch,还是有那么一些奥秘的. 要什么switch,我有if-else 确实,项目中使用switch比较少的 ...
- 【TCP/IP网络编程】:03地址族与数据序列
上一篇文章介绍了套接字的创建过程,这篇文章主要讨论分配给套接字的IP地址和端口号的相关知识. IP地址和端口号 IP(Internet Protocol,网络协议)地址是收发网络数据而分配给计算机的值 ...
- 2、linu
一.常用linux命令 昨日内容回顾 linux基本命令 ls 查看目录和文件ls -la 查看所有文件和目录详情(包括隐藏文件, -l和-a可以单独使用)mkdirrmdirtouchcatcdrm ...
- python编程【环境篇】- 如何优雅的管理python的版本
简介 之前的文章(Python2还是python3 )中我们提到,建议现在大家都采用python3,因为python2在今年年底将不在维护.但在实际的开发和使用python过程中,我们避免不了还得用到 ...
- NOIP模拟赛 华容道 (搜索和最短路)蒟蒻的第一道紫题
题目描述 小 B 最近迷上了华容道,可是他总是要花很长的时间才能完成一次.于是,他想到用编程来完成华容道:给定一种局面, 华容道是否根本就无法完成,如果能完成, 最少需要多少时间. 小 B 玩的华容道 ...
- Wireshark嗅探抓取telnet明文账户密码
0x00 Wireshark(前称Ethereal)是一个网络封包分析软件.网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料.Wireshark使用WinPCAP作为接口,直 ...