解析innodb中的MVCC
本人免费整理了Java高级资料,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并发分布式等教程,一共30G,需要自己领取。
传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
一、MVCC简介
一、MVCC简介
MVCC (Multiversion Concurrency Control),即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能
读锁:也叫共享锁、S锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S 锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
写锁:又称排他锁、X锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
表锁:操作对象是数据表。Mysql大多数锁策略都支持(常见mysql innodb),是系统开销最低但并发性最低的一个锁策略。事务t对整个表加读锁,则其他事务可读不可写,若加写锁,则其他事务增删改都不行。
行级锁:操作对象是数据表中的一行。是MVCC技术用的比较多的,但在MYISAM用不了,行级锁用mysql的储存引擎实现而不是mysql服务器。但行级锁对系统开销较大,处理高并发较好。
二、MVCC实现原理
innodb MVCC主要是为Repeatable-Read事务隔离级别做的。在此隔离级别下,A、B客户端所示的数据相互隔离,互相更新不可见
了解innodb的行结构、Read-View的结构对于理解innodb mvcc的实现由重要意义
innodb存储的最基本row中包含一些额外的存储信息 DATA_TRX_ID,DATA_ROLL_PTR,DB_ROW_ID,DELETE BIT
- 6字节的DATA_TRX_ID 标记了最新更新这条行记录的transaction id,每处理一个事务,其值自动+1
- 7字节的DATA_ROLL_PTR 指向当前记录项的rollback segment的undo log记录,找之前版本的数据就是通过这个指针
- 6字节的DB_ROW_ID,当由innodb自动产生聚集索引时,聚集索引包括这个DB_ROW_ID的值,否则聚集索引中不包括这个值.,这个用于索引当中
- DELETE BIT位用于标识该记录是否被删除,这里的不是真正的删除数据,而是标志出来的删除。真正意义的删除是在commit的时候
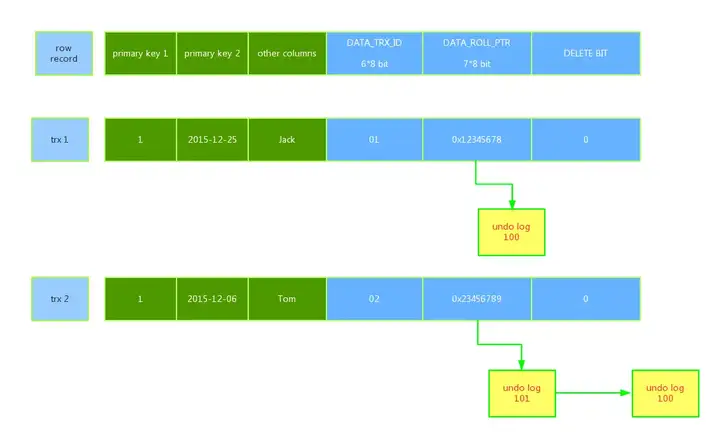
具体的执行过程
begin->用排他锁锁定该行->记录redo log->记录undo log->修改当前行的值,写事务编号,回滚指针指向undo log中的修改前的行
上述过程确切地说是描述了UPDATE的事务过程,其实undo log分insert和update undo log,因为insert时,原始的数据并不存在,所以回滚时把insert undo log丢弃即可,而update undo log则必须遵守上述过程
下面分别以select、delete、 insert、 update语句来说明
SELECT
Innodb检查每行数据,确保他们符合两个标准:
1、InnoDB只查找版本早于当前事务版本的数据行(也就是数据行的版本必须小于等于事务的版本),这确保当前事务读取的行都是事务之前已经存在的,或者是由当前事务创建或修改的行
2、行的删除操作的版本一定是未定义的或者大于当前事务的版本号,确定了当前事务开始之前,行没有被删除
符合了以上两点则返回查询结果。
INSERT
InnoDB为每个新增行记录当前系统版本号作为创建ID。
DELETE
InnoDB为每个删除行的记录当前系统版本号作为行的删除ID。
UPDATE
InnoDB复制了一行。这个新行的版本号使用了系统版本号。它也把系统版本号作为了删除行的版本。
说明
insert操作时 “创建时间”=DB_ROW_ID,这时,“删除时间 ”是未定义的;
update时,复制新增行的“创建时间”=DB_ROW_ID,删除时间未定义,旧数据行“创建时间”不变,删除时间=该事务的DB_ROW_ID;
delete操作,相应数据行的“创建时间”不变,删除时间=该事务的DB_ROW_ID;
select操作对两者都不修改,只读相应的数据
三、对于MVCC的总结
上述更新前建立undo log,根据各种策略读取时非阻塞就是MVCC,undo log中的行就是MVCC中的多版本,这个可能与我们所理解的MVCC有较大的出入,一般我们认为MVCC有下面几个特点:
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本随意修改,各个事务之间无干扰
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
就是每行都有版本号,保存时根据版本号决定是否成功,听起来含有乐观锁的味道,而Innodb的实现方式是:
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
二者最本质的区别是,当修改数据时是否要排他锁定,如果锁定了还算不算是MVCC?
Innodb的实现真算不上MVCC,因为并没有实现核心的多版本共存,undo log中的内容只是串行化的结果,记录了多个事务的过程,不属于多版本共存。但理想的MVCC是难以实现的,当事务仅修改一行记录使用理想的MVCC模式是没有问题的,可以通过比较版本号进行回滚;但当事务影响到多行数据时,理想的MVCC据无能为力了。
比如,如果Transaciton1执行理想的MVCC,修改Row1成功,而修改Row2失败,此时需要回滚Row1,但因为Row1没有被锁定,其数据可能又被Transaction2所修改,如果此时回滚Row1的内容,则会破坏Transaction2的修改结果,导致Transaction2违反ACID。
理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。修改两行数据,但为了保证其一致性,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
解析innodb中的MVCC的更多相关文章
- mysql中innodb引擎的mvcc机制和BufferPool缓存机制
一.MVCC (1)mvcc主要undo日志版本链和read-view一致性视图来保证多事务的并发控制,mvcc是innodb的一种特殊机制,他保证了事务四大特性之一的隔离性(原子性,一致性,隔离性) ...
- (转)InnoDB存储引擎MVCC实现原理
InnoDB存储引擎MVCC实现原理 原文:https://liuzhengyang.github.io/2017/04/18/innodb-mvcc/ 简单背景介绍 MySQL MySQL是现在最流 ...
- 转:InnoDB多版本(MVCC)实现简要分析
InnoDB多版本(MVCC)实现简要分析 基本知识 假设对于多版本(MVCC)的基础知识,有所了解.InnoDB为了实现多版本的一致读,采用的是基于回滚段的协议. 行结构 InnoDB表数据的组织方 ...
- Innodb中的事务隔离级别和锁的关系
前言: 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式.同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力. ...
- Innodb中的事务隔离级别和锁的关系(转)
原文:http://tech.meituan.com/innodb-lock.html 前言: 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式.同时数据库 ...
- MySQL InnoDB下关于MVCC的一个问题的分析
这个是网友++C++在群里问的一个关于MySQL的问题,本篇文章实验测试环境为MySQL 5.6.20,事务隔离级别为REPEATABLE-READ ,在演示问题前,我们先准备测试环境.准备一个测 ...
- MySQL InnoDB中的事务隔离级别和锁的关系
前言: 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式.同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力. ...
- InnoDB中锁的查看
Ⅰ. show engine innodb status\G 1.1 实力分析一波 锁介绍的那篇中已经提到了这个命令,现在我们开一个参数,更细致的分析一下这个命令 (root@localhost) [ ...
- InnoDB中锁的模式,锁的查看,算法
InnoDB中锁的模式 Ⅰ.总览 S行级共享锁lock in share mode X行级排它锁增删改 IS意向共享锁 IX意向排他锁 AI自增锁 Ⅱ.锁之间的兼容性 兼 X IX S IS X ...
随机推荐
- HttpRunner学习7--引用CSV文件数据
前言 在之前的文章中,我们已经学习了 parameters 参数化,是在测试脚本中直接指定参数列表.这种方法简单易用,但如果我们的参数列表数据比较多,这种方法可能就不太适合了. 当数据量比较大的时候, ...
- C# 中的栈和堆
程序运行时,它的数据必须存储在内存中.一个数据项需要多大的内存.存储在内存中的什么位置.以及如何存储都依赖于该数据项的类型. 运行中的程序使用两个内存区域来存储数据:栈和堆. 栈 栈是一个内存数组,是 ...
- linux系统centos7安装最新版本nginx
一.准备环境 1.安装centos,一般买一个阿里云测试 2.下载nginx,链接http://nginx.org/download/nginx-1.10.2.tar.gz 二.开始安装 1.cent ...
- JS---案例:协议按钮禁用(倒计时)
案例:协议按钮倒计时和禁用 <textarea name="texta" id="" cols="30" rows="10& ...
- numpy的基本API(四)——拼接、拆分、添加、删除
numpy的基本拼接.拆分.添加.删除API iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 1.np.concatenate((a, b), axis=0) ...
- Kafka实战(七) - 优雅地部署 Kafka 集群
既然是集群,必然有多个Kafka节点,只有单节点构成的Kafka伪集群只能用于日常测试,不可能满足线上生产需求. 真正的线上环境需要考量各种因素,结合自身的业务需求而制定.看一些考虑因素(以下顺序,可 ...
- Spring 常犯的十大错误,(收藏后)永远不要在犯了
1. 错误一:太过关注底层 我们正在解决这个常见错误,是因为 “非我所创” 综合症在软件开发领域很是常见.症状包括经常重写一些常见的代码,很多开发人员都有这种症状. 虽然理解特定库的内部结构及其实现, ...
- sql server中取交集、差集和并集的语法
这里简单总结下在SQL Server中取交集.差集和并集的语法. 交集:INTERSECT(适用于两个结果集) SELECT ID, NAME FROM YANGGB1 INTERSECT SELEC ...
- .Net Core 使用 NPOI 导入Excel
由于之前在网上查阅一些资料发现总是不能编译通过,不能正常使用,现把能正常使用的代码贴出: /// <summary> /// Excel导入帮助类 /// </summary> ...
- 解决bcp导出CSV文件没有表头
思路: 1.输出表头文件到指定目录 2.bcp导出csv文件到temp目录 3.将以上导出文件与表头文件合并 4.删除temp目录下的文件 实现: create proc exportCSV ( @i ...