Flume 学习笔记之 Flume NG+Kafka整合
Flume NG集群+Kafka集群整合:
修改Flume配置文件(flume-kafka-server.conf),让Sink连上Kafka
hadoop1:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop1
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop1
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ScalaTopic
a1.sinks.k1.brokerList = hadoop1:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel=c1
hadoop2:
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = hadoop2
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = hadoop2
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = ScalaTopic
a1.sinks.k1.brokerList = hadoop2:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel=c1
集群测试:
- 启动zookeeper(hadoop1,hadoop2,hadoop3)
- 启动kafka server和consumer(hadoop1,hadoop2)
- 启动Flume server(hadoop1,hadoop2):flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-kafka-server.conf --name a1 -Dflume.root.logger=INFO,console
- 启动Flume client(hadoop3):flume-ng agent --conf conf --conf-file /usr/local/flume/conf/flume-client.conf --name agent1 -Dflume.root.logger=INFO,console
- 在hadoop3上追加一条日志记录
- kafka consumer收到记录,从则测试完毕。
hadoop3:

hadoop1:
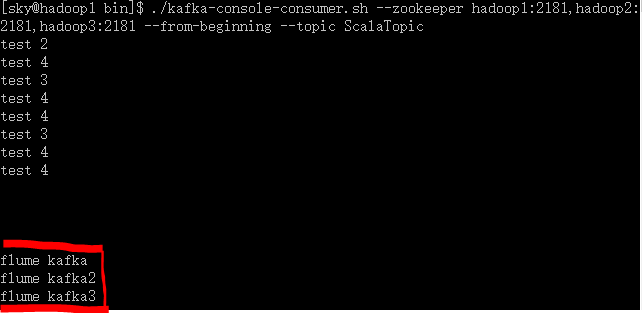
测试完毕,这样Flume+kafka就整合起来了,即Flume+Kafka+Spark Streaming的实时日志分析系统就孕育而生了。
Flume 学习笔记之 Flume NG+Kafka整合的更多相关文章
- Flume 学习笔记之 Flume NG高可用集群搭建
Flume NG高可用集群搭建: 架构总图: 架构分配: 角色 Host 端口 agent1 hadoop3 52020 collector1 hadoop1 52020 collector2 had ...
- Flume 学习笔记之 Flume NG概述及单节点安装
Flume NG概述: Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
- flume学习笔记——安装和使用
Flume是一个分布式.可靠.和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力. Flume是一 ...
- Spring学习笔记(六)—— SSH整合
一.整合原理 二.整合步骤 2.1 导包 [hibernate] hibernate/lib/required hibernate/lib/jpa 数据库驱动 [struts2] struts-bla ...
- Flink学习笔记:Connectors之kafka
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- 【Flume学习之一】Flume简介
环境 apache-flume-1.6.0 Flume是分布式日志收集系统.可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase:同类工具:Facebook Scribe,Apache ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- Apache Flume 学习笔记
# 从http://flume.apache.org/download.html 下载flume ############################################# # 概述: ...
- flume学习笔记
#################################################################################################### ...
随机推荐
- POJ-2406Power Strings-KMP+定理
Power Strings 题意:给一个字符串S长度不超过10^6,求最大的n使得S由n个相同的字符串a连接而成,如:"ababab"则由n=3个"ab"连接而 ...
- Harbinger vs Sciencepal
Harbinger vs Sciencepal 题意:给你n对人, 每一对都有2个人,每个人分别有一个值, 现在将每队人拆开塞入2组,要求分完这n对人之后,2个组的差值最小. 题解:将每队人的差值算出 ...
- Codeforces 468 B Two Sets
Two Sets 题意:就是将一对数放进setA, setB中, 如果放进setA的话要求满足 x与a-x都在这个集合里面, 如果放进setB中要求满足x与b-x都在这个集合中. 题解:我们将能放进B ...
- 【Leetcode】【简单】【66. 加一】【JavaScript】
题目描述 66. 加一 给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一. 最高位数字存放在数组的首位, 数组中每个元素只存储单个数字. 你可以假设除了整数 0 之外,这个整数不会以零 ...
- vim中处理重定向文件中的^H和^M
做实验的时候会把日志重定向写到文件中,方便以后查看.但是用vim打开之后出现很多^H和^M,就像乱码一样.如图所示: 现在尝试在vim中解决这个问题. 替换^H 在vim中输入命令,表示把^H替换成空 ...
- 【Redis】缓存穿透与缓存雪崩
一.缓存雪崩 1.1 缓存雪崩产生的原因 1.2 解决方案 1.3 锁的方式 1.4 消息中间件 1.5 一级和二级缓存 1.6 均摊分配redis key 失效时间 二.缓存穿透 一.缓存雪崩 1. ...
- 编写一个函数来反转某个二进制型里的字节顺序(erlang)
reverse_byte(<<>>) -> <<>>; reverse_byte(<<Header:8, Tail/bits>& ...
- Python二元操作符
def quiz_message(grade): outcome = 'failed' if grade<50 else 'passid' print ('grade', grade, 'out ...
- Spring Boot(一):快速开始
Spring Boot(一):快速开始 本系列文章旨在使用最小依赖.最简单配置,帮助初学者快速掌握Spring Boot各组件使用,达到快速入门的目的.全部文章所使用示例代码均同步Github仓库和G ...
- Spring Boot初识
今天准备开一个新系列springboot,springboot结束后会更新springcloud,想要学会springcloud先学springboot吧.以后springboot和hadoop轮流更 ...