Oracle 优化器_访问数据的方法_单表
Oracle 在选择执行计划的时候,优化器要决定用什么方法去访问存储在数据文件中的数据。我们从数据文件中查询到相关记录,有两种方法可以实现:1.直接访问表记录所在位置。2.访问索引,拿到索引中对应的rowid,然后根据rowid 去表中获取相应的数据。(有些情况,不需要再去表中取数据就可以得到相应的结果,那么就会直接返回)。
访问表的方法
全表扫描
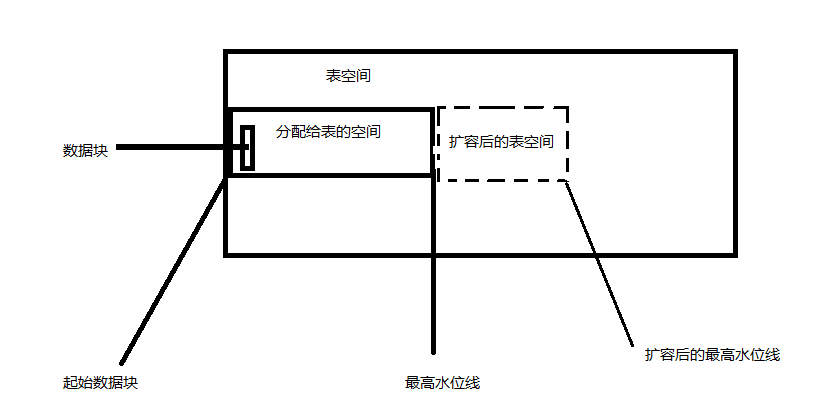
全表扫描,Oracle 在取数据库数据的时候,从该表在硬盘上的第一个数据块开始,扫描到该表的最高水位线所在的数据块。在读的时候,会使用多块读的技术,将全表扫描一遍表数据,然后将不满足的数据剔除掉,返回需要的数据。Oracle 全表扫描的速度取决于最高水位线的大小。当表中的高水位线越大,需要消耗的资源(主要是I/O资源)越多。这样一来,耗费的时间也会增加。
高水位:在Oracle中,表是属于表空间的,如果建表的时候,没有设置表空间,那么就会将当前用户的默认空间作为表格所在的表空间。如果一直往表中插入数据,分配给表的空间用完了,高水位线就会向上移动。如果用delete语句删除数据,水位线也不回降下来。这就会导致,有的表虽然只有几条数据,但是全表扫描就会很消耗性能。所以在进行大量的delete操作的时候,需要执行降水位的操作。
ROWID 扫描
rowId 类似于指针的概念。rowid和数据块中的行数据是一一对应的。我们知道某一行对应的rowid后,可以直接通过rowid去直接访问相应数据对应的数据行。Oracle 使用row取数据有两种:1、直接用rowId从取得相应数据。2、根据索引获得rowId,然后取数据。
我们获取rowid的方法很简单,在每行记录中,都有一个Oracle内置的伪列rowId 直接在查询的时候去获取就可以了(注:这里需要将rowId 进行重命名,不然无法返回,不知道是不是笔者个人原因还是都需要这么写)。以emp表为例:
SELECT ENAME ,EMPNO, rowId dataRowId FROM EMP;
查出来的结果如下:
SMITH 7368 AAAtkkAAGAABqYkAAA
SMITH 7369 AAAtkkAAGAABqYkAAB
ALLEN 7499 AAAtkkAAGAABqYkAAC
WARD 7521 AAAtkkAAGAABqYkAAD
JONES 7566 AAAtkkAAGAABqYkAAE
MARTIN 7654 AAAtkkAAGAABqYkAAF
BLAKE 7698 AAAtkkAAGAABqYkAAG
CLARK 7782 AAAtkkAAGAABqYkAAH
SCOTT 7788 AAAtkkAAGAABqYkAAI
KING 7839 AAAtkkAAGAABqYkAAJ
TURNER 7844 AAAtkkAAGAABqYkAAK
ADAMS 7876 AAAtkkAAGAABqYkAAL
JAMES 7900 AAAtkkAAGAABqYkAAM
FORD 7902 AAAtkkAAGAABqYkAAN
MILLER 7934 AAAtkkAAGAABqYkAAO
这里查出的rowId可以直接作为where条件去进行查询,SQL如下:
SELECT ENAME ,EMPNO, rowId dataRowId FROM EMP where rowId='AAAtkkAAGAABqYkAAA';
执行结果:

这条SQL的执行计划如下:
Plan hash value: 1116584662 -----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 22 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY USER ROWID| EMP | 1 | 22 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------- Note
-----
从Id为1的这一行可以看出,执行计划走的是 BY USER ROWID 这个执行计划。我们对比下通过主键EMPNO去查询得到的执行计划:
执行SQL如下:
SELECT ENAME ,EMPNO, rowId dataRowId FROM EMP where EMPNO='';
执行结果跟通过rowId执行得到的执行结果一致:

其执行计划如下:
Plan hash value: 2137789089 ---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 8168 | 16336 | 29 (0)| 00:00:01 |
| 1 | COLLECTION ITERATOR PICKLER FETCH| DISPLAY | 8168 | 16336 | 29 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------- Note
-----
可以看出,通过rowId得到的结果比使用主键进行查找的消耗要小的多,因为主键是先通过主键索引找到rowId,然后进行数据的提取操作,而rowId则是直接从数据文件中提取数据。
访问索引的方法
索引结构(B树索引)
在说通过索引扫描数据之前,先介绍下什么是索引。Oracle数据库中用的最多的是B树索引。B树索引的结构如下图所示:
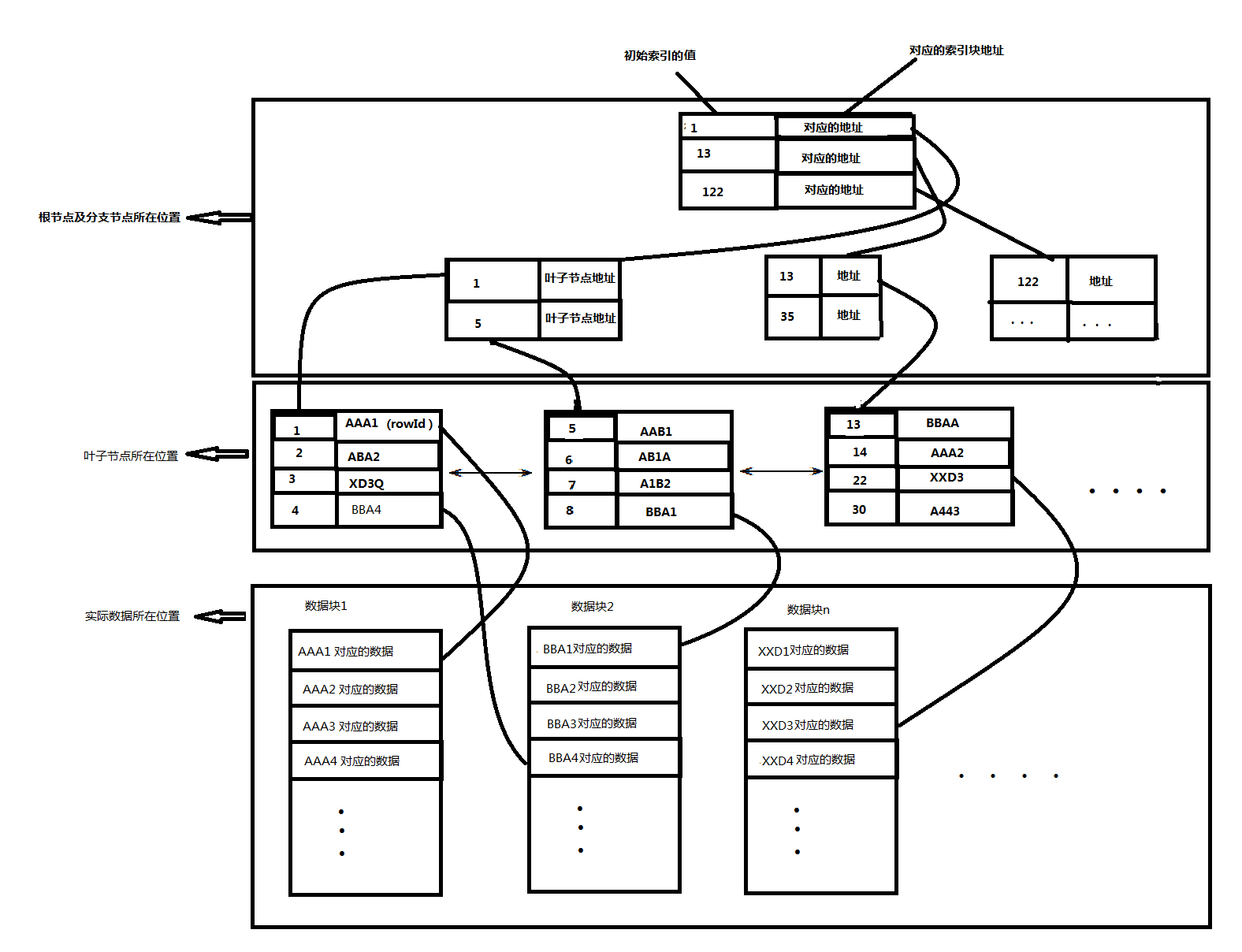
索引包含两个部分,一部分是索引分支块,另外一部分是叶子块。在数据根据索引进行扫描的时候,可以根据数据的内容,计算得出一个索引的值。然后根据索引值,得到响应的rowId,然后根据rowid,去数据文件取出相应的数据。Oracle 通过索引访问表里的记录的效率并不会随着相关表的数据量的递增而显著降低,所以索引访问数据的时间是基本稳定可控的。
索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描,是针对唯一性索引(unique scan)进行的扫描。当它的where条件是等于号的时候,扫描结果至多会返回一条数据记录。例如:sql语句:
select * from emp where EMPNO = 7368
执行计划:
Plan hash value: 2949544139 --------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 37 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 37 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("EMPNO"=7368) Note
索引范围扫描(INDEX RANGE SCAN)
范围索引扫描,使用于所有类型的B树索引,当扫描对象是唯一性索引时,目标的SQL条件一定是范围条件,例如 where 条件为between、<、> 等。
例如,SQL语句为:
select * from emp where EMPNO > 7933
执行计划为:
Plan hash value: 2787773736 ----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 37 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 37 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | PK_EMP | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("EMPNO">7933) Note
通过对比范围索引和唯一索引可以看出,即使使用同样的索引,范围索引也比唯一索引消耗更多的CPU,因为范围索引至少要多一次逻辑读。
索引全扫描(INDEX FULL SCAN)
索引在做全扫描的时候,要求索引不能为空。不然会漏掉null 的字段。索引全扫描在默认情况下,直接从第一个叶子节点,通过叶子节点之间相互的链表指针进行跳转。既能保证数据有序,又避免了对索引真正值的排序操作。
sql语句:
SELECT EMPNO FROM EMP
执行计划 :
Plan hash value: 179099197 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16 | 64 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | PK_EMP | 16 | 64 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------- Note
索引快速全扫描(INDEX FAST FULL SCAN)
索引快速扫描和索引全扫描类似,与之相比有如下区别:
1.快速全扫描只适用于CBO。
2.索引快速全扫描可以使用多块读,也可以并发执行。
3.索引快速全扫描结果不一定有序。
索引跳跃式扫描(INDEX SKIP SCAN)
索引跳跃式扫描适用于组合索引。适用场景举例:当前索引有两个列,为:C1,C2。当我们的SQL语句where条件中,没有对C1进行筛选,而是对C2进行了筛选。那么有时候就会出现使用跳跃式索引扫描的情况。Oracle 中索引跳跃扫描适用于前导列可选择性较差,后续列的可选择性又非常好的场景。因为前导列包含的distinct值越少,跳跃次数也就越少,索引效率也就越高。
Oracle 优化器_访问数据的方法_单表的更多相关文章
- Oracle优化器基础知识之访问数据的方法
目录 一.访问数据的方法 1.直接访问数据 2.访问索引 一.访问数据的方法 Oracle访问表中数据的方法有两种,一种是直接表中访问数据,另外一种是先访问索引,如果索引数据不符合目标SQL,就回表, ...
- Oracle索引梳理系列(一)- Oracle访问数据的方法
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle 优化器_表连接
概述 在写SQL的时候,有时候涉及到的不仅只有一个表,这个时候,就需要表连接了.Oracle优化器处理SQL语句时,根据SQL语句,确定表的连接顺序(谁是驱动表,谁是被驱动表及 哪个表先和哪个表做链接 ...
- Oracle优化器介绍
Oracle优化器介绍 本文讲述了Oracle优化器的概念.工作原理和使用方法,兼顾了Oracle8i.9i以及最新的10g三个版本.理解本文将有助于您更好的更有效的进行SQL优化工作. RBO优化器 ...
- Oracle 优化器
http://blog.csdn.net/it_man/article/details/8185370一.优化器基本知识 Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执 ...
- ORACLE优化器RBO与CBO介绍总结
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- [转]ORACLE优化器RBO与CBO的区别
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- 【SQL Server性能优化】删除大量数据的方法比较
原文:[SQL Server性能优化]删除大量数据的方法比较 如果你要删除表中的大量数据,这个大量一般是指删除大于10%的记录,那么如何删除,效率才会比较高呢? 而如何删除才会对系统的影响相对较小呢? ...
- 选用适合的ORACLE优化器
ORACLE的优化器共有3种: a. RULE (基于规则) b. COST (基于成本) c. CHOOSE (选择性) 设置缺省的优化器,可以通过对init.ora文件中OPTIMIZER ...
随机推荐
- [原创]一款基于Reactor线程模型的java网络爬虫框架
AJSprider 概述 AJSprider是笔者基于Reactor线程模式+Jsoup+HttpClient封装的一款轻量级java多线程网络爬虫框架,简单上手,小白也能玩爬虫, 使用本框架,只需要 ...
- java数组扩容
有些时候使用数组代替栈,玩意数组容量不够需要扩容 则: 1.Array.toString();直接遍历打印数组 2.数组扩容采用Array.copyOf(),直接实现数组扩容功能,非常强大 (实际 ...
- Linux学习笔记05之网络基础知识
一.OSI参考模型:适用于所有网络,现有模型,后有协议 1.应用层:应用程序.用户接口 2.表示层:编码转换.压缩.解压.加密等 3.会话层:建立.维护.拆除会话 4.传输层规定了应用程序的的接口 协 ...
- hdu 6406 Taotao Picks Apples (线段树)
Problem Description There is an apple tree in front of Taotao's house. When autumn comes, n apples o ...
- git之coding.net的使用
先在Coding上创建个项目 现在是这样,我本地有个项目Project(/Users/huang/Desktop/Project),我想把它上传到刚创建的项目里,以后就用git代码托管.可我之 ...
- spring学习笔记之---bean管理的注解方式
bean管理的注解方式 (一)使用注解定义bean (1)常用注解 (2)实例 1.在pom.xml中进行配置 <dependencies> <dependency> < ...
- 关于Unity 中对UGUI制作任务系统的编程
版权声明: 本文原创发布于博客园"优梦创客"的博客空间(网址:http://www.cnblogs.com/raymondking123/)以及微信公众号"优梦创客&qu ...
- 【原创】JAVA进程突然消失的原因?
引言 值此七夕佳节,烟哥放弃了无数妹纸的邀约,坐在电脑面前码字,就是为了给读者带来新的知识,这是一件伟大的事业! 好吧,实际情况是没人约.为了化解尴尬,我决定卖力写文章,嗯,一定是我过于屌丝! 好了, ...
- c++/c关于函数指针
顺便提一句:指针也是一种变量类型 和 int double 这些类型是一个级别 不同的是它的值是地址 #include "stdafx.h"#include<stdlib.h ...
- JMS入门简介
一.JMS是什么 1.JMS即Java消息服务(Java Message Service)应用程序接口,是一个Java平台中关于面向消息中间件(MOM)的API,用于在两个应用程序之间,或分布式系统中 ...