06 css选择器
一、简介
cookie概念
当用户通过浏览器首次访问一个域名时,访问的web服务器会给客户端发送数据,以保持web服务器与客户端之间的状态保持,这些数据就是cookie。
Cookie 是指某些网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件,Cookie可以保持登录信息到用户下次与服务器的会话。
为什么会有cookie呢?
因为http和https都是短链接,链接成功之后链接马上断开了。服务端是不会保存客户端的相关信息的。所以,服务端和客户端是没有办法建立一个长链接的。为了让服务端长久的记录客户端的状态。才会产生cookie这样一种机制。客户端第一次访问服务端的时候,服务端会给客户端创建一次会话,会给客户端创建一个cookie,用来让服务器端记录客户端相关的状态的。服务器端把cookie创建好之后,cookie不会存在服务器端,会让服务器端发送给客户端,会保存到客户端浏览器本地。一旦存到客户端之后,客户端下次向服务器发请求的时候,就可以携带这个cookie了。服务端就可以收到这个cookie,服务端就会根据这个cookie来判定当前客户端是怎么样的状态。
Cookie是http消息头中的一种属性,包括:
Cookie名字(Name)
Cookie的值(Value)
Cookie的过期时间(Expires/Max-Age)
Cookie作用路径(Path)
Cookie所在域名(Domain),
使用Cookie进行安全连接(Secure)。
前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大小限制是有差异的)。
Cookie由变量名和值组成,根据 Netscape公司的规定,Cookie格式如下:
Set-Cookie: NAME=VALUE;Expires=DATE;Path=PATH;Domain=DOMAIN_NAME;SECURE
二、cookie 使用
- 手动处理:将cookie添加到headers
- 自动处理:使用会话对象requests.Session(),会话对象可以向requests模块一样进行请求的发送。
案例1:
在爬取豆瓣的数据时发现了一些问题。因为要做一个爬虫,爬取用户读过的书以及对书的评分。但是在进行网页的分析时却出现了点问题。 当浏览器打开用户读书记录的链接时是没有任何问题的,但是用requests库来进行网页爬取时却出现了问题。 以https://book.douban.com/people/…/collect这个链接为例,获取这个链接的html源码,一般都是这样写:
import requests url = 'https://book.douban.com/people/.../collect'
r = requests.get(url)
print(r.text)
运行结果却是:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
网页却能正常访问
经过百度后发现,这是因为在爬取网页时没有传入Cookie,服务器不能识别用户身份,网页不能显示给没有用户身份的请求,所以网页源码被隐藏了。因此,要在请求时加上Cookie,如何获取Cookie? 不能https://book.douban.com/people/…/collect这个链接中直接获取Cookie,因为这个链接在缺少Cookie的情况下根本不能正常访问。但是可以登录豆瓣官网来获取Cookie,登录豆瓣官网不需要Cookie。
import urllib.request
import http.cookiejar /*设置文件来存储Cookie*/
filename = 'cookie.txt' /*创建一个MozillaCookieJar()对象实例来保存Cookie*/
cookie = http.cookiejar.MozillaCookieJar(filename) /*创建Cookie处理器*/
handler = urllib.request.HTTPCookieProcessor(cookie) /*构建opener*/
opener = urllib.request.build_opener(handler)
response = opener.open("https://www.douban.com/")
cookie.save(ignore_discard=True, ignore_expires=True)
打开cookie.txt文件会发现cookie已被保存。 
这样在访问用户读过的书的链接时,从文件中读取Cookie,在进行网页请求时加上Cookie就行了。
import requests
import http.cookiejar cookie = http.cookiejar.MozillaCookieJar()
/*加载Cookie*/
cookie.load('cookie.txt', ignore_discard=True, ignore_expires=True)
url = 'https://book.douban.com/people/.../collect'
r = requests.get(url, cookies=cookie)
print(r.text)123456789
运行结果:
<!DOCTYPE html>
<html lang="zh-cmn-Hans" class=" book-new-nav">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>
读过的书(219)
</title> <script>!function(e){var o=function(o,n,t){var c,i,r=new Date;n=n||30,t=t||"/",r.setTime(r.getTime()+24*n*60*60*1e3),c="; expires="+r.toGMTString();for(i in o)e.cookie=i+"="+o[i]+c+"; path="+t},n=function(o){var n,t,c,i=o+"=",r=e.cookie.split(";");for(t=0,c=r.length;t<c;t++)if(n=r[t].replace(/^\s+|\s+$/g,""),0==n.indexOf(i))return n.substring(i.length,n.length).replace(/\"/g,"");return null},t=e.write,c={"douban.com":1,"douban.fm":1,"google.com":1,"google.cn":1,"googleapis.com":1,"gmaptiles.co.kr":1,"gstatic.com":1,"gstatic.cn":1,"google-analytics.com":1,"googleadservices.com":1},i=function(e,o){var n=new Image;n.οnlοad=function(){},n.src="https://www.douban.com/j/except_report?kind=ra022&reason="+encodeURIComponent(e)+"&environment="+encodeURIComponent(o)},r=function(o){try{t.call(e,o)}catch(e){t(o)}},a=/<script.*?src\=["']?([^"'\s>]+)/gi,g=/http:\/\/(.+?)\.([^\/]+).+/i;e.writeln=e.write=function(e){var t,l=a.exec(e);return l&&(t=g.exec(l[1]))?c[t[2]]?void r(e):void("tqs"!==n("hj")&&(i(l[1],location.href),o({hj:"tqs"},1),setTimeout(function(){location.replace(location.href)},50))):void r(e)}}(document);
</script>
案例2:伪造cookie
爬取豆瓣时却出了问题: 豆瓣封IP,白天一分钟可以访问40次,晚上一分钟可以访问60次,超过限制次数就会封IP。 即使使用代理IP,但是一旦超过限制次数爬虫仍然不能正常访问豆瓣。 问题出在Cookie上 ,豆瓣利用封IP+封Cookie来限制爬虫,因此只用代理IP的话也不行,Cookie也要更换。
- 想法1: 每次使用代理IP时,先访问豆瓣官网获取Cookie再访问用户的评论页面。本以为换了IP,Cookie随之也会更换,其实Cookie并没有改变。
- 想法2: 伪造Cookie。 观察豆瓣设置的Cookie格式,并进行伪造。
import requests
r = requests.get('https://www.douban.com/')
print(r.cookies)
'''
<RequestsCookieJar[<Cookie bid=UTM5r4DvtLY for .douban.com/>, <Cookie ll="118237" for .douban.com/>]>
'''
下图是第一次访问豆瓣官网时,豆瓣建立Cookie的格式。如果已经访问过,可以把Cookie的信息删除再访问。
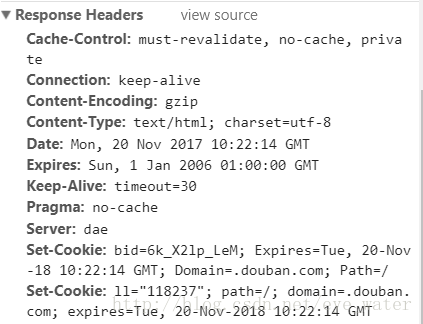
然后,根据Set-Cookie的格式构造Cookie就行了。 先构造一个Cookie试试:
import requests jar = requests.cookies.RequestsCookieJar()
jar.set('tasty_cookie', 'yum', domain='.douban.com', path='/cookies')
url = 'https://book.douban.com/people/122624856/collect'
r = requests.get(url, cookies=jar)
print(r.text)
运行结果:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
按照豆瓣的格式来构造Cookie:
import requests jar = requests.cookies.RequestsCookieJar()
jar.set('bid', 'ehjk9OLdwha', domain='.douban.com', path='/')
jar.set('', '', domain='.douban.com', path='/')
url = 'https://book.douban.com/people/122624856/collect'
r = requests.get(url, cookies=jar)
print(r.text)
运行结果:
<!DOCTYPE html>
<html lang="zh-cmn-Hans" class=" book-new-nav">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>
北渺读过的书(175)
</title> <script>!function(e){var o=function(o,n,t){var c,i,r=new Date;n=n||30,t=t||"/",r.setTime(r.getTime()+24*n*60*60*1e3),c="; expires="+r.toGMTString();for(i in o)e.cookie=i+"="+o[i]+c+"; path="+t},n=function(o){var n,t,c,i=o+"=",r=e.cookie.split(";");for(t=0,c=r.length;t<c;t++)if(n=r[t].replace(/^\s+|\s+$/g,""),0==n.indexOf(i))return n.substring(i.length,n.length).replace(/\"/g,"");return null},t=e.write,c={"douban.com":1,"douban.fm":1,"google.com":1,"google.cn":1,"googleapis.com":1,"gmaptiles.co.kr":1,"gstatic.com":1,"gstatic.cn":1,"google-analytics.com":1,"googleadservices.com":1},i=function(e,o){var n=new Image;n.οnlοad=function(){},n.src="https://www.douban.com/j/except_report?kind=ra022&reason="+encodeURIComponent(e)+"&environment="+encodeURIComponent(o)},r=function(o){try{t.call(e,o)}catch(e){t(o)}},a=/<script.*?src\=["']?([^"'\s>]+)/gi,g=/http:\/\/(.+?)\.([^\/]+).+/i;e.writeln=e.write=function(e){var t,l=a.exec(e);return l&&(t=g.exec(l[1]))?c[t[2]]?void r(e):void("tqs"!==n("hj")&&(i(l[1],location.href),o({hj:"tqs"},1),setTimeout(function(){location.replace(location.href)},50))):void r(e)}}(document);
</script>
案例3:雪球网,爬取新闻标题和内容
1 import requests
2 from lxml import etree
3 headers = {
4 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
5 }
6
7 # 创建一个会话对象:可以像requests模块一样发起请求。如果请求过程中产生cookie的话,则cookie会被会话自动处理
8 s = requests.Session()
9 first_url = 'https://xueqiu.com/'
10
11 # 请求过程中会产生cookie,cookie就会被存储到session对象中,从起始url获取cookie
12 s.get(url=first_url,headers=headers)
13
14
15 url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=-1&count=10&category=-1'
16
17 #携带cookie,对url进行请求发送。# 这里不能用request发送,要用session对象
18 json_obj = s.get(url=url,headers=headers).json()
19 print(json_obj)
案例4:模拟登录古诗文网
请求这个验证码图片的时候,也会产生cookie,模拟登陆的时候需要使用这张图片所对应的cookie,所以直接使用session发送请求。这个案例总共保存了2组cookie , 一组是验证码的,一组是登录信息的。
1 import requests
2 import urllib
3 from lxml import etree
4 headers = {
5 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
6 }
7 s = requests.Session()
8 login_url = 'https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx'
9 page_text = requests.get(url=login_url,headers=headers).text
10 tree = etree.HTML(page_text)
11 img_src = 'https://so.gushiwen.org'+tree.xpath('//*[@id="imgCode"]/@src')[0]
12 img_data = s.get(url=img_src,headers=headers).content
13 with open('./img.jpg','wb') as fp:
14 fp.write(img_data)
15 img_text = getCodeDate('bobo328410948','bobo328410948','./img.jpg',1004)
16
17 #模拟登录
18 url = 'https://so.gushiwen.org/user/login.aspx?from=http%3a%2f%2fso.gushiwen.org%2fuser%2fcollect.aspx'
19 data = {
20 "__VIEWSTATE":"9AsGvh3Je/0pfxId7DYRUi258ayuEG4rrQ1Z3abBgLoDSOeAUatOZOrAIxudqiOauXpR9Zq+dmKJ28+AGjXYHaCZJTTtGgrEemBWI1ed7oS7kpB7Rm/4yma/+9Q=",
21 "__VIEWSTATEGENERATOR":"C93BE1AE",
22 "from":"http://so.gushiwen.org/user/collect.aspx",
23 "email":"xxx@qq.com",
24 "pwd":"*****",
25 "code":img_text,
26 "denglu":"登录",
27 }
28 page_text = s.post(url=url,headers=headers,data=data).text
29 with open('./gushiwen.html','w',encoding='utf-8') as fp:
30 fp.write(page_text)
三、爬虫中获取cookie的方式
为什么要获取cookie?
因为有的页面爬取的时候,需要登录后才能爬,比如知乎,如何判断一个页面是否已经登录,通过判断是否含有cookies就可以,我们获取到cookie后就可以携带cookie来访问需要登录后的页面了。
方式一:使用session
这里的session并不是django中的session,而是requests中的session
import requests url = 'https://www.processon.com/login'
login_email = '286933867@qq.com'
login_password = 'ZZZ05382881391' # 创建一个session,作用会自动保存cookie
session = requests.session()
data = {
'login_email': login_email,
'login_password': login_password
} # 使用session发起post请求来获取登录后的cookie,cookie已经存在session中
response = session.post(url = url,data=data) # 用session给个人主页发送请求,因为session中已经有cookie了
index_url = 'https://www.processon.com/diagrams'
index_page = session.get(url=index_url).text
print(index_page)
把cookie保存在本地,并判断用户是否已经登录。
import requests
from http import cookiejar # 创建一个session,作用会自动保存cookie
session = requests.session() # 指定cookie保存的路径
session.cookies = cookiejar.LWPCookieJar(filename="cookies.txt")
try:
session.cookies.load(ignore_discard=True) # 加载cookie文件,ignore_discard = True,即使cookie被抛弃,也要保存下来
except:
print('cookie未能加载') def login_save_cookie():
"""
登录并保存cookie到本地
:return:
"""
url = 'https://www.processon.com/login'
login_email = '*****@qq.com'
login_password = '****1391'
data = {
'login_email': login_email,
'login_password': login_password
}
# 使用session发起post请求来获取登录后的cookie,cookie已经存在session中
response = session.post(url=url, data=data)
# 把cookie保存到文件中
session.cookies.save() def read_cookie():
"""
读取cookie进入登录后的页面
:return:
"""
index_url = 'https://www.processon.com/diagrams'
index_page = session.get(url=index_url).text
print(index_page) def login_y_n():
"""
判断用户是否已经登录,我们这里使用的方法是:随便找一个登陆后页面的url,如果我们访问它时不发生重定向,我们就可以
判断该用户应经登录了
:return:
"""
url = 'https://www.processon.com/diagrams/new#template'
response = session.get(url = url,allow_redirects=False) # allow_redirects =False不允许重定向到登录页面
if response != 200:
return False
else:
return True read_cookie()
方法二:使用selenium获取cookies
from selenium import webdriver
import json
browser = webdriver.Chrome(executable_path=r"E:\chromedriver_win32_2.46\chromedriver.exe") def get_cookies():
"""
通过selenium获取cookie保存在文件中
:return:
"""
url = 'https://www.processon.com/login'
browser.get(url=url)
browser.find_element_by_id('login_email').send_keys('286933867@qq.com')
browser.find_element_by_id('login_password').send_keys('ZZZ05382881391')
browser.find_element_by_id('signin_btn').click()
# 获取cookie,这里得到的是一个列表
cookies_list = browser.get_cookies()
browser.close()
with open("cookies.txt", "w") as fp:
json.dump(cookies_list, fp) # 这里切记,如果我们要使用json.load读取数据,那么一定要使用json.dump来写入数据,
# 不能使用str(cookies)直接转为字符串进行保存,因为其存储格式不同。这样我们就将cookies保存在文件中了。 def read_cookie():
"""
读取cookie,添加到browser中
:return:
"""
url = 'https://www.processon.com/diagrams'
browser.get(url=url) # 这里必须先访问一次否则页面不能打开
with open('./cookies.txt','r') as fp:
cookies_list = json.load(fp)
for cookies in cookies_list:
browser.add_cookie(cookies)
browser.get(url) read_cookie()
注意:用selenium来获取的cookie是一个列表,列表中有很多字典,字典中有domain、expiry、name、value、path等key,但是在我们真正的浏览器中就只有一个字典,字典中只有name 键对应的值和value对应的值,所以在使用的时候还需要转换一下:
[{"domain": ".processon.com", "expiry": 1560351255.689168, "httpOnly": false, "name": "_sid", "path": "/", "secure": false, "value": "796afe66ce2a6002828ab3ca281f96fb"},
{"domain": ".processon.com", "httpOnly": true, "name": "JSESSIONID", "path": "/", "secure": false, "value": "EBDACE1BDAB1464A2CCBBFFB7048A238.jvm1"},
{"domain": ".processon.com", "expiry": 1586703257, "httpOnly": false, "name": "zg_did", "path": "/", "secure": false, "value": "%7B%22did%22%3A%20%2216a173113351bb-062c441b2e33b7-7a1437-144000-16a173113362e%22%7D"},
{"domain": ".processon.com", "expiry": 1560351255.689117, "httpOnly": false, "name": "processon_userKey", "path": "/", "secure": false, "value": "59f7fba9e4b0edf0e25cd413"},
{"domain": ".processon.com", "expiry": 1555167313, "httpOnly": false, "name": "_gat", "path": "/", "secure": false, "value": ""},
{"domain": ".processon.com", "expiry": 1555253657, "httpOnly": false, "name": "_gid", "path": "/", "secure": false, "value": "GA1.2.1345294219.1555167253"},
{"domain": ".processon.com", "expiry": 1618239257, "httpOnly": false, "name": "_ga", "path": "/", "secure": false, "value": "GA1.2.555498451.1555167253"},
{"domain": ".processon.com", "expiry": 1586703257, "httpOnly": false, "name": "zg_3f37ba50e54f4374b9af5be6d12b208f", "path": "/", "secure": false, "value": "%7B%22sid%22%3A%201555167253312%2C%22updated%22%3A%201555167257424%2C%22info%22%3A%201555167253326%2C%22superProperty%22%3A%20%22%7B%7D%22%2C%22platform%22%3A%20%22%7B%7D%22%2C%22utm%22%3A%20%22%7B%7D%22%2C%22referrerDomain%22%3A%20%22%22%2C%22cuid%22%3A%20%2259f7fba9e4b0edf0e25cd413%22%7D"}]
Cookie: zg_did=%7B%22did%22%3A%20%2216a16fc24ab1e7-08f589794c6e4d-7a1437-144000-16a16fc24ac76a%22%7D; _ga=GA1.2.1095343087.1555163784; _gid=GA1.2.545489346.1555163784; processon_userKey=59f7fba9e4b0edf0e25cd413; _sid=796afe66ce2a6002828ab3ca281f96fb; zg_3f37ba50e54f4374b9af5be6d12b208f=%7B%22sid%22%3A%201555163784372%2C%22updated%22%3A%201555165807015%2C%22info%22%3A%201555163784376%2C%22superProperty%22%3A%20%22%7B%7D%22%2C%22platform%22%3A%20%22%7B%7D%22%2C%22utm%22%3A%20%22%7B%7D%22%2C%22referrerDomain%22%3A%20%22%22%2C%22cuid%22%3A%20%2259f7fba9e4b0edf0e25cd413%22%7D; JSESSIONID=685AABAF6B8D70AF25E501C7E9E67A32.jvm1
参考链接:https://www.cnblogs.com/amou/p/9136925.html
https://blog.csdn.net/eye_water/article/details/78484217
https://blog.csdn.net/eye_water/article/details/78585394
https://www.cnblogs.com/sticker0726/articles/10703682.html
06 css选择器的更多相关文章
- CSS+DIV入门第一天基础视频 CSS选择器层叠性和继承性
大家好,我是小强老师, 现在网上的CSS+DIV视频,要么讲的太深,要么太浅,很多初学的同学们总是遇到困难,今天小强老师专门给大家准备了css课程的视频.带你从零基础学习CSS+DIV一直到能独立完成 ...
- Unit02: CSS 概述 、 CSS 语法 、 CSS 选择器 、 CSS声明
Unit02: CSS 概述 . CSS 语法 . CSS 选择器 . CSS声明 my.css p { color: yellow; } demo1.html <!DOCTYPE html&g ...
- CSS选择器使用
今天要对CSS选择器的使用方法做一个全面的总结(几乎全部是从这篇文章摘抄的 https://blog.csdn.net/qq_39241986/article/details/82185697) CS ...
- 前端极易被误导的css选择器权重计算及css内联样式的妙用技巧
记得大学时候,专业课的网页设计书籍里面讲过css选择器权重的计算:id是100,class是10,html标签是5等等,然后全部加起来的和进行比较... 我只想说:真是误人子弟,害人不浅! 最近,在前 ...
- css选择器
常用css选择器,希望对大家有所帮助,不喜勿喷. 1.*:通用选择器 * { margin: 0; padding: 0; } 选择页面上的全部元素,通常用于清除浏览器默认样式,不推荐使用. 2.#i ...
- dynamic-css 动态 CSS 库,使得你可以借助 MVVM 模式动态生成和更新 css,从 js 事件和 css 选择器的苦海中脱离出来
dynamic-css 使得你可以借助 MVVM 模式动态生成和更新 css,从而将本插件到来之前,打散.嵌套在 js 中的修改样式的代码剥离出来.比如你要做元素跟随鼠标移动,或者根据滚动条位置的变化 ...
- CSS选择器的权重与优先规则?
我们做项目的时候,经常遇到样式层叠问题,被其他的样式覆盖,或者写的权重不高没效果,对权重没有具体的分析,做了一个总结. css继承是从一个元素向其后代元素传递属性值所采用的机制.确定应当向一个元素应用 ...
- css选择器的使用详解
-.css选择器的分类: 二.常用选择器详解: 1.标签选择器: 语法: 标签名 { 属性:属性值; } 代码示例: h1 { color: #ccc; font-size: 28px; } 2.类选 ...
- js,jq,css选择器
js获取节点: var chils= s.childNodes; //得到s的全部子节点 var par=s.parentNode; //得到s的父节点 var ns=s.nextSbiling; / ...
随机推荐
- MD5的简单用法
非常简单的MD5加密和解密(即用即copy) 点击帮助灯泡引用就可使用 //生成MD5帮助文件文件 public class MD5Help{ ///MD5加密 方法类 public static s ...
- [leetcode] 621. Task Scheduler(medium)
原题 思路: 按频率最大的字母来分块,频率最大的字母个数-1为分成的块数,每一块个数为n+1 比如AAABBCE,n=2, 则分为A-A- +A AAABBBCCEE,n=2,则分为AB-AB- +A ...
- [virtualenvwrapper] 命令小结
创建环境 mkvirtualenv env1 mkvirtualenv env2 环境创建之后,会自动进入该目录,并激活该环境. 切换环境 workon env1 workon env2 列出已有环境 ...
- UTF-16 -- 顶级程序员也会忽略的系统编码问题,JDK 错了十年!
Unicode(统一码.万国码.单一码)是计算机科学领域里的一项业界标准,包括字符集.编码方案等.Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一 ...
- ArcGIS API For JavaScript 开发(二)基础地图
有了开发环境,接下来的就是实践了,实践是检验真理的唯一标准! 多多练习,不要觉得自己能够想的出来就万事大吉了,还是得动手做才是最好的检验自己的能力. 基础地图,本节将通过arcgis api for ...
- Python 学习笔记(1)Python容器:列表、元组、字典与集合
Python容器:列表.元组.字典与集合 列表: 1.列表 的创建 使用[ ] 或者 list()创建列表:empty_list = [ ] 或者 empty_list= list() 使用list( ...
- RestClient测试
1,对象里面包含集合及字符串属性 {"roloeList":[{ "id":10001,"areaid":1,"name" ...
- 箭头函数=>
箭头函数特点一:没有自己的this对象,其this对象为所在环境 特点二 :没有arguments参数 可以用...rest代替特点三:不能使用构造函数,不可使用new命令,否则会报错 //函数的扩展 ...
- linux下pip的安装
---恢复内容开始--- 1 输入apt-cache search wxpython 如果有返回信息 则输入 sudo apt-get install python-tools 2 否则 1.添加软件 ...
- MySQL5.7运行CPU达百分之400处理方案
用户在使用 MySQL 实例时,会遇到 CPU 使用率过高甚至达到 100% 的情况.本文将介绍造成该状况的常见原因以及解决方法,并通过 CPU 使用率为 100% 的典型场景,来分析引起该状况的原因 ...