Elasticsearch索引增量统计及定时邮件实现
0、需求
随着ELKStack在应用系统中的数据规模的急剧增长,每天千万级别数据量(存储大小:10000000*10k/1024/1024=95.37GB,假设单条数据10kB,实际远大于10KB)的累积成为日常需求。
如何以相对简单的图形化效果展示数据的增量呢?
本文给出思路和实现。
1、问题分解
1.1 ES集群的数据量统计
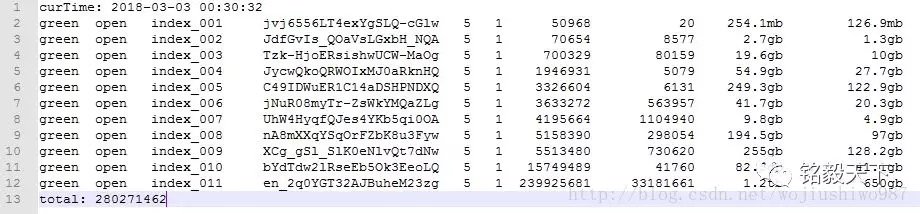
ES自带的命令行统计举例:
curl 'localhost:9200/_cat/indices?v'
1.2 如何实现增量?
简化思路:
1)每天的固定时间,如早晨00:00统计一次当天的数据量,形成日志文件存储如:20180228-00:00.log
2)20180228的增量为:20180229-00:00.log的数据值-20180228-00:00.log的数据量。(下一天-前一天)
1.3 如何实现统计
简化思路:
1)shell脚本获取每天统计的数据量
2)Excel公式简单计算增量
1.4 如何实现定时邮件统计
简化思路:
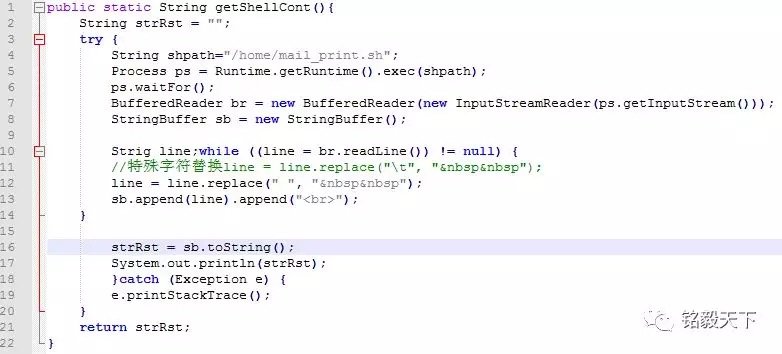
1)java + 邮件程序 + 读取脚本实现。
2)crontab实现定时任务处理。
2、具体实现
2.1 单日数据量统计
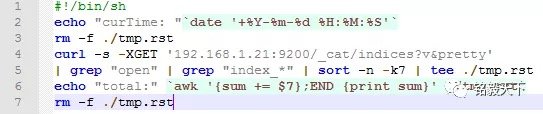
返回结果如下:
2.2 Java读取Shell脚本
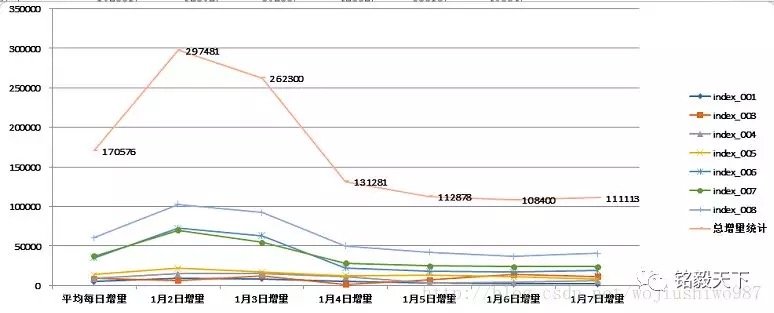
2.3 增量数据统计
步骤1:单日数据统计。 步骤2:增量数据统计。
步骤2:增量数据统计。  步骤1,步骤2数据可以Excel统计得出。
步骤1,步骤2数据可以Excel统计得出。
其中单日数据的拷贝shell脚本如下:

步骤3:Excel生成图表。
3、难点
无
4、小结
通过shell脚本+Excel数据统计,简单实现了数据增量可视化。
通过java+邮件处理+定时任务,实现了数据的定时统计以及定时邮件预警功能。
可以,在此基础上,做更多的扩展应用,比如:
- 1)集群监控状态监控;
- 2)集群堆内存使用监控;
- 3)开发中其他相关物理机器内存、CPU、磁盘读写性能等指标的监控等。
推荐阅读:
为什么选择 Spring 作为 Java 框架?
SpringBoot RocketMQ 整合使用和监控
上篇好文:
使用Arthas 获取Spring ApplicationContext还原问题现场

Elasticsearch索引增量统计及定时邮件实现的更多相关文章
- Elasticsearch 索引的全量/增量更新
Elasticsearch 索引的全量/增量更新 当你的es 索引数据从mysql 全量导入之后,如何根据其他客户端改变索引数据源带来的变动来更新 es 索引数据呢. 首先用 Python 全量生成 ...
- Elasticsearch索引原理
转载 http://blog.csdn.net/endlu/article/details/51720299 最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计 ...
- Elasticsearch索引和查询性能调优的21条建议
Elasticsearch部署建议 1. 选择合理的硬件配置:尽可能使用 SSD Elasticsearch 最大的瓶颈往往是磁盘读写性能,尤其是随机读取性能.使用SSD(PCI-E接口SSD卡/SA ...
- 带你走进神一样的Elasticsearch索引机制
更多精彩内容请看我的个人博客 前言 相比于大多数人熟悉的MySQL数据库的索引,Elasticsearch的索引机制是完全不同于MySQL的B+Tree结构.索引会被压缩放入内存用于加速搜索过程,这一 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- Elasticsearch索引(company)_Centos下CURL增删改
目录 返回目录:http://www.cnblogs.com/hanyinglong/p/5464604.html 1.Elasticsearch索引说明 a. 通过上面几篇博客已经将Elastics ...
- Sybase数据库收集表及其索引的统计信息
更新表及其索引的统计信息: update table statistics 表名 go update index statistics 表名 go 建议此操作在闲时操作.
- sphinx续5-主索引增量索引和实时索引
原文件地址:http://blog.itpub.net/29806344/viewspace-1400942/ 在数据库数据非常庞大的时候,而且实时有新的数据插入,如果我们不更新索引,新的数据就sea ...
- ES3:ElasticSearch 索引
ElasticSearch是文档型数据库,索引(Index)定义了文档的逻辑存储和字段类型,每个索引可以包含多个文档类型,文档类型是文档的集合,文档以索引定义的逻辑存储模型,比如,指定分片和副本的数量 ...
随机推荐
- Windows和linux环境下按文件名和字符串搜索命令
Windows 1.遍历C盘下所有txt 命令:for /r c:\ %i in (*.txt) do @echo %i 注释:for 循环的意思 /r 按照路径搜索 c:\ 路径 %i in ( ...
- python中的内置函数的思维导图
https://mubu.com/doc/taq9-TBNix
- .NET Core 3.0之深入源码理解Kestrel的集成与应用(二)
前言 前一篇文章主要介绍了.NET Core继承Kestrel的目的.运行方式以及相关的使用,接下来将进一步从源码角度探讨.NET Core 3.0中关于Kestrel的其他内容,该部分内容,我们 ...
- C语言学习书籍推荐《C语言入门经典(第4版)》
霍顿 (Ivor Horton) (作者), 杨浩 (译者) <C语言入门经典(第4版)>的目标是使你在C语言程序设计方面由一位初学者成为一位称职的程序员.读者基本不需要具备任何编程知识, ...
- Apache struts2远程命令执行_CVE-2017-9805(S2-052)漏洞复现
Apache struts2远程命令执行_CVE-2017-9805(S2-052)漏洞复现 一.漏洞概述 Apache Struts2的REST插件存在远程代码执行的高危漏洞,Struts2 RES ...
- Dom4J的基本使用
初始化数据 <?xml version="1.0" encoding="UTF-8"?> <RESULT> <VALUE> ...
- 【题解】旅行-C++
Description 某趟列车的最大载客容量为V人,沿途共有n个停靠站,其中始发站为第1站,终点站为第n站.在第1站至第n-1站之 间,共有m个团队申请购票搭乘,若规定:(1)对于某个团队的购票申请 ...
- form 利用BeginCollectionItem提交集合List<T>数据 以及提交的集合中含有集合的数据类型 如List<List<T>> 数据的解决方案
例子: public class IssArgs { public List<IssTabArgs> Tabs { get; set; } } public class IssTabArg ...
- TensorFlow笔记-文件读取
小数量数据读取 这些只用于可以完全加载到内存中的小型数据集: 1,储存在常数中 2,储存在变量中,初始化后,永远不改变它的值 使用常量 training_data = ... training_lab ...
- [leetcode] 80. Remove Duplicates from Sorted Array II (Medium)
排序数组去重题,保留重复两个次数以内的元素,不申请新的空间. 解法一: 因为已经排好序,所以出现重复的话只能是连续着,所以利用个变量存储出现次数,借此判断. Runtime: 20 ms, faste ...