Hive 学习之路(四)—— Hive 常用DDL操作
一、Database
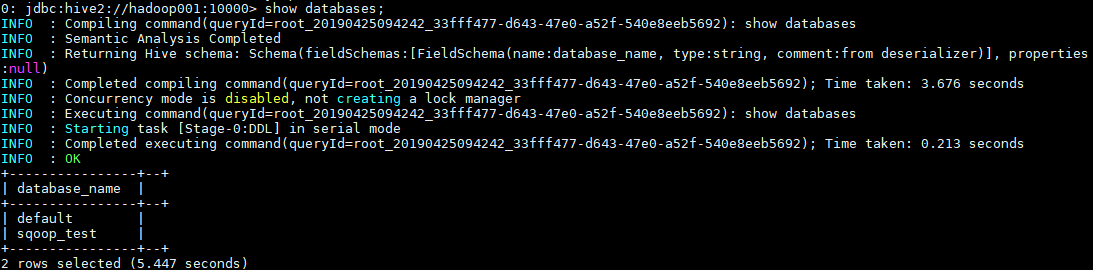
1.1 查看数据列表
show databases;
1.2 使用数据库
USE database_name;
1.3 新建数据库
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name --DATABASE|SCHEMA是等价的
[COMMENT database_comment] --数据库注释
[LOCATION hdfs_path] --存储在HDFS上的位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; --指定额外属性
示例:
CREATE DATABASE IF NOT EXISTS hive_test
COMMENT 'hive database for test'
WITH DBPROPERTIES ('create'='heibaiying');
1.4 查看数据库信息
语法:
DESC DATABASE [EXTENDED] db_name; --EXTENDED 表示是否显示额外属性
示例:
DESC DATABASE EXTENDED hive_test;
1.5 删除数据库
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
- 默认行为是RESTRICT,如果数据库中存在表则删除失败。要想删除库及其中的表,可以使用CASCADE级联删除。
示例:
DROP DATABASE IF EXISTS hive_test CASCADE;
二、创建表
2.1 建表语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --表名
[(col_name data_type [COMMENT col_comment],
... [constraint_specification])] --列名 列数据类型
[COMMENT table_comment] --表描述
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --分区表分区规则
[
CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS
] --分桶表分桶规则
[SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
] --指定倾斜列和值
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
] -- 指定行分隔符、存储文件格式或采用自定义存储格式
[LOCATION hdfs_path] -- 指定表的存储位置
[TBLPROPERTIES (property_name=property_value, ...)] --指定表的属性
[AS select_statement]; --从查询结果创建表
2.2 内部表
CREATE TABLE emp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
2.3 外部表
CREATE EXTERNAL TABLE emp_external(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_external';
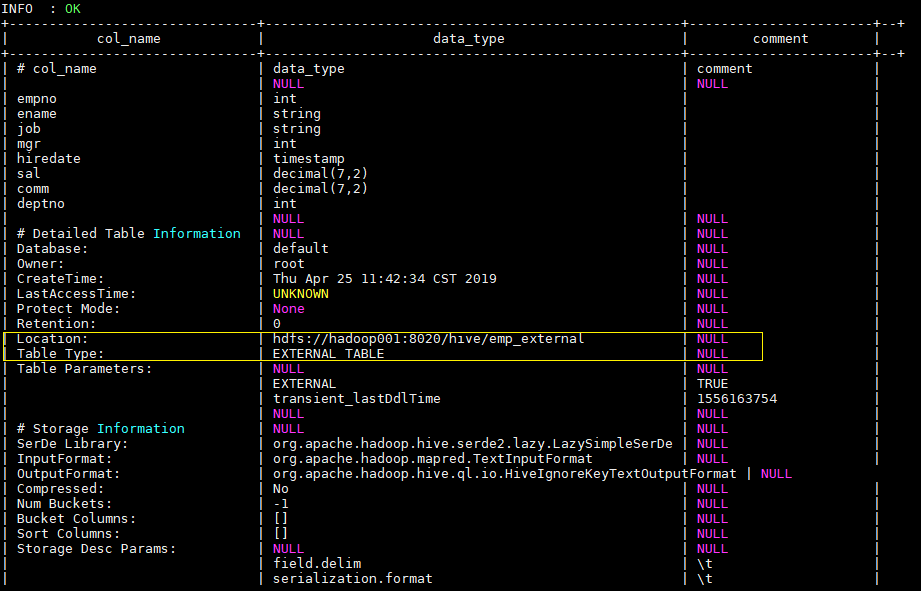
使用 desc format emp_external命令可以查看表的详细信息如下:
2.4 分区表
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_partition';
2.5 分桶表
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照员工编号散列到四个bucket中
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_bucket';
2.6 倾斜表
通过指定一个或者多个列经常出现的值(严重偏斜),Hive会自动将涉及到这些值的数据拆分为单独的文件。在查询时,如果涉及到倾斜值,它就直接从独立文件中获取数据,而不是扫描所有文件,这使得性能得到提升。
CREATE EXTERNAL TABLE emp_skewed(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
SKEWED BY (empno) ON (66,88,100) --指定empno的倾斜值66,88,100
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
LOCATION '/hive/emp_skewed';
2.7 临时表
临时表仅对当前session可见,临时表的数据将存储在用户的暂存目录中,并在会话结束后删除。如果临时表与永久表表名相同,则对该表名的任何引用都将解析为临时表,而不是永久表。临时表还具有以下两个限制:
- 不支持分区列;
- 不支持创建索引。
CREATE TEMPORARY TABLE emp_temp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";
2.8 CTAS创建表
支持从查询语句的结果创建表:
CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20';
2.9 复制表结构
语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --创建表表名
LIKE existing_table_or_view_name --被复制表的表名
[LOCATION hdfs_path]; --存储位置
示例:
CREATE TEMPORARY EXTERNAL TABLE IF NOT EXISTS emp_co LIKE emp
2.10 加载数据到表
加载数据到表中属于DML操作,这里为了方便大家测试,先简单介绍一下加载本地数据到表中:
-- 加载数据到emp表中
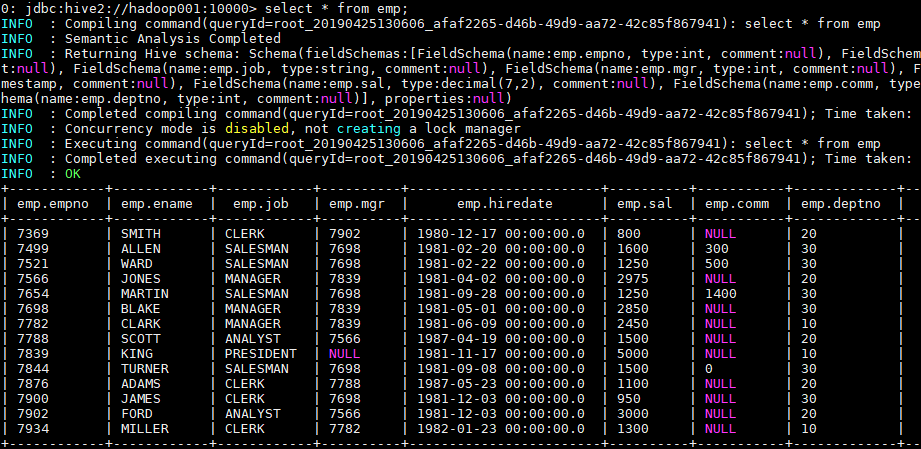
load data local inpath "/usr/file/emp.txt" into table emp;
其中emp.txt的内容如下,你可以直接复制使用,也可以到本仓库的resources目录下载:
7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20
7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 20
7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 30
7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 10
7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 20
7839 KING PRESIDENT 1981-11-17 00:00:00 5000.00 10
7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 20
7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 30
7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 20
7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 10
加载后可查询表中数据:
三、修改表
3.1 重命名表
语法:
ALTER TABLE table_name RENAME TO new_table_name;
示例:
ALTER TABLE emp_temp RENAME TO new_emp; --把emp_temp表重命名为new_emp
3.2 修改列
语法:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type
[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
示例:
-- 修改字段名和类型
ALTER TABLE emp_temp CHANGE empno empno_new INT;
-- 修改字段sal的名称 并将其放置到empno字段后
ALTER TABLE emp_temp CHANGE sal sal_new decimal(7,2) AFTER ename;
-- 为字段增加注释
ALTER TABLE emp_temp CHANGE mgr mgr_new INT COMMENT 'this is column mgr';
3.3 新增列
示例:
ALTER TABLE emp_temp ADD COLUMNS (address STRING COMMENT 'home address');
四、清空表/删除表
4.1 清空表
语法:
-- 清空整个表或表指定分区中的数据
TRUNCATE TABLE table_name [PARTITION (partition_column = partition_col_value, ...)];
- 目前只有内部表才能执行TRUNCATE操作,外部表执行时会抛出异常
Cannot truncate non-managed table XXXX。
示例:
TRUNCATE TABLE emp_mgt_ptn PARTITION (deptno=20);
4.2 删除表
语法:
DROP TABLE [IF EXISTS] table_name [PURGE];
- 内部表:不仅会删除表的元数据,同时会删除HDFS上的数据;
- 外部表:只会删除表的元数据,不会删除HDFS上的数据;
- 删除视图引用的表时,不会给出警告(但视图已经无效了,必须由用户删除或重新创建)。
五、其他命令
5.1 Describe
查看数据库:
DESCRIBE|Desc DATABASE [EXTENDED] db_name; --EXTENDED 是否显示额外属性
查看表:
DESCRIBE|Desc [EXTENDED|FORMATTED] table_name --FORMATTED 以友好的展现方式查看表详情
5.2 Show
1. 查看数据库列表
-- 语法
SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards'];
-- 示例:
SHOW DATABASES like 'hive*';
LIKE子句允许使用正则表达式进行过滤,但是SHOW语句当中的LIKE子句只支持*(通配符)和|(条件或)两个符号。例如employees,emp *,emp * | * ees,所有这些都将匹配名为employees的数据库。
2. 查看表的列表
-- 语法
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
-- 示例
SHOW TABLES IN default;
3. 查看视图列表
SHOW VIEWS [IN/FROM database_name] [LIKE 'pattern_with_wildcards']; --仅支持Hive 2.2.0 +
4. 查看表的分区列表
SHOW PARTITIONS table_name;
5. 查看表/视图的创建语句
SHOW CREATE TABLE ([db_name.]table_name|view_name);
参考资料
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hive 学习之路(四)—— Hive 常用DDL操作的更多相关文章
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Git学习之路(6)- 分支操作
▓▓▓▓▓▓ 大致介绍 几乎所有的版本控制系统都会支持分支操作,分支可以让你在不影响开发主线的情况下,随心所欲的实现你的想法,但是在大多数的版本控制系统中,这个过程的效率是非常低的.就比如我在没有学习 ...
- Hive 学习之路(七)—— Hive 常用DML操作
一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (p ...
- Hive学习之路 (四)Hive的连接3种连接方式
一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~]$ hive SLF4J: Class path contains multiple SLF4J bindi ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路 (十一)Hive的5个面试题
一.求单月访问次数和总访问次数 1.数据说明 数据字段说明 用户名,月份,访问次数 数据格式 A,, A,, B,, A,, B,, A,, A,, A,, B,, B,, A,, A,, B,, B ...
- Hive 学习之路(八)—— Hive 数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件emp.txt和dept.txt可以从本仓库的resources目录下载. 1.1 员工表 -- 建表语句 CREAT ...
- Hive 学习之路(六)—— Hive 视图和索引
一.视图 1.1 简介 Hive 中的视图和RDBMS中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条SELECT语句的结果集.视图是纯粹的逻辑对象,没有关联的存储(Hive 3.0.0引入的 ...
随机推荐
- Java--Vector类
Java Vector 类 Vector类实现了一个动态数组.和ArrayList和相似,但是两者是不同的: Vector是同步访问的. Vector包含了许多传统的方法,这些方法不属于集合框架. V ...
- 阐述php(五岁以下儿童)
注意事项和使用功能
1.函数声明 <?php /** * function 函数名(參数1, 參数2.... ){ * 函数体; * 返回值; * } */ $sum = sum(3, 4); echo $sum; ...
- WPF MVVM模式中,通过命令实现窗体拖动、跳转以及显隐控制
原文:WPF MVVM模式中,通过命令实现窗体拖动.跳转以及显隐控制 在WPF中使用MVVM模式,可以让我们的程序实现界面与功能的分离,方便开发,易于维护.但是,很多初学者会在使用MVVM的过程中遇到 ...
- 相关web 片段记录安全性研究(不时更新)
一.有关html/css, js, php, cgi 的一些认识 当我们浏览器訪问一个网站的静态文件.会把文件内容都下载下来(一般压缩).当然假设遇到外联的css/js,会再发起请求得 到.假设我们右 ...
- 零元学Expression Design 4 - Chapter 4 教你如何自制超炫笔刷
原文:零元学Expression Design 4 - Chapter 4 教你如何自制超炫笔刷 在Chapter 2 有稍微讲过Design内建笔刷的用法,本章将教大家如何自制独一无二的笔刷,并且重 ...
- 微信小程序特殊效果合集
微信小程序的开发并不难,但是有时我们想做出比较炫的效果,可能会一时没有思路或找不到方法.下面就整理了微信小程序的一些特殊效果的案例,均来自网络,供你参考. 1.文字跑马灯效果:http://www.w ...
- MongoDB Shell 经常使用的操作
数组查询 数组查询 MongoDB 中有子文档的概念,一个文档中能方便的嵌入子文档,这与关系性数据库有着明显的不同.在查询时,语法有一些注意点. 样例代码,假如我们的一个集合(tests)中存在标签键 ...
- 疯狂的图形(利用C# + GDI plus模拟杂乱无章的现实场景)
原文:疯狂的图形(利用C# + GDI plus模拟杂乱无章的现实场景) 本文给出了模拟竹叶.长叶草.杂乱石头.天上繁星等关键代码.使用.Net环境下C#语言,GDI+编写. 模拟竹叶 挺像的吧? ...
- WPF特效-粒子动画
原文:WPF特效-粒子动画 WPF实现泡泡龙小游戏效果. /// -Ball to Ball Collision - Detection and Handling /// http:// ...
- python 识别身份证号码
# !/usr/bin/python # -*-coding:utf-8-*- import sys import time time1 = time.time() from PIL import I ...