Hadoop —— 集群环境搭建
一、集群规划
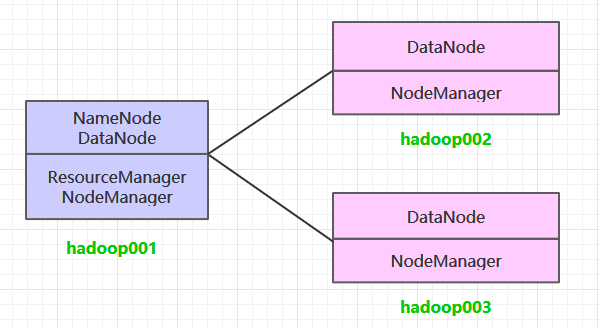
这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务。
二、前置条件
Hadoop的运行依赖JDK,需要预先安装。其安装步骤单独整理至:
三、配置免密登录
3.1 生成密匙
在每台主机上使用ssh-keygen命令生成公钥私钥对:
ssh-keygen
3.2 免密登录
将hadoop001的公钥写到本机和远程机器的~/ .ssh/authorized_key文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003
3.3 验证免密登录
ssh hadoop002
ssh hadoop003
四、集群搭建
3.1 下载并解压
下载Hadoop。这里我下载的是CDH版本Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
编辑profile文件:
# vim /etc/profile
增加如下配置:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置立即生效:
# source /etc/profile
3.3 修改配置
进入${HADOOP_HOME}/etc/hadoop目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
<property>
<!--namenode节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--datanode节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
4. yarn-site.xml
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--指定mapreduce作业运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. slaves
配置所有从属节点的主机名或IP地址,每行一个。所有从属节点上的DataNode服务和NodeManager服务都会被启动。
hadoop001
hadoop002
hadoop003
3.4 分发程序
将Hadoop安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下Hadoop的环境变量。
# 将安装包分发到hadoop002
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/
# 将安装包分发到hadoop003
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/
3.5 初始化
在Hadoop001上执行namenode初始化命令:
hdfs namenode -format
3.6 启动集群
进入到Hadoop001的${HADOOP_HOME}/sbin目录下,启动Hadoop。此时hadoop002和hadoop003上的相关服务也会被启动:
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
3.7 查看集群
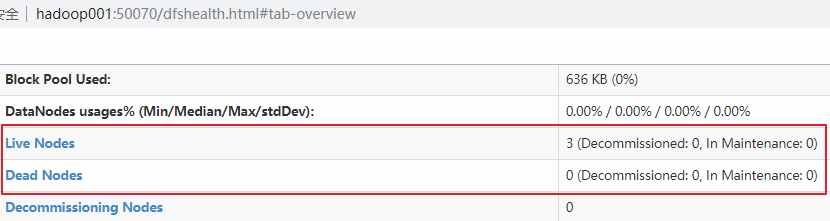
在每台服务器上使用jps命令查看服务进程,或直接进入Web-UI界面进行查看,端口为50070。可以看到此时有三个可用的Datanode:
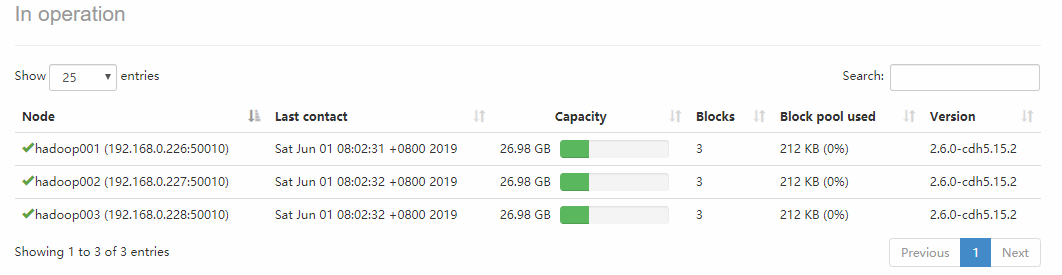
点击Live Nodes进入,可以看到每个DataNode的详细情况:
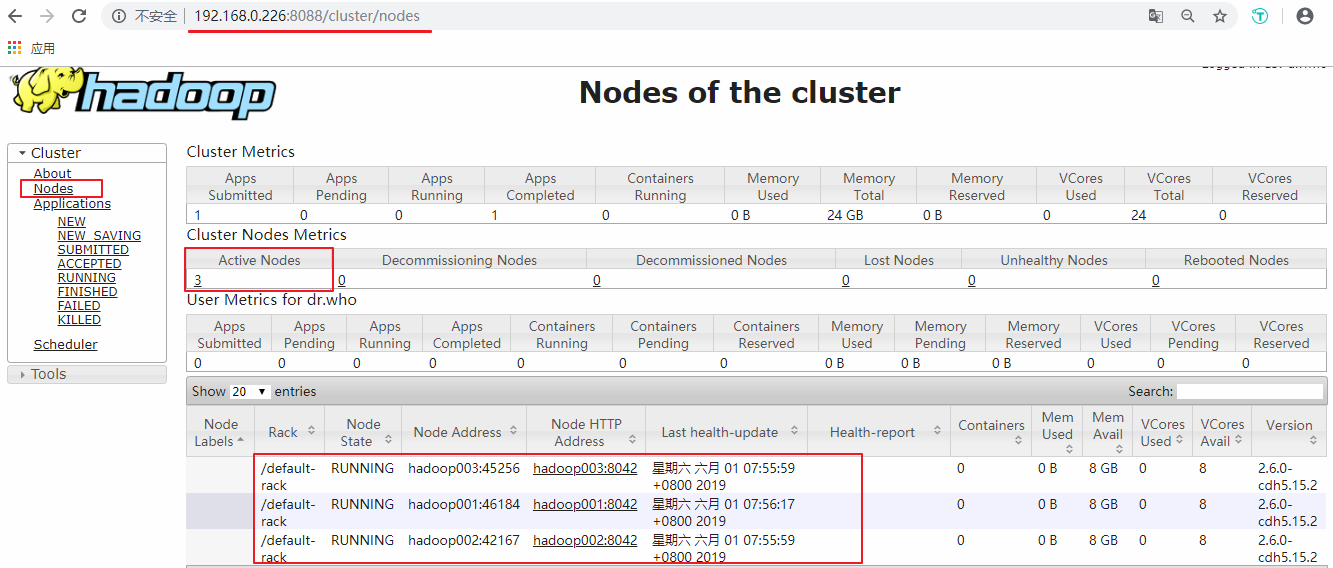
接着可以查看Yarn的情况,端口号为8088 :
五、提交服务到集群
提交作业到集群的方式和单机环境完全一致,这里以提交Hadoop内置的计算Pi的示例程序为例,在任何一个节点上执行都可以,命令如下:
hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop —— 集群环境搭建的更多相关文章
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作. 注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和 ...
- Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Hadoop(4)-Hadoop集群环境搭建
准备工作 开启全部三台虚拟机,确保hadoop100的机器已经配置完成 分发脚本 操作hadoop100 新建一个xsync的脚本文件,将下面的脚本复制进去 vim xsync #这个脚本使用的是rs ...
随机推荐
- python 和为S的两个数字
输入一个递增排序的数组和一个数字S,在数组中查找两个数,是的他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的. 运用到的知识; 1.判断是否是统一类型: if not isinsta ...
- EditText 详细信息(监听事件时,输入改变、透明背景、提示改变文字颜色、密文输入)
1.对EditText输入监视.给EditText 捆绑 addTextChangedListener 监控事件 能够. 2.EditText输入内容.密文显示: android:password=& ...
- 在sqlserver中,使用sql语句更新数据库:生成随机数,更新每一行中的年龄字段
use School --指定数据库 declare @min_id int --声明整数变量@x set @min_id=(select MIN(Id) from Students) --给变量@x ...
- 办ZigBee实验SmartRF Flash Programmer软件界面无法打开
开SmartRF Flash Programmer: 打开任务管理器.在任务管理器里右键点击.将其最大化: 将最大化的界面拖动到屏幕中间: 然后关闭SmartRF Flash Programmer,之 ...
- Android - 小的特点 - 使用最新版本ShareSDK手册分享(分享自己定义的接口)
前太实用Share SDK很快分享,但官员demo快捷共享接口已被设置死,该公司的产品还设计了自己的份额接口,这需要我手动共享. 读了一堆公文,最终写出来,行,废话,进入主题. 之前没实用过Share ...
- C++ string的那些坑,C++ string功能补充(类型互转,分割,合并,瘦身) ,c++ string的内存本质(简单明了的一个测试)
1. size_type find_first_of( const basic_string &str, size_type index = 0 ); 查找在字符串中第一个与str中的某个字符 ...
- Raw-OS备用事件源代码分析
作为分析的内核版本2014-04-15,基于1.05正式版,blogs我们会跟上的内核开发进度的最新版本,如果出现源代码的目光"???"的话.没有深究的部分是理解. Raw-OS官 ...
- Full Stack developer and Fog Computing
尊重开发人员的劳动成果.转载请注明From郝萌主 http://blog.csdn.net/haomengzhu/article/details/40453769 看到这两组词,你是什么感觉? 不知所 ...
- JDK源码阅读——Vector实现
1 继承结构图 Vector同样继承自AbstractList,与ArrayList.LinedList一样,是List的一种实现 2 数据结构 // 与ArrayList一样,也是使用对象数组保存元 ...
- jquery 复选框操作-prop()的使用
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...