7.18 collection time random os sys 序列化 subprocess 等模块
collection模块
namedtuple 具名元组(重要)
应用场景1
# 具名元组
# 想表示坐标点x为1 y为2 z为5的坐标
from collections import namedtuple
# point = namedtuple('坐标',['x','y','z']) # 第二个参数既可以传可迭代对象
point = namedtuple('坐标','x y z') # 也可以传字符串 但是字符串之间以空格隔开
p = point(1,2,5) # 注意元素的个数必须跟namedtuple第二个参数里面的值数量一致
print(p)
print(p.x)
print(p.y)
print(p.z)
>>>
坐标(x=1, y=2, z=5)
1
2
5
from collections import namedtuple
city = namedtuple('天津','location person job')
c = city('剧院','岳云鹏','相声')
print(c)
print(c.location)
print(c.person)
print(c.job)
应用场景2
from collections import namedtuple
card = namedtuple('扑克牌','color number')
# card1 = namedtuple('扑克牌',['color','number'])
A = card('♠','A')
print(A)
print(A.color)
print(A.number)
>>>
扑克牌(color='♠', number='A')
♠
A
队列queue:先进先出(FIFO first in first out)(重要)
import queue
q = queue.Queue() # 生成队列对象
q.put('first') # 往队列中添加值
q.put('second')
q.put('third')
print(q.get()) # 朝队列要值
print(q.get())
print(q.get())
print(q.get()) # 如果队列中的值取完了 程序会在原地等待 直到从队列中拿到值才停止
双端队列deque(重要)
from collections import deque
q = deque(['a','b','c'])
"""
之前学习过的方法
append
appendleft
pop
popleft
"""
q.append(1)
q.appendleft(2)
"""
队列不应该支持任意位置插值
只能在首尾插值(不能插队)
"""
q.insert(2,'哈哈哈') # 特殊点:双端队列可以根据索引在任意位置插值
print(q.pop())
print(q.popleft())
print(q.popleft())
有序字典OrderedDict
使用dict时,key是无序的。在对dict做迭代时,我们无法确定key的顺序。
如果要保持key的顺序,可以用OrderedDict:
normal_d = dict([('a',1),('b',2),('c',3)])
print(normal_d)
from collections import OrderedDict
order_d = OrderedDict([('a',1),('b',2),('c',3)])
order_d1 = OrderedDict()
order_d1['x'] = 1
order_d1['y'] = 2
order_d1['z'] = 3
print(order_d1)
for i in order_d1:
print(i)
# print(order_d1)
# print(order_d)
order_d1 = dict()
order_d1['x'] = 1
order_d1['y'] = 2
order_d1['z'] = 3
print(order_d)
for i in order_d:
print(i)
#OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
# 普通dict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = {}
for value in values:
if value>66:
if my_dict.has_key('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
# defaultdict
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
c = Counter('abcdeabcdabcaba')
print c
输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
time模块
和时间有关系的我们就要用到时间模块。在使用模块之前,应该首先导入这个模块。
#常用方法
1.time.sleep(secs)
(线程)推迟指定的时间运行。单位为秒。
2.time.time()
获取当前时间戳
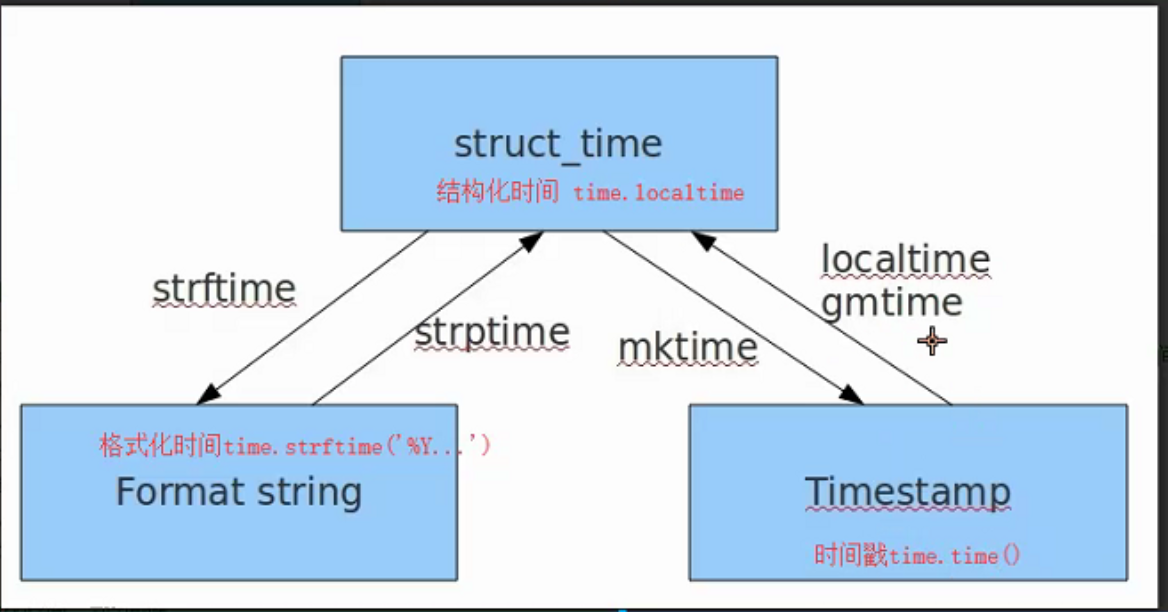
表示时间的三种方式
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1)时间戳(timestamp) :
通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2)格式化的时间字符串(Format String):
‘1999-12-06
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
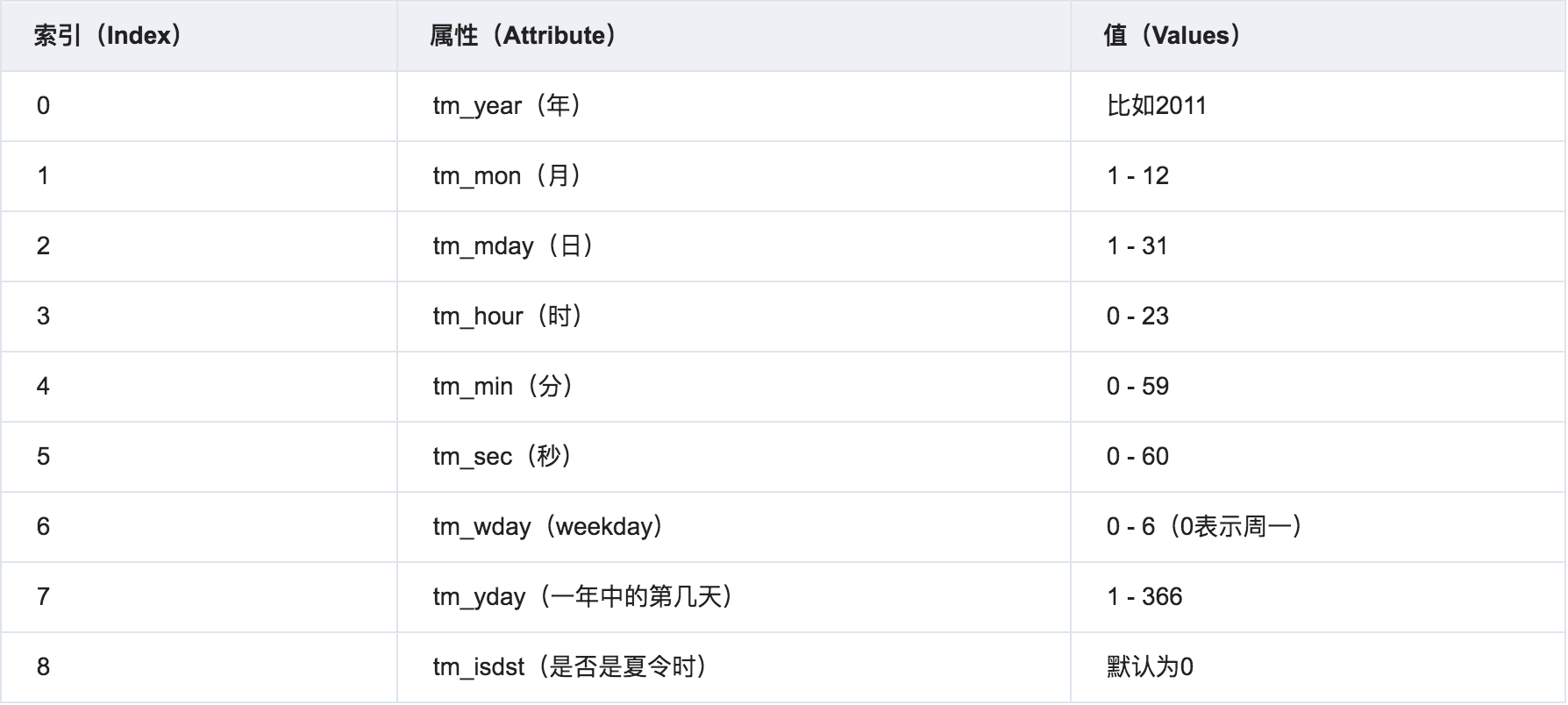
(3)元组(struct_time) :
struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
#导入时间模块
>>>import time
#时间戳
>>>time.time()
1500875844.800804
#时间字符串
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")
'2017-07-24 13-55-04'
#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种格式之间的转换
random模块
# 随机模块
import random
print(random.randint(1,6)) # 随机取一个你提供的整数范围内的数字 包含首尾
print(random.random()) # 随机取0-1之间小数
print(random.choice([1,2,3,4,5,6])) # 摇号 随机从列表中取一个元素
res = [1,2,3,4,5,6]
random.shuffle(res) # 洗牌
print(res)
# 生成随机验证码
"""
大写字母 小写字母 数字
5位数的随机验证码
chr
random.choice
封装成一个函数,用户想生成几位就生成几位
"""
def get_code(n):
code = ''
for i in range(n):
# 先生成随机的大写字母 小写字母 数字
upper_str = chr(random.randint(65,90))
lower_str = chr(random.randint(97,122))
random_int = str(random.randint(0,9))
# 从上面三个中随机选择一个作为随机验证码的某一位
code += random.choice([upper_str,lower_str,random_int])
return code
res = get_code(4)
print(res)
os模块
os模块:跟操作系统打交道的模块
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
sys模块
sys模块:跟python解释器打交道模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
import sys
try:
sys.exit(1)
except SystemExit as e:
print(e)
序列化模块
序列:字符串
序列化:其他数据类型(包括字符串)转换成json格式的字符串的过程
写入文件的数据必须是字符串
基于网络传输的数据必须是二进制
序列化:其他数据类型(包括字符串)转换成json格式的字符串的过程
反序列化:json格式的字符串转成其他数据类型(包括字符串)
json模块(IMPORTANT)
所有的语言都支持json格式
支持的数据类型很少 字符串 列表 字典 整型 浮点型 元组(转成列表) 布尔值 None
pickle模块(IMPORTANT)
只支持python
python所有的数据类型都支持
json实例
import json
d = {"name":"jason"}
print(d)
res = json.dumps(d) # json格式的字符串 对内部的格式有严格的要求 必须是双引号 >>>: '{"name": "jason"}'
print(res,type(res))
res1 = json.loads(res)
print(res1,type(res1)) # json中 内部全是双引号 外部全是单引号
import json
d = {"name":"jason"}
with open('userinfo','w',encoding='utf-8') as f:
json.dump(d,f) # 装字符串并自动写入文件
with open('userinfo','r',encoding='utf-8') as f:
res = json.load(f)
print(res,type(res))
import json
with open('userinfo','w',encoding='utf-8') as f:
json.dump(d,f) # 装字符串并自动写入文件
json.dump(d,f) # 装字符串并自动写入文件
with open('userinfo','r',encoding='utf-8') as f:
res1 = json.load(f) # 不能够多次反序列化
res2 = json.load(f)
print(res1,type(res1))
print(res2,type(res2))
import json
d1 = {'name':'刘德华'}
print(json.dumps(d1,ensure_ascii=False))
pickle实例
# pickle
import pickle
d = {'name':'jason'}
res = pickle.dumps(d) # 将对象直接转成二进制
print(pickle.dumps(d))
res1 = pickle.loads(res)
print(res1,type(res1))
"""
用pickle操作文件的时候 文件的打开模式必须是b模式
"""
with open('userinfo_1','wb') as f:
pickle.dump(d,f)
with open('userinfo_1','rb') as f:
res = pickle.load(f)
print(res,type(res))
subprocess模块
sub :子
process:进程
while True:
cmd = input('cmd>>>:').strip()
import subprocess
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
# print(obj)
print('正确命令返回的结果stdout',obj.stdout.read().decode('gbk'))
print('错误命令返回的提示信息stderr',obj.stderr.read().decode('gbk'))
7.18 collection time random os sys 序列化 subprocess 等模块的更多相关文章
- 模块random+os+sys+json+subprocess
模块random+os+sys+json+subprocess 1. random 模块 (产生一个随机值) import random 1 # 随机小数 2 print(random.rando ...
- collection,random,os,sys,序列化模块
一.collection 模块 python拥有一些内置的数据类型,比如 str,list.tuple.dict.set等 collection模块在这些内置的数据类型的基础上,提供了额外的数据类型: ...
- 2019-7-18 collections,time,random,os,sys,序列化模块(json和pickle)应用
一.collections模块 1.具名元组:namedtuple(生成可以使用名字来访问元素的tuple) 表示坐标点x为1 y为2的坐标 注意:第二个参数可以传可迭代对象,也可以传字符串,但是字 ...
- day19:常用模块(collections,time,random,os,sys)
1,正则复习,re.S,这个在用的最多,re.M多行模式,这个主要改变^和$的行为,每一行都是新串开头,每个回车都是结尾.re.L 在Windows和linux里面对一些特殊字符有不一样的识别,re. ...
- python笔记-1(import导入、time/datetime/random/os/sys模块)
python笔记-6(import导入.time/datetime/random/os/sys模块) 一.了解模块导入的基本知识 此部分此处不展开细说import导入,仅写几个点目前的认知即可.其 ...
- python 常用模块之random,os,sys 模块
python 常用模块random,os,sys 模块 python全栈开发OS模块,Random模块,sys模块 OS模块 os模块是与操作系统交互的一个接口,常见的函数以及用法见一下代码: #OS ...
- Python全栈--7模块--random os sys time datetime hashlib pickle json requests xml
模块分为三种: 自定义模块 内置模块 开源模块 一.安装第三方模块 # python 安装第三方模块 # 加入环境变量 : 右键计算机---属性---高级设置---环境变量---path--分号+py ...
- Python常用模块(time, datetime, random, os, sys, hashlib)
time模块 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运 ...
- 21 模块(collections,time,random,os,sys)
关于模块importfrom xxx import xxx2. Collections1. Counter 计数器2. 栈: 先进后出.队列:先进先出deque:双向队列3. defaultdict ...
随机推荐
- Spring Boot + Elasticsearch 实现索引批量写入
在使用Eleasticsearch进行索引维护的过程中,如果你的应用场景需要频繁的大批量的索引写入,再使用上篇中提到的维护方法的话显然效率是低下的,此时推荐使用bulkIndex来提升效率.批写入数据 ...
- 数据结构-循环队列(Python实现)
今天我们来到了循环队列这一节,之前的文章中,我介绍过了用python自带的列表来实现队列,这是最简单的实现方法. 但是,我们都知道,在列表中删除第一个元素和删除最后一个元素花费的时间代价是不一样的,删 ...
- [原创]SSH Tunnel for UDP
SSH Tunnel for UDP UDP port forwarding is a bit more complicated. We will need to convert the packet ...
- JVM的内存区域
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域, 包含程序计数器.虚拟机栈.本地方法栈.Java堆.方法区(运行时常量池).直接内存等,不同的版本会有所差异 各区 ...
- 洛谷P1690 贪婪的Copy 题解
题目:https://www.luogu.org/problemnew/show/P1690 分析: 这道题就是一道最短路的题目,因为看到数据范围: n≤100n\leq100n≤100 所以考虑使用 ...
- 如何在一个项目中兼容Wepy和Taro?
背景交待 NJ 项目启动初期,团队技术栈主要是基于 Vue,技术选择上就选择了类 Vue 的 wepy.迭代几个版本后 mpvue 出来了,简单调研了下,准备基于 mpvue-simple 开发部分页 ...
- Excel催化剂开源第4波-ClickOnce部署要点之导入数字证书及创建EXCEL信任文件夹
Excel催化刘插件使用Clickonce的部署方式发布插件,以满足用户使用插件过程中,需要对插件进行功能升级时,可以无痛地自动更新推送新版本.但Clickonce部署,对用户环境有较大的要求,前期首 ...
- [PTA] 数据结构与算法题目集 6-7 在一个数组中实现两个堆栈
//如果堆栈已满,Push函数必须输出"Stack Full"并且返回false:如果某堆栈是空的,则Pop函数必须输出"Stack Tag Empty"(其中 ...
- pyqt 主程序运行中处理其他事件(多线程的一种代替方式)
一.实验环境 1.Windows7x64_SP1 2.Anaconda2.5.0 + python2.7(anaconda集成,不需单独安装) 3.pyinstaller3.0 4.通过Anacond ...
- 大型系列课程之-七夕告白之旅vbs篇
也许,世间所有的美好的东西,都是需要仪式感的,遇到了一年一度的七夕节,怎么过这个节日,成了很多心中有爱的人关注的事情,七夕不浪漫,人间不值得,七夕,发源于中国,这个美好的节日,来自动人的神话故事传说牛 ...