【知识库】-数据库_MySQL性能分析之Query Optimizer
简书作者:Sio
文章出处: MySql优化之索引原理与 SQL 优化
Query Optimizer
MySQL Optimizer是一个专门负责优化SELECT 语句的优化器模块,它主要的功能就是通过计算分析系统中收 集的各种统计信息,为客户端请求的Query 给出他认为最优的执行计划,也就是他认为最优的数据检索方式。
MySQL常见瓶颈
- CPU饱和:CPU饱和的时候,一般发生在数据装入内存或从磁盘上读取数据的时候
- IO瓶颈: 磁盘IO瓶颈发生在装入数据远大于内存容量的时候
- 服务器硬件的性能瓶颈
执行计划Explai
Explain概述
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MYSQL是如何处理SQL语句的.我们可以用执行 计划来分析查询语句或者表结构的性能瓶颈
Explain作用
- 查看表的读取顺序
- 查看数据库读取操作的操作类型
- 查看哪些索引有可能被用到
- 查看哪些索引真正被用到
- 查看表之间的引用
- 查看表中有多少行记录被优化器查询
4.3.3语法
- 语法
explain sql语句
各字段解释
- 准备工作
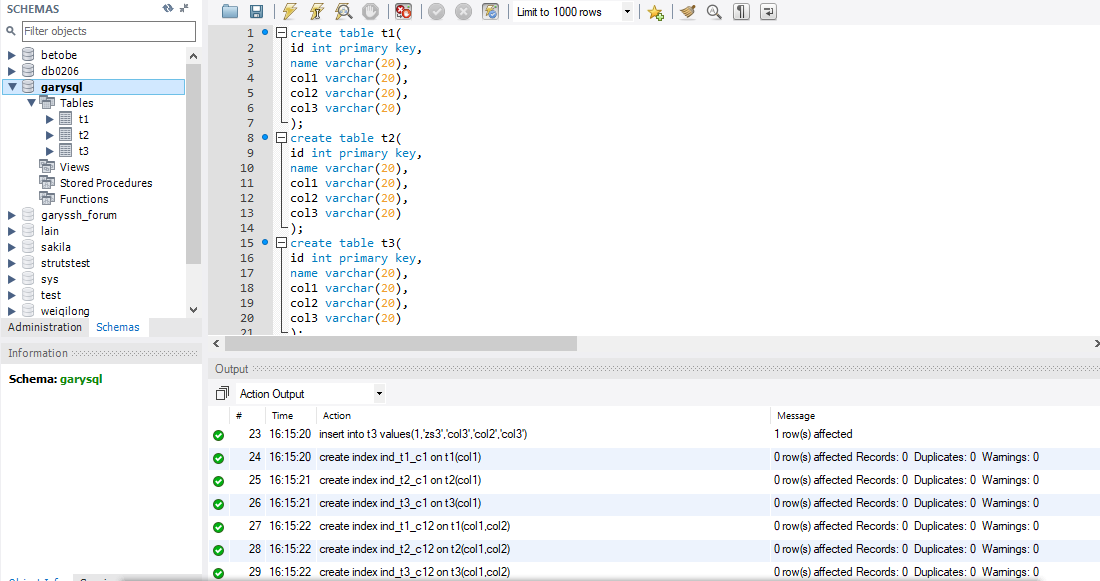
create table t1(
id int primary key,
name varchar(20),
col1 varchar(20),
col2 varchar(20),
col3 varchar(20)
);
create table t2(
id int primary key,
name varchar(20),
col1 varchar(20),
col2 varchar(20),
col3 varchar(20)
);
create table t3(
id int primary key,
name varchar(20),
col1 varchar(20),
col2 varchar(20),
col3 varchar(20)
);
insert into t1 values(1,'zs1','col1','col2','col3');
insert into t2 values(1,'zs2','col2','col2','col3');
insert into t3 values(1,'zs3','col3','col2','col3');
create index ind_t1_c1 on t1(col1);
create index ind_t2_c1 on t2(col1);
create index ind_t3_c1 on t3(col1);
create index ind_t1_c12 on t1(col1,col2);
create index ind_t2_c12 on t2(col1,col2);
create index ind_t3_c12 on t3(col1,col2);
执行explain sql语句后

id
select 查询的序列号,包含一组数字,表示查询中执行Select子句或操作表的顺序
三种情况:
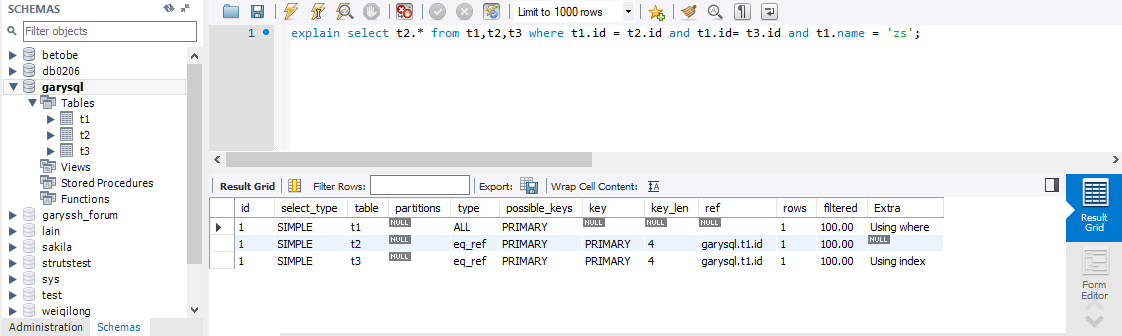
一、id值相同,执行顺序由上而下
explain select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id= t3.id and t1.name = 'zs';
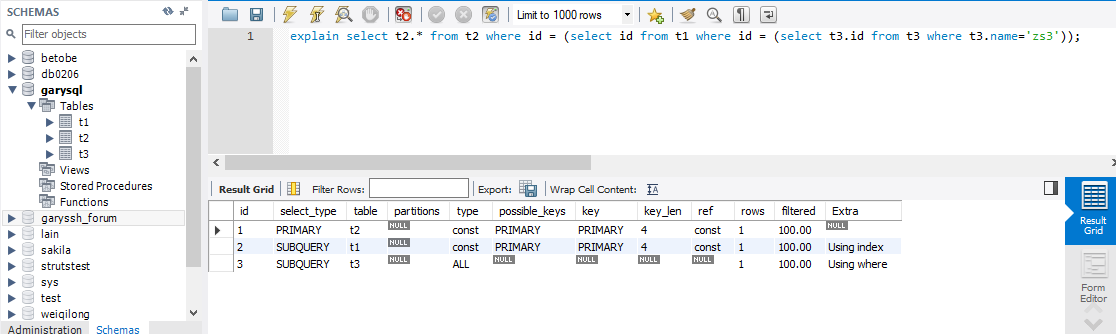
二、id值不同,id值越大优先级越高,越先被执行
explain select t2.* from t2 where id = (select id from t1 where id = (select t3.id from t3 where t3.name='zs3'));
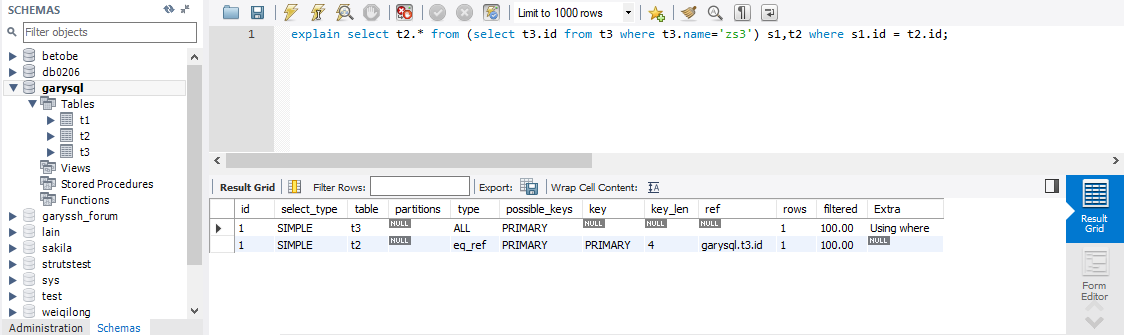
三、id值有相同的也有不同的,如果id相同,从上往下执行,id值越大,优先级越高,越先执行
select_type
查询类型,主要用于区别
- SIMPLE : 简单的select查询,查询中不包含子查询或者UNION
- PRIMARY: 查询中若包含复杂的子查询,最外层的查询则标记为PRIMARY
- SUBQUERY : 在SELECT或者WHERE列表中包含子查询
- DERIVED : 在from列表中包含子查询被标记为DRIVED衍生,MYSQL会递归执行这些子查询,把结果放到临时表 中
- UNION: 若第二个SELECT出现在union之后,则被标记为UNION, 若union包含在from子句的子查询中,外层 select被标记为:derived
- UNION RESULT: 从union表获取结果的select
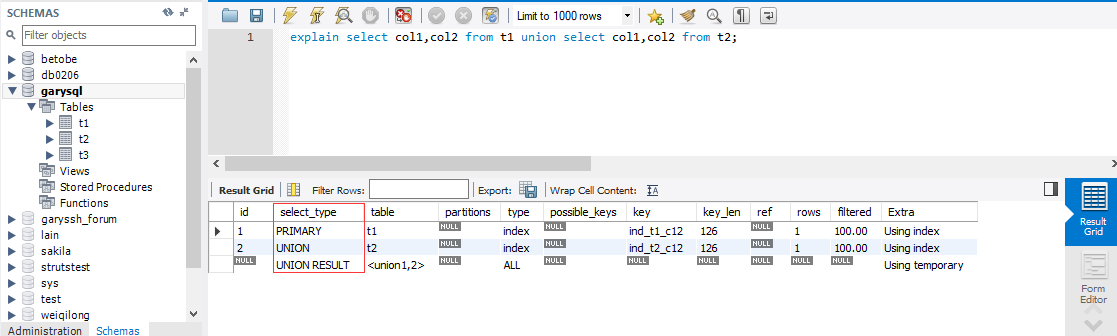
table
显示这一行的数据是和哪张表相关
type
最好到最差依次是: system > const > eq_ref>ref >range > index > all , 最好能优化到range级别或则ref级别
- system: 表中只有一行记录(系统表), 这是const类型的特例, 基本上不会出现
- const: 通过索引一次查询就找到了,const用于比较primary key或者unique索引,因为只匹配一行数据,所以很 快,如将主键置于where列表中,mysql就会将该查询转换为一个常量
explain select * from (select * from t1 where id=1) s1;
- eq_ref: 唯一性索引扫描, 对于每个索引键,表中只有一条记录与之匹配, 常见于主键或者唯一索引扫描
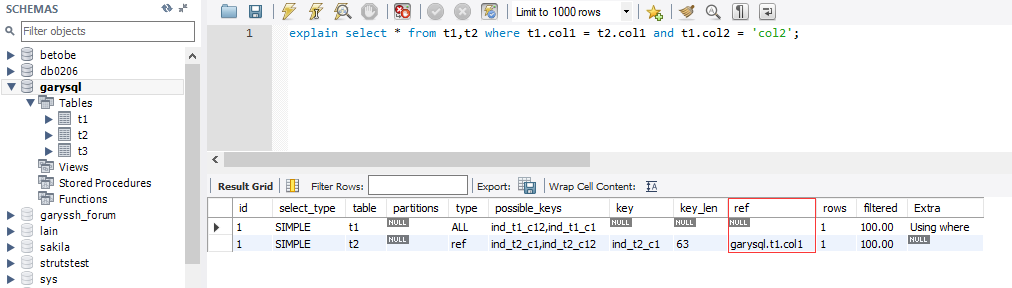
explain select * from t1,t2 where t1.id = t2.id;
- ref : 非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有符合条件的行,然而 它可能返回多个符合条件的行
explain select * from t1 where col1='zs1';
- range : 只检索给定范围的行, 使用一个索引来选择行.key列显示的是真正使用了哪个索引,一般就是在where条 件中使用between,>,<,in 等范围的条件,这种在索引范围内的扫描比全表扫描要好,因为它只在某个范围中扫描, 不需要扫描全部的索引
explain select * from t1 where id between 1 and 10;
- index : 扫描整个索引表, index 和all的区别为index类型只遍历索引树. 这通常比all快,因为索引文件通常比数据 文件小,虽然index和all都是读全表,但是index是从索引中读取,而all是从硬盘中读取数据
explain select id from t1;
- all : full table scan全表扫描 ,将遍历全表以找到匹配的行
explain select * from t1;
- 注意: 开发中,我们得保证查询至少达到range级别,最好能达到ref. 如果百万条数据出现all, 一般情况下就需要考虑使用索引优化了
possible_keys
SQL查询中可能用到的索引,但查询的过程中不一定真正使用
key
查询过程中真正使用的索引,如果为null,则表示没有使用索引
查询中使用了覆盖索引,则该索引仅出现在key列表中
explain select t2.* from t1,t2,t3 where t1.col1 = ' ' and t1.id = t2.id and t1.id= t3.id;
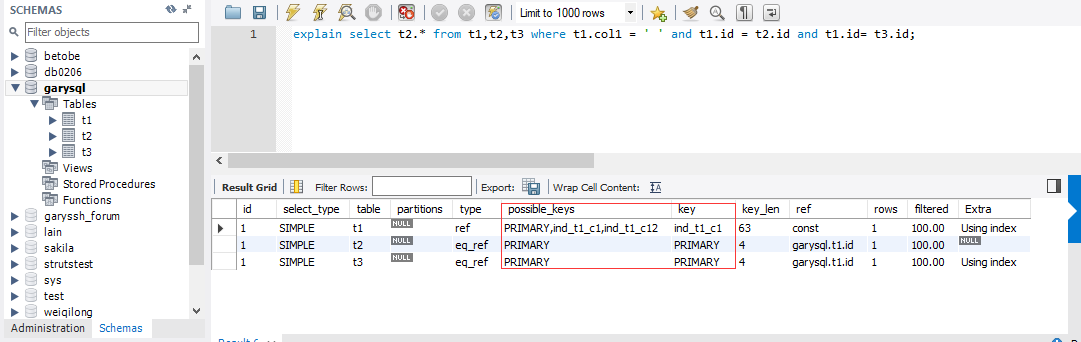
explain select col1 from t1;
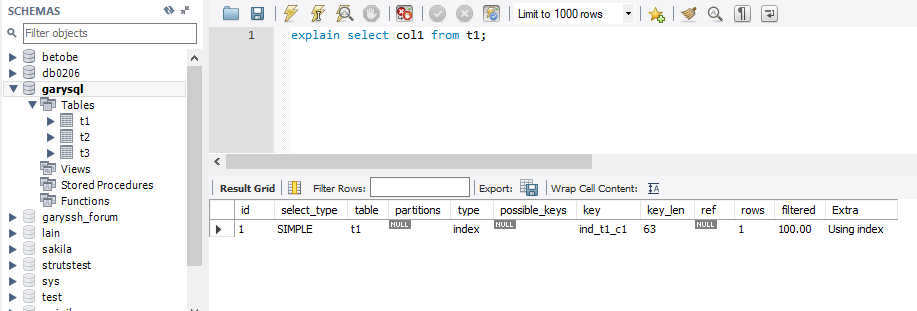
key_len
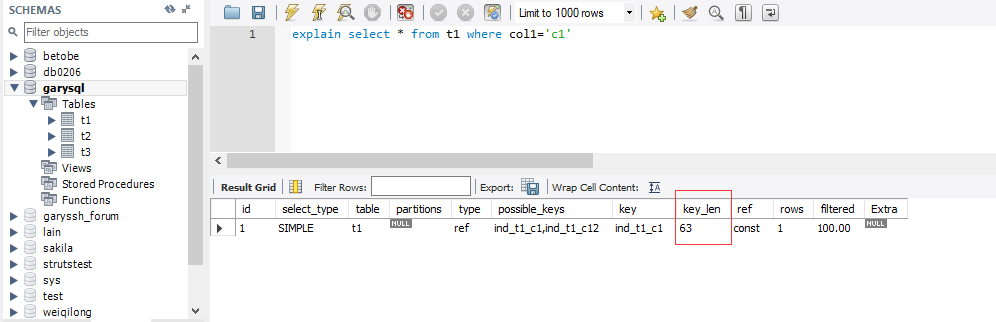
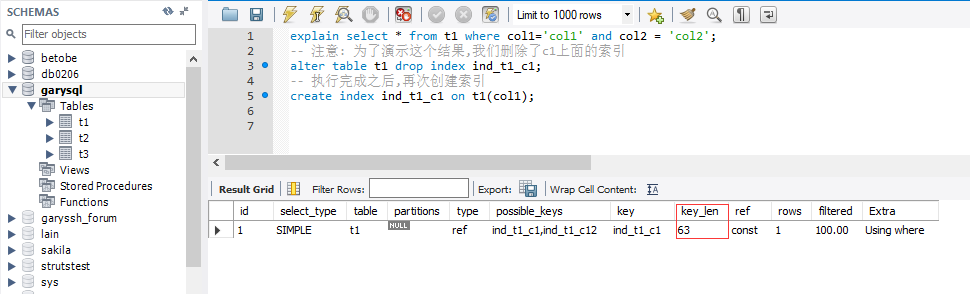
索引中使用的字节数,可通过该列计算查询中使用的索引的长度,在不损失精确度的情况下,长度越短越好, key_len显 示的值为索引字段的最大可能长度,并非实际使用长度, 即key_len是根据表定义计算而得
explain select * from t1 where col1='c1'
explain select * from t1 where col1='col1' and col2 = 'col2';
‐‐ 注意: 为了演示这个结果,我们删除了c1上面的索引
alter table t1 drop index ind_t1_c1;
‐‐ 执行完成之后,再次创建索引
create index ind_t1_c1 on t1(col1);
ref
显示索引的哪一列被使用了,如果可能的话,是一个常数.哪些列或者常量被用于查找索引列上的值
rows
根据表统计信息及索引选用的情况,估算找出所需记录要读取的行数 (有多少行记录被优化器读取) ,越少越好
extra
包含其它一些非常重要的额外信息
- Using filesort : 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,Mysql中无 法利用索引完成的排序操作称为文件排序
explain select col1 from t1 where col1='col1' order by col3;
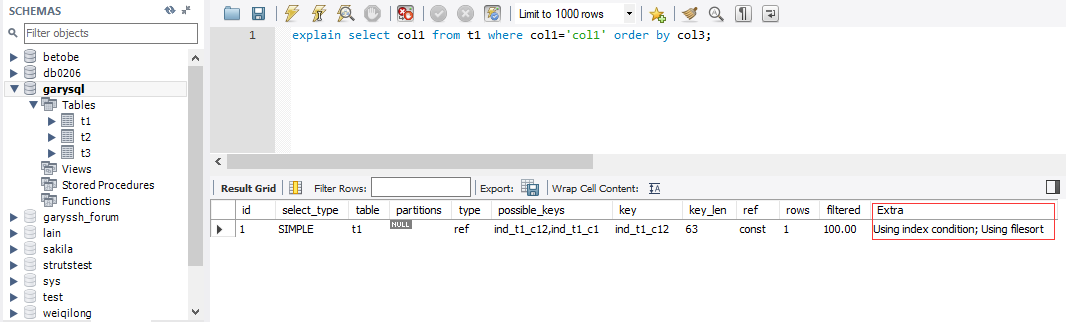
‐‐ 上面这条SQL语句出现了using filesort,但是我们去执行下面这条SQL语句的时候它,又不会出现using filesort
explain select col1 from t1 where col1='col1' order by col2;
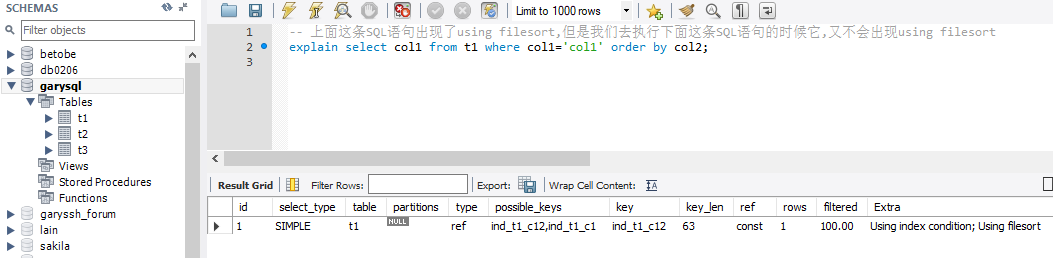
‐‐ 如何优化第一条SQL语句 ?
create index ind_t1_c13 on t1(col1,col3);
explain select col1 from t1 where col1='col1' order by col3;
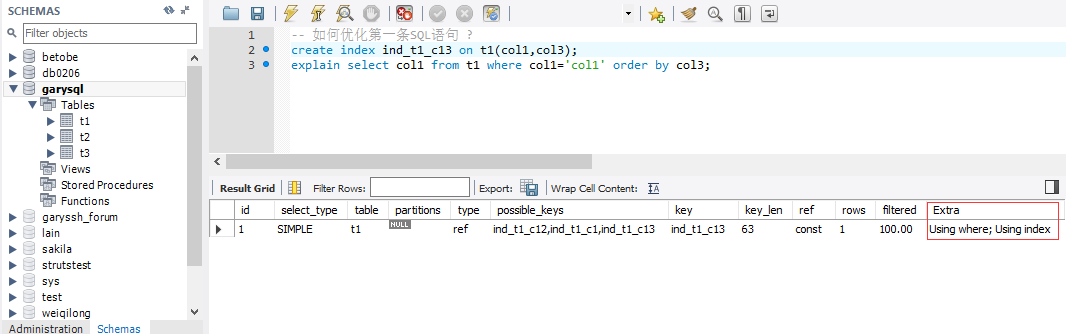
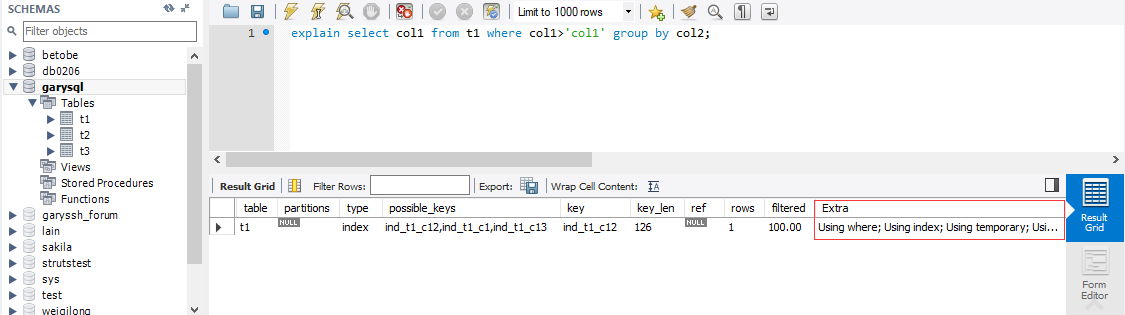
- Using temporary : 使用了临时表保存中间结果,Mysql在对查询结果排序时使用了临时表,常见于order by 和分 组查询group by
explain select col1 from t1 where col1>'col1' group by col2;
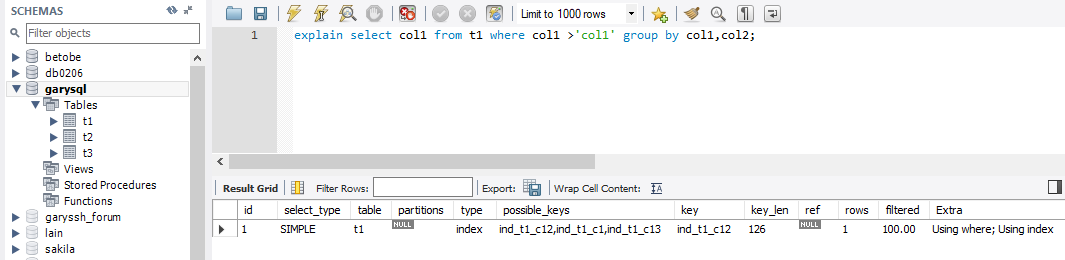
explain select col1 from t1 where col1 >'col1' group by col1,col2;
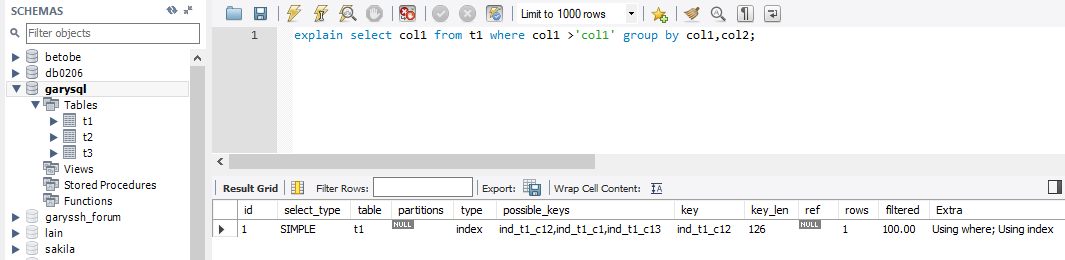
- Using index :
- 查询操作中使用了覆盖索引(查询的列和索引列一致),避免访问了表的数据行,效率好
- 如果同时出现了using where, 表明索引被用来执行索引键值的查找
- 如果没有同时出现using where, 表明索引用来读取数据而非执行查找动作
- 覆盖索引: 查询的列和索引列一致, 换句话说查询的列要被所键的索引覆盖,就是select中数据列只需从索引中就 能读取,不必读取原来的数据行,MySql可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件
explain select col2 from t1 where col1='col1';
explain select col2 from t1;
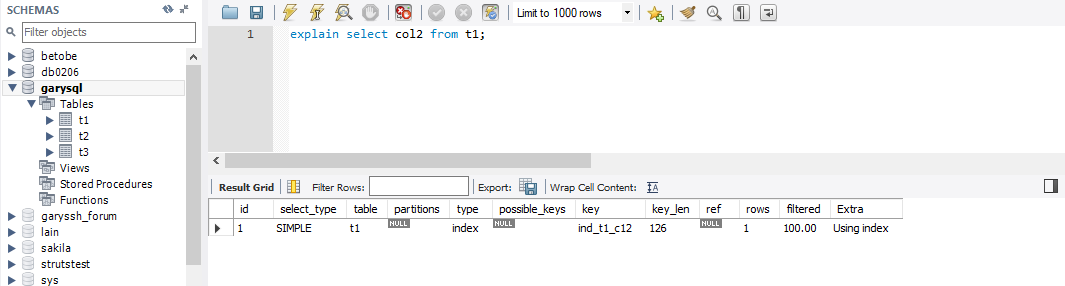
- using where : 表明使用了where条件过滤
- using join buffer : 表明使用了连接缓存, join次数太多了可能会出现
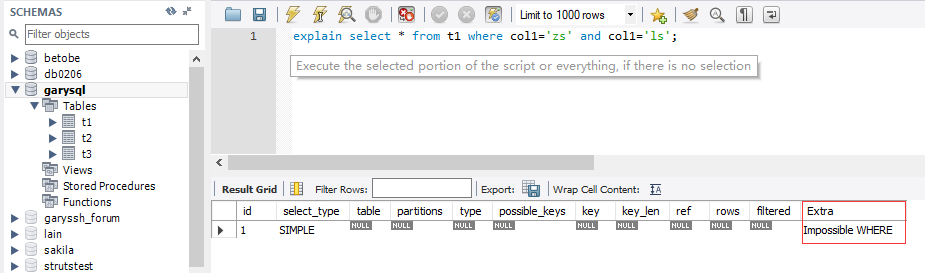
- impossible where : where子句中的值总是false,不能用来获取任何数据
explain select * from t1 where col1='zs' and col1='ls';
- select tables optimized away :
- 在没有group by 子句的情况下, 基于索引优化min/max操作或者对于MyISAM存储引擎优化count(*)操作,不必 等到执行阶段再进行计算,查询执行计划生成阶段即完成优化
- distinct : 优化distinct操作,在找到第一个匹配的数据后即停止查找同样的值的动作
【知识库】-数据库_MySQL性能分析之Query Optimizer的更多相关文章
- MySQL数据库的性能分析 ---图书《软件性能测试分析与调优实践之路》-手稿节选
1 .MySQL数据库的性能监控 1.1.如何查看MySQL数据库的连接数 连接数是指用户已经创建多少个连接,也就是MySQL中通过执行 SHOW PROCESSLIST命令输出结果中运行着的线程 ...
- SQL中利用DMV进行数据库性能分析
相信朋友对SQL Server性能调优相关的知识或多或少都有一些了解.虽然说现在NOSQL相关的技术非常的火热,但是RMDB(关系型数据库)与NOSQL是并存的,并且适用在各种的项目中.在一般的企业级 ...
- 一:MySQL数据库的性能的影响分析及其优化
MySQL数据库的性能的影响分析及其优化 MySQL数据库的性能的影响 一. 服务器的硬件的限制 二. 服务器所使用的操作系统 三. 服务器的所配置的参数设置不同 四. 数据库存储引擎的选择 五. 数 ...
- 如何通过dba_hist_active_sess_history分析数据库历史性能问题
背景在很多情况下,当数据库发生性能问题的时候,我们并没有机会来收集足够的诊断信息,比如system state dump或者hang analyze,甚至问题发生的时候DBA根本不在场.这给我们诊断问 ...
- 【知识库】-数据库_MySQL之高级数据查询:去重复、组合查询、连接查询、虚拟表
简书作者:seay 文章出处: 关系数据库SQL之高级数据查询:去重复.组合查询.连接查询.虚拟表 回顾:[知识库]-数据库_MySQL之基本数据查询:子查询.分组查询.模糊查询 Learn [已经过 ...
- 【知识库】-数据库_MySQL之基本数据查询:子查询、分组查询、模糊查询
简书作者:seay 文章出处: 关系数据库SQL之基本数据查询:子查询.分组查询.模糊查询 回顾:[知识库]-数据库_MySQL常用SQL语句语法大全示例 Learn [已经过测试校验] 一.简单查询 ...
- SQL Server内存性能分析
内存概念: Working Set = Private Bytes + Shared Memory Working Set:某个进程的地址空间中,存放在物理内存的那一部分 Private Bytes: ...
- MySql(八):MySQL性能调优——Query 的优化
一.理解MySQL的Query Optimizer MySQL Optimizer是一个专门负责优化SELECT 语句的优化器模块,它主要的功能就是通过计算分析系统中收集的各种统计信息,为客户端请求的 ...
- Java 性能分析工具 , 第 1 部分: 操作系统工具
引言 性能分析的前提是将应用程序内部的运行状况以及应用运行环境的状况以一种可视化的方式更加直接的展现出来,如何来达到这种可视化的展示呢?我们需要配合使用操作系统中集成的程序监控工具和 Java 中内置 ...
随机推荐
- hdu 4632区间dp 回文字串计数问题
Palindrome subsequence Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65535 K (Java/ ...
- C#中word文档转html
var path = Request.Url.Host + ":" + Request.Url.Port + list[i].AnnexPath; //html保存路径 strin ...
- SQLite数据库_c/s架构的心得
1.使用是Navicat Premium软件, Microsoft Windows版本. 2.选择SQLite并新建数据库: 3.将建好的SQLite数据库,放到新建的项目的debug文件下中, 并在 ...
- HTML5之动画优化(requestAnimationFrame)
定时器setInterval实现的匀速动画为什么不是匀速? window.requestAnimationFrame() 一.定时器setInterval实现的匀速动画为什么不是匀速? 以上提问并非通 ...
- CSS3总结三:文字(text)/字体、文本、文本装饰、多列
Text-Decoration text-shadow text-decoration Font font font-face Text 常用Text属性 Multi-column Multi-col ...
- mtd介绍
转:http://blog.csdn.net/lwj103862095/article/details/21545791 MTD,Memory Technology Device即内存技术设备 字符设 ...
- MySQL 数据类型简介 创建数据表及其字段约束
数据类型介绍 MySQL 数据类型分类 整型 浮点型 字符类型(char与varchar) 日期类型 枚举与集合 具体数据类型见这篇博客 MySQL表操作中的约束 primary key 主键约束 非 ...
- RHEL7中配置本地YUM软件源
1.创建目录,挂载光盘 [root@localhost ~]# mkdir /mnt/iso [root@localhost ~]# mount /dev/sr0 /mnt/iso mount: ...
- cypress 3
https://blog.csdn.net/u014647208/article/details/80525226 https://blog.csdn.net/kulala082/article/de ...
- 《Python基础教程》第三章:使用字符串
find方法可以在一个较长的字符串中查找子字符串.它返回子串所在位置的最左端索引.如果没有找到则返回-1 join方法用来在队列中添加元素,需要添加的队列元素都必须是字符串 >>> ...