特征工程中的IV和WOE详解
1.IV的用途
IV的全称是Information Value,中文意思是信息价值,或者信息量。
我们在用逻辑回归、决策树等模型方法构建分类模型时,经常需要对自变量进行筛选。比如我们有200个候选自变量,通常情况下,不会直接把200个变量直接放到模型中去进行拟合训练,而是会用一些方法,从这200个自变量中挑选一些出来,放进模型,形成入模变量列表。那么我们怎么去挑选入模变量呢?
挑选入模变量过程是个比较复杂的过程,需要考虑的因素很多,比如:变量的预测能力,变量之间的相关性,变量的简单性(容易生成和使用),变量的强壮性(不容易被绕过),变量在业务上的可解释性(被挑战时可以解释的通)等等。但是,其中最主要和最直接的衡量标准是变量的预测能力。
“变量的预测能力”这个说法很笼统,很主观,非量化,在筛选变量的时候我们总不能说:“我觉得这个变量预测能力很强,所以他要进入模型”吧?我们需要一些具体的量化指标来衡量每自变量的预测能力,并根据这些量化指标的大小,来确定哪些变量进入模型。IV就是这样一种指标,他可以用来衡量自变量的预测能力。类似的指标还有信息增益、基尼系数等等。
2.对IV的直观理解
从直观逻辑上大体可以这样理解“用IV去衡量变量预测能力”这件事情:我们假设在一个分类问题中,目标变量的类别有两类:Y1,Y2。对于一个待预测的个体A,要判断A属于Y1还是Y2,我们是需要一定的信息的,假设这个信息总量是I,而这些所需要的信息,就蕴含在所有的自变量C1,C2,C3,……,Cn中,那么,对于其中的一个变量Ci来说,其蕴含的信息越多,那么它对于判断A属于Y1还是Y2的贡献就越大,Ci的信息价值就越大,Ci的IV就越大,它就越应该进入到入模变量列表中。
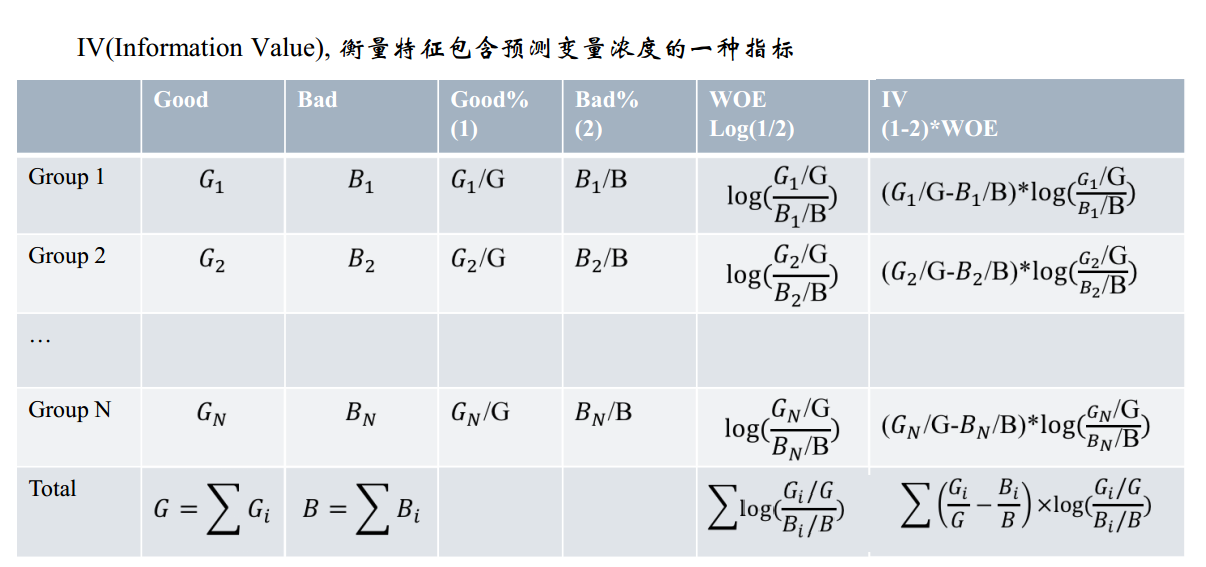
3.IV的计算
前面我们从感性角度和逻辑层面对IV进行了解释和描述,那么回到数学层面,对于一个待评估变量,他的IV值究竟如何计算呢?为了介绍IV的计算方法,我们首先需要认识和理解另一个概念——WOE,因为IV的计算是以WOE为基础的。
3.1WOE
WOE的全称是“Weight of Evidence”,即证据权重。WOE是对原始自变量的一种编码形式。
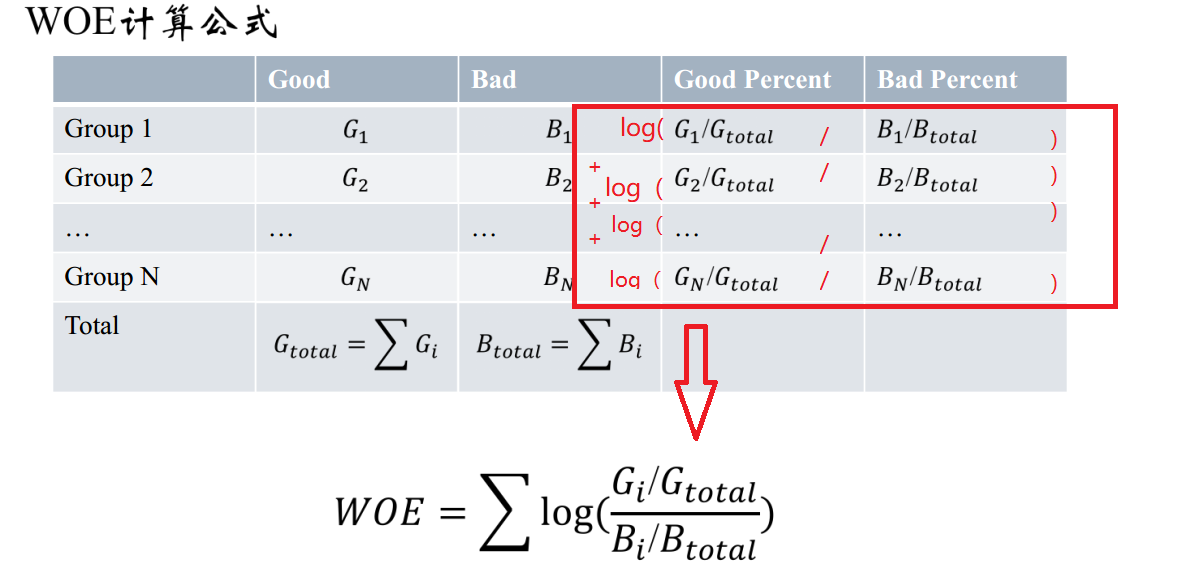
要对一个变量进行WOE编码,需要首先把这个变量进行分组处理(也叫离散化、分箱等等,说的都是一个意思)。分组后,对于第i组,WOE的计算公式如下:
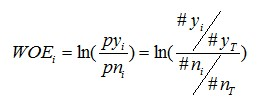
其中,pyi是这个组中响应客户(风险模型中,对应的是违约客户,总之,指的是模型中预测变量取值为“是”或者说1的个体)占所有样本中所有响应客户的比例,pni是这个组中未响应客户占样本中所有未响应客户的比例,#yi是这个组中响应客户的数量,#ni是这个组中未响应客户的数量,#yT是样本中所有响应客户的数量,#nT是样本中所有未响应客户的数量。
从这个公式中我们可以体会到,WOE表示的实际上是“当前分组中响应客户占所有响应客户的比例”和“当前分组中没有响应的客户占所有没有响应的客户的比例”的差异。
对这个公式做一个简单变换,可以得到:
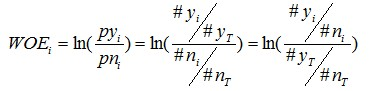
变换以后我们可以看出,WOE也可以这么理解,他表示的是当前这个组中响应的客户和未响应客户的比值,和所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。
这就是WOE编码所表示的意义。

3.2 IV的计算公式
有了前面的介绍,我们可以正式给出IV的计算公式。对于一个分组后的变量,第i 组的WOE前面已经介绍过,是这样计算的:
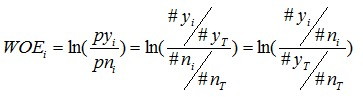
同样,对于分组i,也会有一个对应的IV值,计算公式如下:

有了一个变量各分组的IV值,我们就可以计算整个变量的IV值,方法很简单,就是把各分组的IV相加:

其中,n为变量分组个数。
3.3IV的作用

3.4用实例介绍IV的计算和使用
下面我们通过一个实例来讲解一下IV的使用方式。
3.4.1 实例
假设我们需要构建一个预测模型,这个模型是为了预测公司的客户集合中的每个客户对于我们的某项营销活动是否能够响应,或者说我们要预测的是客户对我们的这项营销活动响应的可能性有多大。假设我们已经从公司客户列表中随机抽取了100000个客户进行了营销活动测试,收集了这些客户的响应结果,作为我们的建模数据集,其中响应的客户有10000个。另外假设我们也已经提取到了这些客户的一些变量,作为我们模型的候选变量集,这些变量包括以下这些(实际情况中,我们拥有的变量可能比这些多得多,这里列出的变量仅仅是为了说明我们的问题):
- 最近一个月是否有购买;
- 最近一次购买金额;
- 最近一笔购买的商品类别;
- 是否是公司VIP客户;
假设,我们已经对这些变量进行了离散化,统计的结果如下面几张表所示。
(1) 最近一个月是否有过购买:

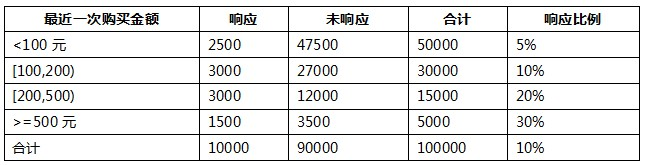
(2) 最近一次购买金额:
(3) 最近一笔购买的商品类别:

(4) 是否是公司VIP客户:

3.4.2 计算WOE和IV
我们以其中的一个变量“最近一次购买金额”变量为例:
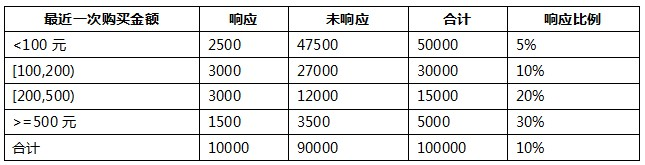

我们把这个变量离散化为了4个分段:<100元,[100,200),[200,500),>=500元。首先,根据WOE计算公式,这四个分段的WOE分别为:

插播一段,从上面的计算结果中我们可以看一下WOE的基本特点:
1)当前分组中,响应的比例越大,WOE值越大;
2)当前分组WOE的正负,由当前分组响应和未响应的比例,与样本整体响应和未响应的比例的大小关系决定,当前分组的比例小于样本整体比例时,WOE为负,当前分组的比例大于整体比例时,WOE为正,当前分组的比例和整体比例相等时,WOE为0。
3)WOE的取值范围是全体实数。
我们进一步理解一下WOE,会发现,WOE其实描述了变量当前这个分组,对判断个体是否会响应(或者说属于哪个类)所起到影响方向和大小,当WOE为正时,变量当前取值对判断个体是否会响应起到的正向的影响,当WOE为负时,起到了负向影响。而WOE值的大小,则是这个影响的大小的体现。
计算完WOE,我们分别计算四个分组的IV值:
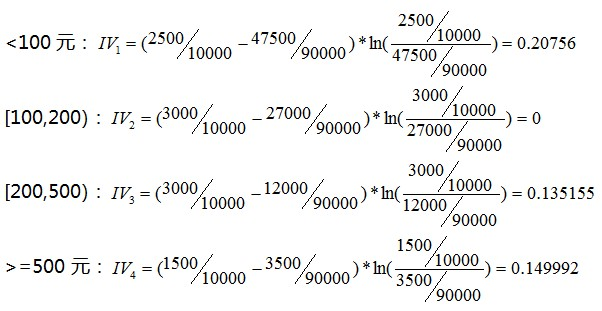
从上面IV的计算结果我们可以看出IV的以下特点:
- 对于变量的一个分组,这个分组的响应和未响应的比例与样本整体响应和未响应的比例相差越大,IV值越大,否则,IV值越小;
- 极端情况下,当前分组的响应和未响应的比例和样本整体的响应和未响应的比例相等时,IV值为0;
- IV值的取值范围是[0,+∞),且,当当前分组中只包含响应客户或者未响应客户时,IV = +∞。
OK,再次回到正题。最后,我们计算变量总IV值:
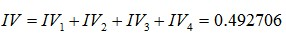
3.4.3 IV值的比较和变量预测能力的排序
我们已经计算了四个变量中其中一个的WOE和IV值。另外三个的计算过程我们不再详细的说明,直接给出IV结果。
- 最近一个月是否有过购买:0.250224725
- 最近一笔购买的商品类别:0.615275563
- 是否是公司VIP客户:1.56550367
前面我们已经计算过,最近一次购买金额的IV为0.49270645
这四个变量IV排序结果是这样的:是否是公司VIP客户 > 最近一笔购买的商品类别 > 最近一次购买金额 > 最近一个月是否有过购买。我们发现“是否是公司VIP客户”是预测能力最高的变量,“最近一个月是否有过购买”是预测能力最低的变量。如果我们需要在这四个变量中去挑选变量,就可以根据IV从高到低去挑选了。
4.关于IV和WOE的进一步思考
4.1 为什么用IV而不是直接用WOE?
从上面的内容来看,变量各分组的WOE和IV都隐含着这个分组对目标变量的预测能力这样的意义。那我们为什么不直接用WOE相加或者绝对值相加作为衡量一个变量整体预测能力的指标呢?
并且,从计算公式来看,对于变量的一个分组,IV是WOE乘以这个分组响应占比和未响应占比的差。而一个变量的IV等于各分组IV的和。如果愿意,我们同样也能用WOE构造出一个这样的一个和出来,我们只需要把变量各个分组的WOE和取绝对值再相加,即(取绝对值是因为WOE可正可负,如果不取绝对值,则会把变量的区分度通过正负抵消的方式抵消掉):

那么我们为什么不直接用这个WOE绝对值的加和来衡量一个变量整体预测能力的好坏,而是要用WOE处理后的IV呢。
我们这里给出两个原因。IV和WOE的差别在于IV在WOE基础上乘以的那个
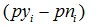
我们暂且用pyn来代表这个值。
第一个原因,当我们衡量一个变量的预测能力时,我们所使用的指标值不应该是负数,否则,说一个变量的预测能力的指标是-2.3,听起来很别扭。从这个角度讲,乘以pyn这个系数,保证了变量每个分组的结果都是非负数,你可以验证一下,当一个分组的WOE是正数时,pyn也是正数,当一个分组的WOE是负数时,pyn也是负数,而当一个分组的WOE=0时,pyn也是0。
当然,上面的原因不是最主要的,因为其实我们上面提到的
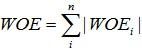
这个指标也可以完全避免负数的出现。
更主要的原因,也就是第二个原因是,乘以pyn后,体现出了变量当前分组中个体的数量占整体个体数量的比例,对变量预测能力的影响。怎么理解这句话呢?我们还是举个例子。
假设我们上面所说的营销响应模型中,还有一个变量A,其取值只有两个:0,1,数据如下:

我们从上表可以看出,当变量A取值1时,其响应比例达到了90%,非常的高,但是我们能否说变量A的预测能力非常强呢?不能。为什么呢?原因就在于,A取1时,响应比例虽然很高,但这个分组的客户数太少了,占的比例太低了。虽然,如果一个客户在A这个变量上取1,那他有90%的响应可能性,但是一个客户变量A取1的可能性本身就非常的低。所以,对于样本整体来说,变量的预测能力并没有那么强。我们分别看一下变量各分组和整体的WOE,IV。

从这个表我们可以看到,变量取1时,响应比达到90%,对应的WOE很高,但对应的IV却很低,原因就在于IV在WOE的前面乘以了一个系数,而这个系数很好的考虑了这个分组中样本占整体样本的比例,比例越低,这个分组对变量整体预测能力的贡献越低。相反,如果直接用WOE的绝对值加和,会得到一个很高的指标,这是不合理的。
4.2 IV的极端情况以及处理方式
IV依赖WOE,并且IV是一个很好的衡量自变量对目标变量影响程度的指标。但是,使用过程中应该注意一个问题:变量的任何分组中,不应该出现响应数=0或非响应数=0的情况。
原因很简单,当变量一个分组中,响应数=0时,
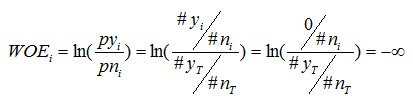
此时对应的IVi为+∞。
而当变量一个分组中,没有响应的数量 = 0时,

此时的IVi为+∞。
IVi无论等于负无穷还是正无穷,都是没有意义的。
由上述问题我们可以看到,使用IV其实有一个缺点,就是不能自动处理变量的分组中出现响应比例为0或100%的情况。那么,遇到响应比例为0或者100%的情况,我们应该怎么做呢?建议如下:
(1)如果可能,直接把这个分组做成一个规则,作为模型的前置条件或补充条件;
(2)重新对变量进行离散化或分组,使每个分组的响应比例都不为0且不为100%,尤其是当一个分组个体数很小时(比如小于100个),强烈建议这样做,因为本身把一个分组个体数弄得很小就不是太合理。
(3)如果上面两种方法都无法使用,建议人工把该分组的响应数和非响应的数量进行一定的调整。如果响应数原本为0,可以人工调整响应数为1,如果非响应数原本为0,可以人工调整非响应数为1.
5. IV和WOE的实战
https://www.jianshu.com/p/b1b1344bd99f
https://www.jianshu.com/p/f931a4df202c
特征工程中的IV和WOE详解的更多相关文章
- 数据挖掘模型中的IV和WOE详解
IV: 某个特征中 某个小分组的 响应比例与未响应比例之差 乘以 响应比例与未响应比例的比值取对数 数据挖掘模型中的IV和WOE详解 http://blog.csdn.net/kevin7658/ar ...
- 转载:数据挖掘模型中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选自变 ...
- 评分卡模型中的IV和WOE详解
1.IV的用途 IV的全称是Information Value,中文意思是信息价值,或者信息量. 我们在用逻辑回归.决策树等模型方法构建分类模型时,经常需要对自变量进行筛选.比如我们有200个候选 ...
- HBase在特征工程中的应用
前言HBase是一款分布式的NoSQL DB,可以轻松扩展存储和读写能力. 主要特性有: 按某精确的key获取对应的value(Get) 通过前缀匹配一段相邻的数据(Scan) 多版本 动态列 服务端 ...
- 前端后台以及游戏中使用Google Protocol Buffer详解
前端后台以及游戏中使用Google Protocol Buffer详解 0.什么是protoBuf protoBuf是一种灵活高效的独立于语言平台的结构化数据表示方法,与XML相比,protoBuf更 ...
- [ 转载 ] Java开发中的23种设计模式详解(转)
Java开发中的23种设计模式详解(转) 设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类 ...
- Linux中/proc目录下文件详解
转载于:http://blog.chinaunix.net/uid-10449864-id-2956854.html Linux中/proc目录下文件详解(一)/proc文件系统下的多种文件提供的系统 ...
- JQuery在循环中绑定事件的问题详解
JQuery在循环中绑定事件的问题详解 有个页面上需要N个DOM,每个DOM里面的元素ID都要以数字结尾,比如说 ? 1 2 3 <input type="text" nam ...
- C#中的Linq to Xml详解
这篇文章主要介绍了C#中的Linq to Xml详解,本文给出转换步骤以及大量实例,讲解了生成xml.查询并修改xml.监听xml事件.处理xml流等内容,需要的朋友可以参考下 一.生成Xml 为了能 ...
随机推荐
- linux内核开源代码地址下载
https://www.kernel.org/pub/linux/kernel/v2.6/
- [转帖] ./demoCA/newcerts: No such file or directory openssl 生成证书时问题的解决.
接上面一篇blog 发现openssl 生成server.crt 时有问题. 找了一个网站处理了一下: http://blog.sina.com.cn/s/blog_49f8dc400100tznt. ...
- vue中关于checkbox数据绑定v-model指令说明
vue.js为开发者提供了很多便利的指令,其中v-model用于表单的数据绑定很常见, 下面是最常见的例子: <div id='myApp'> <input type="c ...
- ARST第二周打卡
Algorithm : 做一个 leetcode 的算法题 题目:一个无序数组里有99个不重复正整数,范围从1到100,唯独缺少一个整数.如何找出这个缺失的整数? int FindOneMissNum ...
- crontab中的%
crontab中的%是换行的意思,在使用时需要使用\做转义. ----------------- 在用crontab执行一段定时任务时,想要把数据输出到一个日期命名的文件中 * * * * * cd ...
- Python开发之JavaScript
JavaScript是一门编程语言,浏览器内置了JavaScript语言的解释器,所以在浏览器上按照JavaScript语言的规则编写相应代码之,浏览器可以解释并做出相应的处理. 一.如何编写 1.J ...
- X86逆向10:学会使用硬件断点
本节课我们将学习硬件断点的使用技巧,硬件断点是由硬件提供给我们的一组寄存器,我们可以对这些硬件寄存器设置相应的值,然后让硬件帮我们断在需要下断点的地址上面,这就是硬件断点,硬件断点依赖于寄存器,这些寄 ...
- 解决radiobutton在gridview中无法单选的一种方法
最近在项目中有个单选gridview中某一项的需求,使用radiobutton后发现,虽然最终选择出来的是一项,但是在页面上却可以选择多项,经过查看生成的html代码,发现生成的radio的name属 ...
- Autofac通过配置的方式
autofac是比较简单易用的IOC容器.下面我们展示如何通过json配置文件,来进行控制反转. 需要用到以下程序集.可以通过nugget分别安装 Microsoft.Extensions.Confi ...
- 使用EF Core 连接远程oracle 不需要安装oracle客户端方法
连接字符串: Data Source=(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=IP地址(PORT=1521))(CONNECT_DATA=(SERVICE_ ...