python学习之路入门篇
本文是up学习python过程中遇到的一些问题及总结归纳,本小节是入门篇。
python基本语法
循环、分支不多赘述。
模块:一个.py文件就是一个模块。
文件和异常
| 模式 | 含义解释 |
| “r” | 读模式 |
| "w" | 写模式(写之前会截断之前的内容) |
| "x" | 写入,如果文件已经存在会产生异常 |
| "a" | 追加,将内容写入到已有文件的末尾 |
| "b" | 二进制模式 |
| "t" | 文本模式(默认) |
| "+" | 更新(既可以读又可以写) |
读文件---read (try ~ except 捕获异常)
def main():
f = None
try:
f = open('致橡树.txt', 'r', encoding='utf-8')
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!')
finally:
if f:
f.close() if __name__ == '__main__':
main()
上面,最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到(甚至是调用了sys模块的exit函数退出Python环境,finally块都会被执行,因为exit函数实质上是引发了SystemExit异常),因此我们通常把finally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。如果不愿意在finally代码块中关闭文件对象释放资源,也可以使用上下文语法,通过with关键字指定文件对象的上下文环境并在离开上下文环境时自动释放文件资源,代码如下:
def main():
try:
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read())
except FileNotFoundError:
print('无法打开指定的文件!')
except LookupError:
print('指定了未知的编码!')
except UnicodeDecodeError:
print('读取文件时解码错误!') if __name__ == '__main__':
main()
逐行读文件---for in/readline
import time
def main():
# 一次性读取整个文件内容
with open('致橡树.txt', 'r', encoding='utf-8') as f:
print(f.read()) # 通过for-in循环逐行读取
with open('致橡树.txt', mode='r') as f:
for line in f:
print(line, end='')
time.sleep(0.5)
print() # 读取文件按行读取到列表中
with open('致橡树.txt') as f:
lines = f.readlines()
print(lines) if __name__ == '__main__':
main()
写文件
from math import sqrt def is_prime(n):
"""判断素数的函数"""
assert n > 0
for factor in range(2, int(sqrt(n)) + 1):
if n % factor == 0:
return False
return True if n != 1 else False def main():
filenames = ('a.txt', 'b.txt', 'c.txt')
fs_list = []
try:
for filename in filenames:
fs_list.append(open(filename, 'w', encoding='utf-8'))
'''
(1-99之间的素数保存在a.txt中,100-999之间的素数保存在b.txt中,1000-9999之间的素数保存在c.txt中)。
'''
for number in range(1, 10000):
if is_prime(number):
if number < 100:
fs_list[0].write(str(number) + '\n')
elif number < 1000:
fs_list[1].write(str(number) + '\n')
else:
fs_list[2].write(str(number) + '\n')
except IOError as ex:
print(ex)
print('写文件时发生错误!')
finally:
for fs in fs_list:
fs.close()
print('操作完成!') if __name__ == '__main__':
main()
读写二进制文件
def main():
try:
with open('guido.jpg', 'rb') as fs1:
data = fs1.read()
print(type(data)) # <class 'bytes'>
with open('吉多.jpg', 'wb') as fs2:
fs2.write(data)
except FileNotFoundError as e:
print('指定的文件无法打开.')
except IOError as e:
print('读写文件时出现错误.')
print('程序执行结束.') if __name__ == '__main__':
main()
读写json文件
把一个列表或者一个字典中的数据保存到文件中又该怎么做呢?当然是将数据以JSON格式进行保存。JSON是“JavaScript Object Notation”的缩写,它本来是JavaScript语言中创建对象的一种字面量语法,现在已经被广泛的应用于跨平台跨语言的数据交换,原因很简单,因为JSON也是纯文本,任何系统任何编程语言处理纯文本都是没有问题的。目前JSON基本上已经取代了XML作为异构系统间交换数据的事实标准。下面是一个JSON的简单例子。
{
"name": "路飞",
"age": 38,
"qq": 957658,
"friends": ["索隆", "山治"],
"cars": [
{"brand": "BYD", "max_speed": 180},
{"brand": "Audi", "max_speed": 280},
{"brand": "Benz", "max_speed": 320}
]
}
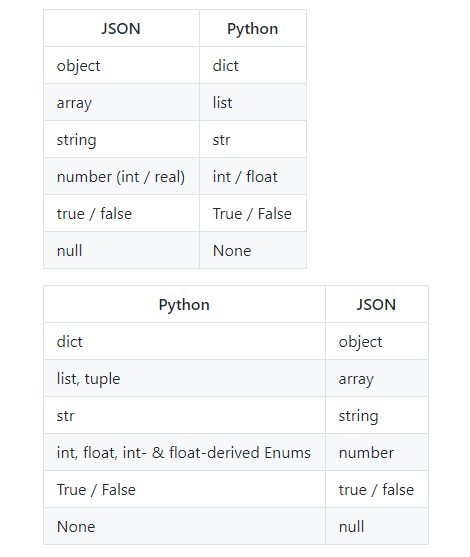
JSON跟Python中的字典其实是一样,对应关系如下面两张表所示。
#使用Python中的json模块就可以将字典或列表以JSON格式保存到文件中 import json def main():
mydict = {
'name': '路飞',
'age': 38,
'qq': 957658,
'friends': ['索隆', '山治'],
'cars': [
{'brand': 'BYD', 'max_speed': 180},
{'brand': 'Audi', 'max_speed': 280},
{'brand': 'Benz', 'max_speed': 320}
]
}
try:
with open('data.json', 'w', encoding='utf-8') as fs:
json.dump(mydict, fs)
except IOError as e:
print(e)
print('保存数据完成!') if __name__ == '__main__':
main()
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中dumps- 将Python对象处理成JSON格式的字符串load- 将文件中的JSON数据反序列化成对象loads- 将字符串的内容反序列化成Python对象
这里出现了两个概念,一个叫序列化,一个叫反序列化。自由的百科全书维基百科上对这两个概念是这样解释的:“序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换为可以存储或传输的形式,这样在需要的时候能够恢复到原先的状态,而且通过序列化的数据重新获取字节时,可以利用这些字节来产生原始对象的副本(拷贝)。与这个过程相反的动作,即从一系列字节中提取数据结构的操作,就是反序列化(deserialization)”。
目前绝大多数网络数据服务(或称之为网络API)都是基于HTTP协议提供JSON格式的数据,关于HTTP协议的相关知识,可以看看阮一峰老师的《HTTP协议入门》,如果想了解国内的网络数据服务,可以看看聚合数据和阿凡达数据等网站,国外的可以看看{API}Search网站。下面的例子演示了如何使用requests模块(封装得足够好的第三方网络访问模块)访问网络API获取国内新闻,如何通过json模块解析JSON数据并显示新闻标题,这个例子使用了天行数据提供的国内新闻数据接口,其中的APIKey需要自己到该网站申请。
import requests
import json def main():
resp = requests.get('http://api.tianapi.com/guonei/?key=APIKey&num=10')
data_model = json.loads(resp.text)
for news in data_model['newslist']:
print(news['title']) if __name__ == '__main__':
main()
字符串和常用数据结构
字符串
str1 = 'hello, world!'
# 通过len函数计算字符串的长度
print(len(str1)) #
# 获得字符串首字母大写的拷贝
print(str1.capitalize()) # Hello, world!
# 获得字符串变大写后的拷贝
print(str1.upper()) # HELLO, WORLD!
# 从字符串中查找子串所在位置
print(str1.find('or')) #
print(str1.find('shit')) # -1
# 与find类似但找不到子串时会引发异常
# print(str1.index('or'))
# print(str1.index('shit'))
# 检查字符串是否以指定的字符串开头
print(str1.startswith('He')) # False
print(str1.startswith('hel')) # True
# 检查字符串是否以指定的字符串结尾
print(str1.endswith('!')) # True
# 将字符串以指定的宽度居中并在两侧填充指定的字符
print(str1.center(50, '*'))
# 将字符串以指定的宽度靠右放置左侧填充指定的字符
print(str1.rjust(50, ' '))
str2 = 'abc123456'
# 从字符串中取出指定位置的字符(下标运算)
print(str2[2]) # c
# 字符串切片(从指定的开始索引到指定的结束索引)
print(str2[2:5]) # c12
print(str2[2:]) # c123456
print(str2[2::2]) # c246
print(str2[::2]) # ac246
print(str2[::-1]) # 654321cba
print(str2[-3:-1]) #
# 检查字符串是否由数字构成
print(str2.isdigit()) # False
# 检查字符串是否以字母构成
print(str2.isalpha()) # False
# 检查字符串是否以数字和字母构成
print(str2.isalnum()) # True
str3 = ' jackfrued@126.com '
print(str3)
# 获得字符串修剪左右两侧空格的拷贝
print(str3.strip())
列表
#列表定义
list1 = [1, 3, 5, 7, 100]
list2 = ['hello'] * 5 # 计算列表长度(元素个数)
print(len(list1)) # 下标(索引)运算
print(list1[0]) # 添加元素
list1.append(200)
list1.insert(1, 400)
list1 += [1000, 2000] #删除列表
list1.remove(3)
if 1234 in list1:
list1.remove(1234)
del list1[0] # 清空列表元素
list1.clear() #列表也可以做切片操作,通过切片操作我们可以实现对列表的复制或者将列表中的一部分#取出来创建出新的列表
def main():
fruits = ['grape', 'apple', 'strawberry', 'waxberry']
fruits += ['pitaya', 'pear', 'mango']
# 循环遍历列表元素
for fruit in fruits:
print(fruit.title(), end=' ')
print()
# 列表切片
fruits2 = fruits[1:4]
print(fruits2)
# fruit3 = fruits # 没有复制列表只创建了新的引用
# 可以通过完整切片操作来复制列表
fruits3 = fruits[:]
print(fruits3)
fruits4 = fruits[-3:-1]
print(fruits4)
# 可以通过反向切片操作来获得倒转后的列表的拷贝
fruits5 = fruits[::-1]
print(fruits5) if __name__ == '__main__':
main() #下面的代码实现了对列表的排序操作
def main():
list1 = ['orange', 'apple', 'zoo', 'internationalization', 'blueberry']
list2 = sorted(list1)
# sorted函数返回列表排序后的拷贝不会修改传入的列表
# 函数的设计就应该像sorted函数一样尽可能不产生副作用
list3 = sorted(list1, reverse=True)
# 通过key关键字参数指定根据字符串长度进行排序而不是默认的字母表顺序
list4 = sorted(list1, key=len)
print(list1)
print(list2)
print(list3)
print(list4)
# 给列表对象发出排序消息直接在列表对象上进行排序
list1.sort(reverse=True)
print(list1) if __name__ == '__main__':
main() #使用列表的生成式语法来创建列表
import sys def main():
f = [x for x in range(1, 10)]
print(f)
f = [x + y for x in 'ABCDE' for y in '']
print(f)
# 用列表的生成表达式语法创建列表容器
# 用这种语法创建列表之后元素已经准备就绪所以需要耗费较多的内存空间
f = [x ** 2 for x in range(1, 1000)]
print(sys.getsizeof(f)) # 查看对象占用内存的字节数
print(f)
# 请注意下面的代码创建的不是一个列表而是一个生成器对象
# 通过生成器可以获取到数据但它不占用额外的空间存储数据
# 每次需要数据的时候就通过内部的运算得到数据(需要花费额外的时间)
f = (x ** 2 for x in range(1, 1000))
print(sys.getsizeof(f)) # 相比生成式生成器不占用存储数据的空间
print(f)
for val in f:
print(val) if __name__ == '__main__':
main()
元组
# 定义元组
t = ('骆昊', 38, True, '四川成都')
print(t)
# 获取元组中的元素
print(t[0])
print(t[3])
# 遍历元组中的值
for member in t:
print(member)
# 重新给元组赋值
# t[0] = '王大锤' # TypeError
# 变量t重新引用了新的元组原来的元组将被垃圾回收
t = ('王大锤', 20, True, '云南昆明')
print(t)
# 将元组转换成列表
person = list(t)
print(person)
# 列表是可以修改它的元素的
person[0] = '李小龙'
person[1] = 25
print(person)
# 将列表转换成元组
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
集合
def main():
set1 = {1, 2, 3, 3, 3, 2}
print(set1)
print('Length =', len(set1))
set2 = set(range(1, 10))
print(set2)
set1.add(4)
set1.add(5)
set2.update([11, 12])
print(set1)
print(set2)
set2.discard(5)
# remove的元素如果不存在会引发KeyError
if 4 in set2:
set2.remove(4)
print(set2)
# 遍历集合容器
for elem in set2:
print(elem ** 2, end=' ')
print()
# 将元组转换成集合
set3 = set((1, 2, 3, 3, 2, 1))
print(set3.pop())
print(set3)
# 集合的交集、并集、差集、对称差运算
print(set1 & set2)
# print(set1.intersection(set2))
print(set1 | set2)
# print(set1.union(set2))
print(set1 - set2)
# print(set1.difference(set2))
print(set1 ^ set2)
# print(set1.symmetric_difference(set2))
# 判断子集和超集
print(set2 <= set1)
# print(set2.issubset(set1))
print(set3 <= set1)
# print(set3.issubset(set1))
print(set1 >= set2)
# print(set1.issuperset(set2))
print(set1 >= set3)
# print(set1.issuperset(set3)) if __name__ == '__main__':
main()
字典
def main():
scores = {'骆昊': 95, '白元芳': 78, '狄仁杰': 82}
# 通过键可以获取字典中对应的值
print(scores['骆昊'])
print(scores['狄仁杰'])
# 对字典进行遍历(遍历的其实是键再通过键取对应的值)
for elem in scores:
print('%s\t--->\t%d' % (elem, scores[elem]))
# 更新字典中的元素
scores['白元芳'] = 65
scores['诸葛王朗'] = 71
scores.update(冷面=67, 方启鹤=85)
print(scores)
if '武则天' in scores:
print(scores['武则天'])
print(scores.get('武则天'))
# get方法也是通过键获取对应的值但是可以设置默认值
print(scores.get('武则天', 60))
# 删除字典中的元素
print(scores.popitem())
print(scores.popitem())
print(scores.pop('骆昊', 100))
# 清空字典
scores.clear()
print(scores) if __name__ == '__main__':
main()
函数和过程
装饰器
定义:本质就是函数,(装饰其他函数)就是为其他函数添加附加功能。
原则:1、不能修改被装饰函数的源代码
2、不能修改被装饰函数的调用方式
基础:1、函数即“变量”
2、高阶函数
3、嵌套函数
高阶函数+嵌套函数=》装饰器
迭代器
类和对象
类的定义
class Student(object):
# __init__是一个特殊方法用于在创建对象时进行初始化操作
# 通过这个方法我们可以为学生对象绑定name和age两个属性
def __init__(self, name, age):
self.name = name
self.age = age
def study(self, course_name):
print('%s正在学习%s.' % (self.name, course_name))
# PEP 8要求标识符的名字用全小写多个单词用下划线连接
# 但是部分程序员和公司更倾向于使用驼峰命名法(驼峰标识)
def watch_movie(self):
if self.age < 18:
print('%s只能观看《熊出没》.' % self.name)
else:
print('%s正在观看岛国爱情大电影.' % self.name)
创建和使用类的对象
def main():
# 创建学生对象并指定姓名和年龄
stu1 = Student('骆昊', 38)
# 给对象发study消息
stu1.study('Python程序设计')
# 给对象发watch_av消息
stu1.watch_movie()
stu2 = Student('王大锤', 15)
stu2.study('思想品德')
stu2.watch_movie() if __name__ == '__main__':
main()
访问权限
在Python中,属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头。但是,Python并没有从语法上严格保证私有属性或方法的私密性,它只是给私有的属性和方法换了一个名字来“妨碍”对它们的访问,事实上如果你知道更换名字的规则仍然可以访问到它们。之所以这样设定,可以用这样一句名言加以解释,就是“We are all consenting adults here”。因为绝大多数程序员都认为开放比封闭要好,而且程序员要自己为自己的行为负责。
图形用户界面和游戏开发
进程与线程
网络编程
文档处理
陆续补充中。。。。。。
python学习之路入门篇的更多相关文章
- STM32学习之路入门篇之指令集及cortex——m3的存储系统
STM32学习之路入门篇之指令集及cortex——m3的存储系统 一.汇编语言基础 一).汇编语言:基本语法 1.汇编指令最典型的书写模式: 标号 操作码 操作数1, 操作数2,... ...
- python学习之路基础篇(第七篇)
一.模块 configparser configparser用于处理特定格式的文件,其本质是利用open来对文件进行操作 [section1] # 节点 k1 = v1 # 值 k2:v2 # 值 [ ...
- python学习之路基础篇(第五篇)
前四天课程回顾 1.python简介 2.python基本数据类型 类: int:整型 | str:字符串 | list:列表 |tuple:元组 |dict:字典 | set:集合 对象: li = ...
- python学习之路基础篇(第四篇)
一.课程内容回顾 1.python基础 2.基本数据类型 (str|list|dict|tuple) 3.将字符串“老男人”转换成utf-8 s = "老男人" ret = by ...
- python学习之路基础篇(三)
博客参考:http://www.cnblogs.com/wupeiqi/articles/4943406.html http://www.cnblogs.com/luotianshuai/p/4949 ...
- Python学习之路基础篇--01Python的基本常识
1 计算机基础 首先认识什么是CPU(Central Processing Unit),即中央处理器,相当于人类的大脑.内存,临时储存数据,断电即消失.硬盘,可以长久的储存数据,有固态硬盘,机械硬盘之 ...
- python学习之路——基础篇(3)模块(续)
re正则表达式.shutil.ConfigParser.xml 一.re 正则元字符和语法: 语法 说明 表达式 完全匹配字符 字符 一般字符 匹配自身 abc abc . 匹配除换行符"\ ...
- Python学习之路——基础篇(1)字符串格式化
字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存. 百分号方式 ...
- python学习之路基础篇(第八篇)
一.作业(对象的封装) 要点分析 1.封装,对象中嵌套对象 2.pickle,load,切记,一定要先导入相关的类二.上节内容回顾和补充 面向对象基本知识: 1.类和对象的关系 2.三大特性: 封装 ...
随机推荐
- LC 406. Queue Reconstruction by Height
Suppose you have a random list of people standing in a queue. Each person is described by a pair of ...
- LC 465. Optimal Account Balancing 【lock,hard】
A group of friends went on holiday and sometimes lent each other money. For example, Alice paid for ...
- 爬虫 selenium + phantomjs / chrome
selenium 模块 Web自动化测试工具, 可运行在浏览器,根据指定命令操作浏览器, 必须与第三方浏览器结合使用 安装 sudo pip3 install selenium phantomjs 浏 ...
- java源码-LinkedHashMap类设计
LinkedHashMap 继承于 hashMap LinkedHashMap .Entry 继承 HashMap.Node 继承 Map.Entry类 LinkedHashMap .Entry 该E ...
- gl-transitions 【68个转场效果图】
angular.glsl Bounce.glsl BowTieHorizontal.glsl BowTieVertical.glsl burn.glsl ButterflyWaveScrawler.g ...
- SAS数据挖掘实战篇【四】
SAS数据挖掘实战篇[四] 今天主要是介绍一下SAS的聚类案例,希望大家都动手做一遍,很多问题只有在亲自动手的过程中才会有发现有收获有心得. 1 聚类分析介绍 1.1 基本概念 聚类就是一种寻找数据之 ...
- HCL试验七
在静态路由的基础上实行动态路由 对每台路由器的直连ip编写动态路由命令 路由器1 rip 1 network 192.168.1.0 network 10.1.1.0 undo summary und ...
- linux系统查看当前正在运行的服务
--查看当前服务器所有服务 service --status-all -- 查看当前所有正在运行的服务 service --status-all | grep running --查看指定服务运行状态 ...
- 2019年icpc区域赛银川站总结
目录 一.前言 二.10月19日热身赛 三.10月20日正式赛 四.结果 一.前言 比赛前我们队有ccpc厦门和icpc银川的名额,然而这两个地区的时间正好撞了,考虑到银川更容易拿奖,加上我们ACM协 ...
- VirtualBox下Centos6.8网络配置
win10环境下,VirtualBox和Centos6.8已经按照完毕,下面配置Centos6.8网络. 1.设置VirtualBox为桥接模式,具体的有三种联网方法,我们参考http://www.c ...