利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数。
1)一元(unary)ufunc,如,sqrt和exp函数
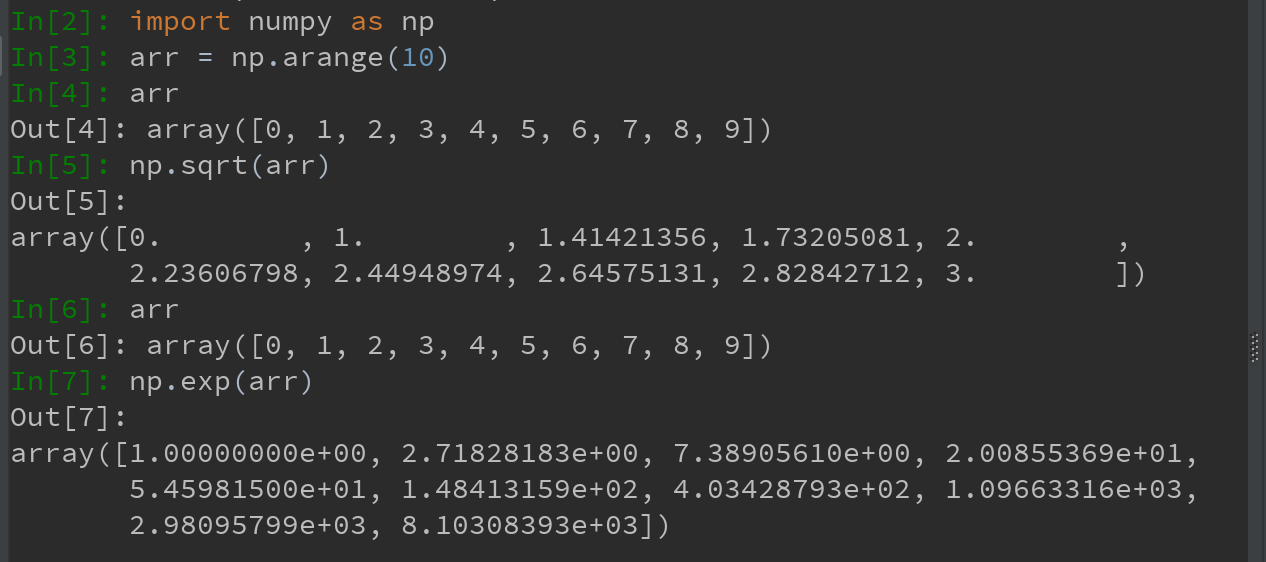
2)二元(unary)ufunc,可接受2个数组,并返回一个结果数组,如add或maximum函数
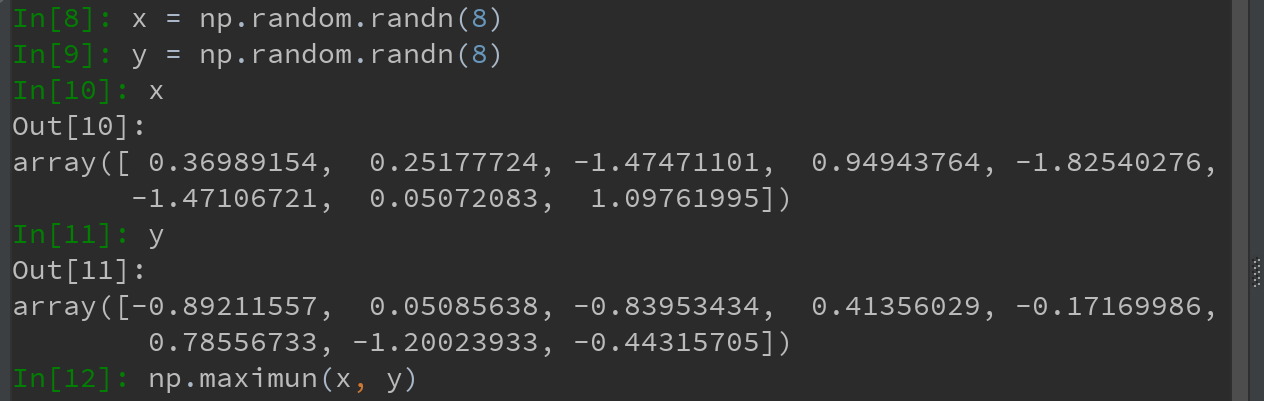

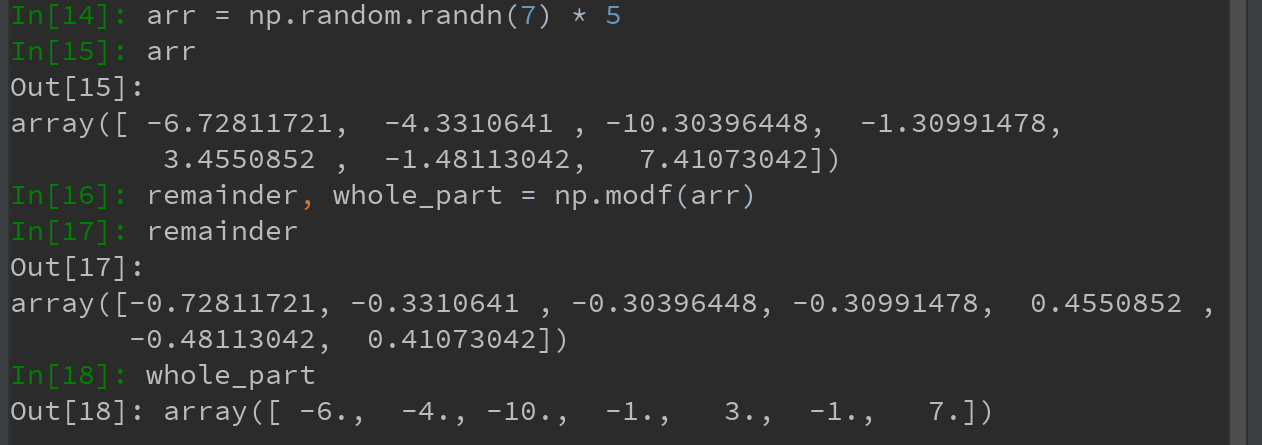
3)部分ufunc可返回多个数组,如modf,是Python内置函数divmod的矢量化版本,可返回浮点数数组的整数部分和小数部分:
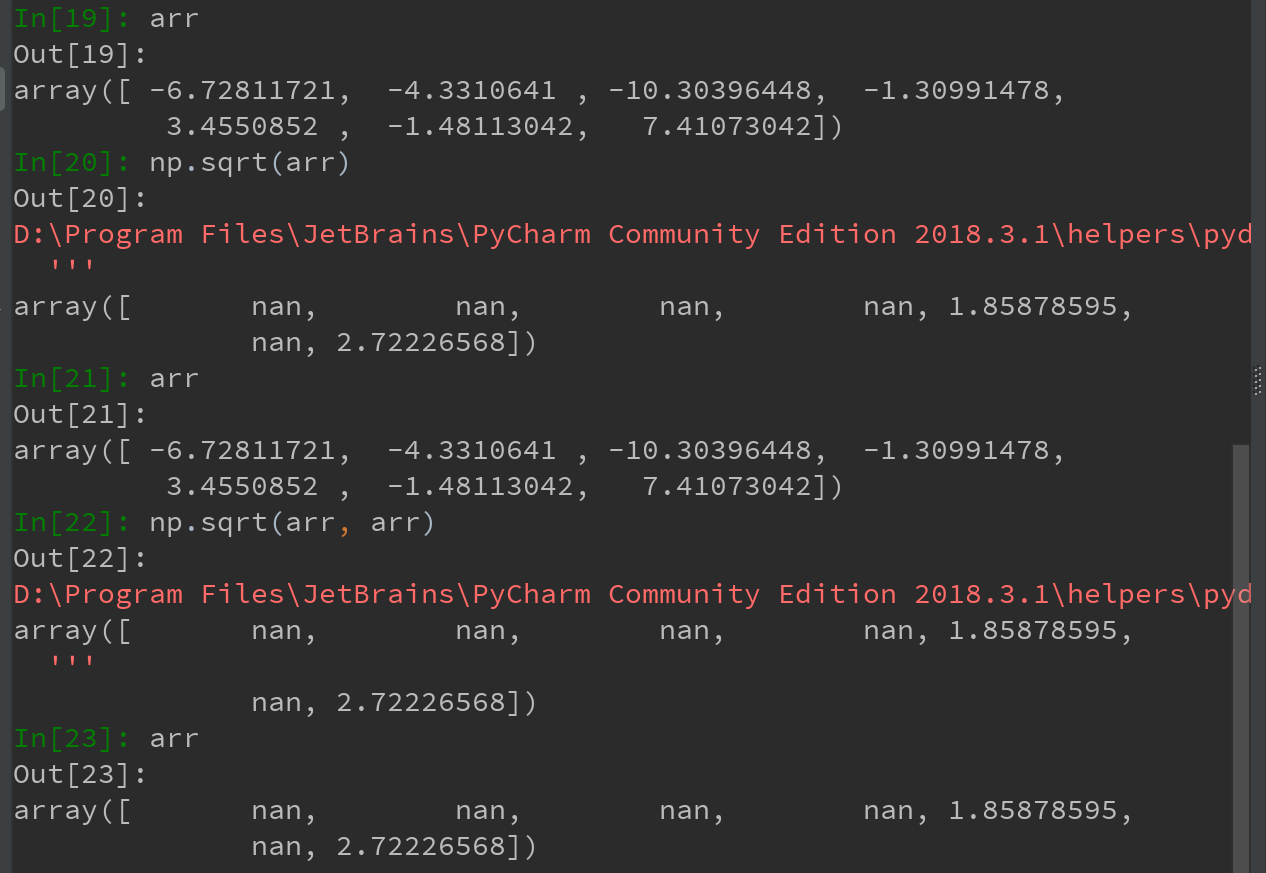
4)Ufuncs可以接受一个out可选参数,这样就能在数组原地进行操作。
列举部分一元和二元ufunc


4.3 利用数组进行数据处理
numpy提供的numpy.meshgrid()函数可以让我们快速生成坐标矩阵X,Y。
语法:X,Y = numpy.meshgrid(x, y)
输入的x,y,就是网格点的横纵坐标列向量(非矩阵)
输出的X,Y,就是坐标矩阵。
(1)将条件逻辑表述为数组运算 - Numpy.where函数
numpy.where函数是三元表达式 x if condition else y 的矢量化版本。numpy.where(condition, result1, reult2),如果condition为真值,则输出result1,如果condition为False值,则输出result2。示例:

假设我们有如上一个布尔数组和两个值数组,现根据cond中的值选取xarr和yarr值,也即:当cond中为True时,选取xarr的值,否则从yarr中选取。

Ps:在数据分析工作中,where通常用于根据一个数组生成一个新数组。
如,希望将一个由随机数据组成的矩阵中,所有的正值替换为2,所有负值替换为-2,则实现如下:
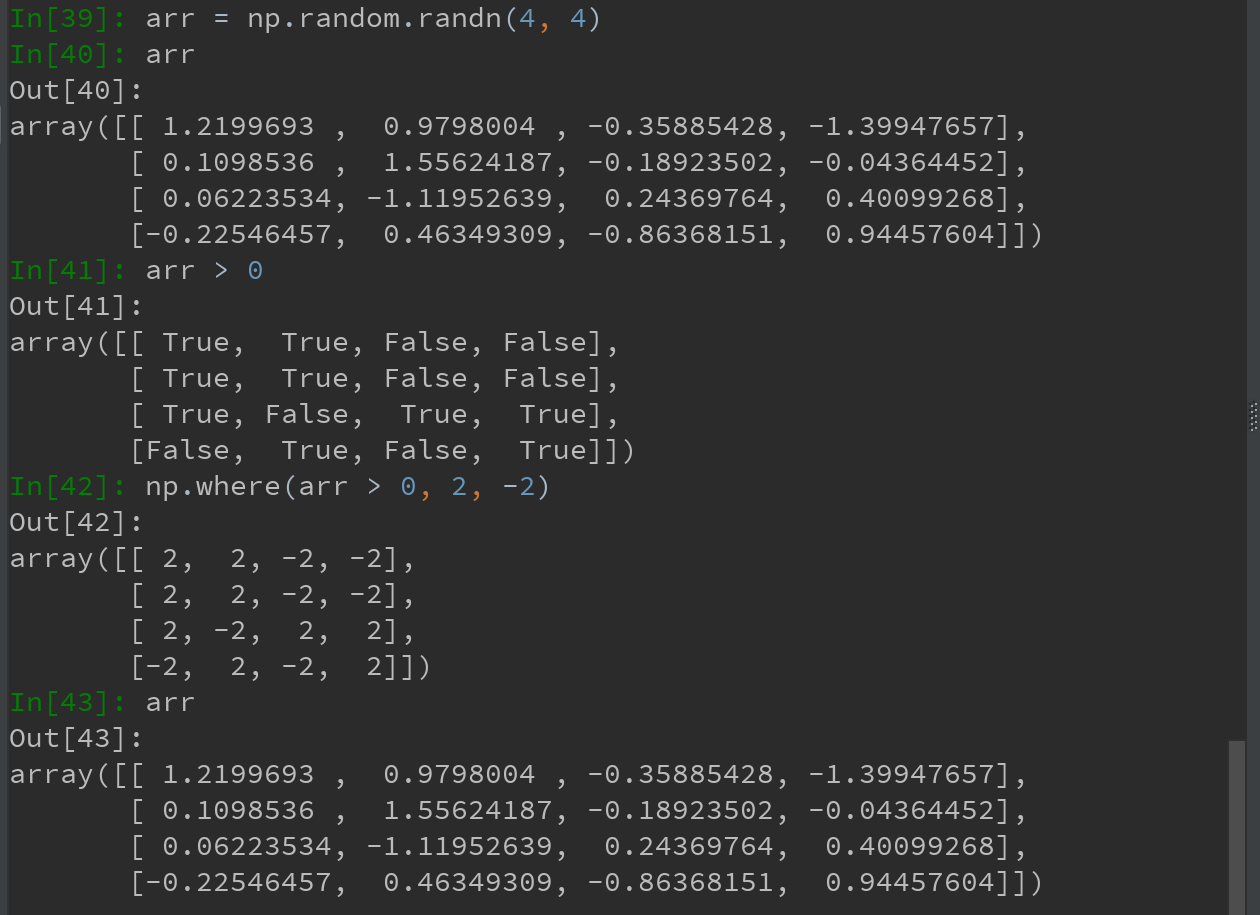
此外,np.where 可以将标量和数组结合使用,如仅将arr中的正值替换为2,其余保持不变:

(2)数学和统计方法
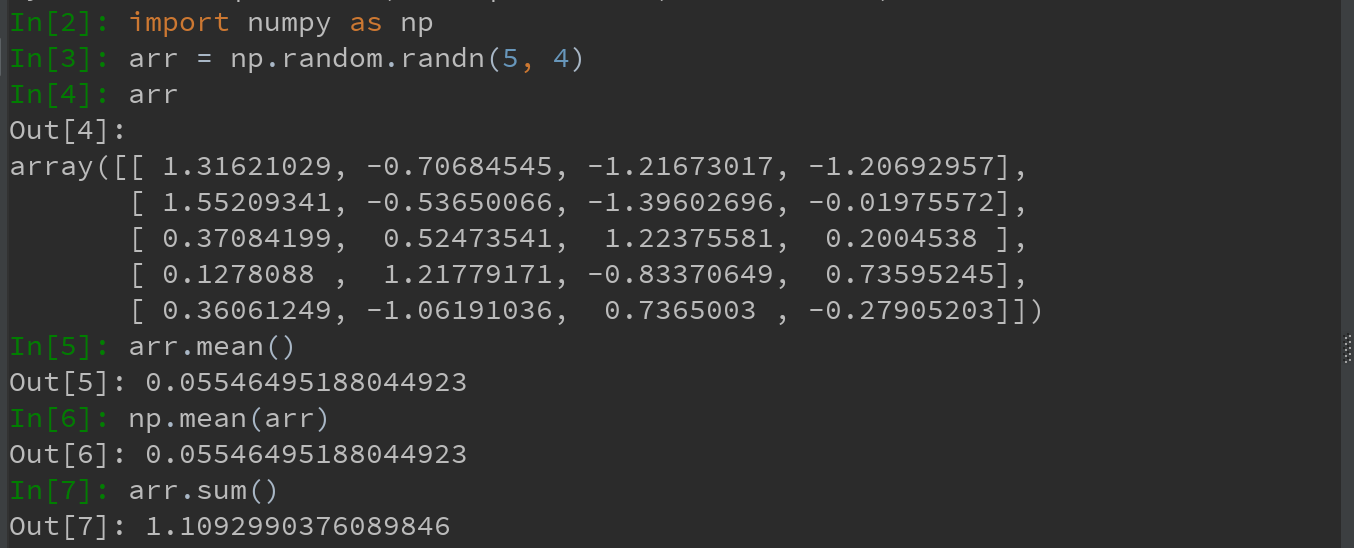
可通过数组上的一组数学函数,对整个数组或某个轴向的数据进行统计计算。sum、mean及标准差std等聚合计算(aggreation,通常叫约简-reduction)既可当作数组的实例方法调用,也可以当作顶级NumPy函数使用。
Ps:mean和sum这类函数可接受一个axis选项参数,用于计算该轴向上的统计值,最终结果是一个少一维的数组。
关于NumPy数组轴的理解,参见:https://www.cnblogs.com/ElonJiang/p/11626851.html

arr.mean(axis = 1) 是指沿列方向折叠聚合求每一行的平均值;
arr.sum(axis = 0) 是指沿行方向折叠聚合求每一列的和。

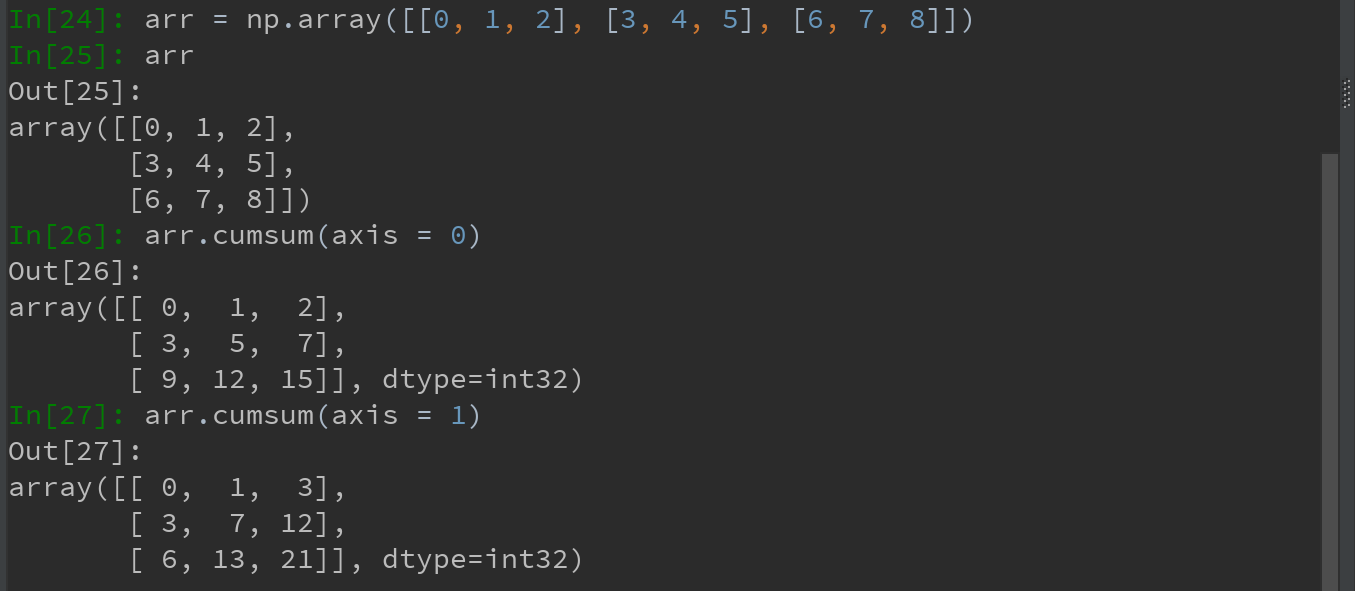
arr.cumsum和arr.cumprod分别用于求所有元素的累计和,以及累计积。同样适用于多维数组:
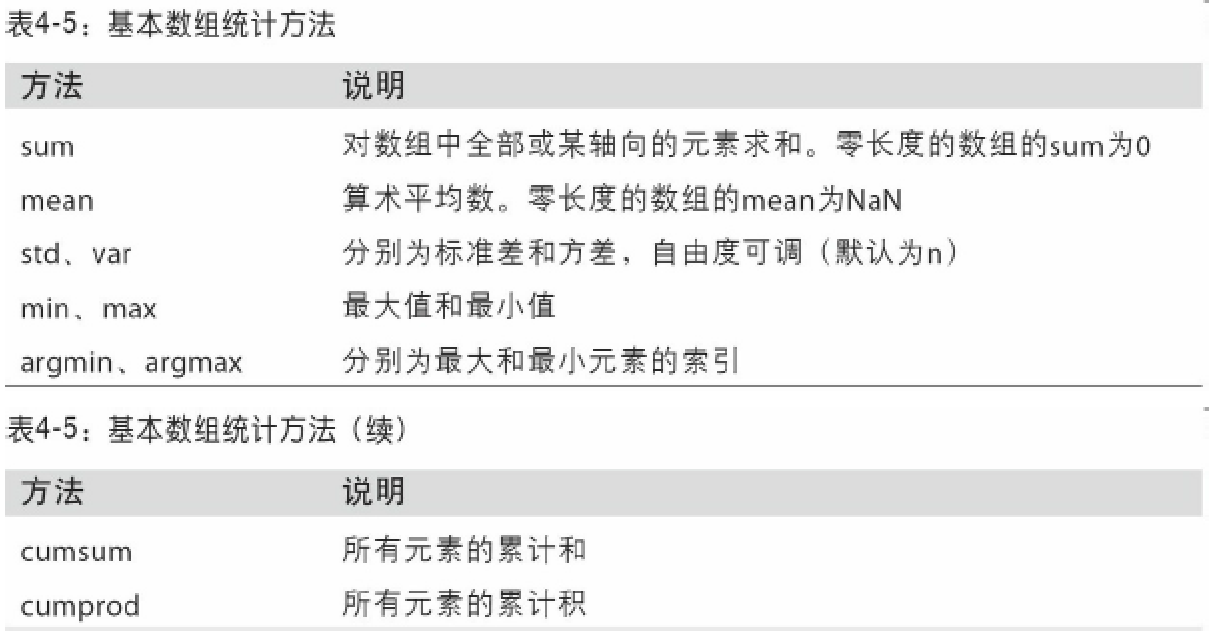
列出全部的基本数组统计方法:
(3)用于布尔型数组的方法
1)布尔型数组中的sum方法
在上面(2)所列出的方法中,布尔值会被强制转换为1(True)和0(False),故,sum经常被用来对布尔型数组中的True值计数:

2)布尔型数组中的any和all方法
any用于测试数组中是否存在一个或多个True;all用于检查数组中所有值是否都是True

Ps:any和all方法也可用于非布尔类型数组,所有非0元素将会被当作True。
(4)排序
NumPy数组,跟Python内置的列表类型一样,可以通过sort方法就地排序。
一维数组:

多维数组(可在任何一个轴向进行排序,只需将轴编号传给sort即可):
Ps:顶级方法 np.sort()返回的是数组的已排序副本,但前述arr.sort()是就地排序会修改数组本身。
排序的经典应用:
计算数组分位数,最简单方法是对数组进行排序,然后取特定位置的值即可,示例如下。

(5)唯一化及其他的集合逻辑
NumPy提供了一些针对一维ndarray的基本集合运算。
1)np.unique,最常用的基本集合运算方法,用于找出数组中的唯一值并返回已排序的结果。


2)np.in1d,用于测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组。

NumPy中的集合函数:

4.4 用于数组的文件输入输出
NumPy能够读写磁盘上的文本数据或二进制数据,此处仅学习NumPy的内置二进制格式(通常更多用户会使用pandas或其他加载文本或表格数据,见第6章)
(1)np.save和np.load函数
np.save函数,用于在磁盘上写入数组数据,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为 .npy的文件中。
np.load函数,用于从磁盘上读取数组数据。

(2)np.savez函数
np.savez函数,可将多个数组保存到一个未压缩的文件中,将数组以关键字参数的形式传入即可。
加载 .npz文件时,会得到一个类似字典的对象,该对象会对各个数组进行延迟加载。

4.5 线性代数(不完整,待需要之时深入学习)
线性代数,如矩阵乘法、矩阵分解、行列式以及其他方阵数学等,是任何数组库的重要组成部分。
(1)矩阵乘法numpy.dot函数,既是一个数组方法,也是numpy命名空间中的一个函数
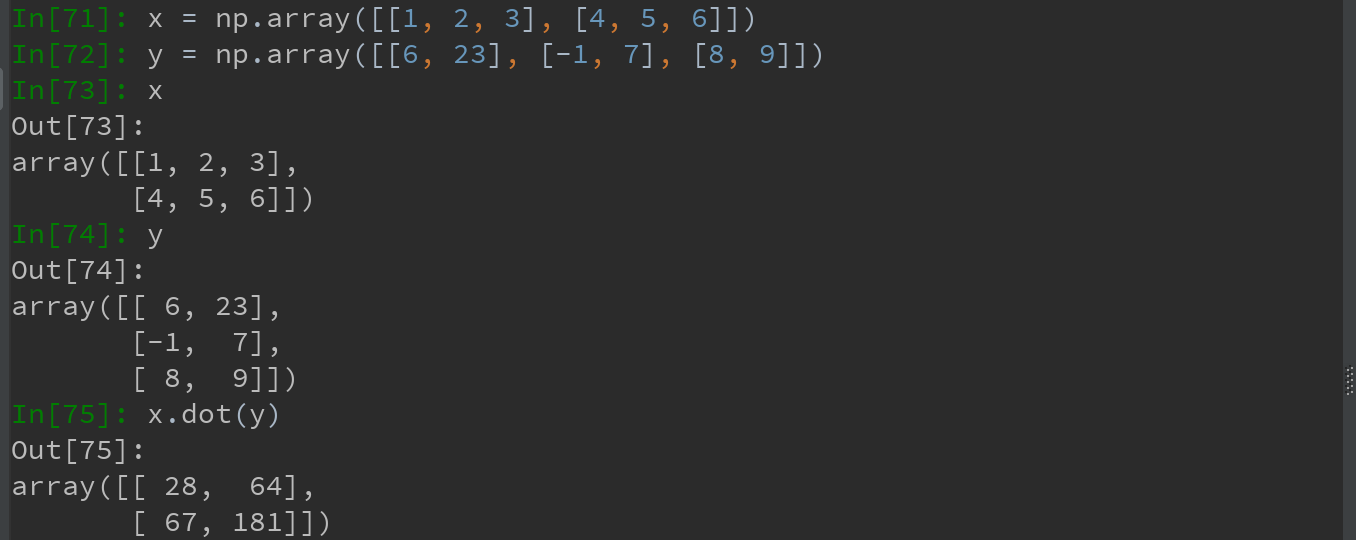
x.dot(y) 等价于 np.dot(x, y)

numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的函数,常用的numpy.linalg列出如下:

该部分涉及较多线性代数的数学知识,故其余的在业务需要之时,结合案例学习。
4.6 伪随机数生成
numpy.random模块对Python内置的random进行了补充,增加了一些用于高效生成多种概率分布的样本值的函数。
称之为“伪随机函数”,是因为它们都是通过 算法基于 随机数生成器种子,在确定性的条件下生成的。
可通过NumPy的np.random.seed更改随机数生成种子:

numpy.random的数据生成函数,使用了全局的随机种子。
要避免全局状态,可使用np.random.RandomState创建一个与其它隔离的随机数生成器:

部分numpy.random中的函数:

4.7 示例:随机漫步
随机漫步理论参考:https://blog.csdn.net/Da___Vinci/article/details/82958297
(1)简单的随机漫步:从0开始,步长1和-1等概率出现
关于random.randint函数,参见:https://www.cnblogs.com/ElonJiang/p/11627717.html

基于所得的数据,沿漫步路径做一些统计工作,如求最大值和最小值:

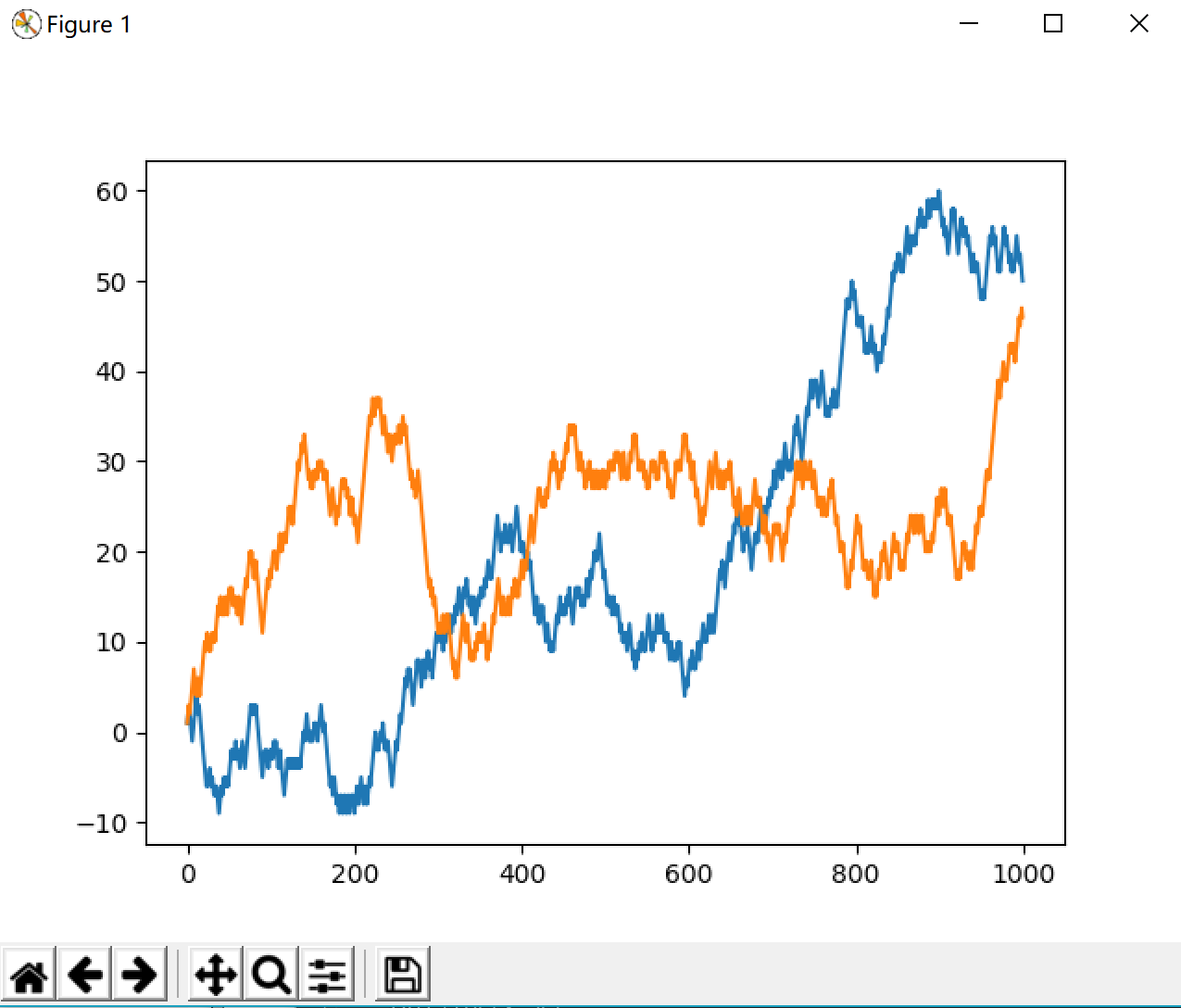
继续求1000个随机漫步值生成的折线图:

Ps:稍复杂的统计任务——计算首次穿越时间,即随机漫步过程中第一次到达某个特定值的时间
假设,统计本次随机漫步需要多久才能距离初始0点至少10步远(任一方向均可)

其中,函数 .argmax(),返回的是该布尔型数组(np.abs(walk)>=10)第一个最大值的索引(True就是最大值)。
(2)一次模拟多个随机漫步
示例,模拟5000个随机漫步过程。
(关于np.random.randint函数,参见:https://www.cnblogs.com/ElonJiang/p/11627717.html)
进行随机漫步过程最大值和最小值的统计:

统计30或-30的最小穿越时间:
1)先用any方法进行检查

2)用该布尔类型数组选出穿越了30(abs绝对值)的随机漫步(行),调用argmax在轴1上获取穿越时间

利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)的更多相关文章
- 利用Python进行数据分析 第4章 IPython的安装与使用简述
本篇开始,结合前面所学的Python基础,开始进行实战学习.学习书目为<利用Python进行数据分析>韦斯-麦金尼 著. 之前跳过本书的前述基础部分(因为跟之前所学的<Python基 ...
- python数据分析---第04章 NumPy基础:数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- 利用Python进行数据分析 第7章 数据清洗和准备(2)
7.3 字符串操作 pandas加强了Python的字符串和文本处理功能,使得能够对整组数据应用字符串表达式和正则表达式,且能够处理烦人的缺失数据. 7.3.1 字符串对象方法 对于许多字符串处理和脚 ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- python numpy基础 数组和矢量计算
在python 中有时候我们用数组操作数据可以极大的提升数据的处理效率, 类似于R的向量化操作,是的数据的操作趋于简单化,在python 中是使用numpy模块可以进行数组和矢量计算. 下面来看下简单 ...
- 利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式 实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化. pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle ...
- 利用Python进行数据分析 第7章 数据清洗和准备(1)
学习时间:2019/10/25 周五晚上22点半开始. 学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完. 实际反馈:集中学习1.5小时,学习6页:集中学习 ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 利用Python进行数据分析 第5章 pandas入门(2)
5.2 基本功能 (1)重新索引 - 方法reindex 方法reindex是pandas对象地一个重要方法,其作用是:创建一个新对象,它地数据符合新地索引. 如,对下面的Series数据按新索引进行 ...
随机推荐
- 小程序开发--API之登录授权逻辑
小程序登录授权获取逻辑 原生的小程序提供许多开放接口供使用者开发,快速建立小程序内的用户体系. 下面将小程序校验.登录.授权.获取用户信息诸多接口串联起来,以便更直观的认识到这些接口是如何在实际应用中 ...
- 常用的etl工具比较
ETL是什么? ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract).转换(transform).加载(load)至目的端的过程.(数 ...
- bind--dns-docker---[nslookup/dig]
[dig] https://www.cnblogs.com/apexchu/p/6790241.html [dns resolution and revserse ]https://www.cnbl ...
- Linux中 mv(文件移动)
mv命令的功能有以下两种: source target mv 参数1 参数2 1.对文件或目录重新命名 如果源文件和目标文件在同一个目录下,mv的作用就是改文件名. 2.将文件从一个目录移到另一个目录 ...
- angular 中*ngIf 和*ngSwitch判断语句
<div style="text-align:center"> <h1> Welcome to {{ title }}! </h1> <p ...
- 贝济埃曲线quadTo与传统的手势轨迹平滑度对比分析
package com.loaderman.customviewdemo; import android.content.Context; import android.graphics.Canvas ...
- JDK&JRE
JDK是提供给Java开发人员使用的,其中包含了java的开发工具,也包括了JRE.所以安装了JDK,就不用在单独安装JRE了. 其中的开发工具:编译工具(javac.exe) 打包工具(jar.ex ...
- 阶段5 3.微服务项目【学成在线】_day09 课程预览 Eureka Feign_06-Feign远程调用-Ribbon测试
2.1.2 Ribbon测试 Spring Cloud引入Ribbon配合 restTemplate 实现客户端负载均衡.Java中远程调用的技术有很多,如: webservice.socket.rm ...
- 阶段5 3.微服务项目【学成在线】_day16 Spring Security Oauth2_20-认证接口开发-接口测试
测试接口 因为继承了spring security会拦截这个请求,我们需要写代码 让他对这个认证接口放行 查看代码发现之前已经写过放行的代码了 发现是路径前面少了auth 加断点,测试.申请令牌 r ...
- 一百四十八:部署python项目之环境依赖
环境:centos7 + python3.6 准备工作,生成项目requirements.txt文件,用于存放第三方库和版本信息:pip freeze > requirements.txt,并且 ...