seq2seq聊天模型(二)——Scheduled Sampling
使用典型seq2seq模型,得到的结果欠佳,怎么解决
结果欠佳原因在这里
- 在训练阶段的decoder,是将目标样本["吃","兰州","拉面"]作为输入下一个预测分词的输入。
- 而在预测阶段的decoder,是将上一个预测结果,作为下一个预测值的输入。(注意查看预测多的箭头)
这个差异导致了问题的产生,训练和预测的情景不同。
在预测的时候,如果上一个词语预测错误,还后面全部都会跟着错误,蝴蝶效应。

解决办法-Scheduled Sampling
修改训练时decoder的模型
基础模型只会使用真实lable数据作为输入, 现在,train-decoder不再一直都是真实的lable数据作为下一个时刻的输入。
train-decoder时以一个概率P选择模型自身的输出作为下一个预测的输入,以1-p选择真实标记作为下一个预测的输入。
Secheduled sampling(计划采样),即采样率P在训练的过程中是变化的。
一开始训练不充分,先让P小一些,尽量使用真实的label作为输入,随着训练的进行,将P增大,多采用自身的输出作为下一个预测的输入。
随着训练的进行,P越来越大大,train-decoder模型最终变来和inference-decoder预测模型一样,消除了train-decoder与inference-decoder之间的差异
总之:
通过这个scheduled-samping方案,抹平了训练decoder和预测decoder之间的差异!让预测结果和训练时的结果一样。
tensorflow
tensoflow已经完成了这个模型,直接调用,设定参数可以使用
training_helper = tf.contrib.seq2seq.ScheduledEmbeddingTrainingHelper(inputs=dec_emb_inputs,sequence_length=self.dec_sequence_length + 2,embedding=self.dec_Wemb,sampling_probability=self.sampling_probability,time_major=False,name='training_helper')self.sampling_probability = tf.placeholder(tf.float32,shape=[],name='sampling_probability')# 下面这个时feed_dic# 随着epoch的增大,sampling_probability_list逐渐变为1,即全部采用自身输出作为下个输入,sampling_probability_list = np.linspace(start=0.0,stop=1.0,num=n_epoch,dtype=np.float32)
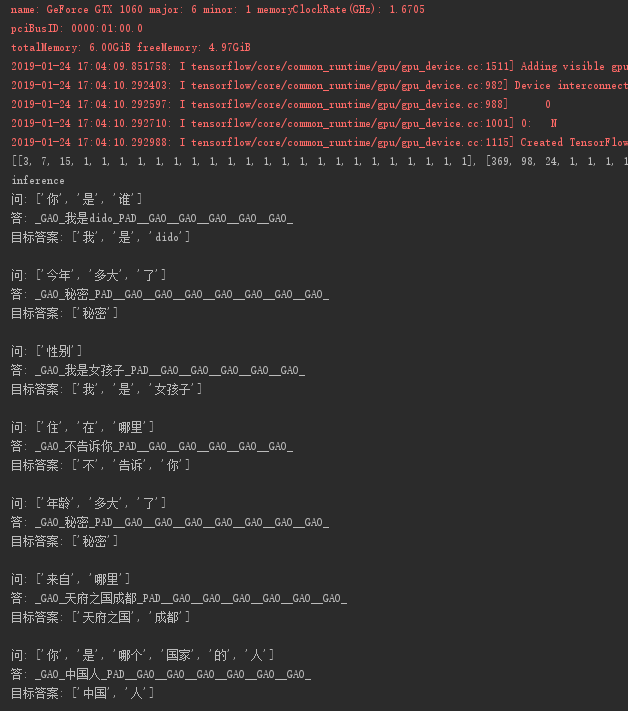
实际结果
效果很好
seq2seq聊天模型(二)——Scheduled Sampling的更多相关文章
- seq2seq聊天模型(一)
原创文章,转载请注明出处 最近完成了sqe2seq聊天模型,磕磕碰碰的遇到不少问题,最终总算是做出来了,并符合自己的预期结果. 本文目的 利用流程图,从理论方面,回顾,总结seq2seq模型, seq ...
- seq2seq聊天模型(三)—— attention 模型
注意力seq2seq模型 大部分的seq2seq模型,对所有的输入,一视同仁,同等处理. 但实际上,输出是由输入的各个重点部分产生的. 比如: (举例使用,实际比重不是这样) 对于输出"晚上 ...
- 深度学习教程 | Seq2Seq序列模型和注意力机制
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/35 本文地址:http://www.showmeai.tech/article-det ...
- django模型二
django模型二 常用模型字段类型 IntegerField → int CharField → varchar TextField → longtext DateFiel ...
- pytorch做seq2seq注意力模型的翻译
以下是对pytorch 1.0版本 的seq2seq+注意力模型做法语--英语翻译的理解(这个代码在pytorch0.4上也可以正常跑): # -*- coding: utf-8 -*- " ...
- socket实现聊天功能(二)
socket实现聊天功能(二) WebSocket协议是建立在HTTP协议之上,因此创建websocket服务时需要调用http模块的createServer方法.将生成的server作为参数传入so ...
- [Beego模型] 二、CRUD 操作
[Beego模型] 一.ORM 使用方法 [Beego模型] 二.CRUD 操作 [Beego模型] 三.高级查询 [Beego模型] 四.使用SQL语句进行查询 [Beego模型] 五.构造查询 [ ...
- {django模型层(二)多表操作}一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询、分组查询、F查询和Q查询
Django基础五之django模型层(二)多表操作 本节目录 一 创建模型 二 添加表记录 三 基于对象的跨表查询 四 基于双下划线的跨表查询 五 聚合查询.分组查询.F查询和Q查询 六 xxx 七 ...
- {03--CSS布局设置} 盒模型 二 padding bode margin 标准文档流 块级元素和行内元素 浮动 margin的用法 文本属性和字体属性 超链接导航栏 background 定位 z-index
03--CSS布局设置 本节目录 一 盒模型 二 padding(内边距) 三 boder(边框) 四 简单认识一下margin(外边距) 五 标准文档流 六 块级元素和行内元素 七 浮动 八 mar ...
随机推荐
- Redis过期命令
Redis键的过期时长的设定 ·命令名称:EXPIRE ·语法:EXPIRE key seconds ·功能:为给定key设置生存时间,当key过期时(生存时间为0),它会被自动删除 ·返回值:设置成 ...
- Abp 领域事件简单实践 <三> 自定义事件
熵片用到的 EntityCreatedEventData<TEntity>,继承自EventData. 我们可以自定义事件: public class TestEvent: EventD ...
- ppt调整三级标题的位置
---恢复内容开始--- 标题格式:一级标题 中文数字加.例如 一. 二级标题 中文数字加: 例如二: 三级标题 小写数字加. 例如3. 使用方法: 打开PPT 按alt+f11,打开 ...
- 关于Objective C的私有函数
(1)很多从其他语言(例如C++)转到objective c的初学者,往往会问到一个问题,如何定义类的私有函数?这里的“私有函数”指的是,某个函数只能在类的内部使用,不能在类的外部,或者派生类内部使用 ...
- css垂直居中如何实现
利用CSS3的transform:translate .center{ width:%; position: absolute; top: %; left: %; -moz-transform: tr ...
- innodb是如何巧妙实现事务隔离级别-转载
原文地址:innodb是如何巧妙实现事务隔离级别 之前的文章mysql锁机制详解中我们详细讲解了innodb的锁机制,锁机制是用来保证在并发情况下数据的准确性,而要保证数据准确通常需要事务的支持,而m ...
- 彻底弄懂HTTP缓存机制及原理-转载
首先附上原文地址,非常感谢博主大神的分享彻底弄懂HTTP缓存机制及原理 前言 Http 缓存机制作为 web 性能优化的重要手段,对于从事 Web 开发的同学们来说,应该是知识体系库中的一个基 ...
- Image Processing and Analysis_15_Image Registration: A Method for Registration of 3-D shapes——1992
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- C# 直播录制视频
//项目引用 ffmpeg.exe 下载地址http://ffmpeg.org/ var time = DateTime.Now; ; //录制分钟 var fileName = Guid.NewGu ...
- sk_buff内核api函数记录
1.alloc_skb() 上层协议要发送数据包的时候或网络设备准备接收数据包的时候调用 2.kfree_skb() 释放sk_buff结构体 3.skb_put() 在数据区的末端添加某协议的尾部 ...