《Mysql 索引 - 概述》
一:索引的目的
- 索引的出现其实就是为了提高数据查询的效率,就像书的目录一样。
二:InnoDB 索引模型
- InnoDB 采用 B+树 的数据结构进行存储。
- 例如,我们建立一张表,分析他的数据建立
mysql> create table T(
id int primary key,
k int not null,
name varchar(),
index (k)
) engine=InnoDB;插入对应的表数据,表中 R1~R5 的 (ID,k) 值分别为 (,)、(,)、(,)、(,) 和 (,)
- 则,对应的两颗树建立如下
- 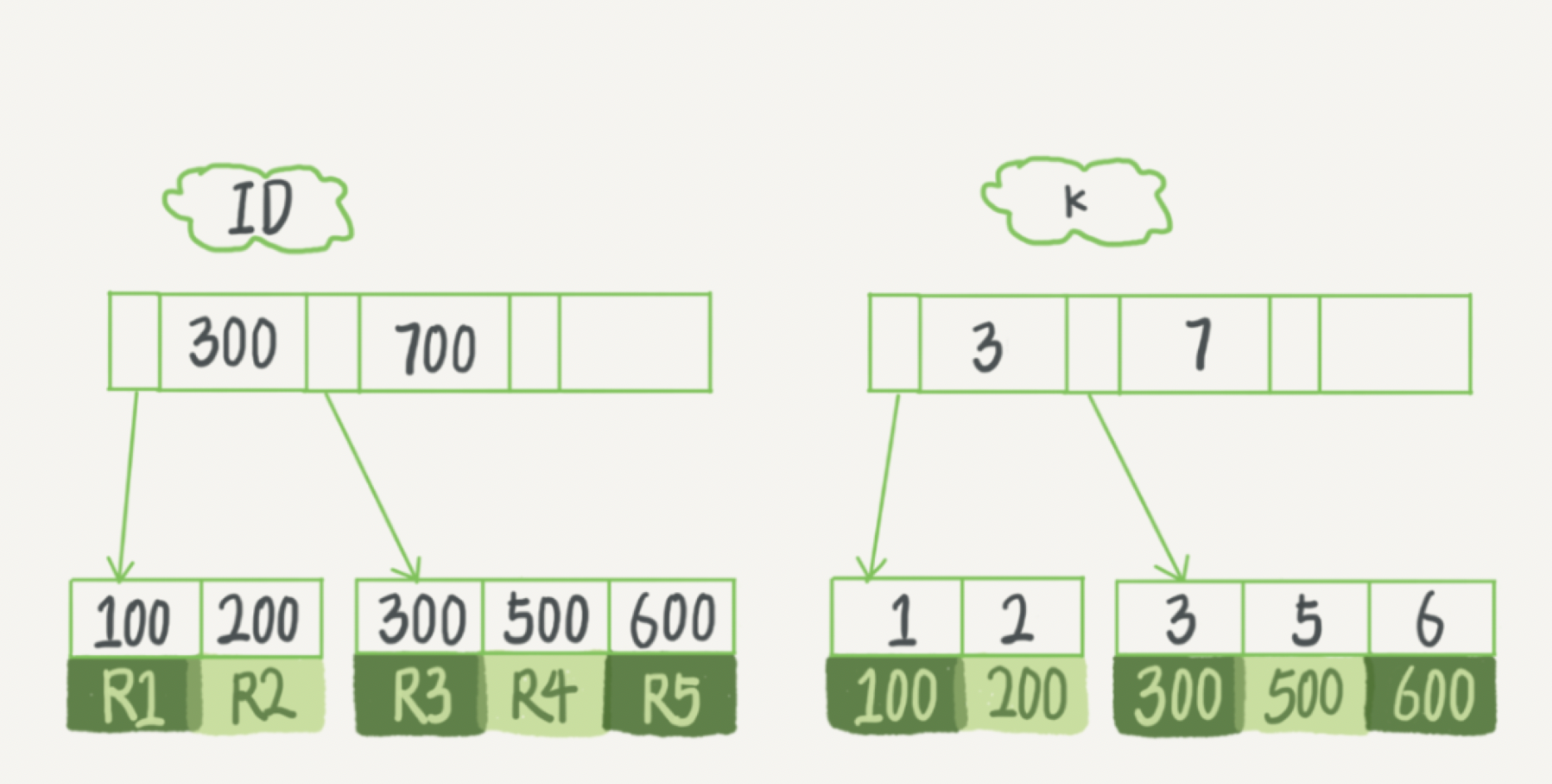
- 从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
- 主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
- 非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
- 也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
三:基于存储结构谈为什么要建立自增主键?
- B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。
- 以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。
- 如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
- 而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。
- 在这种情况下,性能自然会受影响。
- 在这种情况下,性能自然会受影响。
- 除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
- 自增主键
- 也就是说,自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。
- 每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
- 显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
- 所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
- 适合业务做主键的使用场景
- 只有一个索引;
- 该索引必须是唯一索引。
- 典型的 KV 场景。(由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。)
四:联合索引技巧
- 覆盖索引
- 如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据
- 最左前缀(前缀索引)
- 联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符(前缀索引)
- 联合索引
- 根据创建联合索引的顺序,以最左原则进行where检索。
- 比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引。
- 考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。
- MySQL5.6版本之前,会对匹配的数据进行回表查询。
- 5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
四:索引重建
- 为什么要重索引?
- 文章里面有提到,索引可能因为删除,或者页分裂等原因,导致数据页有空洞。
- 重建索引的过程会创建一个新的索引,把数据按顺序插入,这样页面的利用率最高,也就是索引更紧凑、更省空间。
- 如何重建索引
- 注意:不论是删除主键还是创建主键,都会将整个表重建。
重建索引请使用
- alter table T engine=InnoDB
《Mysql 索引 - 概述》的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- 【原创】go语言学习(十七)接口应用实战--日志库
目前 日志库需求分析 日志库接口设计 文件日志库开发 Console日志开发 日志使用以及测试 日志库需求分析 1.日志库需求分析 A. 程序运行是个黑盒B. 而日志是程序运行的外在表现C. 通过日志 ...
- C++11多线程std::thread创建方式
//#include <cstdlib> //#include <cstdio> //#include <cstring> #include <string& ...
- Lua 常用函数 一
lua_getallocf lua_Alloc lua_getallocf (lua_State *L, void **ud); 返回给定状态机的内存分配器函数.如果 ud 不是 NULL ,Lua ...
- python3 调用 beautifulSoup 进行简单的网页处理
python3 调用 beautifulSoup 进行简单的网页处理 from bs4 import BeautifulSoup file = open('index.html','r',encodi ...
- Mac 10.14.5系统偏好设置安全性与隐私不展示任何来源解决办法
Mac新系统升级(10.14.5)后未从appstore下载的软件在安装时会提示安装包已损坏之类的东东,这是因为没有打开“设置”—“安全与隐私”中的“任何来源”造成的,可是升级后的10.14.5却没有 ...
- (转)hadoop 常规错误问题(一)
转至:http://www.freeoa.net/osuport/db/my-hbase-usage-problem-sets_2979.html 本文是我在使用Hbase的过程碰到的一些问题和相应的 ...
- [APIO2015]八邻旁之桥——非旋转treap
题目链接: [APIO2015]八邻旁之桥 对于$k=1$的情况: 对于起点和终点在同侧的直接计入答案:对于不在同侧的,可以发现答案就是所有点坐标与桥坐标的差之和+起点与终点不在同一侧的人数. 将所有 ...
- combobox放入数据
页面 <th width="15%">国际分类号</th><td width="30%"> <select cla ...
- 2018-2019-2 网络对抗技术 20165202 Exp7 网络欺诈防范
博客目录 一.实践目标 二.实践内容 简单应用SET工具建立冒名网站 (1分) ettercap DNS spoof (1分) 结合应用两种技术,用DNS spoof引导特定访问到冒名网站.(1.5分 ...
- Java 面向对象(十)
常用类之Arrays java.util.Arrays 类是 JDK 提供的一个工具类,用来处理数组的各种方法,而且每个方法基本上都是静态方法,能直接通过类名Arrays调用. 1.asList 返回 ...