pytorch中的学习率调整函数
参考:https://pytorch.org/docs/master/optim.html#how-to-adjust-learning-rate
torch.optim.lr_scheduler提供了几种方法来根据迭代的数量来调整学习率
自己手动定义一个学习率衰减函数:
def adjust_learning_rate(optimizer, epoch, lr):
"""Sets the learning rate to the initial LR decayed by 10 every 2 epochs"""
lr *= (0.1 ** (epoch // 2))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
optimizer通过param_group来管理参数组。param_group中保存了参数组及其对应的学习率,动量等等
使用:
model = AlexNet(num_classes=)
optimizer = optim.SGD(params = model.parameters(), lr=) plt.figure()
x = list(range())
y = []
lr_init = optimizer.param_groups[]['lr'] for epoch in range():
adjust_learning_rate(optimizer, epoch, lr_init)
lr = optimizer.param_groups[]['lr']
print(epoch, lr)
y.append(lr) plt.plot(x,y)
返回:
10.0
10.0
1.0
1.0
0.10000000000000002
0.10000000000000002
0.010000000000000002
0.010000000000000002
0.0010000000000000002
0.0010000000000000002
如图:
举例先导入所需的库:
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
1.LambdaLR
CLASS torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-)
将每个参数组的学习率设置为初始lr乘以给定函数。当last_epoch=-1时,将初始lr设置为lr。
参数:
optimizer (Optimizer) – 封装好的优化器
lr_lambda (function or list) –当是一个函数时,需要给其一个整数参数,使其计算出一个乘数因子,用于调整学习率,通常该输入参数是epoch数目;或此类函数的列表,根据在optimator.param_groups中的每组的长度决定lr_lambda的函数个数,如下报错。
last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
如:
optimizer = optim.SGD(params = model.parameters(), lr=0.05) lambda1 = lambda epoch:epoch // 10 #根据epoch计算出与lr相乘的乘数因子为epoch//10的值
lambda2 = lambda epoch:0.95 ** epoch #根据epoch计算出与lr相乘的乘数因子为0.95 ** epoch的值
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
报错:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input--c02d2d9ffc0d> in <module>
lambda1 = lambda epoch:epoch //
lambda2 = lambda epoch:0.95 ** epoch
----> scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
plt.figure()
x = list(range()) /anaconda3/envs/deeplearning/lib/python3./site-packages/torch/optim/lr_scheduler.py in __init__(self, optimizer, lr_lambda, last_epoch)
if len(lr_lambda) != len(optimizer.param_groups):
raise ValueError("Expected {} lr_lambdas, but got {}".format(
---> len(optimizer.param_groups), len(lr_lambda)))
self.lr_lambdas = list(lr_lambda)
self.last_epoch = last_epoch ValueError: Expected lr_lambdas, but got
说明这里只需要一个lambda函数
举例:
1)使用的是lambda2
model = AlexNet(num_classes=)
optimizer = optim.SGD(params = model.parameters(), lr=0.05) #下面是两种lambda函数
#epoch=0到9时,epoch//10=0,所以这时的lr = 0.05*0=0
#epoch=10到19时,epoch//10=1,所以这时的lr = 0.05*1=0.05
lambda1 = lambda epoch:epoch //
#当epoch=0时,lr = lr * (0.2**)=0.05;当epoch=1时,lr = lr * (0.2**)=0.01
lambda2 = lambda epoch:0.2 ** epoch scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda2)
plt.figure()
x = list(range())
y = [] for epoch in range():
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[])
y.append(scheduler.get_lr()[]) plt.plot(x,y)
返回:
0.05
0.010000000000000002
0.0020000000000000005
0.00040000000000000013
8.000000000000002e-05
1.6000000000000006e-05
3.2000000000000015e-06
6.400000000000002e-07
1.2800000000000006e-07
2.5600000000000014e-08
5.120000000000003e-09
1.0240000000000006e-09
2.0480000000000014e-10
4.096000000000003e-11
8.192000000000007e-12
1.6384000000000016e-12
3.276800000000003e-13
6.553600000000007e-14
1.3107200000000014e-14
2.621440000000003e-15
5.242880000000006e-16
1.0485760000000013e-16
2.0971520000000027e-17
4.194304000000006e-18
8.388608000000012e-19
1.6777216000000025e-19
3.355443200000005e-20
6.71088640000001e-21
1.3421772800000022e-21
2.6843545600000045e-22
5.368709120000009e-23
1.0737418240000018e-23
2.147483648000004e-24
4.294967296000008e-25
8.589934592000016e-26
1.7179869184000033e-26
3.435973836800007e-27
6.871947673600015e-28
1.3743895347200028e-28
2.748779069440006e-29
如图:

也可以写成下面的格式:
def lambda_rule(epoch):
lr_l = 0.2 ** epoch
return lr_l scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
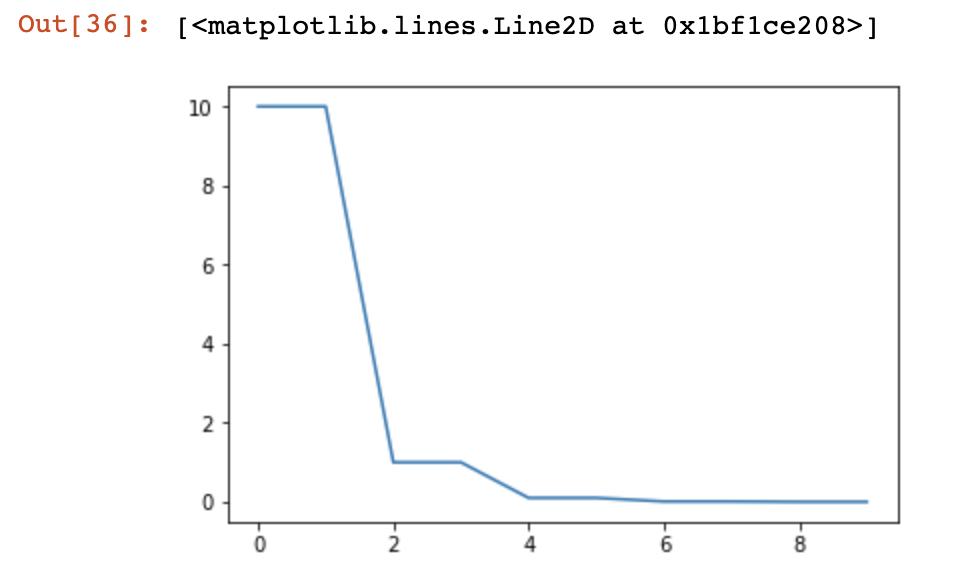
2)使用的是lambda1函数:
返回:
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.1
0.1
0.1
0.1
0.1
0.1
0.1
0.1
0.1
0.1
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
0.15000000000000002
如图:
其他函数:
load_state_dict(state_dict)
下载调试器状态
参数:
- state_dict (dict) – 调试器状态。应为
state_dict()调用返回的对象.
state_dict()
以字典格式返回调试器的状态
它为self.__dict__中的每个变量都包含一个条目,这不是优化器。只有当学习率的lambda函数是可调用对象时才会保存它们,而当它们是函数或lambdas时则不会保存它们。
2.StepLR
CLASS torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-)
每个step_size时间步长后使每个参数组的学习率降低。注意,这种衰减可以与此调度程序外部对学习率的其他更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
参数:
optimizer (Optimizer) – 封装的优化器
step_size (int) – 学习率衰减的周期
gamma (float) – 学习率衰减的乘数因子。Default: 0.1.
last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
举例:
model = AlexNet(num_classes=)
optimizer = optim.SGD(params = model.parameters(), lr=0.05) #即每10次迭代,lr = lr * gamma
scheduler = lr_scheduler.StepLR(optimizer, step_size=, gamma=0.1) plt.figure()
x = list(range())
y = [] for epoch in range():
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[])
y.append(scheduler.get_lr()[]) plt.plot(x,y)
返回:
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
如图:

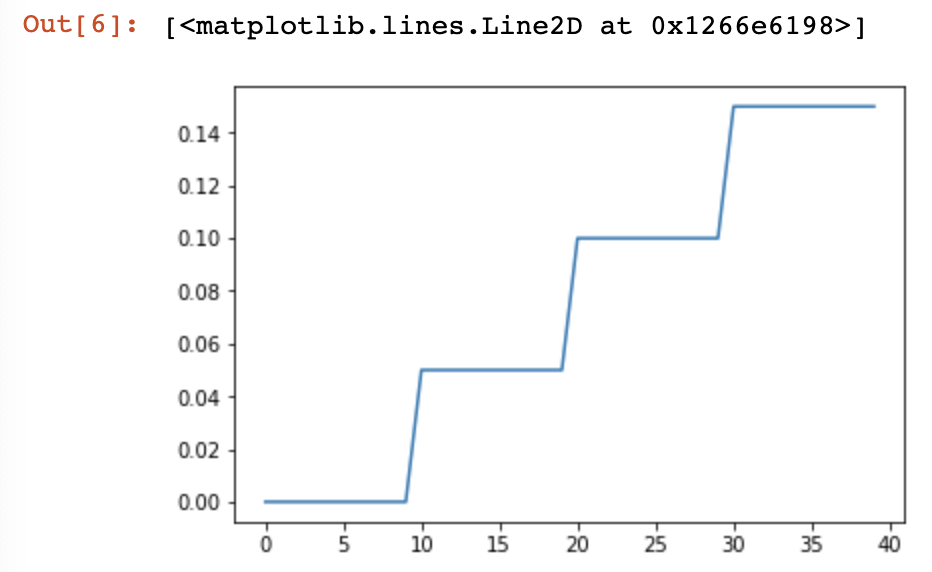
3.MultiStepLR
CLASS torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-)
当迭代数epoch达到某个里程碑时,每个参数组的学习率将被gamma衰减。注意,这种衰减可以与此调度程序外部对学习率的其他更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
参数:
optimizer (Optimizer) – 封装的优化器
milestones (list) –迭代epochs指数列表. 列表中的值必须是增长的.
gamma (float) – 学习率衰减的乘数因子。Default: 0.1.
last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
举例:
model = AlexNet(num_classes=)
optimizer = optim.SGD(params = model.parameters(), lr=0.05) #在指定的epoch值,如[,,,]处对学习率进行衰减,lr = lr * gamma
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[,,,], gamma=0.1) plt.figure()
x = list(range())
y = [] for epoch in range():
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[])
y.append(scheduler.get_lr()[]) plt.plot(x,y)
返回:
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.05
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
0.0005000000000000001
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.0000000000000016e-05
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
5.000000000000001e-06
如图:
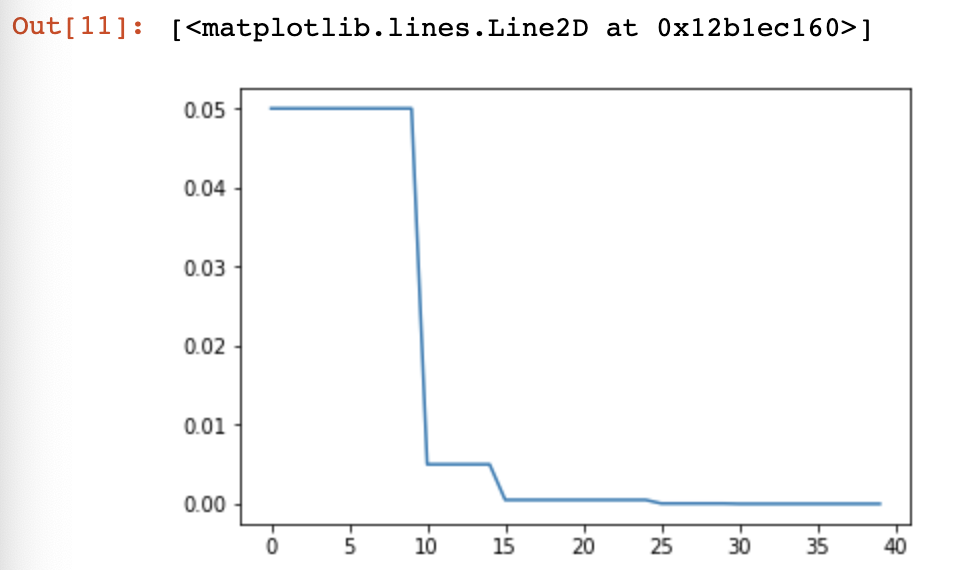
4.ExponentialLR
CLASS torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-)
每个epoch都对每个参数组的学习率进行衰减。当last_epoch=-1时,将初始lr设置为lr。
参数:
optimizer (Optimizer) – 封装的优化器
gamma (float) – 学习率衰减的乘数因子
last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
举例:
model = AlexNet(num_classes=)
optimizer = optim.SGD(params = model.parameters(), lr=0.2) #即每个epoch都衰减lr = lr * gamma,即进行指数衰减
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.2) plt.figure()
x = list(range())
y = [] for epoch in range():
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[])
y.append(scheduler.get_lr()[]) plt.plot(x,y)
返回:
0.2
0.04000000000000001
0.008000000000000002
0.0016000000000000005
0.0003200000000000001
6.400000000000002e-05
1.2800000000000006e-05
2.560000000000001e-06
5.120000000000002e-07
1.0240000000000006e-07
如图:

5.CosineAnnealingLR
CLASS torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=, last_epoch=-)
使用余弦退火调度设置各参数组的学习率,其中ηmax设为初始lr, Tcur为SGDR上次重启后的时间间隔个数:
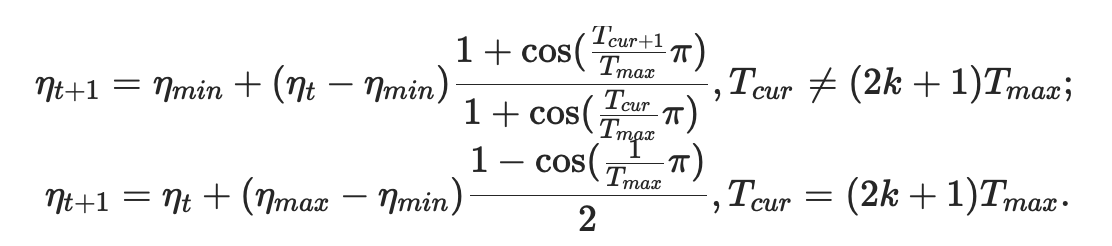
当last_epoch=-1时,将初始lr设置为lr。注意,由于调度是递归定义的,所以其他操作符可以在此调度程序之外同时修改学习率。如果学习速率仅由该调度程序设置。利用cos曲线降低学习率,该方法来源SGDR,学习率变换如下公式:

该方法已在SGDR中提出SGDR: Stochastic Gradient Descent with Warm Restarts。注意,这只实现了SGDR的余弦退火部分,而没有重新启动。
参数:
optimizer (Optimizer) – 封装的优化器
T_max (int) – 迭代的最大数量
eta_min (float) – 最小学习率 Default: 0.
last_epoch (int) – 最后一个迭代epoch的索引. Default: -1.
举例:
model = AlexNet(num_classes=)
optimizer = optim.SGD(params = model.parameters(), lr=) #根据式子进行计算
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=) plt.figure()
x = list(range())
y = [] for epoch in range():
scheduler.step()
lr = scheduler.get_lr()
print(epoch, scheduler.get_lr()[])
y.append(scheduler.get_lr()[]) plt.plot(x,y)
返回:
10.0
5.0
0.0
4.999999999999999
10.0
5.000000000000001
0.0
4.999999999999998
10.0
5.000000000000002
如图:
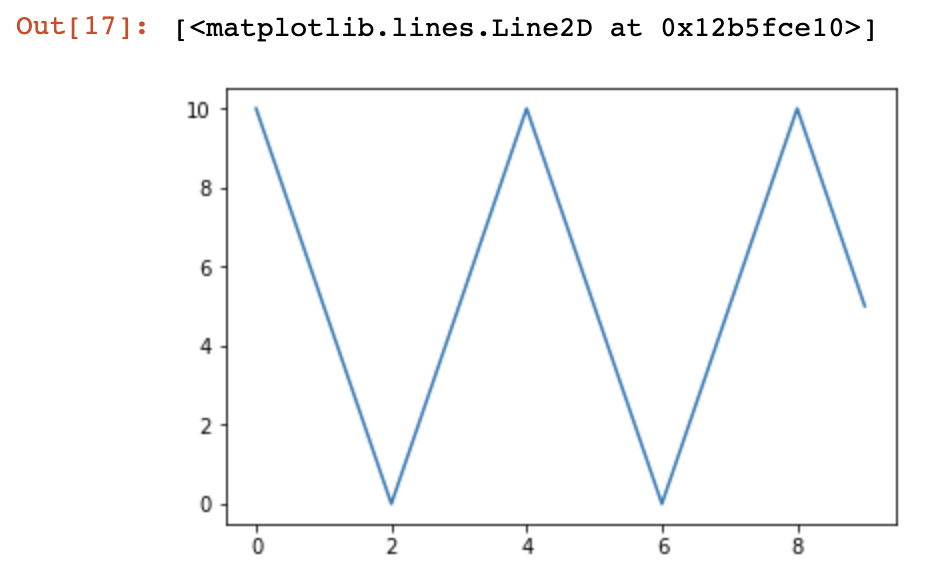
该例子前三个学习率结果的计算方式:
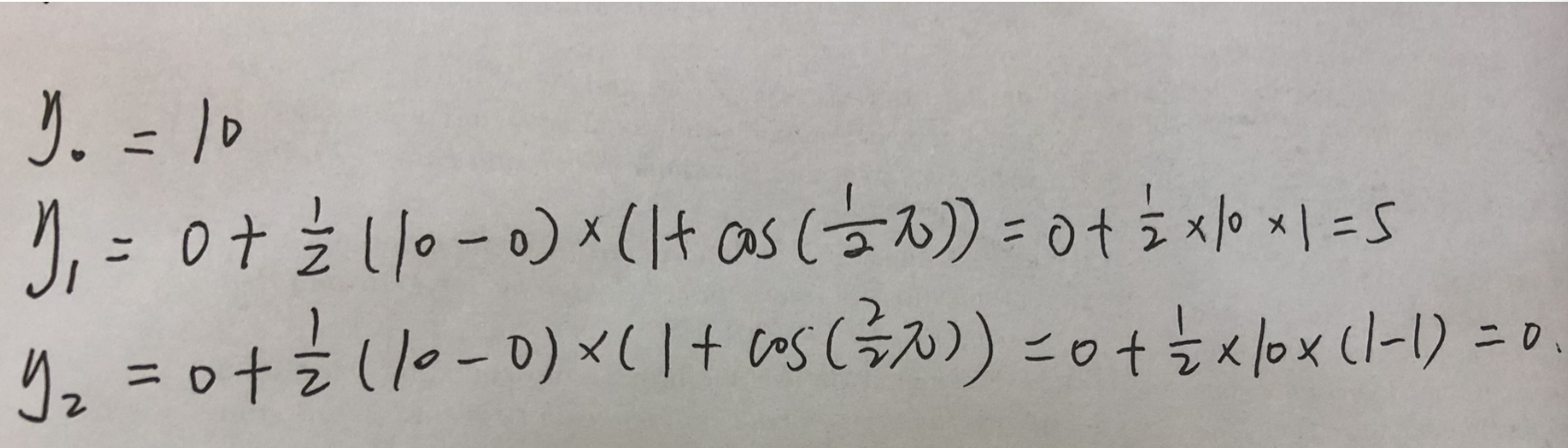
6.ReduceLROnPlateau(动态衰减lr)
CLASS torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=, min_lr=, eps=1e-)
torch.optim.lr_scheduler.ReduceLROnPlateau允许基于一些验证测量对学习率进行动态的下降
当评价指标停止改进时,降低学习率。一旦学习停滞不前,模型通常会从将学习率降低2-10倍中获益。这个调度器读取一个度量量,如果在“patience”时间内没有看到改进,那么学习率就会降低。
参数:
optimizer (Optimizer) – 封装的优化器
mode (str) – min, max两个模式中一个。在min模式下,当监测的数量停止下降时,lr会减少;在max模式下,当监视的数量停止增加时,它将减少。默认值:“分钟”。
factor (float) – 学习率衰减的乘数因子。new_lr = lr * factor. Default: 0.1.
patience (int) – 没有改善的迭代epoch数量,这之后学习率会降低。例如,如果patience = 2,那么我们将忽略前2个没有改善的epoch,如果loss仍然没有改善,那么我们只会在第3个epoch之后降低LR。Default:10。
verbose (bool) – 如果为真,则为每次更新打印一条消息到stdout. Default:
False.threshold (float) – 阈值,为衡量新的最优值,只关注显著变化. Default: 1e-4.
threshold_mode (str) – rel, abs两个模式中一个. 在rel模式的“max”模式下的计算公式为dynamic_threshold = best * (1 + threshold),或在“min”模式下的公式为best * (1 - threshold)。在abs模式下的“max”模式下的计算公式为dynamic_threshold = best + threshold,在“min”模式下的公式为的best - threshold. Default: ‘rel’.
cooldown (int) – 减少lr后恢复正常操作前等待的时间间隔. Default: 0.
min_lr (float or list) – 标量或标量列表。所有参数组或每组的学习率的下界. Default: 0.
eps (float) – 作用于lr的最小衰减。如果新旧lr之间的差异小于eps,则忽略更新. Default: 1e-8.
举例:
import torchvision.models as models
import torch.nn as nn
model = models.resnet34(pretrained=True)
fc_features = model.fc.in_features
model.fc = nn.Linear(fc_features, )
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(params = model.parameters(), lr=)
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
inputs = torch.randn(,,,)
labels = torch.LongTensor([,,,])
plt.figure()
x = list(range())
y = [] for epoch in range():
optimizer.zero_grad()
outputs = model(inputs)
#print(outputs)
loss = criterion(outputs, labels)
print(loss)
loss.backward()
scheduler.step(loss)
optimizer.step() lr = optimizer.param_groups[]['lr']
print(epoch, lr)
y.append(lr) plt.plot(x,y)
监督loss,如果loss在patient=10的epoch中没有改进,那么lr就会衰减
返回:
tensor(0.7329, grad_fn=<NllLossBackward>) tensor(690.2101, grad_fn=<NllLossBackward>) tensor(2359.7373, grad_fn=<NllLossBackward>) tensor(., grad_fn=<NllLossBackward>) tensor(240161.7969, grad_fn=<NllLossBackward>) tensor(3476952.2500, grad_fn=<NllLossBackward>) tensor(5098666.5000, grad_fn=<NllLossBackward>) tensor(719.7433, grad_fn=<NllLossBackward>) tensor(6.7871, grad_fn=<NllLossBackward>) tensor(5.5356, grad_fn=<NllLossBackward>) tensor(4.2844, grad_fn=<NllLossBackward>) tensor(3.0342, grad_fn=<NllLossBackward>)
1.0
tensor(2.9092, grad_fn=<NllLossBackward>)
1.0
tensor(2.7843, grad_fn=<NllLossBackward>)
1.0
tensor(2.6593, grad_fn=<NllLossBackward>)
1.0
tensor(2.5343, grad_fn=<NllLossBackward>)
1.0
tensor(2.4093, grad_fn=<NllLossBackward>)
1.0
tensor(2.2844, grad_fn=<NllLossBackward>)
1.0
tensor(2.1595, grad_fn=<NllLossBackward>)
1.0
tensor(2.0346, grad_fn=<NllLossBackward>)
1.0
tensor(1.9099, grad_fn=<NllLossBackward>)
1.0
tensor(1.7853, grad_fn=<NllLossBackward>)
1.0
tensor(1.6610, grad_fn=<NllLossBackward>)
0.1
tensor(1.6486, grad_fn=<NllLossBackward>)
0.1
tensor(1.6362, grad_fn=<NllLossBackward>)
0.1
tensor(1.6238, grad_fn=<NllLossBackward>)
0.1
tensor(1.6114, grad_fn=<NllLossBackward>)
0.1
tensor(1.5990, grad_fn=<NllLossBackward>)
0.1
tensor(1.5866, grad_fn=<NllLossBackward>)
0.1
tensor(1.5743, grad_fn=<NllLossBackward>)
0.1
tensor(1.5619, grad_fn=<NllLossBackward>)
0.1
tensor(1.5496, grad_fn=<NllLossBackward>)
0.1
tensor(1.5372, grad_fn=<NllLossBackward>)
0.1
tensor(1.5249, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5236, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5224, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5212, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5199, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5187, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5175, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5163, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5150, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5138, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5126, grad_fn=<NllLossBackward>)
0.010000000000000002
tensor(1.5113, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5112, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5111, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5110, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5108, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5107, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5106, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5105, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5103, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5102, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5101, grad_fn=<NllLossBackward>)
0.0010000000000000002
tensor(1.5100, grad_fn=<NllLossBackward>)
0.00010000000000000003
tensor(1.5100, grad_fn=<NllLossBackward>)
0.00010000000000000003
tensor(1.5099, grad_fn=<NllLossBackward>)
0.00010000000000000003
tensor(1.5099, grad_fn=<NllLossBackward>)
0.00010000000000000003
tensor(1.5099, grad_fn=<NllLossBackward>)
0.00010000000000000003
第一个loss为0.7329,一直向后的patient=10的10个epoch中都没有loss小于它,所以根据mode='min',lr = lr*factor=lr * 0.1,所以lr从10变为了1.0
如图:
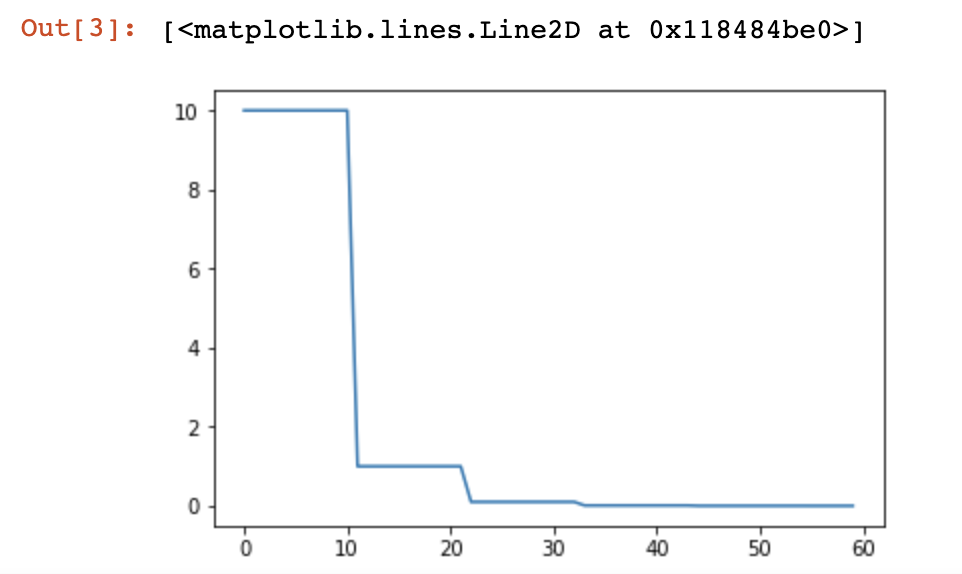
⚠️该函数没有get_lr(),所以使用optimizer.param_groups[0]['lr']得到当前的学习率
7.CyclicLR
CLASS torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr, max_lr, step_size_up=, step_size_down=None, mode='triangular', gamma=1.0, scale_fn=None, scale_mode='cycle', cycle_momentum=True, base_momentum=0.8, max_momentum=0.9, last_epoch=-)
根据循环学习速率策略(CLR)设置各参数组的学习速率。该策略以恒定的频率循环两个边界之间的学习率,论文 Cyclical Learning Rates for Training Neural Networks中进行详细介绍。两个边界之间的距离可以按每次迭代或每次循环进行缩放。
循环学习率策略会在每批batch数据之后改变学习率。该类的step()函数应在使用批处理进行训练后调用。
该类有三个内置策略:
- “triangular”:一个基本的三角形周期w,无振幅缩放
- “triangular2”:一种基本的三角形周期,每个周期的初始振幅乘以一半。
- “exp_range”:在每次循环迭代时,初始振幅按**(循环迭代)缩放的循环。
- This implementation was adapted from the github repo: bckenstler/CLR
- 参数:
optimizer (Optimizer) – 封装的优化器
max_lr (float or list) – 各参数组在循环中的学习率上限。在功能上,它定义了周期振幅(max_lr - base_lr)。任意周期的lr是base_lr和振幅的某种比例的和;因此,根据缩放函数,实际上可能无法达到max_lr。
step_size_up (int) – 在周期的上升部分中,训练迭代的次数. Default: 2000
step_size_down (int) – 在一个周期的下降部分的训练迭代次数。如果step_size_down为None,则将其设置为step_size_up. Default: None
mode (str) – {triangular, triangular2, exp_range}三个模式之一.值对应于上面详细说明的策略。如果scale_fn不为None,则忽略该参数. Default: ‘triangular’
gamma (float) – 在' exp_range '缩放函数中的常量 :计算公式为gamma**(循环迭代)。Default: 1.0
scale_fn (function) – 由一个参数lambda函数定义的自定义缩放策略,其中对于所有x >= 0, 0 <= scale_fn(x) <= 1。如果指定,则忽略“mode”. Default: None
scale_mode (str) – {‘cycle’, ‘iterations’}.定义scale_fn是根据循环数计算还是根据循环迭代(从循环开始的训练迭代)计算. Default: ‘cycle’
cycle_momentum (bool) –
如果为True,momentum与“base_momentum”和“max_momentum”之间的学习率成反比。 . Default: Truebase_momentum (float or list) – 初始momentum是各参数组在周期中的下界. Default: 0.8
max_momentum (float or list) – 各参数组在周期中的最大momentum边界。在功能上,它定义了周期振幅(max_momentum - base_momentum)。任意周期的momentum等于最大动量与振幅的比例之差;因此,根据缩放函数,实际上可能无法达到base_momentum. Default: 0.9
last_epoch (int) – 最后一批batch的索引。此参数用于恢复训练工作。因为step()应该在每个批处理之后调用,而不是在每个epoch之后调用,所以这个数字表示计算的批处理总数,而不是计算的epoch总数。当last_epoch=-1时,调度将从头开始. Default: -1
举例:
出错:找不到CyclicLR,因为我1.0.1版本中没有这个类:
AttributeError: module 'torch.optim.lr_scheduler' has no attribute 'CyclicLR'
然后更新torch到最新版本1.1.0:
(deeplearning) userdeMBP:ageAndGender user$ pip install --upgrade torch torchvision
Collecting torch
...
Installing collected packages: torch
Found existing installation: torch 1.0..post2
Uninstalling torch-1.0..post2:
Successfully uninstalled torch-1.0..post2
Successfully installed torch-1.1.
然后又报错:
(deeplearning) userdeMBP:ageAndGender user$ python
Python 3.6. |Anaconda, Inc.| (default, Dec , ::)
[GCC 4.2. Compatible Clang 4.0. (tags/RELEASE_401/final)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
Traceback (most recent call last):
File "<stdin>", line , in <module>
File "/anaconda3/envs/deeplearning/lib/python3.6/site-packages/torch/__init__.py", line , in <module>
from torch._C import *
ImportError: dlopen(/anaconda3/envs/deeplearning/lib/python3./site-packages/torch/_C.cpython-36m-darwin.so, ): Library not loaded: /usr/local/opt/libomp/lib/libomp.dylib
Referenced from: /anaconda3/envs/deeplearning/lib/python3./site-packages/torch/lib/libshm.dylib
Reason: image not found
>>>
没能解决这个问题,小伙伴有解决了的希望能告知
该类详情可见https://blog.csdn.net/u013166817/article/details/86503899
pix2pix代码相关部分为:
def get_scheduler(optimizer, opt):
"""返回学习率调试器 Parameters:
optimizer -- 网络使用的优化器
opt (option class) -- 存储的所有的实验标记,需要是BaseOptions的子类
opt.lr_policy是学习率策略的名字,如: linear | step | plateau | cosine 对于'linear',对前<opt.niter>个迭代(默认为100)中我们保持相同的学习率,并在下面的<opt.niter_decay>个迭代(m默认为100)中线性衰减学习率到0
对于其他的调试器(step, plateau, and cosine),使用默认的pytorch配置
See https://pytorch.org/docs/stable/optim.html for more details.
"""
if opt.lr_policy == 'linear':
def lambda_rule(epoch): #epoch_count表示epoch开始的值,默认为1
lr_l = 1.0 - max(, epoch + opt.epoch_count - opt.niter) / float(opt.niter_decay + )
return lr_l
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda_rule)
elif opt.lr_policy == 'step':
scheduler = lr_scheduler.StepLR(optimizer, step_size=opt.lr_decay_iters, gamma=0.1)
elif opt.lr_policy == 'plateau':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.2, threshold=0.01, patience=)
elif opt.lr_policy == 'cosine':
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=opt.niter, eta_min=)
else:
return NotImplementedError('learning rate policy [%s] is not implemented', opt.lr_policy)
return scheduler
pytorch中的学习率调整函数的更多相关文章
- 【转载】 Pytorch中的学习率调整lr_scheduler,ReduceLROnPlateau
原文地址: https://blog.csdn.net/happyday_d/article/details/85267561 ------------------------------------ ...
- Pytorch中randn和rand函数的用法
Pytorch中randn和rand函数的用法 randn torch.randn(*sizes, out=None) → Tensor 返回一个包含了从标准正态分布中抽取的一组随机数的张量 size ...
- 【学习笔记】pytorch中squeeze()和unsqueeze()函数介绍
squeeze用来减少维度, unsqueeze用来增加维度 具体可见下方博客. pytorch中squeeze和unsqueeze
- Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析
backward函数 官方定义: torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph ...
- tensorflow中的学习率调整策略
通常为了模型能更好的收敛,随着训练的进行,希望能够减小学习率,以使得模型能够更好地收敛,找到loss最低的那个点. tensorflow中提供了多种学习率的调整方式.在https://www.tens ...
- pytorch中squeeze()和unsqueeze()函数介绍
一.unsqueeze()函数 1. 首先初始化一个a 可以看出a的维度为(2,3) 2. 在第二维增加一个维度,使其维度变为(2,1,3) 可以看出a的维度已经变为(2,1,3)了,同样如果需要在倒 ...
- Pytorch中的torch.cat()函数
cat是concatnate的意思:拼接,联系在一起. 先说cat( )的普通用法 如果我们有两个tensor是A和B,想把他们拼接在一起,需要如下操作: C = torch.cat( (A,B),0 ...
- pytorch中的torch.repeat()函数与numpy.tile()
repeat(*sizes) → Tensor Repeats this tensor along the specified dimensions. Unlike expand(), this fu ...
- 【转载】 PyTorch学习之六个学习率调整策略
原文地址: https://blog.csdn.net/shanglianlm/article/details/85143614 ----------------------------------- ...
随机推荐
- web开发常见的鉴权方式
结合网上找的资料整理了一下,以下是web开发中常见的鉴权方法: 预备:一些基本的知识 RBAC(Role-Based Access Control)基于角色的权限访问控制(参考下面①的连接) l ...
- linux网络编程之system v消息队列(一)
经过上次对于进程通讯的一些理论的认识之后,接下来会通过实验来进一步加深对进程通讯的认识,话不多说,进入正题: 其实还可以通过管道,但是,管道是基于字节流的,所以通常会将它称为流管道,数据与数据之间是没 ...
- Robot Framework--完整的接口测试用例
*** Settings *** Library Collections Library json Library requests Library RequestsLibrary Library H ...
- CentOS 6.5下快速搭建ftp服务器
来源:Linux社区 作者:Linux CentOS 6.5下快速搭建ftp服务器 1.用root 进入系统 2.使用命令 rpm -qa|grep vsftpd 查看系统是否安装了ftp,若安装了v ...
- JZOJ 5870 地图
直接解释题解,记录一下.
- 007_Python3 字符串
字符串是 Python 中最常用的数据类型.我们可以使用引号( ' 或 " )来创建字符串. 创建字符串很简单,只要为变量分配一个值即可. 例如: var1 = 'Hello World!' ...
- jQuery相关方法1
一.设置某个元素的标签内容------.html()方法 <script src="http://libs.baidu.com/jquery/1.10.2/jquery.min.js& ...
- selenium+chromeDriver配合使用(运行js脚本)
在python中调用selenium,访问百度,并运行js脚本爬取内容 python入口程序 from selenium import webdriver import time with open( ...
- 【概率论】5-6:正态分布(The Normal Distributions Part I)
title: [概率论]5-6:正态分布(The Normal Distributions Part I) categories: - Mathematic - Probability keyword ...
- 前端武器库系列之html后台管理页面布局
设计网页,让网页好看:网上找模板 搜 HTML模板 BootStrap 一.页面布局之主站页面 主站布局一般不占满页面,分为菜单栏.主页面.底部 上中下三部分.伪代码如下: <div class ...