计算广告(4)----搜索广告召回(也叫match、触发)
一、搜索广告形态
1、特征工程
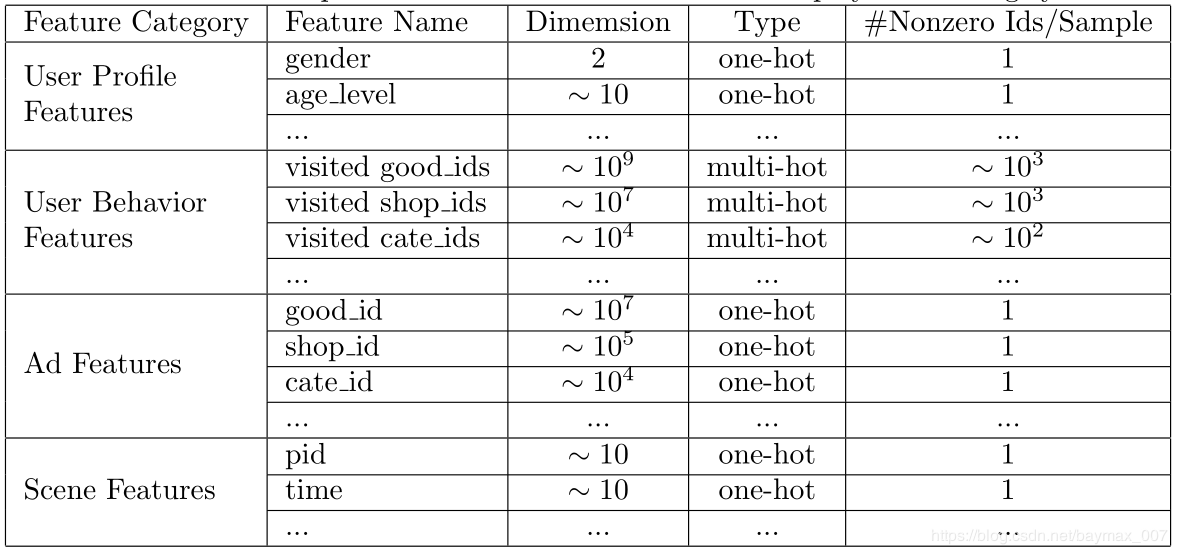
特征主要有用户画像(user profile)、用户行为(user behavior)、广告(ad)和上下文(context)四部分组成,如下所示:
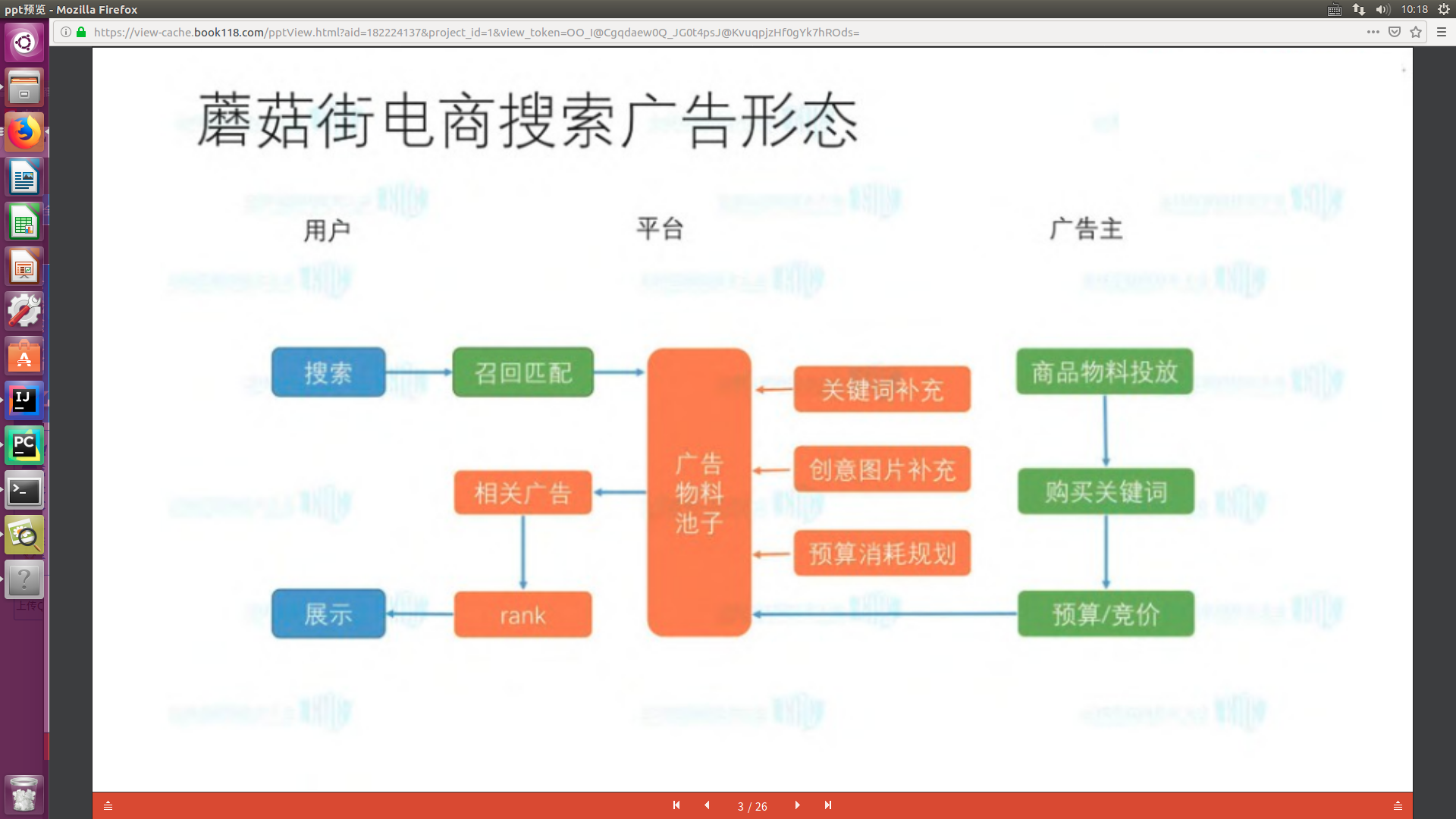
2、平台算法主要分三部分:召回匹配 + 推荐排序 + 广告展示
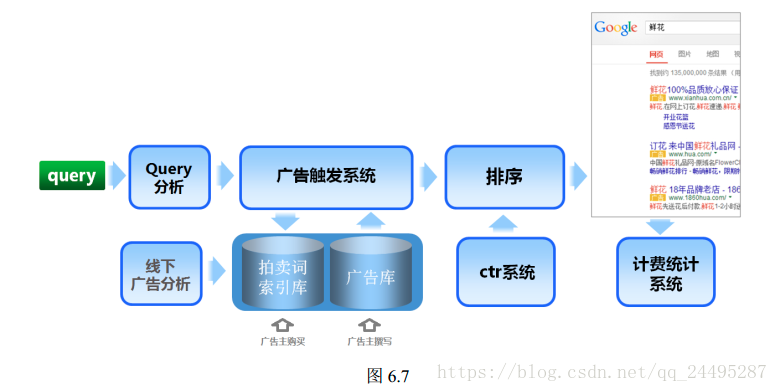
https://zhuanlan.zhihu.com/p/28390635
不同的运营平台会提供给商家后台采买关键词,设置出价和匹配模式等。当用户发起搜索时,根据规则,首先召回采买关键词的商家,然后对这些召回商家排序,返回广告商家。
一般来说,这类广告的收费模式都是按照点击收费(CPC),所以排序肯定不能按照单纯的价高者得。因为即使商家出价再高,但是由于相关度和商家质量问题,而无人点击,平台依然没有任何营收,既浪费了平台流量,也没有给商家贡献转化。普遍来说,对于CPC广告,排序一般基于商户出价Bid * 预估CTR(点击率)。排序在计算广告中占据着举足轻重的地位,提高AUC,CTR等指标,也让无数青年才俊掉了不少头发。不过排序并不是本文介绍的重点,如果你感兴趣,可以搜索LR,GBDT,FM,OCPC等关键词,相信你会有很多的收获。
(1)召回匹配:
扩触发(即多路召回):搜索重定向(上下文)、TDM召回、高CTR
- query 分析
- query重写
- ad summary
- learning to match
(2)推荐排序:CTR预估。
(3)广告展示:智能创意优化【广告配图(图案增强等)、静态动态文案生成(文案融合)、样式橱窗优化、信息流等】
3、效果衡量:
收入、点击/转化率、ecpm
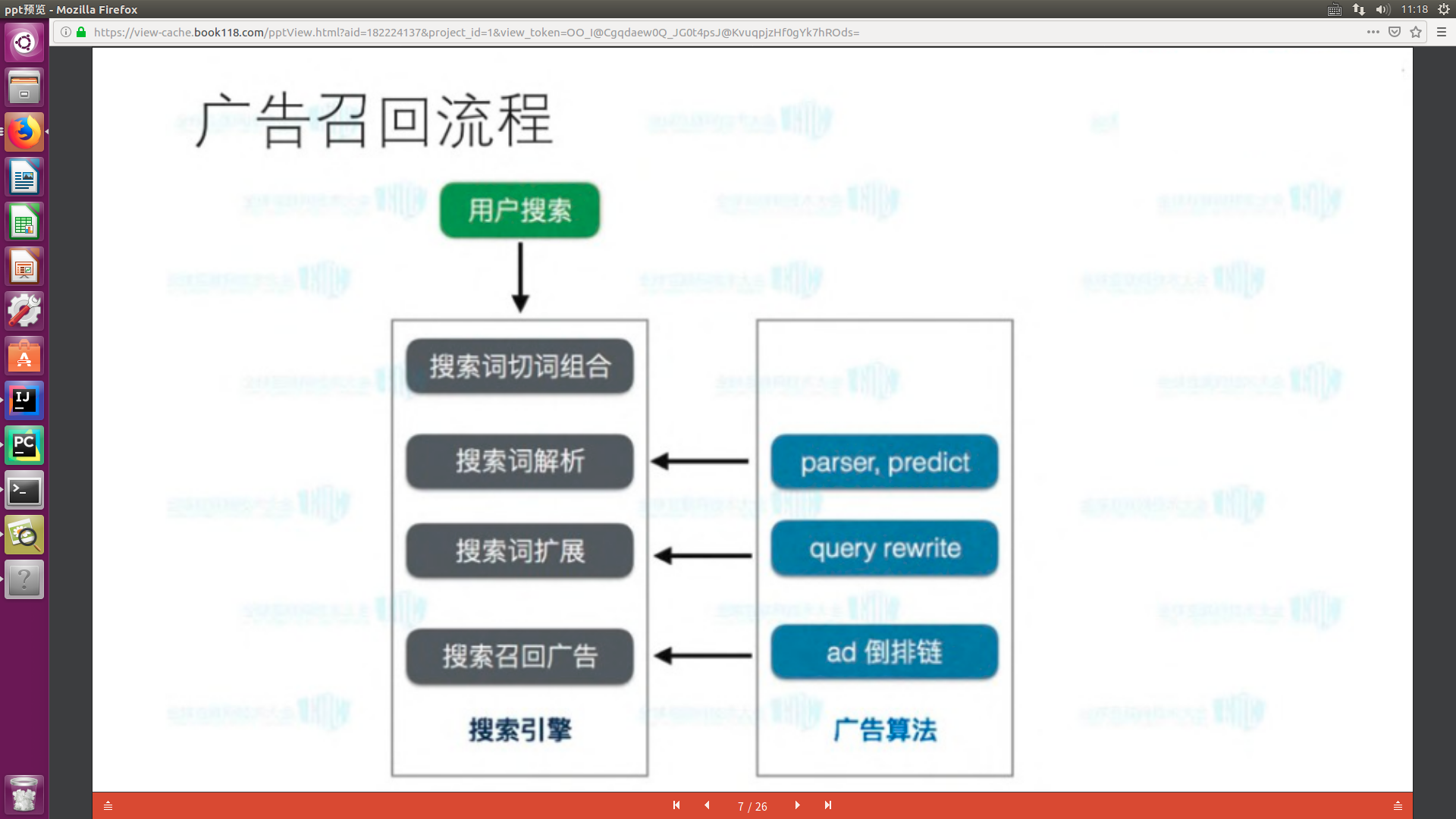
二、广告召回流程:
拿搜索引擎类比,一个道理
比如搜:北京大学
有三个网页被搜索到了:
a. 北京大学保安考上研究生
b. 北京互联网工作招聘
c. 大学生活是什么样的
其中只有a是被正确搜索到的,其他两个其实是和用户搜索词无关,而事实上数据库里还有这种网页:
d. 北大开学季
e. 未名湖的景色
这两个没被搜索到,但d、e和“北京大学”的相关度是超过b、c的,也就是应该被搜索(被召回)到的却没有显示在结果里,即:
召回率 = (a)/ (a + d + e)
1、用户query意图识别
任务:
(1)任务1:解析短语结构,关键词(sub query)等
(2)任务2:明确用户搜索商品类目(category)
query特征:
(1)query存在季节周期性
……
query的商品类预测:
click 数据log:query------商品类别(category)
统计数据:query-----subQuery------category distribution------Top category
预测类别:query-----phrase representation------softmax预测
例子:
query:裙子套装、苹果充电器、波西米亚连衣裙
类目:套装、数码电器、裙子
2、query重写



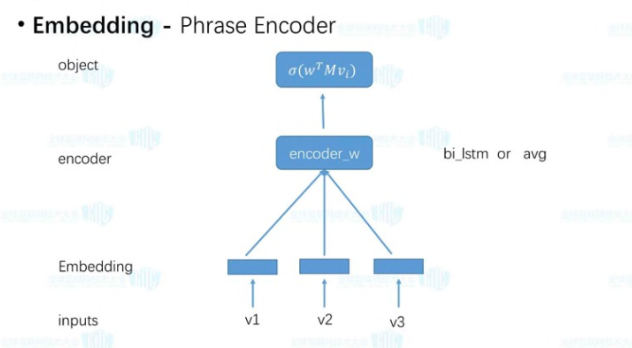

3、Ad summary


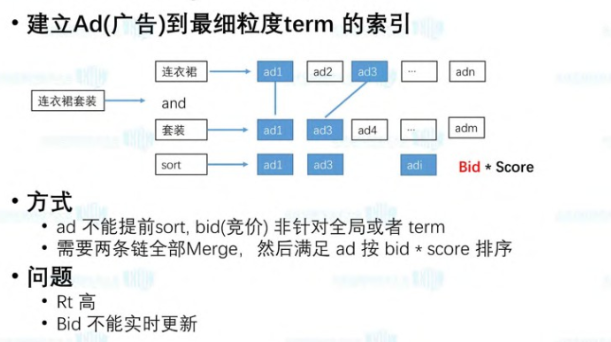
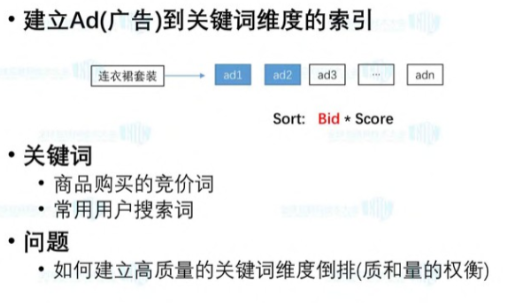
Ad 索引:
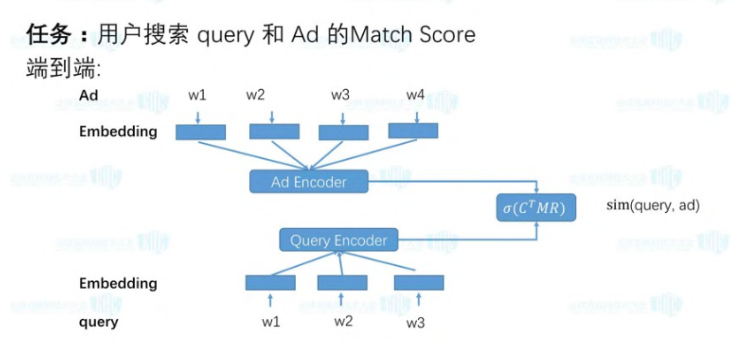
4、召回匹配



三、广告召回算法(基于邻域,基于内容,基于神经网络)
基于邻域(LFM,CF,Personal Rank)
1.1 CF 协同过滤
协同过滤算法分为 基于用户 和 基于tiem 两种情况。整体思路是从历史日志中找到商品或用户的相似度进而对用户进行推荐。上述所提到的相似性度量方法,在机器学习中往往 距离 和 相似性 是比较 相关 的概念,一般距离越大则相似性越低,反之相似性越高。度量距离的方式有很多,例如:person相关系数,余弦相似度,jaccard相似系数等。任何一种度量方式都可以应用到协同过滤中的相似性度量中。
1.1.1 基于用户的相似性度量,通过以item作为连接不同用户的桥梁,构建用户-【tiem序列】的表示,最终计算用户的相似度到达推荐的目的。
1.1.2 基于item的相似度度量,通过以用户作为连接不同item的桥梁,构建item-【用户序列】的表示,最终计算商品的相似度达到推荐的目的。
这两种方式的计算方法本质上的思路是类似的,但是鉴于不同场景下,两种方式各有优劣。基于item的协同过滤方式可以发现长尾商品并可以达到较好的个性化需求。1.2 LFM 隐变量的推荐模型
通过对用户-item的打分矩阵,通过打分矩阵,可以只管的观察到用户对item的评价,这里假设评价的本身是用户对于item的某些属性例如:价格,颜色等的综合评价后,给出的最后得到,这里的某些属性可以理解为隐变量,基于该思想,可以将打分矩阵A分解为V和U两个矩阵的乘积表示,物理意义可以理解为 商品-商品的属性 和 用户-商品属性 的偏爱。
现在,通过对打分矩阵的分解,引入 隐变量
的概念,而隐变量的具体数据是多少,需要根据具体的场景决策。LFM算法完成推荐的同时可以得到用户和item的向量表示,通过LFM算法,可以得到1).给用户推荐的item列表;2).item的相似度矩阵;3).计算用户的相似度等。
具体如何求解两个隐向量U,V,通过利用梯度下降的方式便可求解。1.3 基于图的推荐
用户的关系可以描述为二分图表示,因此可以利用随机游走算法得到不同node之间的关系。物理意义的解释:在二分图中,两个顶点之间的连同路径越多则两个顶点的关联可能性越大;两个顶点之间的连同路径越短则关联可能性越大;两个顶点之间的连同路径经过的顶点出度和越小,则越可能关联。
基于物理意义的含义,这里通过随机游走算法,计算不同定点之间的值,以最终的值最为推荐的依据。基于内容
将item表示成一个features向量,如电影的features向量可以是<author, title, actor, director, ...>对应的boolean或者value的数值向量。
通过用户评分过(或者有过互动如观看)的item的profiles构建用户的profiles。
通过距离计算方式度量用户和item的相似度。
该种方式对于新的item可以直接计算与其他的item的相似性,由于计算相似性只依赖于item的基本属性,不依赖于用户对其的打分。对于CF中相似性较低的用户,也可以通过基于内容的方式达到推荐的目的。但是对于新用户的冷启动问题无法刻画用户,便无法计算相似性也无交互历史,无法推荐。对于用户对于某类型的item,例如特定属性的item没有交互,则该item就算是热门商品,也不会推荐给当前用户。基于神经网络(item2vec)
基于神经网络的方式基本通过利用word2vec的思想。利用神经网络在特征抽象表示能力的优势,通过神经网络对item进行表示。基本思路,对于用户的行为序列进行表示,通过word2vec方法训练,得到最终的item表示。通过论文的结论,利用item2ve的方法训练得到的item向量,其时序性表达缺失且item的点击强度无法表达等缺点。

第一,更全面的行为表达。在模型中结合点击、收藏、搜索等多种行为,能更全面地表示用户行为偏好。
第二,可添加画像特征,可加入性别、地域等用户画像相关的特征。如果你有额外的一些标签或发生的信息,这个模型是可以兼容的,它可以把所有信息糅杂在同一模型里面去做,而在协同过滤模型里面是完全无法引入的。
第三,考虑用户的行为顺序。比如用户通常的行为顺序是,先买一个手机,然后再去买一个手机壳;买了一个汽车后可能会买个汽车坐垫。
第四,组合复杂特征。神经网络可以进行更复杂的特征组合,挖掘更深层次的关联关系。
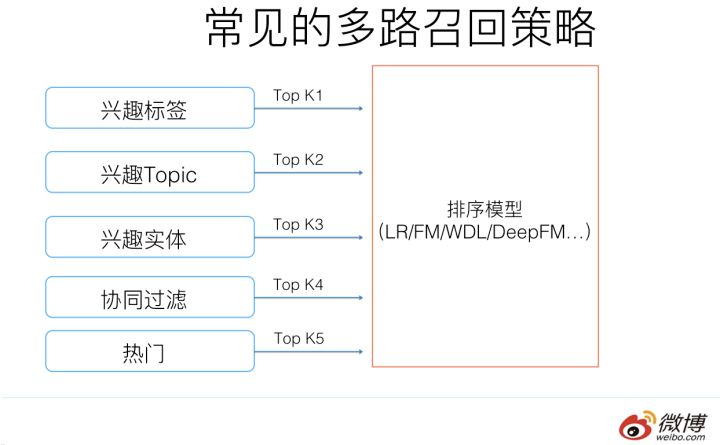
四、多路召回
https://www.sensorsdata.cn/blog/20190312/
https://zhuanlan.zhihu.com/p/59528983
不同业务场景基本包括:基于topic(tag)的召回、实体的召回、地域的召回、CF(协同过滤)的召回以及NN产生的embedding召回、热门召回
基于行为、基于用户画像、冷启动&多样性、多源数据
Youtube DNN召回、DSSM语义召回、RNN序列召回、TDM深度树匹配召回
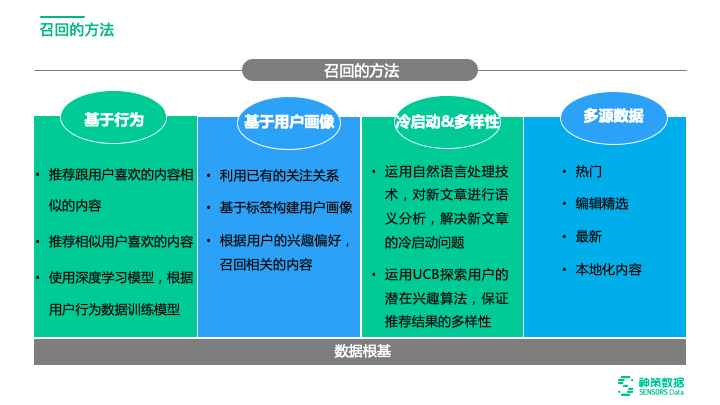
1、基于用户行为分析的召回
协同过滤:市场上熟知的基于用户行为分析的召回主要通过以下两种思路:
1.基于内容的协同过滤(ItemCF)
2.基于用户的协同过滤(userCF)
深度学习:基于行为的深度学习召回模型,再根据用户行为数据训练模型,加强了推荐系统推荐的智能性和准确性。如谷歌的DNN
2、基于用户画像的召回
1.利用已有的关注关系(相似商品贴标签)
关注关系就是用户显性化的喜爱偏好。用户的每次浏览、每次点击、每次填写、每次搜索都隐藏了你的用户偏好。如下图,当用户的站内搜索、浏览页面、点击标签、点击按钮等行为的数据都能抓到并进行分析,就能做到给用户的内容更逼近其心中所想和心中所爱。
2.基于标签构建用户画像(用户贴标签)
不同性别、年龄、职业、地区的用户对内容的兴趣偏好有所不同,即使同一性别、年龄、职业的偏好也有很大差异,所谓千人千面,每个用户都有其特征和偏好。因此,很多企业都有自身的标签平台,如纵横小说会根据用户行为数据结合内容标签,构建用户画像标签,通过这种方式召回用户感兴趣的内容。
3、保障推荐的有效冷启动和推荐多样性的方法
推荐系统的冷启动场景主要分为三类:
用户冷启动:即如何给新用户做个性化推荐,事实上,第一次展现给用户的 item 极其重要,决定了用户的第一印象;
内容冷启动:即如何将新的内容推荐给潜在对它感兴趣的用户;
系统冷启动:即如何在一个新开发的产品中(无用户、无用户行为,只有一些内容)设计个性化推荐,从而在产品刚发布就让用户体验到个性化推荐服务。
1.运用自然语言处理技术,解决内容冷启动问题
关于冷启动,神策智能推荐,会运用自然语言处理技术对新的内容进行语义分析,我们可以这样理解,市面上很多都是文本数据的一些“显式”使用方法,包括在前面介绍的标签也是,所谓显式,是指我们将可读可理解的文本本身作为了相关性计算、召回以及模型排序的特征。这样做的优势是能够清晰地看到起作用的是什么,但是其劣势是无法捕捉到隐藏在文本表面之下的深层次信息。例如,“衣服”和“上衣”指的是类似的东西,“厚外套”和“棉服”具有很强的相关性,类似这样的深层次信息,是显式的文本处理所无法捕捉的,因此我们需要一些更复杂的方法来捕捉,而自然语言处理技术就能捕捉到,运用从词下沉到主题的思路,挖掘更深层次的核心信息。
神策智能推荐运用自然语言处理技术——基于神经网络的文本语义分析模型(如下图),相比市面上通过打标签的方式推荐,可以做到更深层次的偏好挖掘推荐,举个例子,如果用户阅读了大量包含甄子丹、成龙、李小龙等关键词的文章,可以挖掘出用户对功夫类主题的内容偏好,并为其推荐。
2.运用 UCB 探索用户的潜在兴趣算法,保证推荐结果的多样性
在推荐的过程中,需要考虑给新 item 展示的机会,比如给一个喜欢历史分类资讯的用户推荐一些娱乐、政治等其他资讯,解决加强推荐多样性的问题。
大家所熟知的是通过随机分配一部分流量给新 item 曝光,得到一些反馈,然后模型才能对其有较好的建模能力,这是比较传统的冷启动套路。
神策智能推荐采用的是 upperconfidence bound(UCB) 策略: 假设有 K 个新 item 没有任何先验,每个 item 的回报也完全不知道。每个 item 的回报均值都有个置信区间,而随着试验次数增加,置信区间会变窄,对应的是最大置信边界向均值靠拢。如果每次投放时,我们选择置信区间上限最大的那个,则就是 UCB 策略。这个策略主要是通过以下两个原理达成更好地推荐:均值差不多时,优先给统计不那么充分的资讯多些曝光;均值有差异时,优先出效果好的。
4、根据多源数据召回,保障推荐的全面性和精准性
企业产生数据的方式多种多样,推荐系统的个性化精准推荐,离不开对业务和用户的精准把控,只有获取足够全面、颗粒度足够细的数据才能更精准的了解用户。神策智能推荐支持企业结合业务角度和时事热点等多方面,利用多种数据源的整合与综合分析,如支持将热门、编辑精选、最新、本地化内容等多类数据进行综合,吸取不同数据源的特点,并将这些内容放入到候选集里,为排序提供足够全面且详尽的内容。
比如,某个资讯类 APP 的编辑会在热门流中精选出部分内容,形成一个精选内容集,就是一个精选出来的数据源,可将其放入候选集中,再次推荐增加曝光。再比如,当出了某些热门事件,资讯类 APP 就可以通过编辑打标签、手动筛选或通过某个简单的程序抓取相关的内容,将其归为一类放入内容池,再经过一系列操作后进行推荐。
https://max.book118.com/html/2018/0830/7056052031001145.shtm
搜索引擎:https://blog.csdn.net/poson/article/category/384665
文本上的算法读书笔记六--搜索引擎:https://blog.csdn.net/qq_24495287/article/details/83038312
Facebook:FastText 理解和在query意图识别的应用:https://blog.csdn.net/hero_fantao/article/details/69487744
计算广告(4)----搜索广告召回(也叫match、触发)的更多相关文章
- 【项目】百度搜索广告CTR预估
-------倒叙查看本文. 6,用auc对测试的结果进行评估: auc代码如下: #!/usr/bin/env python import sys def auc(labels,predicted_ ...
- 【项目】搜索广告CTR预估(二)
项目介绍 给定查询和用户信息后预测广告点击率 搜索广告是近年来互联网的主流营收来源之一.在搜索广告背后,一个关键技术就是点击率预测-----pCTR(predict the click-through ...
- 苹果搜索广告后台大揭秘,最全最细致详解,手把手设置教程「后附官方视频」-b
WWDC2016 搜索广告分会视频和 PPT 发布了,ASO100 带开发者第一时间了解 Search Ads 后台设置(文末有原声视频). 首先介绍一下搜索广告的模式和竞价规则 广告模式为 CPT( ...
- 搜索广告与广告网络Demand技术-搜索广告
搜索广告 搜索广告就是一个典型的Ad Network,但是搜索广告非常重要,它的收入非常高,所以它有其独特之处,复杂度也比展示广告要高.它与展示广告在点击率预测,检索部分差不多,它的特点:1. 用户定 ...
- 搜索广告与广告网络Demand技术-探索与利用
探索与利用(Explore and exploit) 点击率预测中还有一个重要的问题,就是探索与利用,它在工程中解决的并不好,我这章把现在论文中的常见的几种方法介绍一下.探索与利用它是所有互联网应用都 ...
- 教你编写百度搜索广告过滤的chrome插件
1 前言 目前百度搜索列表首页里,广告5条正常内容是10条,而且广告都是前1到5条的位置,与正常内容的显示样式无异.对于我们这样有能力的开发者,其实可以简单的实现一个chrome插件,在百度搜索页面里 ...
- [译]Facebook广告基础--数字广告指南
广告商指南 原文链接:https://www.facebook.com/business/help/337584869654348/ Ads Help - Desktop > Learn Abo ...
- Google自动广告,将广告代码放置在 HTML 中的什么位置?
Google自动广告,将广告代码放置在 HTML 中的什么位置? 为自动广告生成广告代码后,您需要将此代码放置在要展示广告的每个网页中.您应将广告代码放置在网页的 <head> 标记(或正 ...
- 搜索广告与广告网络Demand技术-流式计算平台
流式计算平台-Storm 我们以Storm为例来看流式计算的功能是什么. 下面内容引用自大圆的博客.在Storm中,一个实时应用的计算任务被打包作为Topology发布,这同Hadoop的MapRed ...
随机推荐
- 高级UI-RecyclerView间隔线添加
上文讲到了RecyclerView的简单使用,知道RecycleView是怎么使用的了,那么这一节将基于上一届的内容继续改进,在ListView中很轻松就能实现的间隔线,在RecycleView中也需 ...
- tomcat性能优化参数
线上环境使用默认tomcat配置文件,性能很一般,为了满足大量用户的访问,需要对tomcat进行参数性能优化,具体优化的地方如下: Linux内核的优化 服务器资源JVM 配置的优化 Tomcat参数 ...
- 【leetcode算法-中等】3. 无重复字符的最长字串
[题目描述] 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度. 示例 1: 输入: "abcabcbb"输出: 3 解释: 因为无重复字符的最长子串是 " ...
- Hadoop Join
1. Reduce Join工作原理 Map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录.然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输 ...
- VC++:创建,调用Win32静态链接库
概述 DLL(Dynamic Linkable Library)动态链接库,Dll可以看作一种仓库,仓库中包含了可以直接使用的变量,函数或类. 仓库的发展史经历了"无库" ---& ...
- 剑指offer15:反转链表后,输出新链表的表头。
1 题目描述 输入一个链表,反转链表后,输出新链表的表头. 2 思路和方法 (1)利用栈作为中间存储,进行链表的反转,将压入的数据按先进后出的顺序弹出依次赋给链表再输出表头pHead. (2)将当前节 ...
- 通过jquery触发select自身的change事件
###通过jquery触发select自身的change事件 1.通过js来去触发select的change事件 代码如下:包含了html部分和js部分 //html部分 <select cla ...
- 100天搞定机器学习|Day4-6 逻辑回归
逻辑回归avik-jain介绍的不是特别详细,下面再唠叨一遍这个算法. 1.模型 在分类问题中,比如判断邮件是否为垃圾邮件,判断肿瘤是否为阳性,目标变量是离散的,只有两种取值,通常会编码为0和1.假设 ...
- element-ui 合并单元格的方法
arraySpanMethod({ row, column, rowIndex, columnIndex }) { // 只合并区域位置 //columnIndex 横的第一列 ...
- electron窗口相关操作(放大缩小退出,可拖动,可resize等)
如下是对窗口最大化,最小化等相关操作: import { ipcMain, ipcRenderer, remote } from 'electron' import is from 'electron ...