软件测试第4周小组作业:WordCount优化
一、基本任务:代码编写+单元测试
1、Github地址:
https://github.com/Wegnery/New_WordCount
2、PSP2.1表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
5 | 5 |
|
· Estimate |
· 估计这个任务需要多少时间 |
5 | 5 |
|
Development |
开发 |
235 | 340 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
15 | 30 |
|
· Design Spec |
· 生成设计文档 |
—— | —— |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
—— | —— |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 | 10 |
|
· Design |
· 具体设计 |
30 | 30 |
|
· Coding |
· 具体编码 |
120 | 180 |
|
· Code Review |
· 代码复审 |
30 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
30 | 60 |
|
Reporting |
报告 |
45 | 45 |
|
· Test Report |
· 测试报告 |
30 | 30 |
|
· Size Measurement |
· 计算工作量 |
5 | 5 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 | 10 |
|
合计 |
285 | 390 |
2、对接口的实现
我负责输入控制模块,概况如下:
- 一个类:Input.class
- 实现功能:1.识别.txt文件,读入 2.判定合法输入与不合法输入
- 一个函数:Vector<String> InputManage(String[] args)
- 输入:main函数的String[] args,即命令行中输入的文件名;输出:一个Vector,包含文件中的所有单词。
实现步骤分为两步:
(1)、第一步对命令行输入的文件名字符串进行处理,识别是否是有效的txt并给出提示,考虑了如下几种情况:
a.一次仅处理一个文件:若用空格隔开输入多个文件名,仅处理第一个,即args数组第一个元素args[0],并会提示输入了多个文件。
//一次仅处理一个文件,不同时处理多个文件。有多个文件时输出提示
if(args.length >= 2)
{
System.out.println("输入了不止一个文件,仅处理第一个文件");
}
b.通过Pattern匹配正则表达式判断是否是.txt,不是则输出提示并退出程序。
//判断输入的是否是txt文件,是则打开并提取单词
if (Pattern.matches(".*\\.txt", args[0]))
{ }
else
{
System.out.println("输入的不是txt文件");
System.exit(1);
}
c.IOException含有‘系统找不到文件’提示,故未写
d.对文件中有无单词的判断写在main函数里
(2)第二步对文件中的内容提取单词
当if判断输入的是txt文件,则打开文件并提取单词,以下代码为提取单词部分。
按照作业要求中判断单词的两个条件运用正则表达式匹配进行提取,
“[A-Za-z]+-?[A-Za-z]+”为0或1个“-”前后有1或多个英文字母,考虑到“这种情况night-,带短横线的单词,视为1个单词,即night。”
“[A-Za-z]”为只有一个字母的时候的补充,因为上式最少情况下有两个字母。
因为是按照条件直接抽取的单词,不是像第二周一样根据分隔符用spilt()方法划分单词,数字和常见字符就不需考虑在内。
//文件内容以行为单位提取单词
while((line = br.readLine()) != null)
{
line = line.toLowerCase();//大写转换成小写
String regex = "[A-Za-z]+-?[A-Za-z]+|[A-Za-z]";//提取含-或者不含的单词的正则表达式
Pattern pattern=Pattern.compile(regex);//将正则表达式转为pattern
Matcher ma=pattern.matcher(line);//与每行文本进行匹配
while(ma.find())
{
words.addElement(ma.group());//将每个单词加入words向量
}
}
4、测试用例设计
采用黑盒测试的等价类划分设计测试用例,分为两大类,一类是对文件读取错误时会产生的提示的测试,一类是对含不同字符的文本进行单词提取的结果。因为宁宁已经对第一类测试用例进行了设计,所以我仅对第二类进行设计,对易产生问题的规定的常见字符都覆盖了进去,字母和数字挑选了部分,提高测试效率。以下为例子,全部20个测试用例在github的“测试用例.xlsx”文件里。
5、单元测试运行
挑选了其中十个测试用例进行运行。因不知道如何将被测单元的控制台输出重定向进行对比,所以没有测试第一类是对文件读取错误时产生的提示,仅测试了第二类对单词的提取。人工对第一类进行测试也出现了一些问题,如发现对文件名参数处理的部分,若用户输入时用空格隔开多个文件名且第一个文件不是txt,第二个文件是txt,由于只处理args[0],会提示输入的不是txt。若用其他字符隔开多个文件名则一同被存进args[0],则会提示系统找不到文件,这都是考虑有所欠缺的地方。所以测试质量和被测模块的质量均有待改进。

二、扩展任务:静态测试
所有小组成员已经完成扩展功能。
1、开发规范文档
采用的邹欣老师的讲义“现代软件工程讲义 3 代码规范与代码复审”
2、对组员代码的分析
分析了组员17010的代码。
首先她的优点是,每行代码都有良好的注释说明,缩进也很工整,读起来简明易懂。
缺点有如下几条:
- 开头和结尾有注释掉的编写代码时测试用的main函数和打印函数,应该在完成提交时删掉。
- 类名和函数名首字母没有大写。
- 大括号没有每个占一行,复杂的条件表达式中,逻辑优先级容易不清晰。
- 对变量的命名不够直观。
3、静态代码审查工具
运用的工具是FindBugs,IDEA插件中安装的,安装方法如:https://blog.csdn.net/fancy_xty/article/details/51718687
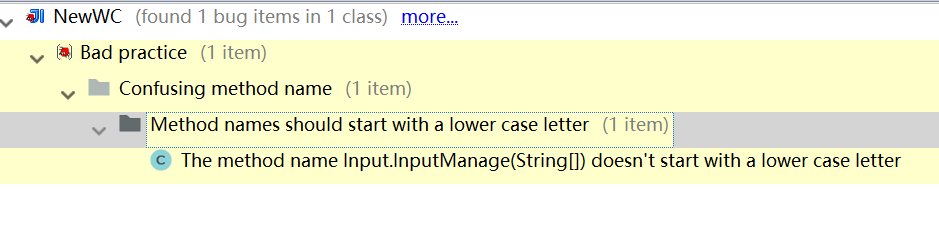
4、扫描结果
发现了一个问题:函数名首字母应该是小写。但是根据邹欣老师的代码规范,所有的类型/类/函数名都用Pascal形式,即所有单词的第一个字母都大写。
我遵循了类名和函数名首字母都大写,大括号每个占一行。
5、小组存在的问题
经过审查,发现整个小组大部分存在以下问题:
- 开头和结尾有注释掉的编写代码时测试用的main函数和打印函数,应该在完成提交时删掉。
- 无用的import没有及时删除。
- 类名和函数名首字母没有大写。
- 大括号没有每个占一行,复杂的条件表达式中,逻辑优先级容易不清晰。
- 对变量的命名不够直观。
三、高级功能
所有小组成员均完成高级功能
1、测试数据集的设计思路
采用了两种类型的数据测试集:
- 一是选取的较长的英文小说的txt,我们选取的是冰与火之歌Game of Thrones,大小为2.26 MB,含有2,375,616 字节。
- 二是自己用代码编写的用规定字符(英文字母、数字、常见字符)随机生成的不同大小的txt,生成了长度分别为10万字节,大小为98 KB和100万字节,991 KB的txt。
2、程序性能指标
3、同行评审
- 主持人:宁宁17009
- 评审员:宁宁17009、朱全17031、周雨贝17011
- 作者:宁宁17009,朱全17031,周雨贝17011,易成龙17020
- 讲解员:易成龙17020
- 记录员:易成龙17020
- 输入文件大小
- 输入文件中包含特殊字符比例
- 输入文件中包含由空格隔开的字符串数量
- 排序时所采用的算法是否高效。
- 硬件制约因素如:磁盘I/O,CPU性能等。
- 单词重复率,TreeMap中是否有该单词,如果一个单词重复率很高,那每次在Treemap中找单词的时间并加一的时间要比直接添加到TreeMap中的时间长。
4、实际测试结论
5、总结
本次作业实践中,基本任务完成了软件开发和软件的动态测试,扩展功能完成对代码的静态测试,高级功能对性能进行测试和优化,进一步提高软件质量。
软件开发、软件测试、软件质量之间的关系应该是:
- 没有软件开发就没有测试,软件开发提供软件测试的对象。
- 软件开发和软件测试都是软件生命周期中的重要组成部分
- 软件测试是保证软件质量的重要手段。
6、小组贡献分:0.25
软件测试第4周小组作业:WordCount优化的更多相关文章
- HUST软测1504班第4周小组作业成绩:WordCount优化
说明 本次公布的成绩为第四周作业的结果: 第4周小组作业:WordCount优化 博客推荐:本次作业有一位同学完成有创意,推荐优秀博客.(优秀博客不会对成绩带来正面或者负面影响)PS:做任何创新的任务 ...
- HUST软测1504班第6周小组作业成绩
说明 本次公布的成绩为第6周小组作业的结果: 第6周小组作业:WordCount(详情见毕博平台) 如果同学对作业结果存在异议,可以: 在毕博平台讨论区的第6周作业第在线答疑区发帖申诉. 或直接在博客 ...
- 第4周小组作业:WordCount优化
Github项目地址:https://github.com/chaseMengdi/wcPro stage1:代码编写+单元测试 PSP表格 PSP2.1 PSP阶段 预估耗时(分钟) 实际耗时(分 ...
- 第四周小组作业:Wordcount优化
1.小组github地址 https://github.com/muzhailong/wcPro 2.PSP表格 PSP2.1 PSP阶段 预计耗时(分钟) 实际耗时(分钟) Planning 计划 ...
- 第六周小组作业 软件测试与评估:百词斩VS扇贝单词
被测产品说明: A:百词斩 B:扇贝单词 一.基本任务 1.测试进度表 | 项目 | 内容说明 | 预估耗时(分钟) | 实际耗时 (分钟) | | -------------- | -------- ...
- WordCount优化-第四周小组作业
一.基本功能 GITHUB项目地址:https://github.com/LongtermPartner/ExtendWordCount PSP表格填写: PSP2.1 PSP阶段 预估耗时 (分钟) ...
- 软件测试第2周个人作业:WordCount编码测试
一.Github地址 https://github.com/zhouyubei/WordCount 二.PSP表格 PSP2.1 PSP阶段 预估耗时 (分钟) 实际耗时 (分钟) Planning ...
- 软件测试第二周作业 WordCount
本人github地址: https://github.com/wenthehandsome23 psp阶段 预估耗时 (分钟) 实际耗时 (分钟) 计划 30 10 估计这个任务需要多少时间 20 ...
- WcPro项目(WordCount优化)
1 基本任务:代码编写+单元测试 1.1 项目GitHub地址 https://github.com/ReWr1te/WcPro 1.2 项目PSP表格 PSP2.1 PSP阶段 预估耗时(分钟) 实 ...
随机推荐
- np中的温故知新
1.一维数组中寻找与某个数最近的数 # 一维数组中寻找与某个数最近的数 Z=np.random.uniform(0,1,20) print("随机数组:\n",Z) z=0.5 m ...
- BZOJ 3772: 精神污染 (dfs序+树状数组)
跟 BZOJ 4009: [HNOI2015]接水果一样- CODE #include <set> #include <queue> #include <cctype&g ...
- CodeForces - 837E - Vasya's Function | Educational Codeforces Round 26
/* CodeForces - 837E - Vasya's Function [ 数论 ] | Educational Codeforces Round 26 题意: f(a, 0) = 0; f( ...
- boost 函数与回调
result_of 含义:result_of可以帮助程序员确定一个调用表达式的返回类型,主要用于泛型编程和其他boost库组件,它已经被纳入TR1 头文件:<boost/utility/resu ...
- vue-cli3构建多页面应用
创建一个项目hello-world vue create hello-worldcd hello-worldnpm run serve 在src目录下新建pages目录,在pages下新建页面 App ...
- HDU 3081 Marriage Match II 最大流OR二分匹配
Marriage Match IIHDU - 3081 题目大意:每个女孩子可以和没有与她或者是她的朋友有过争吵的男孩子交男朋友,现在玩一个游戏,每一轮每个女孩子都要交一个新的男朋友,问最多可以玩多少 ...
- Jenkins发布.Net Core项目到IIS
安装Java8,Git,和Jenkins及插件. jenkins安装后以windows服务的方式运行,浏览器访问本机8080端口可访问. 自动部署的原理分为三步,首先从git服务器获取最新代码,然后用 ...
- poj1737
Connected Graph POJ - 1737 An undirected graph is a set V of vertices and a set of E∈{V*V} edges.An ...
- Multiism四阶巴特沃兹低通滤波器的仿真实现
因为4阶巴特沃兹低通滤波器比较简单,所以省略设计过程和思路以及不必要的废话. 设计的滤波器的性能:截止频率大约是500HKZ,Rs = Rl = 32 欧姆. 预估滤波器大致的幅频特性曲线如下: 最初 ...
- 部署自己的聊天系统 DuckChat(鸭信)
之前在找一款能自己部署的聊天系统,要求含有手机端APP,最好部署过程能简单点的.看了几款稍嫌麻烦,有的还没有app.今天无意间发现了这款DuckChat,开源免费,有手机APP,部署非常简单.直接上传 ...