Movidius的深度学习入门
1.Ubuntu虚拟机上安装NC SDK
cd /home/shine/Downloads/
mkdir NC_SDK
git clone https://github.com/movidius/ncsdk.git
make install
通过运行测试例程判断是否正确安装
make examples
2.激活USB设备
在启动ubuntu前,请不要插入movidius,等ubuntu启动以后,再插入(知乎用户经验,笔者测试不影响)
3.测试工程
cd /home/shine/Downloads/NC_SDK/ncsdk/examples/apps/hello_ncs_cpp/
make run
cd /home/shine/Downloads/NC_SDK/ncsdk/examples/apps/hello_ncs_py/
make run
正常结果显示
Hello NCS! Device opened normally.
Goodbye NCS! Device Closed normally.
NCS device working.
4.训练工程
ncappzoo中提供了大量的工程样例提供分析,为开发者的模型选择提供了极大的便利,在选择模型的时候需要综合权衡训练样本的类型、大小以及部署后的运行速度。
cd /home/shine/Downloads/NC_SDK/ncsdk/
git clone https://github.com/ashwinvijayakumar/ncappzoo
git checkout dogsvscats
以猫和狗的分类任务为例
- 数据集的准备(在百度网盘中共享测试数据集和训练数据集)
https://pan.baidu.com/s/1mtXYfB61Czkadjrgs4RXzw
https://pan.baidu.com/s/1ZD4Hocgk4bMcl8tQGkTHcQ
cd ncappzoo/apps/dogsvscats
mkdir data
mv /home/shine/Downloads/test1.zip ~/Downloads/ncappzoo/apps/dogsvscats/data/
mv /home/shine/Downloads/train.zip ~/Downloads/ncappzoo/apps/dogsvscats/data/
cd ncappzoo/apps/dogsvscats
make
上述操作主要执行
Image pre-processing - resizing , cropping , histogram equalization (图像预处理)
Shuffling the images (图像打乱)
Splitting the images into training and validation (图像分割为训练集和测试集)
Creating an lmdb database of these images (格式转换)
Computing image mean -a common deep learning technique used to normalize data (计算图像均值)
- 模型对比
①比较模型的差异
export CAFFE_PATH=~/Downloads/caffe-master
diff -u $CAFFE_PATH/models/bvlc_googlenet bvlc_googlenet/org
- 数据训练
①下载caffe预训练模型,使用本地CPU或GPU进行训练,CAFFE_PATH需要替换为本地安装目录
$CAFFE_PATH/scripts/download_model_binary.py $CAFFE_PATH/models/bvlc_googlenet
$CAFFE_PATH/build/tools/caffe train --solver bvlc_googlenet/org/solver.prototxt --weights $CAFFE_PATH/models/bvlc_googlenet/bvlc_googlenet.caffemodel 2>&1 | tee bvlc_googlenet/org/train.log
#错误1:Cannot use GPU in CPU-only Caffe: check mode
cd ~/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/org
vim solver.prototxt
将其中的 solver_mode: GPU改为 solver_mode: CPU 或者将caffe重新编译成GPU模式 #错误2:Check failed: error == cudaSuccess (2 vs. 0) out of memory
由于博主使用的是GTX 650Ti 显存只有979Mb,执行GPU运算的时候出现显存不足的现象
②使用Intel AI Cloud 加速训练
如上文所述,在本地训练数据是一个巨大的运算量,常常需要几周或几个月,因此使用Intel提供的云服务器可以极大缩短训练的时间
在terminal中使用如下语句登陆到AI Cloud 服务器
ssh colfax
mkdir dogsvscats
登陆成功后即显示
########################################################################
# Welcome to Intel AI DevCloud!
########################################################################
将训练dogsvscats工程所需的数据集及shell命令上传到服务器(请根据实际目录进行调整,若上传速度较慢请尝试云服务器wget直接下载开放数据集)
scp /home/shine/Downloads/ncappzoo/apps/dogsvscats/data/train.zip colfax:/home/u14673/ncappzoo/apps/dogsvscats/data/
scp /home/shine/Downloads/ncappzoo/apps/dogsvscats/data/test1.zip .zip colfax:/home/u14673/ncappzoo/apps/dogsvscats/data/
将对应的shell文件和Makefile上传到服务器用于训练数据预处理(请根据实际目录进行调整)
scp /home/shine/Downloads/ncappzoo/apps/dogsvscats/Makefile colfax:/home/u14673/ncappzoo/apps/dogsvscats/
scp /home/shine/Downloads/ncappzoo/apps/dogsvscats/create-labels.py colfax:/home/u14673/ncappzoo/apps/dogsvscats/
scp /home/shine/Downloads/ncappzoo/apps/dogsvscats/create-lmdb.sh colfax:/home/u14673/ncappzoo/apps/dogsvscats/
使用Makefile进行预处理,由于Makefile中deps含有sudo apt-get -y install unzip和sudo pip install pyyaml,且sudo apt-get在AI Cloud中无法运行
vi Makefile
将deps更改为
@echo "Installing dependencies..."
# sudo apt-get -y install unzip
# sudo pip install pyyaml
:wq!保存后退出,创建任务用于数据预处理
vi data_process.sh
在打开的界面中输入(请根据实际目录进行调整)
echo "Start Data Process"
cd /home/u14673/ncappzoo/apps/dogsvscats/
make all
echo "Data Process Finished"
:wq!保存后退出,提交任务开始数据预处理
qsub data_process.sh
使用qstat可以查看任务完成的情况,完成后会在当前目录中生成对应的日志文件
将训练所需的prototxt及预训练模型上传至AI Cloud
scp -r /home/shine/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet colfax:/home/u14673/ncappzoo/apps/dogsvscats/
scp /home/shine/Downloads/caffe/models/bvlc_googlenet/bvlc_googlenet.caffemodel colfax:/home/u14673/ncappzoo/apps/dogsvscats/
创建任务用于数据训练
vi data_train.sh
在打开的界面中输入如下语句(请根据实际目录进行调整)
cd /home/u14673/ncappzoo/apps/dogsvscats/
echo 'Start Trainning'
# >&表示所有的标准输出和标准错误输出都将被重定向
/glob/intel-python/python3/bin/caffe train --solver bvlc_googlenet/org/solver.prototxt --weights /home/u14673/ncappzoo/apps/dogsvscats/bvlc_googlenet.caffemodel 2>&1 | tee bvlc_googlenet/org/train.log
关于caffe train命令的定义,标准的范例如下
caffe train \
--solver=solver_1st.prototxt \
--weights=VGG/VGG_ILSVRC_16_layers.caffemodel \
--gpu=0,1,2,3 2>&1 | tee log_1st.txt 其中--solver为必要的参数,配置solver文件
如果从头开始训练模型,则无需配置--weights
如果从快照中恢复,则需要配置--snapshot--weights
如果是fine-tuning,则需要配置
:wq!保存后退出,提交任务开始训练,训练完成后在当前目录可以看到日志文件
qsub data_train.sh
查看日志,日志保存在 bvlc_googlenet/org 目录,使用如下命令将数据拷贝到本地
scp colfax:/home/u14673/ncappzoo/apps/dogsvscats/bvlc_googlenet/org/train.log ./
使用caffe自带的工具绘制(位于caffe/tools/extra目录)训练数据,caffe中支持很多种曲线绘制,通过指定不同的类型参数即可,具体参数如下
Notes:
1. Supporting multiple logs.
2. Log file name must end with the lower-cased ".log".
Supported chart types:
0: Test accuracy vs. Iters
1: Test accuracy vs. Seconds
2: Test loss vs. Iters
3: Test loss vs. Seconds
4: Train learning rate vs. Iters
5: Train learning rate vs. Seconds
6: Train loss vs. Iters
7: Train loss vs. Seconds
解析日志并生成Test accuracy vs. Seconds曲线(实际应该为Test Loss,参考https://www.cnblogs.com/WaitingForU/p/9130327.html的解析)
cd ~/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/org
cp -r /home/shine/Downloads/caffe/tools/extra ~/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/org
mv train.log ./extra/
./plot_training_log.py.example 0 save.png ./train.log
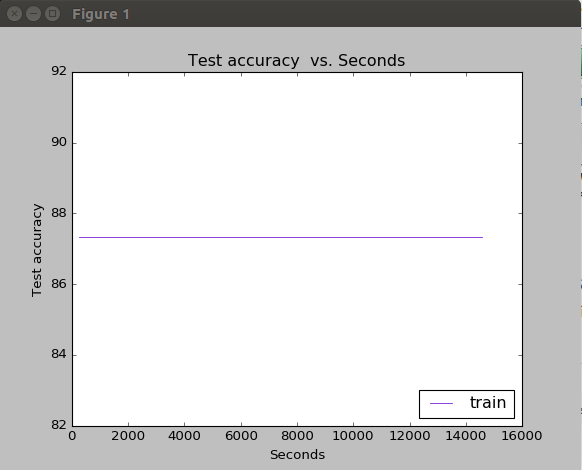
Test Loss Vs Seconds
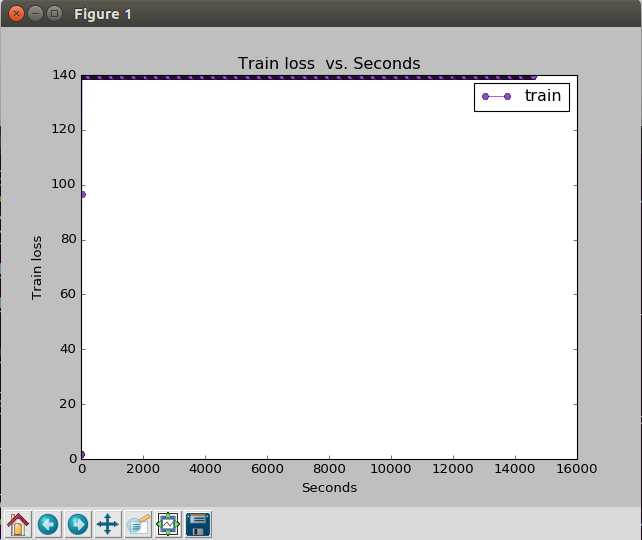
Train Loss Vs Seconds
从上述两张图来看,似乎训练过程并未收敛,对于这一问题,原作者并未给出原因,而是建议去掉--weights重新进行训练
/glob/intel-python/python3/bin/caffe train --solver bvlc_googlenet/org/solver.prototxt 2>&1 | tee bvlc_googlenet/org/train_withoutweights.log
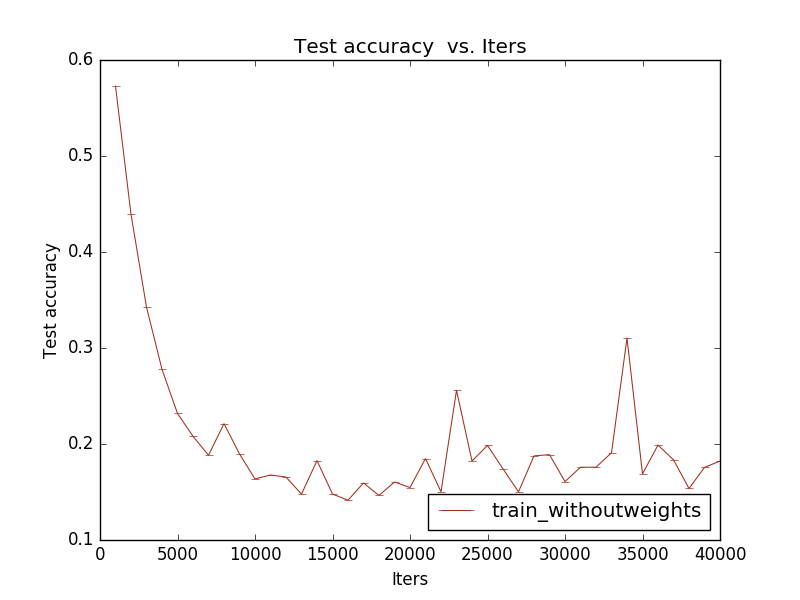
Test Loss Vs Iters
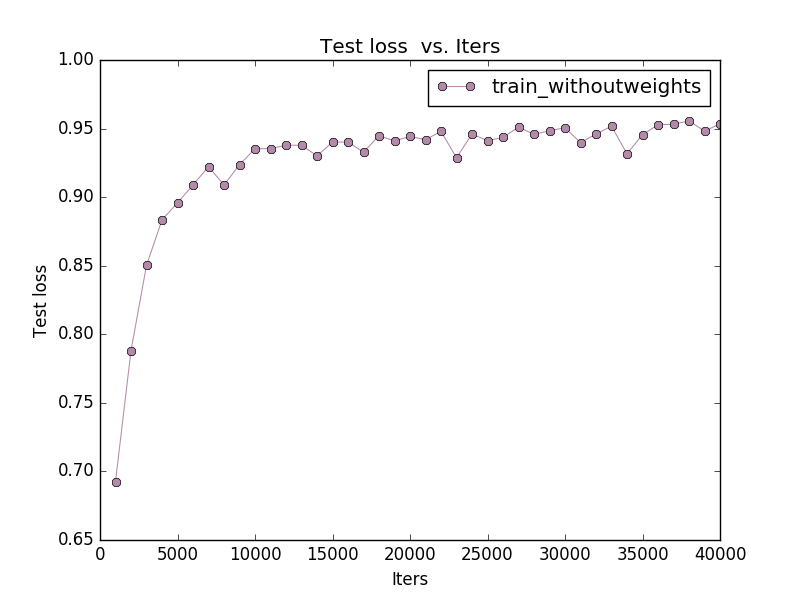
Test Accuracy Vs Iters
将训练后的模型拷贝到本地
scp colfax:/home/u14673/ncappzoo/apps/dogsvscats/bvlc_googlenet/org/bvlc_googlenet_iter_40000.caffemodel /home/shine/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/org/cd ~/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/org/
本地机器(需要安装NCSDK)查看网络分析,大致可以得到如下的图形,显示了各层连接的带宽和运行时间
mvNCProfile -s 12 deploy.prototxt -w bvlc_googlenet_iter_40000.caffemodel
firefox output_report.html
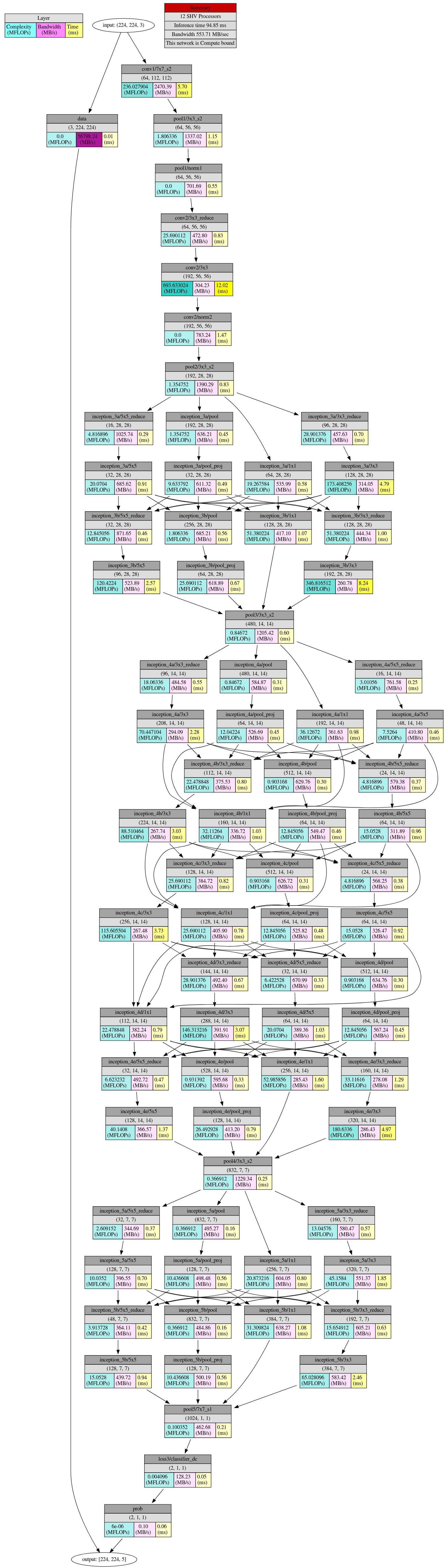
- 模型调优
作者对比了dogsvscats例程中改进的网络和GoogLenet原始网络,通过Caffe自带的Python工具分别绘制对应网络拓扑
cd ~/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/org
python ~/Downloads/caffe/python/draw_net.py train_val.prototxt train_val_plot.png
eog train_val_plot.png
cd ~/Downloads/ncappzoo/apps/dogsvscats/bvlc_googlenet/custom
python ~/Downloads/caffe/python/draw_net.py train_val.prototxt train_val_plot.png
eog train_val_plot.png
使用python-caffe自带的工具draw_net.py时可能会遇到如下错误
#错误1 ImportError: No module named google.protobuf (没有安装python-protobuf)
sudo apt-get install python-protobuf #错误2 ImportError: No module named _caffe (caffe源码编译的时候没有编译pycaffe)
cd ~/Downloads/caffe/
sudo make pycaffe #错误3 ImportError: No module named skimage.io (没有安装python-skimage)
sudo apt-get install python-skimage #错误4 ImportError: No module named pydot (没有安装python-pydot)
sudo apt install python-pydot python-pydot-ng graphviz
- 模型部署
根据最新训练的结果,生成graph文件
cd ~/workspace/ncappzoo/apps/dogsvscats/bvlc_googlenet/org (由于前面训练过程未能收敛,使用该模型预测时会出现Nan的结果)
mvNCCompile -s 12 deploy.prototxt -w bvlc_googlenet_iter_40000.caffemodel -o dogsvscats-org.graph
cd ~/workspace/ncappzoo/apps/dogsvscats/bvlc_googlenet/custom (定制优化后的网络)
mvNCCompile -s 12 deploy.prototxt -w bvlc_googlenet_iter_40000.caffemodel -o dogsvscats-org.graph
- 模型测试
修改ncappzoo/apps/image-classifier.py,原文件如下
# User modifiable input parameters
NCAPPZOO_PATH = '../..'
GRAPH_PATH = NCAPPZOO_PATH + '/caffe/GoogLeNet/graph'
IMAGE_PATH = NCAPPZOO_PATH + '/data/images/cat.jpg'
CATEGORIES_PATH = NCAPPZOO_PATH + '/data/ilsvrc12/synset_words.txt'
IMAGE_MEAN = numpy.float16( [104.00698793, 116.66876762, 122.67891434] )
IMAGE_STDDEV = ( 1 )
IMAGE_DIM = ( 224, 224 )
修改后的文件如下
NCAPPZOO_PATH = '../..'
GRAPH_PATH = NCAPPZOO_PATH +'/apps/dogsvscats/bvlc_googlenet/custom/dogsvscats-org.graph'
IMAGE_PATH = NCAPPZOO_PATH +'/apps/dogsvscats/data/test1/173.jpg'
CATEGORIES_PATH = NCAPPZOO_PATH +'/apps/dogsvscats/data/categories.txt'
IMAGE_MEAN = numpy.float16( [106.202, 115.912, 124.449] )
IMAGE_STDDEV = ( 1 )
IMAGE_DIM = ( 224, 224 )
使用生成的graph测试准确率(注意是python3,使用python image-classifier.py时会报错,具体原因待查明)
cd ~/Downloads/ncappzoo/apps/image-classifier
python3 image-classifier.py
得到结果如下
------- predictions --------
Prediction for : dog with 100.0% confidence in 89.67 ms
Prediction for : cat with 0.0% confidence in 89.67 ms
那么关于本步骤部署,系统具体作了哪些事情呢,深入查看image-classifier.py我们可以得知
# ---- Step 1: Open the enumerated device and get a handle to it -------------
# 枚举Movidius神经元计算棒
# ---- Step 2: Load a graph file onto the NCS device -------------------------
# 加载graph文件
# ---- Step 3: Offload image onto the NCS to run inference -------------------
# 加载image文件
# ---- Step 4: Read & print inference results from the NCS -------------------
# 读取并打印运算结果
# ---- Step 5: Unload the graph and close the device -------------------------
# 关闭神经元计算棒
- 模型调优
- 参考文献:
1.https://movidius.github.io/blog/deploying-custom-caffe-models
2.https://communities.intel.com/community/tech/intel-ai-academy
3.https://www.kaggle.com/khorchanov/dogsvscats
Movidius的深度学习入门的更多相关文章
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
这次博客园的排版彻底残了..高清版请移步: https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程: 给深度学习入门者的Python快速教程 - 基础篇 给深度 ...
- 给深度学习入门者的Python快速教程 - numpy和Matplotlib篇
始终无法有效把word排版好的粘贴过来,排版更佳版本请见知乎文章: https://zhuanlan.zhihu.com/p/24309547 实在搞不定博客园的排版,排版更佳的版本在: 给深度学习入 ...
- 深度学习入门实战(二)-用TensorFlow训练线性回归
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者 :董超 上一篇文章我们介绍了 MxNet 的安装,但 MxNet 有个缺点,那就是文档不太全,用起来可能 ...
- 给深度学习入门者的Python快速教程
给深度学习入门者的Python快速教程 基础篇 numpy和Matplotlib篇 本篇部分代码的下载地址: https://github.com/frombeijingwithlove/dlcv_f ...
- Python学习(二)——深度学习入门介绍
课程二:深度学习入门 讲师:David (数据分析工程师) 这门课主要介绍了很多神经网络的基本原理,非常非常基础的了解. 零.思维导图预览: 一.深度神经网络 1.神经元 ...
- 学习《深度学习入门:基于Python的理论与实现》高清中文版PDF+源代码
入门神经网络深度学习,推荐学习<深度学习入门:基于Python的理论与实现>,这本书不来虚的,一上来就是手把手教你一步步搭建出一个神经网络,还能把每一步的出处讲明白.理解神经网络,很容易就 ...
- 深度学习入门者的Python快速教程 - 基础篇
5.1 Python简介 本章将介绍Python的最基本语法,以及一些和深度学习还有计算机视觉最相关的基本使用. 5.1.1 Python简史 Python是一门解释型的高级编程语言,特点是简单明 ...
- 最全的机器学习&深度学习入门视频课程集
资源介绍 链接:http://pan.baidu.com/s/1kV6nWJP 密码:ryfd 链接:http://pan.baidu.com/s/1dEZWlP3 密码:y82m 更多资源 ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
随机推荐
- python之字典二 内置方法总结
Python字典包含了以下内置方法: clear()函数用于删除字典内所有元素 dict1 = {, 'Class': 'First'} print('the start len %d' % len( ...
- 在线程中使用ClientQuery注意的问题
今天遇到奇怪的问题,在线程中建立一个TkbmMWClientQuery的临时对象q,及一个TkbmMWBinaryStreamFormat的临时对象bsf,第一次执行正常,再次执行时一直等待,也不产生 ...
- SpringMVC----视图层框架
Spring Web模型-视图-控制器(MVC)框架是围绕DispatcherServlet设计的,DispatcherServlet将接收的请求分派给应用程序.SpringMVC具有配置处理程序映射 ...
- linux的top下buffer与cache的区别、free命令内存解释
buffer: 缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据 的区域.通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据 时,速度快的设备的操作进程不发 ...
- 1.Nginx安装
1.Nginx安装配置 Nginx("engine x")是一款是由俄罗斯的程序设计师Igor Sysoev所开发的高性能 Web和 反向代理服务器,也是一个 IMAP/POP3/ ...
- QTP(7)
一.输出值(Output Value) 1.应用场景: 1) 关心被测系统的数据 2) 将被测系统生成的数据作为后面步骤的输入 2.输出值就是输出被测系统中实际运行时的数据的一种技术 a.运行中对象的 ...
- Java语言基础(15)
1 综合案例 Demo1 设计一个父类Shape(图形类),抽象类常量:public static final double PI = 3.14;抽象方法:void show():输出每一个属性值vo ...
- idea中添加mybatis mapper 样例
代码: <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC &quo ...
- ora-01847:月份中日的值必须介于 1 和当月最后一日之间
今天解决了一个奇葩问题: ORA-01847: 月份中日的值必须介于 1 和当月最后一日之间 将数据从一个视图倒入到一个同结构的表中,但是老报错,也就那么几个字段,肉眼真看不出来什么问题,但是既然报这 ...
- phpMyAdmin出现Fatal error: Maximum execution time of 300 seconds
在mysql用phpMyAdmin导入大数据的时候出现:Fatal error: Maximum execution time of 300 seconds exceeded in D:/查了很多文章 ...