python常用模块collections os random sys
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
例子
下例是个简单的模块 support.py:
support.py 模块:
def print_func( par ):
print ("Hello : ", par)
return
import 语句
模块的引入
模块定义好后,我们可以使用 import 语句来引入模块,语法如下:
import module1[, module2[,... moduleN]]
比如要引用模块 math,就可以在文件最开始的地方用 import math 来引入。在调用 math 模块中的函数时,必须这样引用:
模块名.函数名
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support.py,需要把命令放在脚本的顶端:
test.py 文件代码:
以上实例输出结果:
Hello : Runoob
一个模块只会被导入一次,不管你执行了多少次import。这样可以防止导入模块被一遍又一遍地执行。
from…import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块 fib 的 fibonacci 函数,使用如下语句:
from fib import fibonacci
这个声明不会把整个 fib 模块导入到当前的命名空间中,它只会将 fib 里的 fibonacci 单个引入到执行这个声明的模块的全局符号表。
from…import* 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
例如我们想一次性引入 math 模块中所有的东西,语句如下:
from math import *
搜索路径
当你导入一个模块,Python 解析器对模块位置的搜索顺序是:
- 1、当前目录
- 2、如果不在当前目录,Python 则搜索在 shell 变量 PYTHONPATH 下的每个目录。
- 3、如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/。
模块搜索路径存储在 system 模块的 sys.path 变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
PYTHONPATH 变量
作为环境变量,PYTHONPATH 由装在一个列表里的许多目录组成。PYTHONPATH 的语法和 shell 变量 PATH 的一样。
在 Windows 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=c:\python27\lib;
在 UNIX 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=/usr/local/lib/python
命名空间和作用域
变量是拥有匹配对象的名字(标识符)。命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样。
Python 会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的。
因此,如果要给函数内的全局变量赋值,必须使用 global 语句。
global VarName 的表达式会告诉 Python, VarName 是一个全局变量,这样 Python 就不会在局部命名空间里寻找这个变量了。
例如,我们在全局命名空间里定义一个变量 Money。我们再在函数内给变量 Money 赋值,然后 Python 会假定 Money 是一个局部变量。然而,我们并没有在访问前声明一个局部变量 Money,结果就是会出现一个 UnboundLocalError 的错误。取消 global 语句的注释就能解决这个问题。
#!/usr/bin/python # -*- coding: UTF-8 -*- Money = 2000 def AddMoney(): # 想改正代码就取消以下注释: # global Money Money = Money + 1 print Money AddMoney() print Money
dir()函数
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例:
#!/usr/bin/python # -*- coding: UTF-8 -*- # 导入内置math模块 import math content = dir(math) print content;
以上实例输出结果:
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan', 'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp', 'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log', 'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt', 'tan', 'tanh']
在这里,特殊字符串变量__name__指向模块的名字,__file__指向该模块的导入文件名。
globals() 和 locals() 函数
根据调用地方的不同,globals() 和 locals() 函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用 locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用 globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用 keys() 函数摘取。
reload() 函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用 reload() 函数。该函数会重新导入之前导入过的模块。语法如下:
reload(module_name)
在这里,module_name要直接放模块的名字,而不是一个字符串形式。比如想重载 hello 模块,如下:
reload(hello)
Python中的包
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__init__.py 用于标识当前文件夹是一个包。
考虑一个在 package_runoob 目录下的 runoob1.py、runoob2.py、__init__.py 文件,test.py 为测试调用包的代码,目录结构如下:
test.py package_runoob |-- __init__.py |-- runoob1.py |-- runoob2.py
源代码如下:
package_runoob/runoob1.py
package_runoob/runoob2.py
现在,在 package_runoob 目录下创建 __init__.py:
package_runoob/__init__.py
然后我们在 package_runoob 同级目录下创建 test.py 来调用 package_runoob 包
test.py
以上实例输出结果:
package_runoob 初始化 I'm in runoob1 I'm in runoob2
如上,为了举例,我们只在每个文件里放置了一个函数,但其实你可以放置许多函数。你也可以在这些文件里定义Python的类,然后为这些类建一个包。
collections是Python内建的一个集合模块,提供了许多有用的集合类。
namedtuple
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:
>>> p = (1, 2)
但是,看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
定义一个class又小题大做了,这时,namedtuple就派上了用场:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
namedtuple是一个函数,它用来创建一个自定义的tuple对象,并且规定了tuple元素的个数,并可以用属性而不是索引来引用tuple的某个元素。
这样一来,我们用namedtuple可以很方便地定义一种数据类型,它具备tuple的不变性,又可以根据属性来引用,使用十分方便。
可以验证创建的Point对象是tuple的一种子类:
>>> isinstance(p, Point)
True
>>> isinstance(p, tuple)
True
类似的,如果要用坐标和半径表示一个圆,也可以用namedtuple定义:
# namedtuple('名称', [属性list]):
Circle = namedtuple('Circle', ['x', 'y', 'r'])
deque
使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈:
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
注意默认值是调用函数返回的,而函数在创建defaultdict对象时传入。
除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。
OrderedDict
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
>>> od = OrderedDict()
>>> od['z'] = 1
>>> od['y'] = 2
>>> od['x'] = 3
>>> od.keys() # 按照插入的Key的顺序返回
['z', 'y', 'x']
OrderedDict可以实现一个FIFO(先进先出)的dict,当容量超出限制时,先删除最早添加的Key:
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
if len(self) - containsKey >= self._capacity:
last = self.popitem(last=False)
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value)
Counter
Counter是一个简单的计数器,例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for ch in 'programming':
... c[ch] = c[ch] + 1
...
>>> c
Counter({'g': 2, 'm': 2, 'r': 2, 'a': 1, 'i': 1, 'o': 1, 'n': 1, 'p': 1})
Counter实际上也是dict的一个子类,上面的结果可以看出,字符'g'、'm'、'r'各出现了两次,其他字符各出现了一次。
小结
collections模块提供了一些有用的集合类,可以根据需要选用。
python3 deque(双向队列)
创建双向队列
import collections d = collections.deque()
append(往右边添加一个元素)

import collections d = collections.deque() d.append(1) d.append(2) print(d) #输出:deque([1, 2])
appendleft(往左边添加一个元素)
import collections d = collections.deque() d.append(1) d.appendleft(2) print(d) #输出:deque([2, 1])
clear(清空队列)
import collections d = collections.deque() d.append(1) d.clear() print(d) #输出:deque([])
copy(浅拷贝)
import collections d = collections.deque() d.append(1) new_d = d.copy() print(new_d) #输出:deque([1])
count(返回指定元素的出现次数)
import collections d = collections.deque() d.append(1) d.append(1) print(d.count(1)) #输出:2
extend(从队列右边扩展一个列表的元素)
import collections d = collections.deque() d.append(1) d.extend([3,4,5]) print(d) #输出:deque([1, 3, 4, 5])
extendleft(从队列左边扩展一个列表的元素)
import collections d = collections.deque() d.append(1) d.extendleft([3,4,5]) print(d) # # #输出:deque([5, 4, 3, 1])
index(查找某个元素的索引位置)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
print(d)
print(d.index('e'))
print(d.index('c',0,3)) #指定查找区间
#输出:deque(['a', 'b', 'c', 'd', 'e'])
# 4
# 2
insert(在指定位置插入元素)
import collections d = collections.deque() d.extend(['a','b','c','d','e']) d.insert(2,'z') print(d) #输出:deque(['a', 'b', 'z', 'c', 'd', 'e'])
pop(获取最右边一个元素,并在队列中删除)
import collections d = collections.deque() d.extend(['a','b','c','d','e']) x = d.pop() print(x,d) #输出:e deque(['a', 'b', 'c', 'd'])
popleft(获取最左边一个元素,并在队列中删除)
import collections d = collections.deque() d.extend(['a','b','c','d','e']) x = d.popleft() print(x,d) #输出:a deque(['b', 'c', 'd', 'e'])
remove(删除指定元素)
import collections
d = collections.deque()
d.extend(['a','b','c','d','e'])
d.remove('c')
print(d)
#输出:deque(['a', 'b', 'd', 'e'])
reverse(队列反转)
import collections d = collections.deque() d.extend(['a','b','c','d','e']) d.reverse() print(d) #输出:deque(['e', 'd', 'c', 'b', 'a'])
rotate(把右边元素放到左边)
import collections d = collections.deque() d.extend(['a','b','c','d','e']) d.rotate(2) #指定次数,默认1次 print(d) #输出:deque(['d', 'e', 'a', 'b', 'c'])
namedtuple 命名元组
Python namedtuple(命名元组)使用实例
|
1
2
3
4
5
6
7
8
9
|
#!/usr/bin/python3import collectionsMyTupleClass = collections.namedtuple('MyTupleClass',['name', 'age', 'job'])obj = MyTupleClass("Tomsom",12,'Cooker')print(obj.name)print(obj.age)print(obj.job) |
执行结果:
|
1
2
3
|
Tomsom12Cooker |

namedtuple对象就如它的名字说定义的那样,你可以给tuple命名,具体看下面的例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
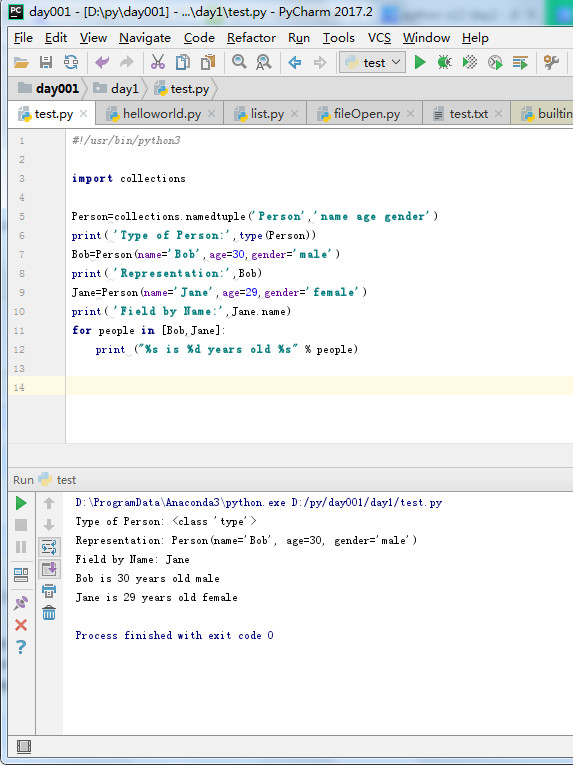
#!/usr/bin/python3import collectionsPerson=collections.namedtuple('Person','name age gender')print( 'Type of Person:',type(Person))Bob=Person(name='Bob',age=30,gender='male')print( 'Representation:',Bob)Jane=Person(name='Jane',age=29,gender='female')print( 'Field by Name:',Jane.name)for people in [Bob,Jane]: print ("%s is %d years old %s" % people) |
执行结果:
|
1
2
3
4
5
|
Type of Person: <class 'type'>Representation: Person(name='Bob', age=30, gender='male')Field by Name: JaneBob is 30 years old maleJane is 29 years old female |
来解释一下nametuple的几个参数,以Person=collections.namedtuple(‘Person’,'name age gender’)为例,其中’Person’是这个namedtuple的名称,后面的’name age gender’这个字符串中三个用空格隔开的字符告诉我们,我们的这个namedtuple有三个元素,分别名为name,age和gender。我们在 创建它的时候可以通过Bob=Person(name=’Bob’,age=30,gender=’male’)这种方式,这类似于Python中类对象 的使用。而且,我们也可以像访问类对象的属性那样使用Jane.name这种方式访问namedtuple的元素。其输出结果如下:
但是在使用namedtyuple的时候要注意其中的名称不能使用Python的关键字,如:class def等;而且也不能有重复的元素名称,比如:不能有两个’age age’。如果出现这些情况,程序会报错。但是,在实际使用的时候可能无法避免这种情况,比如:可能我们的元素名称是从数据库里读出来的记录,这样很难保 证一定不会出现Python关键字。这种情况下的解决办法是将namedtuple的重命名模式打开,这样如果遇到Python关键字或者有重复元素名 时,自动进行重命名。
看下面的代码:
|
1
2
3
4
5
|
import collectionswith_class=collections.namedtuple('Person','name age class gender',rename=True)print with_class._fieldstwo_ages=collections.namedtuple('Person','name age gender age',rename=True)print two_ages._fields |
其输出结果为:
|
1
2
|
('name', 'age', '_2', 'gender')('name', 'age', 'gender', '_3') |
我们使用rename=True的方式打开重命名选项。可以看到第一个集合中的class被重命名为 ‘_2' ; 第二个集合中重复的age被重命名为 ‘_3'这是因为namedtuple在重命名的时候使用了下划线 _ 加元素所在索引数的方式进行重命名。
附两段官方文档代码实例:
1) namedtuple基本用法
|
1
2
3
4
5
6
7
8
9
10
11
12
|
>>> # Basic example>>> Point = namedtuple('Point', ['x', 'y'])>>> p = Point(11, y=22) # instantiate with positional or keyword arguments>>> p[0] + p[1] # indexable like the plain tuple (11, 22)33>>> x, y = p # unpack like a regular tuple>>> x, y(11, 22)>>> p.x + p.y # fields also accessible by name33>>> p # readable __repr__ with a name=value stylePoint(x=11, y=22) |
2) namedtuple结合csv和sqlite用法
|
1
2
3
4
5
6
7
8
9
10
|
EmployeeRecord = namedtuple('EmployeeRecord', 'name, age, title, department, paygrade')import csvfor emp in map(EmployeeRecord._make, csv.reader(open("employees.csv", "rb"))):print(emp.name, emp.title)import sqlite3conn = sqlite3.connect('/companydata')cursor = conn.cursor()cursor.execute('SELECT name, age, title, department, paygrade FROM employees')for emp in map(EmployeeRecord._make, cursor.fetchall()):print(emp.name, emp.title) |
Python collections.defaultdict() 与 dict的使用和区别
看样子这个文档是难以看懂了。直接看示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import collectionss = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]# defaultdictd = collections.defaultdict(list)for k, v in s: d[k].append(v)# Use dict and setdefault g = {}for k, v in s: g.setdefault(k, []).append(v) # Use dicte = {}for k, v in s: e[k] = v##list(d.items())##list(g.items())##list(e.items()) |
看看结果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
list(d.items())[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]>>> list(g.items())[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]>>> list(e.items())[('blue', 4), ('red', 1), ('yellow', 3)]>>> ddefaultdict(<class 'list'>, {'blue': [2, 4], 'red': [1], 'yellow': [1, 3]})>>> g{'blue': [2, 4], 'red': [1], 'yellow': [1, 3]}>>> e{'blue': 4, 'red': 1, 'yellow': 3}>>> d.items()dict_items([('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])])>>> d["blue"][2, 4]>>> d.keys()dict_keys(['blue', 'red', 'yellow'])>>> d.default_factory<class 'list'>>>> d.values()dict_values([[2, 4], [1], [1, 3]]) |
可以看出
collections.defaultdict(list)使用起来效果和运用dict.setdefault()比较相似
python help上也这么说了
When each key is encountered for the first time, it is not already in the mapping; so an entry is automatically created using the default_factory function which returns an empty list. The list.append() operation then attaches the value to the new list. When keys are encountered again, the look-up proceeds normally (returning the list for that key) and the list.append() operation adds another value to the list. This technique is simpler and faster than an equivalent technique using dict.setdefault():
说这种方法会和dict.setdefault()等价,但是要更快。
有必要看看dict.setdefault()
setdefault(key[, default])
If key is in the dictionary, return its value. If not, insert key with a value of default and return default. default defaults to None.
如果这个key已经在dictionary里面存着,返回value.如果key不存在,插入key和一个default value,返回Default. 默认的defaults是None.
但是这里要注意的是defaultdict是和dict.setdefault等价,和下面那个直接赋值是有区别的。从结果里面就可以看到,直接赋值会覆盖。
从最后的d.values还有d[“blue”]来看,后面的使用其实是和dict的用法一样的,唯一不同的就是初始化的问题。defaultdict可以利用工厂函数,给初始keyi带来一个默认值。
这个默认值也许是空的list[] defaultdict(list), 也许是0, defaultdict(int).
再看看下面的这个例子。
defaultdict(int) 这里的d其实是生成了一个默认为0的带key的数据字典。你可以想象成 d[key] = int default (int工厂函数的默认值为0)
d[k]所以可以直接读取 d[“m”] += 1 就是d[“m”] 就是默认值 0+1 = 1
后面的道理就一样了。
|
1
2
3
4
5
6
7
|
>>> s = 'mississippi'>>> d = defaultdict(int)>>> for k in s:... d[k] += 1...>>> list(d.items())[('i', 4), ('p', 2), ('s', 4), ('m', 1)] |
python中的time模块
time模块--时间获取和转换
time模块提供各种时间相关的功能
与时间相关的模块有:time,datetime,calendar必要说明:
这个模块的功能不是适用于所有的平台
这个模块中定义的大部分函数是调用C平台上的同名函数实现一些术语和约定的解释:
1.时间戳(timestamp)的方式:通常来说,时间戳表示的是从1970年1月1日开始按秒计算的偏移量(time.gmtime(0))此模块中的函数无法处理1970纪元年以前的时间或太遥远的未来(处理极限取决于C函数库,对于32位系统而言,是2038年)
2.UTC(Coordinated Universal Time,世界协调时)也叫格林威治天文时间,是世界标准时间.在我国为UTC+8
3.DST(Daylight Saving Time)即夏令时
4.一些实时函数的计算精度可能不同时间元祖(time.struct_time)
gmtime(),localtime()和strptime()以时间元祖(struct_time)的形式返回| 索引值(index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | (例如:2015) |
| 1 | tm_mon(月) | 1-12 |
| 2 | tm_mday(日) | 1-31 |
| 3 | tm_hour(时) | 0-23 |
| 4 | tm_min(分) | 0-59 |
| 5 | tm_sec(秒) | 0-61(60代表闰秒,61是基于历史原因保留) |
| 6 | tm_wday(星期几) | 0-6(0表示星期一) |
| 7 | tm_yday(一年中的第几天) | 1-366 |
| 8 | tm_isdst(是否为夏令时) | 0,1,-1(-1代表夏令时) |
time.altzone
返回格林威治西部的夏令时地区的偏移秒数,如果该地区在格林威治东部会返回负值(如西欧,包括英国),对夏令时启用地区才能使用time.asctime([t])
接受时间元组并返回一个可读的形式"Tue May 30 17:17:30 2017"(2017年5月30日周二17时17分30秒)的24个字符的字符串time.clock()
用以浮点数计算的秒数返回当前的CPU时间,用来衡量不同程序的耗时,比time.time()更有用
python3.3以后不被推荐使用,该方法依赖操作系统,建议使用per_counter(返回系统运行时间)或process_time(返回进程运行时间)代替time.ctime([secs])
作用相当于asctime(localtime(secs)),未给参数相当于asctime()time.gmtime([secs])
接收时间辍(1970纪元年后经过的浮点秒数)并返回格林威治天文时间下的时间元组t(t.tm_isdst始终为0)time.daylight
如果夏令时被定义,则该值为非零time.localtime([secs])
接收时间辍(1970纪元年后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取为0或1,取决于当地当时是不是夏令时)time.mktime(t)
接受时间元组并返回时间辍(1970纪元年后经过的浮点秒数)time.perf_counter()
返回计时器的精准时间(系统的运行时间),包含整个系统的睡眠时间.由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的time.process_time()
返回当前进程执行CPU的时间总和,不包含睡眠时间.由于返回值的基准点是未定义的,所以只有连续调用的结果之间的差才是有效的time.sleep(secs)
推迟调用线程的运行,secs的单位是秒time.strftime(format[,t])
把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串.如果t未指定,将传入time.localtime(),如果元组中任命一个元素越界,将会抛出ValueError异常
format格式如下:
%a 本地(local)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01-31)
%H 一天中的第几个小时(24小时制,00-23)
%l 一天中的第几个小时(12小时制,01-12)
%j 一年中的第几天(01-366)
%m 月份(01-12)
%M 分钟数(00-59)
%p 本地am或者pm的相应符
%S 秒(01-61)
%U 一年中的星期数(00-53,星期天是一个星期的开始,第一个星期天之前的所有天数都放在第0周)
%w 一个星期中的第几天(0-6,0是星期天)
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00-99)
%Y 完整的年份
%z 用+HHMM或者-HHMM表示距离格林威治的时区偏移(H代表十进制的小时数,M代表十进制的分钟数)
%Z 时区的名字(如果不存在为空字符)
%% %号本身
%p只有与%I配合使用才有效果
当使用strptime()函数时,只有当在这年中的周数和天数被确定的时候%U和%W才会被计算time.strptime(string[,format])
把一个格式化时间字符串转化为struct_time,实际上它和strftie()是逆操作time.time()
返回当前时间的时间戳(1970元年后的浮点秒数)time.timezone()
是当地时区(未启动夏令时)距离格林威治的偏移秒数(美洲>0,欧洲大部分,亚洲,非洲<=0)time.tzname
包含两个字符串的元组,第一是当地夏令时区的名称,第二是当地的DST时区的名称Python random
如果你对在Python生成随机数与random模块中最常用的几个函数的关系与不懂之处,下面的文章就是对Python生成随机数与random模块中最常用的几个函数的关系,希望你会有所收获,以下就是这篇文章的介绍。
random.random()用于生成
用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成随机数
|
1
|
n: a <= n <= b。如果 a <b, 则 b <= n <= a。 |
|
1
2
3
4
5
6
|
print random.uniform(10, 20) print random.uniform(20, 10) #---- #18.7356606526 #12.5798298022 random.randint |
用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,Python生成随机数
|
1
2
3
|
print random.randint(12, 20) #生成的随机数n: 12 <= n <= 20 print random.randint(20, 20) #结果永远是20 #print random.randint(20, 10) #该语句是错误的。 |
下限必须小于上限。
random.randrange
从指定范围内,按指定基数递增的集合中 ,这篇文章就是对python生成随机数的应用程序的部分介绍。
随机整数:
>>> import random
>>> random.randint(0,99)
21
随机选取0到100间的偶数:
>>> import random
>>> random.randrange(0, 101, 2)
42
随机浮点数:
>>> import random
>>> random.random()
0.85415370477785668
>>> random.uniform(1, 10)
5.4221167969800881
随机字符:
>>> import random
>>> random.choice('abcdefg&#%^*f')
'd'
多个字符中选取特定数量的字符:
>>> import random
random.sample('abcdefghij',3)
['a', 'd', 'b']
多个字符中选取特定数量的字符组成新字符串:
>>> import random
>>> import string
>>> string.join(random.sample(['a','b','c','d','e','f','g','h','i','j'], 3)).r
eplace(" ","")
'fih'
随机选取字符串:
>>> import random
>>> random.choice ( ['apple', 'pear', 'peach', 'orange', 'lemon'] )
'lemon'
洗牌:
>>> import random
>>> items = [1, 2, 3, 4, 5, 6]
>>> random.shuffle(items)
>>> items
[3, 2, 5, 6, 4, 1]
Python OS模块
#OS模块
#os模块就是对操作系统进行操作,使用该模块必须先导入模块:
import os
#getcwd() 获取当前工作目录(当前工作目录默认都是当前文件所在的文件夹)
result = os.getcwd()
print(result)
#chdir()改变当前工作目录
os.chdir('/home/sy')
result = os.getcwd()
print(result)
open('02.txt','w')
#操作时如果书写完整的路径则不需要考虑默认工作目录的问题,按照实际书写路径操作
open('/home/sy/下载/02.txt','w')
#listdir() 获取指定文件夹中所有内容的名称列表
result = os.listdir('/home/sy')
print(result)
#mkdir() 创建文件夹
#os.mkdir('girls')
#os.mkdir('boys',0o777)
#makedirs() 递归创建文件夹
#os.makedirs('/home/sy/a/b/c/d')
#rmdir() 删除空目录
#os.rmdir('girls')
#removedirs 递归删除文件夹 必须都是空目录
#os.removedirs('/home/sy/a/b/c/d')
#rename() 文件或文件夹重命名
#os.rename('/home/sy/a','/home/sy/alibaba'
#os.rename('02.txt','002.txt')
#stat() 获取文件或者文件夹的信息
#result = os.stat('/home/sy/PycharmProject/Python3/10.27/01.py)
#print(result)
#system() 执行系统命令(危险函数)
#result = os.system('ls -al') #获取隐藏文件
#print(result)
#环境变量
'''
环境变量就是一些命令的集合
操作系统的环境变量就是操作系统在执行系统命令时搜索命令的目录的集合
'''
#getenv() 获取系统的环境变量
result = os.getenv('PATH')
print(result.split(':'))
#putenv() 将一个目录添加到环境变量中(临时增加仅对当前脚本有效)
#os.putenv('PATH','/home/sy/下载')
#os.system('syls')
#exit() 退出终端的命令
#os模块中的常用值
#curdir 表示当前文件夹 .表示当前文件夹 一般情况下可以省略
print(os.curdir)
#pardir 表示上一层文件夹 ..表示上一层文件夹 不可省略!
print(os.pardir)
#os.mkdir('../../../man')#相对路径 从当前目录开始查找
#os.mkdir('/home/sy/man1')#绝对路径 从根目录开始查找
#name 获取代表操作系统的名称字符串
print(os.name) #posix -> linux或者unix系统 nt -> window系统
#sep 获取系统路径间隔符号 window ->\ linux ->/
print(os.sep)
#extsep 获取文件名称和后缀之间的间隔符号 window & linux -> .
print(os.extsep)
#linesep 获取操作系统的换行符号 window -> \r\n linux/unix -> \n
print(repr(os.linesep))
#导入os模块
import os
#以下内容都是os.path子模块中的内容
#abspath() 将相对路径转化为绝对路径
path = './boys'#相对
result = os.path.abspath(path)
print(result)
#dirname() 获取完整路径当中的目录部分 & basename()获取完整路径当中的主体部分
path = '/home/sy/boys'
result = os.path.dirname(path)
print(result)
result = os.path.basename(path)
print(result)
#split() 将一个完整的路径切割成目录部分和主体部分
path = '/home/sy/boys'
result = os.path.split(path)
print(result)
#join() 将2个路径合并成一个
var1 = '/home/sy'
var2 = '000.py'
result = os.path.join(var1,var2)
print(result)
#splitext() 将一个路径切割成文件后缀和其他两个部分,主要用于获取文件的后缀
path = '/home/sy/000.py'
result = os.path.splitext(path)
print(result)
#getsize() 获取文件的大小
#path = '/home/sy/000.py'
#result = os.path.getsize(path)
#print(result)
#isfile() 检测是否是文件
path = '/home/sy/000.py'
result = os.path.isfile(path)
print(result)
#isdir() 检测是否是文件夹
result = os.path.isdir(path)
print(result)
#islink() 检测是否是链接
path = '/initrd.img.old'
result = os.path.islink(path)
print(result)
#getctime() 获取文件的创建时间 get create time
#getmtime() 获取文件的修改时间 get modify time
#getatime() 获取文件的访问时间 get active time
import time
filepath = '/home/sy/下载/chls'
result = os.path.getctime(filepath)
print(time.ctime(result))
result = os.path.getmtime(filepath)
print(time.ctime(result))
result = os.path.getatime(filepath)
print(time.ctime(result))
#exists() 检测某个路径是否真实存在
filepath = '/home/sy/下载/chls'
result = os.path.exists(filepath)
print(result)
#isabs() 检测一个路径是否是绝对路径
path = '/boys'
result = os.path.isabs(path)
print(result)
#samefile() 检测2个路径是否是同一个文件
path1 = '/home/sy/下载/001'
path2 = '../../../下载/001'
result = os.path.samefile(path1,path2)
print(result)
#os.environ 用于获取和设置系统环境变量的内置值
import os
#获取系统环境变量 getenv() 效果
print(os.environ['PATH'])
#设置系统环境变量 putenv()
os.environ['PATH'] += ':/home/sy/下载'
os.system('chls')
python之sys模块详解
sys模块功能多,我们这里介绍一些比较实用的功能,相信你会喜欢的,和我一起走进python的模块吧!
sys模块的常见函数列表
sys.argv: 实现从程序外部向程序传递参数。sys.exit([arg]): 程序中间的退出,arg=0为正常退出。sys.getdefaultencoding(): 获取系统当前编码,一般默认为ascii。sys.setdefaultencoding(): 设置系统默认编码,执行dir(sys)时不会看到这个方法,在解释器中执行不通过,可以先执行reload(sys),在执行 setdefaultencoding('utf8'),此时将系统默认编码设置为utf8。(见设置系统默认编码 )sys.getfilesystemencoding(): 获取文件系统使用编码方式,Windows下返回'mbcs',mac下返回'utf-8'.sys.path: 获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。sys.platform: 获取当前系统平台。sys.stdin,sys.stdout,sys.stderr: stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们
sys.argv
功能:在外部向程序内部传递参数
示例:sys.py
#!/usr/bin/env python
import sys
print sys.argv[0]
print sys.argv[1]运行:
# python sys.py argv1
sys.py
argv1自己动手尝试一下,领悟参数对应关系
sys.exit(n)
功能:执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.exit函数,带有一个可选的整数参数返回给调用它的程序,表示你可以在主程序中捕获对sys.exit的调用。(0是正常退出,其他为异常)
示例:exit.py
#!/usr/bin/env python
import sys
def exitfunc(value):
print value
sys.exit(0)
print "hello"
try:
sys.exit(1)
except SystemExit,value:
exitfunc(value)
print "come?"运行:
# python exit.py
hello
1sys.path
功能:获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。
示例:
>>> import sys
>>> sys.path
['', '/usr/lib/python2.7', '/usr/lib/python2.7/plat-x86_64-linux-gnu', '/usr/lib/python2.7/lib-tk', '/usr/lib/python2.7/lib-old', '/usr/lib/python2.7/lib-dynload', '/usr/local/lib/python2.7/dist-packages', '/usr/lib/python2.7/dist-packages', '/usr/lib/python2.7/dist-packages/PILcompat', '/usr/lib/python2.7/dist-packages/gtk-2.0', '/usr/lib/python2.7/dist-packages/ubuntu-sso-client']sys.path.append("自定义模块路径")
sys.modules
功能:sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules将自动记录该模块。当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度。它拥有字典所拥有的一切方法。
示例:modules.py
#!/usr/bin/env python
import sys
print sys.modules.keys()
print sys.modules.values()
print sys.modules["os"]运行:
python modules.py
['copy_reg', 'sre_compile', '_sre', 'encodings', 'site', '__builtin__',......sys.stdin\stdout\stderr
功能:stdin , stdout , 以及stderr 变量包含与标准I/O 流对应的流对象. 如果需要更好地控制输出,而print 不能满足你的要求, 它们就是你所需要的. 你也可以替换它们, 这时候你就可以重定向输出和输入到其它设备( device ), 或者以非标准的方式处理它们
python常用模块collections os random sys的更多相关文章
- python 常用模块之os、sys、shutil
目录: 1.os 2.sys 3.shutil 一.os模块 说明:os模块是对操作系统进行调用的接口 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdi ...
- Python常用模块之os和sys
1.OS常用方法 os.access(path, mode) # 检验权限模式 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirn ...
- python常用模块---collections、time、random、os、sys、序列号模块
collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdict. ...
- day19:常用模块(collections,time,random,os,sys)
1,正则复习,re.S,这个在用的最多,re.M多行模式,这个主要改变^和$的行为,每一行都是新串开头,每个回车都是结尾.re.L 在Windows和linux里面对一些特殊字符有不一样的识别,re. ...
- 【python】-- 模块、os、sys、time/datetime、random、logging、re
模块 模块,用一堆代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个 ...
- python 常用模块(一): os模块,序列化模块(json模块 pickle模块 )
1.os模块 2.序列化模块:(1)json模块 和 pickle模块 一.os模块 os.path.abspath: (1)把路径中不符合规范的/改成操作系统默认的格式 import os path ...
- Python常用模块(time, datetime, random, os, sys, hashlib)
time模块 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp) : 通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运 ...
- python标准模块(os及sys模块)
一.os模块 用于提供系统级别的操作 os.getcwd() 获取当前工作目录 os.stat('path/filename') 获取文件/目录信息,其中包括文件大小等 os.sep 获得操作系统特定 ...
- Python常用模块time & datetime &random 模块
时间模块前言 在Python中,与时间处理有关的模块就包括:time,datetime 一.在Python中,通常有这几种方式来表示时间: 时间戳 格式化的时间字符串 元组(struct_time)共 ...
随机推荐
- Ubuntu genymotion
官网注册帐号 下载genymotion-[VERSION]_[ARCH].bin 进入android studio In Android Studio, go to File > Setting ...
- 【LG3244】[HNOI2015]落忆枫音
题面 洛谷 题解 20pts 枚举每一条边是否在树中即可. 另10pts 我们考虑一张\(DAG\)中构成树的方法数,每个点选一个父亲即可,那么有 \[Ans=\prod_{i=1}^{n} deg_ ...
- OpenStack入门篇(五)之KVM性能优化及IO缓存介绍
1.KVM的性能优化,介绍CPU,内存,IO性能优化 KVM CPU-->qemu进行模拟ring 3-->用户应用 (用户态,用户空间)ring 0-->操作系统 (内核态,内核空 ...
- charles录制https请求
之前一直用windows系统,抓包什么的都是用的fiddler或者wireshark,操作比较简单,扩展性也比较强,现在因为工作原因换了mac,在网上一直没有找到fiddler的mac版本,就只能切换 ...
- 【RAC搭建报错】在RAC搭建到grid安装前的检查时,报错
这种ip的报错,无非是检查防火墙,ip配置的原因 而我防火墙已关闭,ip也没配错 最后的原因是因为我172.16.1.41/42这两个IP选的虚拟机没有配置网段 [grid@rac01 grid]$ ...
- 安装完.net core sdk 后部署 ASP.NET Core 出现错误502.5
将项目升级到和sdk一样的版本 然后 命令行执行 iisreset
- python全栈开发-前方高能-函数进阶
python_day_10 一.今日主要内容 1. 动态参数 位置参数的动态参数: *args 关键字参数的动态参数 : **kwargs 顺序: 位置,*args,默认值,**kwargs 在形参上 ...
- appium -- 页面出现弹窗,关闭后,无法识别页面元素(转)
原文:https://www.cnblogs.com/leavescy/p/9733001.html; 1. 问题:如图所示:在修改手势密码的过程中,点击了返回按钮后,弹出该弹窗:点击继续设置后,就发 ...
- jquery中国地图插件
插件下载地址: http://www.17sucai.com/preview/1266961/2018-09-18/map/js/jsMap-1.1.0.min.js jsMap 项目介绍 这是一个功 ...
- Spring 定时任务Scheduled 开发详细图文
Spring 定时任务Scheduled 开发 文章目录 一.前言 1.1 定时任务 1.2 开发环境 1.3 技术实现 二.创建包含WEB.xml 的Maven 项目 2.1 创建多模块项目task ...