【thrift】thrift详解
转载:http://zheming.wang/thrift-rpcxiang-jie.html
Thrift
Thrift是一个跨语言的服务部署框架,最初由Facebook于2007年开发,2008年进入Apache开源项目。Thrift通过一个中间语言(IDL, 接口定义语言)来定义RPC的接口和数据类型,然后通过一个编译器生成不同语言的代码(目前支持C++,Java, Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, Smalltalk和OCaml),并由生成的代码负责RPC协议层和传输层的实现。
Thrift实际上是实现了C/S模式,通过代码生成工具将接口定义文件生成服务器端和客户端代码(可以为不同语言),从而实现服务端和客户端跨语言的支持。用户在Thirft描述文件中声明自己的服务,这些服务经过编译后会生成相应语言的代码文件,然后用户实现服务(客户端调用服务,服务器端提服务)便可以了。其中protocol(协议层, 定义数据传输格式,可以为二进制或者XML等)和transport(传输层,定义数据传输方式,可以为TCP/IP传输,内存共享或者文件共享等)被用作运行时库。
Thrift的协议栈如下图所示:
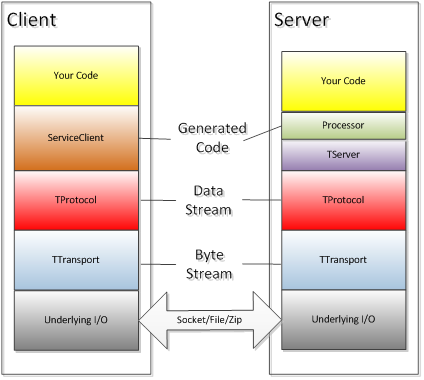
在Client和Server的最顶层都是用户自定义的处理逻辑,也就是说用户只需要编写用户逻辑,就可以完成整套的RPC调用流程。用户逻辑的下一层是Thrift自动生成的代码,这些代码主要用于结构化数据的解析,发送和接收,同时服务器端的自动生成代码中还包含了RPC请求的转发(Client的A调用转发到Server A函数进行处理)。
协议栈的其他模块都是Thrift的运行时模块:
底层IO模块,负责实际的数据传输,包括Socket,文件,或者压缩数据流等。
TTransport负责以字节流方式发送和接收Message,是底层IO模块在Thrift框架中的实现,每一个底层IO模块都会有一个对应TTransport来负责Thrift的字节流(Byte Stream)数据在该IO模块上的传输。例如TSocket对应Socket传输,TFileTransport对应文件传输。
TProtocol主要负责结构化数据组装成Message,或者从Message结构中读出结构化数据。TProtocol将一个有类型的数据转化为字节流以交给TTransport进行传输,或者从TTransport中读取一定长度的字节数据转化为特定类型的数据。如int32会被TBinaryProtocol Encode为一个四字节的字节数据,或者TBinaryProtocol从TTransport中取出四个字节的数据Decode为int32。
TServer负责接收Client的请求,并将请求转发到Processor进行处理。TServer主要任务就是高效的接受Client的请求,特别是在高并发请求的情况下快速完成请求。
Processor(或者TProcessor)负责对Client的请求做出相应,包括RPC请求转发,调用参数解析和用户逻辑调用,返回值写回等处理步骤。Processor是服务器端从Thrift框架转入用户逻辑的关键流程。Processor同时也负责向Message结构中写入数据或者读出数据。
Thrift的模块设计非常好,在每一个层次都可以根据自己的需要选择合适的实现方式。同时也应该注意到Thrift目前的特性并不是在所有的程序语言中都支持。例如C++实现中有TDenseProtocol没有TTupleProtocol,而Java实现中有TTupleProtocol没有TDenseProtocol。
利用Thrift用户只需要做三件事:
(1). 利用IDL定义数据结构及服务
(2). 利用代码生成工具将(1)中的IDL编译成对应语言(如C++、JAVA),编译后得到基本的框架代码
(3). 在(2)中框架代码基础上完成完整代码(纯C++代码、JAVA代码等)
为了实现上述RPC协议栈,Thrift定义了一套IDL,封装了server相关类, processor相关类,transport相关类,protocol相关类以及并发和时钟管理方面的库。下文将一一介绍。
数据类型
Thrift类型系统的目标是使编程者能使用完全在Thrift中定义的类型,而不论他们使用的是哪种编程语言。Thrift类型系统没有引入任何特殊的动态类型或包装器对象,也不要求开发者编写任何对象序列化或传输的代码。Thrift IDL文件在逻辑上,是开发者对他们的数据结构进行注解的一种方法,该方法告诉代码生成器怎样在语言之间安全传输对象,所需的额外信息量最小。
- Base Types(基本类型)
bool 布尔值,真或假
byte 有符号字节
i16 16位有符号整数
i32 32位有符号整数
i64 64位有符号整数
double 64位浮点数
string 与编码无关的文本或二进制字符串
许多语言中都没有无符号整数类型,且无法防止某些语言(如Python)的开发者把一个负值赋给一个整型变量,这会导致程序无法预料的行为。从设计角度讲,无符号整型鲜少用于数学目的,实际中更长用作关键词或标识符。这种情况下,符号是无关紧要的,可用有符号整型代替。
- Structs(结构体)
Thrift结构体定义了一个用在多种语言之间的通用对象。定义一个Thrift结构体的基本语法与C结构体定义非常相似。域可由一个整型域标识符(在该结构体的作用域内是唯一的),以及可选的默认值来标注。
struct Phone {
1: i32 id,
2: string number,
3: PhoneType type
}
- enum(枚举)
enum Operation {
ADD = 1,
SUBTRACT = 2,
MULTIPLY = 3,
DIVIDE = 4
}
- Containers(容器)
Thrift容器是强类型的,映射为通用编程语言中最常使用的容器。使用C++模板类来标注。有三种可用类型:
list<type>:映射为STL vector,Java ArrayList,或脚本语言中的native array。。
set<type>: 映射为为STL set,Java HashSet,Python中的set,或PHP/Ruby中的native dictionary。
Map<type1,type2>:映射为STL map,Java HashMap,PHP associative array,或Python/Ruby dictionary。
在目标语言中,定义将产生有read和write两种方法的类型,使用Thrift TProtocol对象对对象进行序列化和传输。
- Exceptions(异常)
异常在语法和功能上都与结构体相同,唯一的区别是它们使用exception关键词,而非struct关键词进行声明。 生成的对象继承自各目标编程语言中适当的异常基类,以便与任何给定语言中的本地异常处理无缝地整合。
exception InvalidOperation {
1: i32 whatOp,
2: string why
}
- Services(服务)
使用Thrift类型定义服务。对一个服务的定义在语法上等同于在面向对象编程中定义一个接口(或一个纯虚抽象类)。Thrift编译器生成实现该接口的客户与服务器存根。服务的定义如下:
service <name> {
<returntype> <name>(<arguments>)
[throws (<exceptions>)]
...
}
一个例子:
service StringCache {
void set(1:i32 key, 2:string value),
string get(1:i32 key) throws (1:KeyNotFound knf),
void delete(1:i32 key)
}
注意: 除其他所有定义的Thrift类型外,void也是一个有效的函数返回类型。void函数可添加一个async修饰符,产生的代码不等待服务器的应答。 一个纯void函数会向客户端返回一个应答,保证服务器一侧操作已完成。应用开发者应小心,仅当方法调用失败是可以接受的,或传输层已知可靠的情况下,才使用async优化。
===================================thrift对java的数据类型映射=================================
要编写Thrift定义文件,肯定要熟悉Thrift常见的数据类型:
1.基本类型(括号内为对应的Java类型):
bool(boolean): 布尔类型(TRUE or FALSE)
byte(byte): 8位带符号整数
i16(short): 16位带符号整数
i32(int): 32位带符号整数
i64(long): 64位带符号整数
double(double): 64位浮点数
string(String): 采用UTF-8编码的字符串
2.特殊类型(括号内为对应的Java类型):
binary(ByteBuffer):未经过编码的字节流
3.Structs(结构):
struct定义了一个很普通的OOP对象,但是没有继承特性。
struct UserProfile {
1: i32 uid,
2: string name,
3: string blurb
}
如果变量有默认值,可以直接写在定义文件里:
struct UserProfile {
1: i32 uid = 1,
2: string name = "User1",
3: string blurb
}
4.容器,除了上面提到的基本数据类型,Thrift还支持以下容器类型:
list(java.util.ArrayList):
set(java.util.HashSet):
map(java.util.HashMap):
用法如下:
struct Node {
1: i32 id,
2: string name,
3: list<i32> subNodeList,
4: map<i32,string> subNodeMap,
5: set<i32> subNodeSet
}
包含定义的其他Object:
struct SubNode {
1: i32 uid,
2: string name,
3: i32 pid
}
struct Node {
1: i32 uid,
2: string name,
3: list<subNode> subNodes
}
5.Services服务,也就是对外展现的接口:
service UserStorage {
void store(1: UserProfile user),
UserProfile retrieve(1: i32 uid)
}
===================================thrift对java的数据类型映射=================================
TServer
Thrift核心库提供一个TServer抽象类。
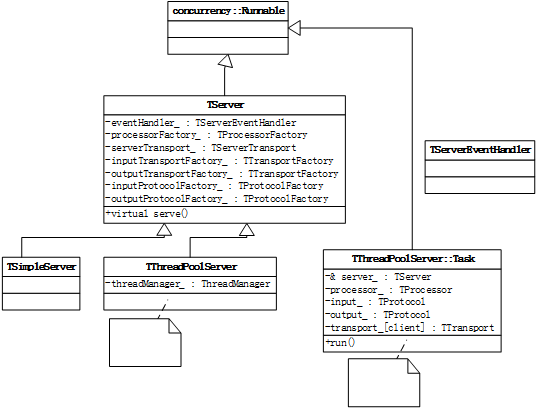
TServer在Thrift框架中的主要任务是接收Client的请求,并转到某个TProcessor上进行请求处理。针对不同的访问规模,Thrift提供了不同的TServer模型。Thrift目前支持的Server模型包括:
1. TSimpleServer:使用阻塞IO的单线程服务器,主要用于调试
2. TThreadedServer:使用阻塞IO的多线程服务器。每一个请求都在一个线程里处理,并发访问情况下会有很多线程同时在运行。
3. TThreadPoolServer:使用阻塞IO的多线程服务器,使用线程池管理处理线程。
4. TNonBlockingServer:使用非阻塞IO的多线程服务器,使用少量线程既可以完成大并发量的请求响应,必须使用TFramedTransport。
Thrift 使用 libevent 作为服务的事件驱动器, libevent 其实就是 epoll更高级的封装而已(在linux下是epoll)。处理大量更新的话,主要是在TThreadedServer和TNonblockingServer中进行选择。TNonblockingServer能够使用少量线程处理大量并发连接,但是延迟较高;TThreadedServer的延迟较低。实际中,TThreadedServer的吞吐量可能会比TNonblockingServer高,但是TThreadedServer的CPU占用要比TNonblockingServer高很多。
TServer的Benchmark可以参考: https://github.com/m1ch1/mapkeeper/wiki/TThreadedServer-vs.-TNonblockingServer
TServer对象通常如下工作:
1) 使用TServerTransport获得一个TTransport
2) 使用TTransportFactory,可选地将原始传输转换为一个适合的应用传输(典型的是使用TBufferedTransportFactory)
3) 使用TProtocolFactory,为TTransport创建一个输入和输出
4) 调用TProcessor对象的process()方法
恰当地分离各个层次,这样服务器代码无需了解任何正在使用的传输、编码或者应用。服务器在连接处理、线程等方面封装逻辑,而processor处理RPC。唯一由应用开发者编写的代码存在于Thrift定义文件和接口实现里。 Facebook已部署了多种TServer实现,包括单线程的TSimpleServer,每个连接一个线程的TThreadedServer,以及线程池的TThreadPoolServer。 TProcessor接口在设计上具有非常高的普遍性。不要求一个TServer使用一个生成的TProcessor对象。应用开发者可以很容易地编写在TProtocol对象上操作的任何类型的服务器(例如,一个服务器可以简单地将一个特定的对象类型流化,而没有任何实际的RPC方法调用)。
Thrift中定义一个server的方法如下:
TSimpleServer server(
boost::make_shared<CalculatorProcessor>(boost::make_shared<CalculatorHandler>()),
boost::make_shared<TServerSocket>(9090),
boost::make_shared<TBufferedTransportFactory>(),
boost::make_shared<TBinaryProtocolFactory>()); TThreadedServer server(
boost::make_shared<CalculatorProcessorFactory>(boost::make_shared<CalculatorCloneFactory>()),
boost::make_shared<TServerSocket>(9090), //port
boost::make_shared<TBufferedTransportFactory>(),
boost::make_shared<TBinaryProtocolFactory>()); const int workerCount = 4;//线程池容量
boost::shared_ptr<ThreadManager> threadManager = ThreadManager::newSimpleThreadManager(workerCount);
threadManager->threadFactory(boost::make_shared<PlatformThreadFactory>());
threadManager->start();
TThreadPoolServer server(
boost::make_shared<CalculatorProcessorFactory>(boost::make_shared<CalculatorCloneFactory>()),
boost::make_shared<TServerSocket>(9090),
boost::make_shared<TBufferedTransportFactory>(),
boost::make_shared<TBinaryProtocolFactory>(),
threadManager); TNonBlockingServer server(
boost::make_shared<CalculatorProcessorFactory>(boost::make_shared<CalculatorCloneFactory>()),
boost::make_shared<TServerSocket>(9090),
boost::make_shared<TFramedTransportFactory>(),
boost::make_shared<TBinaryProtocolFactory>(),
threadManager); server.serve();//启动server
TTransport
Thrift最底层的传输可以使用Socket,File和Zip来实现,Memory传输在Thrift之前的版本里有支持,Thrift 0.8里面就不再支持了。TTransport是与底层数据传输紧密相关的传输层。每一种支持的底层传输方式都存在一个与之对应的TTransport。在TTransport这一层,数据是按字节流(Byte Stream)方式处理的,即传输层看到的是一个又一个的字节,并把这些字节按照顺序发送和接收。TTransport并不了解它所传输的数据是什么类型,实际上传输层也不关心数据是什么类型,只需要按照字节方式对数据进行发送和接收即可。数据类型的解析在TProtocol这一层完成。
TTransport具体的有以下几个类:
TSocket:使用阻塞的TCP Socket进行数据传输,也是最常见的模式
THttpTransport:采用Http传输协议进行数据传输
TFileTransport:文件(日志)传输类,允许client将文件传给server,允许server将收到的数据写到文件中
TZlibTransport:与其他的TTransport配合使用,压缩后对数据进行传输,或者将收到的数据解压 下面几个类主要是对上面几个类地装饰(采用了装饰模式),以提高传输效率。
TBufferedTransport:对某个Transport对象操作的数据进行buffer,即从buffer中读取数据进行传输,或者将数据直接写入buffer
TFramedTransport:同TBufferedTransport类似,也会对相关数据进行buffer,同时,它支持定长数据发送和接收(按块的大小,进行传输)。
TMemoryBuffer:从一个缓冲区中读写数据
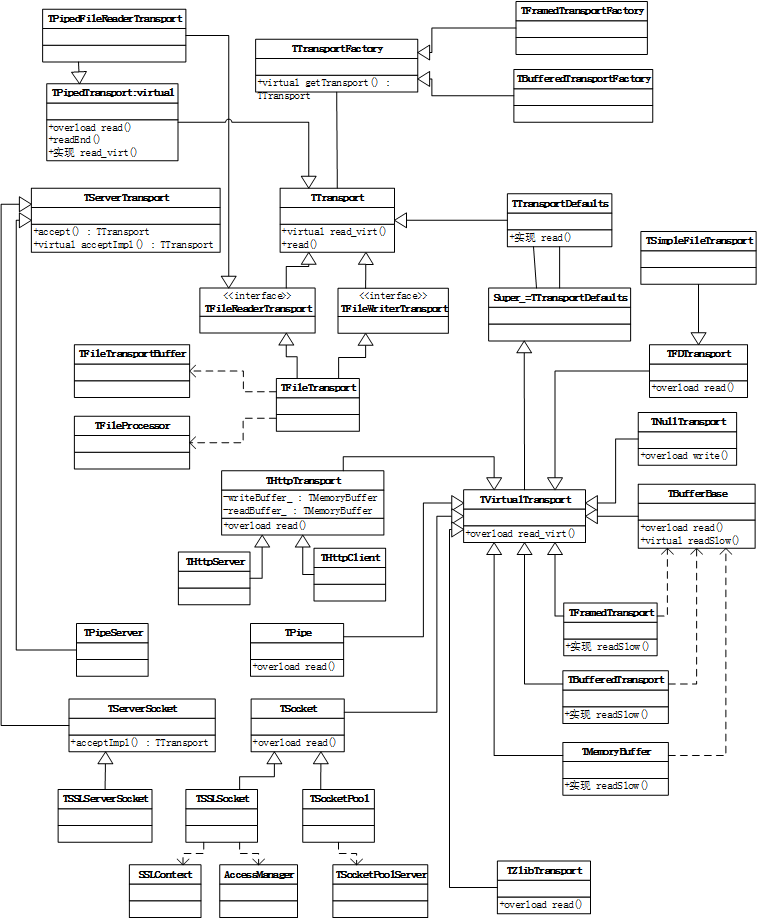
Thrift实现中,一个关键的设计选择就是将传输层从代码生成层解耦。从根本上,生成的Thrift代码只需要知道如何读和写数据。数据的源和目的地无关紧要,可以使一个socket,一段共享内存,或本地磁盘上的一个文件。TTransport(Thrift transport)接口支持以下方法:
open Opens the tranpsort
close Closes the tranport
isOpen Indicates whether the transport is open
read Reads from the transport
write Writes to the transport
flush Forces any pending writes
除以上的TTransport接口外,还有一个TServerTransport接口,用来接受或创建原始传输对象。它的接口如下:
open Opens the transport
listen Begins listening for connections
accept Returns a new client transport
close Closes the transport
TProtocol
TProtocol的主要任务是把TTransport中的字节流转化为数据流(Data Stream),在TProtocol这一层就会出现具有数据类型的数据,如整型,浮点数,字符串,结构体等。TProtocol中数据虽然有了数据类型,但是TProtocol只会按照指定类型将数据读出和写入,而对于数据的真正用途,需要在Thrift自动生成的Server和Client中里处理。
Thrift 可以让用户选择客户端与服务端之间传输通信协议的类别,在传输协议上总体划分为文本 (text) 和二进制 (binary) 传输协议,为节约带宽,提高传输效率,一般情况下使用二进制类型的传输协议为多数。常用协议有以下几种:
TBinaryProtocol: 二进制格式
TCompactProtocol: 高效率的、密集的二进制编码格式
TJSONProtocol: 使用 JSON 的数据编码协议进行数据传输
TSimpleJSONProtocol: 提供JSON只写协议, 生成的文件很容易通过脚本语言解析。
TDebugProtocol: 使用易懂的可读的文本格式,以便于debug
TCompactProtocol 高效的编码方式,使用了类似于ProtocolBuffer的Variable-Length Quantity (VLQ) 编码方式,主要思路是对整数采用可变长度,同时尽量利用没有使用Bit。对于一个int32并不保证一定是4个字节编码,实际中可能是1个字节,也可能是5个字节,但最多是五个字节。TCompactProtocol并不保证一定是最优的,但多数情况下都会比TBinaryProtocol性能要更好。
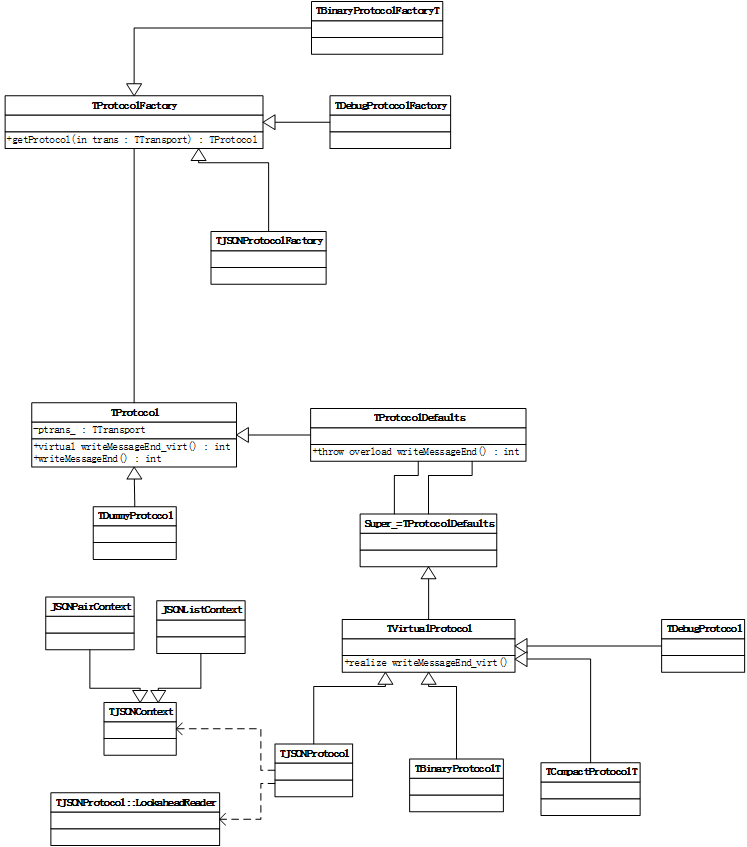
TProtocol接口非常直接,它根本上支持两件事: 1) 双向有序的消息传递; 2) 基本类型、容器及结构体的编码。
writeMessageBegin(name, type, seq)
writeMessageEnd()
writeStructBegin(name)
writeStructEnd()
writeFieldBegin(name, type, id)
writeFieldEnd()
writeFieldStop()
writeMapBegin(ktype, vtype, size)
writeMapEnd()
writeListBegin(etype, size)
writeListEnd()
writeSetBegin(etype, size)
writeSetEnd()
writeBool(bool)
writeByte(byte)
writeI16(i16)
writeI32(i32)
writeI64(i64)
writeDouble(double)
writeString(string)
name, type, seq = readMessageBegin()
readMessageEnd()
name = readStructBegin()
readStructEnd()
name, type, id = readFieldBegin()
readFieldEnd()
k, v, size = readMapBegin()
readMapEnd()
etype, size = readListBegin()
readListEnd()
etype, size = readSetBegin()
readSetEnd()
bool = readBool()
byte = readByte()
i16 = readI16()
i32 = readI32()
i64 = readI64()
double = readDouble()
string = readString()
注意到每个write函数有且仅有一个相应的read方法。WriteFieldStop()异常是一个特殊的方法,标志一个结构的结束。读一个结构的过程是readFieldBegin()直到遇到stop域,然后readStructEnd()。生成的代码依靠这个调用顺序,来确保一个协议编码器所写的每一件事,都可被一个相应的协议解码器读取。 这组功能在设计上更加注重健壮性,而非必要性。例如,writeStructEnd()不是严格必需的,因为一个结构体的结束可用stop域表示。
TProcessor/Processor
Processor是由Thrift生成的TProcessor的子类,主要对TServer中一次请求的 InputProtocol和OutputTProtocol进行操作,也就是从InputProtocol中读出Client的请求数据,向OutputProtcol中写入用户逻辑的返回值。Processor是TServer从Thrift框架转到用户逻辑的关键流程。同时TProcessor.process是一个非常关键的处理函数,因为Client所有的RPC调用都会经过该函数处理并转发。
Thrift在生成Processor的时候,会遵守一些命名规则,可以参考 Thrift Generator部分的介绍。
TProcessor对于一次RPC调用的处理过程可以概括为:
TServer接收到RPC请求之后,调用TProcessor.process进行处理
TProcessor.process首先调用TTransport.readMessageBegin接口,读出RPC调用的名称和RPC调用类型。如果RPC调用类型是RPC Call,则调用TProcessor.process_fn继续处理,对于未知的RPC调用类型,则抛出异常。
TProcessor.process_fn根据RPC调用名称到自己的processMap中查找对应的RPC处理函数。如果存在对应的RPC处理函数,则调用该处理函数继续进行请求响应。不存在则抛出异常。
a) 在这一步调用的处理函数,并不是最终的用户逻辑。而是对用户逻辑的一个包装。
b) processMap是一个标准的std::map。Key为RPC名称。Value是对应的RPC处理函数的函数指针。 processMap的初始化是在Processor初始化的时候进行的。Thrift虽然没有提供对processMap做修改的API,但是仍可以通过继承TProcessor来实现运行时对processMap进行修改,以达到打开或关闭某些RPC调用的目的。
- RPC处理函数是RPC请求处理的最后一个步骤,它主要完成以下三个步骤:
a) 调用RPC请求参数的解析类,从TProtocol中读入数据完成参数解析。不管RPC调用的参数有多少个,Thrift都会将参数放到一个Struct中去。Thrift会检查读出参数的字段ID和字段类型是否与要求的参数匹配。对于不符合要求的参数都会跳过。这样,RPC接口发生变化之后,旧的处理函数在不做修改的情况,可以通过跳过不认识的参数,来继续提供服务。进而在RPC框架中提供了接口的多Version支持。
b) 参数解析完成之后,调用用户逻辑,完成真正的请求响应。
c) 用户逻辑的返回值使用返回值打包类进行打包,写入TProtocol。
ThriftClient
了解了上述提到的TProtocol,TTransport,参数解析类和返回值打包类的概念,Thrift的Client就会变得非常容易理解。
ThriftClient跟TProcessor一样都主要操作InputProtocol和OutputProtocol,不同的是ThritClient将RPC调用分为Send和receive两个步骤。
Send步骤,将用户的调用参数作为一个整体的Struct写入TProcotol,并发送到TServer。
Send结束之后,ThriftClient便立刻进入Receive状态等待TServer的相应。对于TServer返回的响应,使用返回值解析类进行返回值解析,完成RPC调用。
Thrift RPC Version
Thrift的RPC接口支持不同Version之间的兼容性。需要注意的是:
1. 不要修改已经存在数据的字段编号
2. 新加的字段必须是optional的。以保证新生成的代码可以序列旧的Message。同时尽量为新加的字段添加默认值。
3. Required字段不能被删除。可以字段前加上"OBSOLETE_"来提醒后续用户该字段已经不再使用,同时字段编号不能复用。
4. 修改默认值对Version控制没有影响。因为默认值不会被传输,而是由数据的接受者来决定。
Thrift Generator
Thrift自动生成代码的代码框架被直接HardCode到了代码生成器里,因此对生成代码的结构进行修改需要重新编译Thrift,并不是十分方便。如果Thrift将代码结构保存到一个模板文件里,修改生成代码就会相对容易一些。
自动生成的代码就会遵守一定的命名规则。Thrift中几种主要的命名规则为:
1. IDLName + ”_types.h” :用户自定义数据类型头文件
2. IDLName + ”_constants.h” :用户自定义的枚举和常量数据类型头文件
3. ServiceName + “.h” :Server端Processor定义和Client定义头文件
4. ServericeName + ”_” + RPC名称 + “_args” :服务器端RPC参数解析类
5. ServericeName + ”_” + RPC名称 + “_result” :服务器端RPC返回值打包类
6. ServericeName + ”_” + RPC名称 + “_pargs” :客户端RPC参数打包类
7. ServericeName + ”_” + RPC名称 + “_presult” :客户端RPC返回值解析类
8. “process_” + RPC名称:服务器端RPC调用处理函数
9. “send_” + RPC名称:客户端发送RPC请求的方法
10. “recv_” + RPC名称:客户端接收RPC返回的方法
客户端和服务器的参数解析和返回值解析虽然针对的是同样的数据结构,但是Thrift并没有使用同一个类来完成任务,而是将客户端和服务器的解析类分开。
当RPC调用参数含有相同信息,并需要进行相同操作的时候,对参数解析类的集中管理就会变得非常有必要了。比如在一些用Thrift实现访问控制的系统中,每一个RPC调用都会加一个参数token作为访问凭证,并在每一个用户函数里进行权限检查。使用统一的参数解析类接口的话,就可以将分散的权限检查集中到一块进行处理。Thrift中有众多的解析类,这些解析类的接口类似,但是却没有一个共有的基类,对参数的集中管理造成了一定的困难。如果Thrift为解析类建立一个基类,并把解析类指针放到一个Map中,这样参数就可以进行集中管理,不仅可以进一步减小自动生成代码的体积,也满足了对参数进行统一管理的需求。
版本化(Versioning)
Thrift面对版本化和数据定义的改变是健壮的。将阶段性的改变推出到已部署的服务中的能力至关重要。系统必须能够支持从日志文件中读取旧数据,以及过时的客户(服务器)向新的服务器(客户)发送的请求。
- Field Identifiers(域标识符)
Thrift的版本化通过域标识符实现。Thrift中,一个结构体的每一个成员的域头都用一个唯一的域标识符编码。域标识符和类型说明符结合起来,唯一地标志该域。Thrift定义语言支持域标识符的自动分配,但最好始终显式地指定域标识符。标识符的指定如下所示:
struct Example {
1:i32 number=10,
2:i64 bigNumber,
3:double decimals,
4:string name="thrifty"
}
为避免手动和自动分配的标识符之间的冲突,省略了标识符的域所赋的标识符从-1开始递减,本语言对正的标识符仅支持手动赋值。
函数参数列表里能够、并且应当指定域标识符。事实上,参数列表不仅在后端表现为结构,实际上在编译器前端也表现为与结构体同样的代码。这允许我们对方法参数进行版本安全的修改。
service StringCache {
void set(1:i32 key, 2:string value),
string get(1:i32 key) throws (1:KeyNotFound knf),
void delete(1:i32 key)
}
可认为结构体是一个字典,标识符是关键字,而值是强类型的有名字的域。 域标识符在内部使用i16的Thrift类型。然而要注意,TProtocol抽象能以任何格式编码标识符。
- Isset
如果遇到了一个预料之外的域,它可被安全地忽视并丢弃。当一个预期的域找不到时,必须有某些方法告诉开发者该域不在。这是通过定义的对象内部的一个isset结构实现的。(Isset功能在PHP里默认为null,Python里为None,Ruby里为nil)。 各个Thrift结构内部的isset对象为各个域包含一个布尔值,表示该域在结构中是否存在。接收一个结构时,应当在直接对其进行操作之前,先检查一个域是否已设置(being set)。
class Example {
public:
Example() :
number(10),
bigNumber(0),
decimals(0),
name("thrifty") {}
int32_t number;
int64_t bigNumber;
double decimals;
std::string name;
struct __isset {
__isset() : number(false), bigNumber(false), decimals(false), name(false) {};
bool number;
bool bigNumber;
bool decimals;
bool name;
} __isset;
...
}
- Case Analysis(案例分析)
有四种可能发生版本不匹配的情况:
新加的域,旧客户端,新服务器。这种情况下,旧客户端不发送新的域,新服务器认出该域未设置,并对过时的请求执行默认行为。
移除的域,旧客户端,新服务器。这种情况下,旧客户端发送已被移除的域,而新服务器简单地无视它。
新加的域,新客户端,旧服务器。新客户端发送一个旧服务器不识别的域。旧服务器简单地无视该域,像平时一样进行处理。
移除的域,新客户端,旧服务器。这是最危险的情况,因为旧服务器不太可能对丢失的域执行适当的默认行为。这种情形下,建议在新客户端之前,先推出新服务器。
实现细节
- Target Languages(目标语言)
Thrift当前支持五种目标语言:C++,Java,Python,Ruby和PHP。在Facebook,用C++部署的服务器占主导地位。用PHP实现的Thrift服务也已被嵌入Apache web服务器,从后端透明地接入到许多使用THttpClient实现TTransport接口的前端结构。
- Servers and Multithreading(服务器和多线程)
为处理来自多个客户机的同时的请求,Thrift服务要求基本的多线程。对Thrift服务器逻辑的Python和Java实现来说,随语言发布的标准线程库提供了足够的支持。对C++实现来说,不存在标准的多线程运行时库。具体说来,不存在健壮的、轻量的和可移植的线程管理器及定时器类。为此,Thrift实现了自己的库,如下所述。
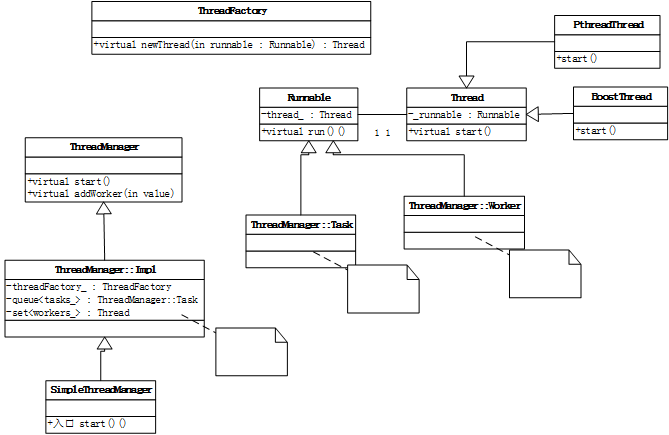
- ThreadManager
ThreadManager创建一池工作者线程,一旦有空闲的工作者线程,应用就可以调度任务来执行。ThreadManager并未实现动态线程池大小的调整,但提供了原语,以便应用能基于负载添加和移除线程。Thrift把复杂的API抽象留给特定应用,提供原语以制定所期望的政策,并对当前状态进行采样。
- TimerManager
TimerManager允许应用在未来某个时间点调度Runnable对象以执行。它具体的工作是允许应用定期对ThreadManager的负载进行抽样,并根据应用的方针使线程池大小发生改变。TimerManager也能用于生成任意数量的定时器或告警事件。 TimerManager的默认实现,使用了单个线程来处理过期的Runnable对象。因此,如果一个定时器操作需要做大量工作,尤其是如果它需要阻塞I/O,则应当在一个单独的线程中完成。
- Nonblocking Operation(非阻塞操作)
尽管Thrift传输接口更直接地映射到一个阻塞I/O模型,然而Thrift基于libevent和TFramedTransport,用C++实现了一个高性能的TNonBlockingServer。这是通过使用状态机,把所有I/O移动到一个严密的事件循环中来实现的。实质上,事件循环将成帧的请求读入TMemoryBuffer对象。一旦全部请求ready,它们会被分发给TProcessor对象,该对象能直接读取内存中的数据。
- Compiler(编译器)
Thrift编译器是使用C++实现的。尽管若用另一种语言来实现,代码行数可能会少,但使用C++能够强制语言结构的显示定义,使代码对新的开发者来说更容易接近。 代码生成使用两遍pass完成。第一遍只看include文件和类型定义。这一阶段,并不检查类型定义,因为它们可能依赖于include文件。第一次pass,所有包含的文件按顺序被扫描一遍。一旦解析了include树,第二遍pass过所有文件,将类型定义插入语法树,如果有任何未定义的类型,则引发一个error。然后,根据语法树生成程序。 由于固有的复杂性以及潜在的循环依赖性,Thrift显式地禁止前向声明。两个Thrift结构不能各自包含对方的一个实例。
- TFileTransport
TFileTransport通过将来的数据及数据长度成帧,并将它写到磁盘上,来对Thrift的请求/结构作日志。使用一个成帧的磁盘上格式,允许了更好的错误检查,并有助于处理有限数目的离散事件。TFileWriterTransport使用一个交换内存中缓冲区的系统,来确保作大量数据的日志时的高性能。一个Thrift日志文件被分裂成某一特定大小的块,被记入日志的信息不允许跨越块的边界。如果有一个可能跨越块边界的消息,则添加填塞直到块的结束,并且消息的第一个字节与下一个块的开始对齐。将文件划分成块,使从文件的一个特定点读取及解释数据成为可能。
Facebook的Thrift服务
Facebook中已经大量使用了Thrift,包括搜索、日志、手机、广告和开发者平台。下面讨论两种具体的使用。
- Search(搜索)
Facebook搜索服务使用Thrift作为底层协议和传输层。多语言的代码生成很适合搜索,因为可以用高效的服务器端语言(C++)进行应用开发,并且Facebook基于PHP的web应用可以使用Thrift PHP库调用搜索服务。Thrift使搜索团队能够利用各个语言的长处,快速地开发代码。
- Logging(日志)
使用Thrift TFileTransport功能进行结构化的日志。可认为各服务函数定义以及它的参数是一个结构化的日志入口,由函数名识别。
Thrift vs ProtocolBuffer
与ProtocolBuffer不同,Thrift不仅提供了跨语言的数据序列化和反序列化机制,更提供了跨语言的RPC实现。在Thrift的框架里,用户只需要实现用户逻辑即可完成从客户端到服务器的RPC调用。由于Thrift良好的模块设计,用户也可以非常方便的根据自己的需要选择合适的模块。例如RPC的Server既可以使用单线程的SimpleServer,也可以使用更高性能的多线程NonblockingServer。
Thrift和ProtocolBuffer解决的一个主要问题是结构化数据的序列化和反序列化。与ProtocolBuffer不同,Thrift在结构化数据之前加入了一个MessageHeader,并使用MessageHeader来完成RPC调用。在MessageBoy上,Thrift和ProtocolBuffer的结构大致相同,每一个数据字段都由Meta信息和数据信息两部分组成。Meta的内容会随着数据信息的不同而发生变化,例如在表示String类型的数据时,Meta信息中会包含一个字长信息,而表示int32类型的数据,并不需要这种Meta信息。但一般都会包含字段类型(Byte,i32,String…)和字段编号两个Meta信息。
Thrift不仅支持的程序语言比ProtocolBuffer多,而且支持的数据结构也比ProtocolBuffer要多。Thrift不仅支持Byte,i32,String等基本数据类型,更是支持List,Map,Set和Struct等复杂数据类型,但是Thrift在数据序列化和反序列化上的性能要比ProtocolBuffer稍微差一些。
Ref
【thrift】thrift详解的更多相关文章
- Thrift实现C#调用Java开发步骤详解
概述 Thrift实现C#调用Java开发步骤详解 详细 代码下载:http://www.demodashi.com/demo/10946.html Apache Thrift 是 Facebook ...
- 使用Zeppelin时出现at org.apache.zeppelin.interpreter.thrift.RemoteInterpreterService$Client.recv_getFormType(RemoteInterpreterService.java:288)错误的解决办法(图文详解)
不多说,直接上干货! 问题详解 org.apache.thrift.TApplicationException: Internal error processing getFormType at or ...
- Storm配置项详解【转】
Storm配置项详解 ——阿里数据平台技术博客:storm配置项详解 什么是Storm? Storm是twitter开源的一套实时数据处理框架,基于该框架你可以通过简单的编程来实现对数据流的实时处理变 ...
- Dubbo架构设计详解-转
Dubbo架构设计详解 2013-09-03 21:26:59 Yanjun Dubbo是Alibaba开源的分布式服务框架,它最大的特点是按照分层的方式来架构,使用这种方式可以使各个层之间解 ...
- [Hive] - Hive参数含义详解
hive中参数分为三类,第一种system环境变量信息,是系统环境变量信息:第二种是env环境变量信息,是当前用户环境变量信息:第三种是hive参数变量信息,是由hive-site.xml文件定义的以 ...
- Carbondata源码系列(二)文件格式详解
在上一章当中,写了文件的生成过程.这一章主要讲解文件格式(V3版本)的具体细节. 1.字典文件格式详解 字典文件的作用是在存储的时候将字符串等类型转换为int类型,好处主要有两点: 1.减少存储占用空 ...
- 详解RPC远程调用和消息队列MQ的区别
PC(Remote Procedure Call)远程过程调用,主要解决远程通信间的问题,不需要了解底层网络的通信机制. RPC框架 知名度较高的有Thrift(FB的).dubbo(阿里的). RP ...
- Dubbo支持的协议的详解
Dubbo支持dubbo.rmi.hessian.http.webservice.thrift.redis等多种协议,但是Dubbo官网是推荐我们使用Dubbo协议的.下面我们就针对Dubbo的每种协 ...
- 精通Dubbo——Dubbo支持的协议的详解
转: 精通Dubbo——Dubbo支持的协议的详解 2017年06月02日 22:26:57 孙_悟_空 阅读数:44500 Dubbo支持dubbo.rmi.hessian.http.webse ...
随机推荐
- Mybatis 之 缓存结构
Mybatis默认提供两种缓存方式,一级缓存是SqlSession 级别的缓存,二级缓存是Mapper 级别的缓存 SqlSession 级别的缓存,每个缓存是相对独立,互不影响:Mapper 级别 ...
- springcloud18---springCloudConfig
package com.itmuch.cloud; import org.springframework.beans.factory.annotation.Value; import org.spri ...
- oracle定时器job的使用
对于DBA来说,数据库Job再熟悉不过了,因为经常要数据库定时的自动执行一些脚本,或做数据库备份,或做数据的提炼,或做数据库的性能优化,包括重建索引等等的工作.但是,Oracle定时器Job时间的处理 ...
- 20145122 《Java程序设计》第二周学习总结
20145122 <Java程序设计>第2周学习总结 教材学习内容总结 在大一的时候我们学习了C语言,所以对第三章的知识不是很陌生,但有些新知识需要记忆. java常用的数据类型: byt ...
- 两行python代码,你是否可猜到运行结果
两行python代码,你是否可猜到运行结果 参考: http://www.cnblogs.com/way_testlife/archive/2011/07/20/2111549.html#215689 ...
- 内核加载模块时出现Unknown symbol等提示
一.背景 1.更改了内核的配置,重新编译了内核 2.未重新编译内核模块 3.板子上只更新了内核,并未更新文件系统 二.分析 发现是在加载内核模块时出现Unknown symbol等信息,恰逢当时只更新 ...
- 使用SpringBoot发送邮件
最后发送成功后,感觉SpringBoot真的很强大. http://www.ykmimi.com/email ↑待加入email输入的重载(可以不上传文件或可以不填写主内容) ↑待加入邮箱RegExp ...
- Python学习札记(二十八) 模块1
参考:模块 NOTE 1.模块:一个.py文件称为一个模块. 2.代码模块化的意义:a.提升程序的可维护性 b.不用重复造轮子 3.避免模块冲突,解决方法:引入了按目录来组织模块的方法,称为包(Pac ...
- LightOJ 1030 Discovering Gold (期望)
https://vjudge.net/problem/LightOJ-1030 题意: 在一个1×N的格子里,每个格子都有相应的金币数,走到相应格子的话,就会得到该格子的金币. 现在从1格子开始,每次 ...
- Python的hasattr() getattr() setattr() 函数使用方法详解--转载
hasattr(object, name)判断一个对象里面是否有name属性或者name方法,返回BOOL值,有name特性返回True, 否则返回False.需要注意的是name要用括号括起来 1 ...