Monte Carlo与TD算法
RL 博客:http://blog.sciencenet.cn/home.php?mod=space&uid=3189881&do=blog&view=me&from=space&srchtxt=RL&page=1
转自:http://blog.sciencenet.cn/home.php?mod=space&uid=3189881&do=blog&id=1128648,感谢分享
Monte carlo 和TD 都是model-free 的估值方法, TD 用于online RL 场景
强化学习中的Model-free问题主要的解决思路来源于统计方法。所谓统计方法又可分为Monte Carlo与TD算法。当学习任务可转化为episode task形式时,Monte Carlo与TD算法在实现上的不同主要体现在如何更新状态动作值函数。n-step TD算法则是由两种不同的值函数更新形式相结合所产生的,所以想要理解n-step TD算法,对Monte Carlo与TD进行透彻地的解析是十分有必要的。
Backup Diagram的区别
Monte Carlo方法:每个执行一个episode task,更新episode开始时的状态值函数。假设一个episode开始时的状态为StartStart,结束时的状态为EndEnd。如果将一个episode经过的状态写为状态集合StateState,则每个episode可更新的状态值函数集合可以写为V(State)V(State),用于更新状态值函数的Return=R(End)Return=R(End)。所以对Monte Carlo来说,一个episode中状态集合的值函数更新更像是对多个状态独立地更新,在强化学习中,可以称其为non-bootstrap,这也应证了Monte Carlo方法最为重要的性质:每一个状态的估计都是独立的,不依赖于其它状态的! 所以为了尽可能保证每个状态都可以被更新到,才有了Exploring Start策略(什么是Exploring Start?可以阅读【RL系列】从蒙特卡罗方法正式引入强化学习)下面将通过Backup Diagram将MC方法的更新形式更加清晰的表现出来:
Monte Carlo

TD方法:在任意一个episode task执行过程中所遇到的每个状态都会被更新,且每个状态的更新都依赖于下一个状态的值函数与到达下一个状态所获得的奖励。因为是边执行episode边更新值函数,这种方法又被称为on-line learning。实际上,类似MC方法将执行好的episode的轨迹(trajectory)保存在下来,再依照TD方法更新也可以达到与on-line learning相同的效果,但很明显,这个方法是off-line learning,也就是说线下与线上学习并不是区分Monte Carlo与TD算法的依据。TD算法的值函数更新可用下图表示出来:
TD
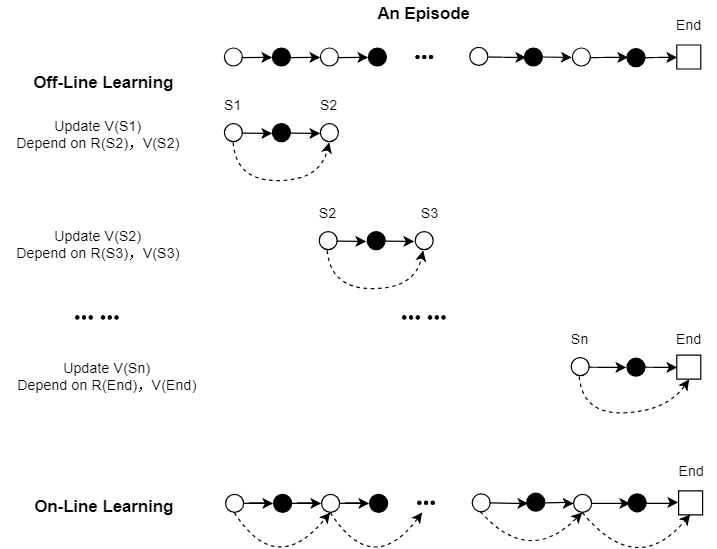
由上述示意图可以发现,TD方法的最后一步,也就是对状态SnSn的值函数更新与Monte Carlo方法并无任何区别。对状态SnSn的更新依赖于R(End)R(End)与V(End)V(End),但由于终止状态实际上不参与值函数更新过程,所以一般情况下都设V(End)=0V(End)=0,这样一来,这最后一步就与Monte Carlo方法一致了。
定步长与不定步长,TD方法
定步长与不定步长的更新方法在Bandit问题里就曾讨论过,定步长实际上为Recency-Weighted Average,不定步长则是Incremental形式。通常来说,Monte Carlo Prediction采用的是不定步长的值函数更新,TD方法则采用的是定步长形式,但也不是固定的,可以互换使用。理论上来说,定步长与不定步长的通用形式可以写为:
在这个式子中,αα通常小于1,若是常数不变则为定步长,若αα是变量则为不定步长。不论定步长与不定步长,该式皆可表示为对随机变量XX的均值估计,且该估计为无偏估计,也就是说当迭代次数无穷大时,这个估计的均值与期望E[X]E[X]是相同的。但是,αα越大估计值的方差就越大(特别注意,这是发生在当迭代次数较大进入收敛状态时),同时也存在着,αα越小收敛速度越慢的情况,所以对于αα的处理总是需要平衡收敛速度与均值方差。
Incremental Implementation作为不定步长的一种形式,可以说是比较好的平衡了收敛速度与均值方差之间的矛盾。对于Incremental形式来说,开始需要收敛速度时,αα很大,进入收敛状态后需要精确度时,αα又变的很小。但有时为了突出优化收敛速度,就必须要牺牲一定的精确度,最简单的方法就是提高αα的值,但需要估计的随机变量XX的方差大小给这种方法带来了不确定性。若是XX的方差D[X]D[X]较大,则估计均值的方差D[V(S)]D[V(S)]会对αα值的增大非常敏感,这样一来不但收敛速度未得到很大改善反而精确度下降得厉害。(举例:均匀分布与0-1分布)
为了解决这个问题,我们可以人为的构造出与原有需要估计的随机变量XX期望相同的新的随机变量YY,且希望随机变量YY的方差可以有所减小。在MC方法中,随机变量XX就是终态的Reward(除终态外各状态Reward为0),而人为构造出的随机变量YY在TD中被描述为:
为什么MC方法中的随机变量XX与TD方法中的随机变量YY的均值估计是等价的?我们使用一个简单例子来稍作计算(这里只考虑除终态Reward外其它Reward值为0的这种奖励设计,这样比较简单)。下图为一个以状态S1S1为起点的马尔可夫决策模型,每一条之路可以表示为一个episode。
例子一:
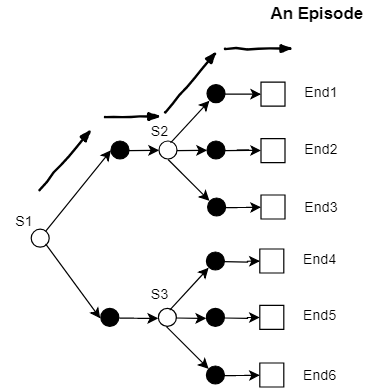
假设共执行了N个episode,其中到达终态的episode个数分别为N1~N7。估计状态S1S1的均值,先用Monte Carlo方法可以得出V(S1)V(S1)为:
如果使用TD方法,对状态S1S1的估计可以写为如下形式。假设episode经过状态S2S2的次数为K1K1,经过状态S3S3的次数为K2K2,其中K1=N1+N2+N3K1=N1+N2+N3与K2=N4+N5+N6K2=N4+N5+N6始终成立。
至于观察方差的变化,我们首先将通用的值函数更新方程做一个简单的化简:
值函数V(S)V(S)的不确定性全部来源于后一项αXαX。首先看αα对估计值方差的影响,有公式Var(cX+b)=c2Var(X)Var(cX+b)=c2Var(X)所以当αα扩大cc倍时,方差会变为原先的c2c2倍。让我们再举个例子,看一看随机变量XX本身对估计值方差的影响。
例子二:
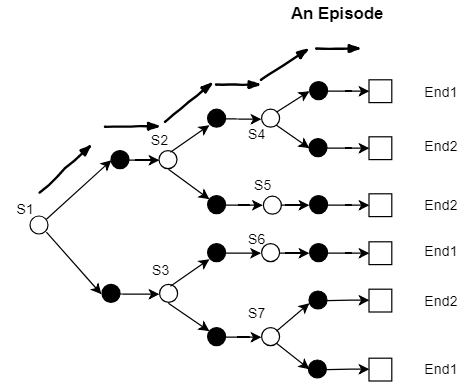
如上图所示,终态只有End1与End2,让我们假设episode到达End1所获得的Reward为1,到达End2所获得的Reward为0。如按照MC方法更新,则值函数通用更新方程中的随机变量XX即为终态时所获得的Reward,该随机变量XX定然服从伯努利分布(0-1分布)。假设每一类episode发生的概率皆为1/6(共有6条支路,6类episode),则随机变量XX的概率分布可以写为:
依据方差计算公式,随机变量XX的方差为:
如果我们按照TD方法更新,则可先计算出V(S2)=13V(S2)=13,V(S3)=23V(S3)=23,则TD方法所构造的随机变量YY的概率分布可以写为如下形式,并依据方差公式计算Var(Y)Var(Y):
TD方法的估计均值误差是MC方法的1/10,这也就是TD方法通常可以在保持与MC方法相同的估计均值误差的前提下会以更快的速度收敛的原因(Random Walk问题就很好的应证了这一点,可以参考Sutton书的Figure 6.2与Figure 6.3)。但实际上这也并非是绝对的,MC方法的表现非常仰赖Reward设计与实际的环境,当终态数量很多时,Reward值之间比较接近时,MC方法的估计均值误差也不一定差。
n-step TD
对于上述的例子二,可将其episode前进的过程分为三个阶段或三层(如下图所示),所构造的待估计随机变量Y={V(S2),V(S3)}Y={V(S2),V(S3)},可以视为估计第一层而依赖于第二层的估计,这就是1-step TD。若构造的待估计随机变量为第三层估计的值函数,即Y={V(S4),V(S5),V(S6),V(S7)}Y={V(S4),V(S5),V(S6),V(S7)},也就是对第一层的估计依赖于第三层,而跳过了第二层(第二层的估计直接依赖于终态的Reward),这就是2-step TD。可以证明2-step TD的估计均值与1-step TD和MC方法完全一致,但均值估计误差却各不相同。
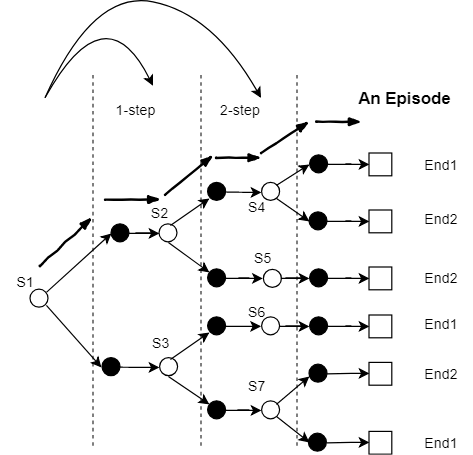
下面给出2-step TD的Backup Diagram:
2-Step TD

可以写出n-step TD的构造随机变量YY的通用表达形式:
通常来说,在进入收敛状态后,n-step TD的均值估计误差并不会一定优于1-step TD,但却可以很好的控制收敛的速度与RMSE之间的平衡,并且n-step TD的优势在于可以很好与eligibility traces相关联,这里就不再深入讨论,只探讨n-step TD本身。
转载本文请联系原作者获取授权,同时请注明本文来自管金昱科学网博客。
链接地址:http://blog.sciencenet.cn/blog-3189881-1128648.html
Monte Carlo与TD算法的更多相关文章
- 简析Monte Carlo与TD算法的相关问题
Monte Carlo算法是否能够做到一步更新,即在线学习? 答案显然是不能,如果可以的话,TD算法还有何存在的意义?MC算法必须要等到episode结束后才可以进行值估计的主要原因在于对Return ...
- 增强学习(四) ----- 蒙特卡罗方法(Monte Carlo Methods)
1. 蒙特卡罗方法的基本思想 蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法.该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基 ...
- Monte Carlo方法简介(转载)
Monte Carlo方法简介(转载) 今天向大家介绍一下我现在主要做的这个东东. Monte Carlo方法又称为随机抽样技巧或统计实验方法,属于计算数学的一个分支,它是在上世纪四十年代 ...
- PRML读书会第十一章 Sampling Methods(MCMC, Markov Chain Monte Carlo,细致平稳条件,Metropolis-Hastings,Gibbs Sampling,Slice Sampling,Hamiltonian MCMC)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:05:00 今天的主要内容:Markov Chain Monte Carlo,M ...
- Monte Carlo Approximations
准备总结几篇关于 Markov Chain Monte Carlo 的笔记. 本系列笔记主要译自A Gentle Introduction to Markov Chain Monte Carlo (M ...
- Introduction to Monte Carlo Tree Search (蒙特卡罗搜索树简介)
Introduction to Monte Carlo Tree Search (蒙特卡罗搜索树简介) 部分翻译自“Monte Carlo Tree Search and Its Applicati ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- Monte Carlo Method(蒙特·卡罗方法)
0-故事: 蒙特卡罗方法是计算模拟的基础,其名字来源于世界著名的赌城——摩纳哥的蒙特卡罗. 蒙特卡罗一词来源于意大利语,是为了纪念王子摩纳哥查理三世.蒙特卡罗(MonteCarlo)虽然是个赌城,但很 ...
- FAST MONTE CARLO ALGORITHMS FOR MATRICES II (快速的矩阵分解策略)
目录 问题 算法 LINEARTIMESVD 算法 CONSTANTTIMESVD 算法 理论 算法1的理论 算法2 的理论 代码 Drineas P, Kannan R, Mahoney M W, ...
随机推荐
- linux ln 命令,相当于windows快捷方式
ln -s 源文件 目标文件. ln -s ** **,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间, 硬链接ln ** **,没有参数-s, 它会在你选定的位置上生成一个和源文件大 ...
- dubbo集群容错之LoadBalance
原文地址:Dubbo 源码分析 - 集群容错之 LoadBalance dubbo 提供了4种负载均衡实现,分别是基于权重随机算法的 RandomLoadBalance.基于最少活跃调用数算法的 Le ...
- MYSQL 本地无ROOT权限 忘记密码
打开CMD窗口 net stop mysql //停止MYSQL mysqld -nt --skip-grant-tables //跳过密码检测. mysqld.exe在Bin目录下 然后另外新打 ...
- 创建自己的区块链游戏SLOT——以太坊代币(三)
一个以太坊合约版本的轮盘游戏,向合约转账ETH,有几率获得3,5,10,100倍奖励 合约地址:0x53DA598E70a1505Ad95cBF17fc5DCA0d2c51174b 捐赠ETH地址:0 ...
- 【树】Validate Binary Search Tree
需要注意的是,左子树的所有节点都要比根节点小,而非只是其左孩子比其小,右子树同样.这是很容易出错的一点是,很多人往往只考虑了每个根节点比其左孩子大比其右孩子小.如下面非二分查找树,如果只比较节点和其左 ...
- Android对敏感数据进行MD5加密(基础回顾)
1.在工具类的包下新建一个进行md5加密的工具类MD5Utils.java package com.example.mobilesafe.utils; import java.security.Mes ...
- split使用和特殊使用(包括截取第一个字符后的数据)
javaScript中关于split()的使用 1.一般使用对一个字符串使用split(),返回一个数组 例子: var testArr = "1,2,3,4,5": var ...
- PHP之mb_substr使用
mb_substr (PHP 4 >= 4.0.6, PHP 5, PHP 7) mb_substr - Get part of string mb_substr - 获取部分字符串 Descr ...
- 闲话handle和handler
虽然handle和handler只有一个字符之差,但在计算机的世界里,含义却大相径庭. 1. 先说说handle 北京话说"一边儿玩儿去,玩勺子把儿去","勺子把儿&qu ...
- 使用 Redis 实现分布式锁(转载)
背景 在一般的分布式应用中,要安全有效地同步多服务器多进程之间的共享资源访问,就要涉及到分布式锁.目前项目是基于 Tornado 实现的分布式部署,同时也使用了 Redis 作为缓存.参考了一些资料并 ...