Spark SQL join的三种实现方式
引言
join是SQL中的常用操作,良好的表结构能够将数据分散到不同的表中,使其符合某种规范(mysql三大范式),可以最大程度的减少数据冗余,更新容错等,而建立表和表之间关系的最佳方式就是join操作。
对于Spark来说有3种Join的实现,每种Join对应的不同的应用场景(SparkSQL自动决策使用哪种实现范式):
1.Broadcast Hash Join:适合一张很小的表和一张大表进行Join;
2.Shuffle Hash Join:适合一张小表(比上一个大一点)和一张大表进行Join;
2.Sort Merge Join:适合两张大表进行Join;
前两者都是基于Hash Join的,只不过Hash Join之前需要先shuffle还是先brocadcast。下面详细解释一下这三种Join的具体原理。
Hash Join
先来看看这样一条SQL语句:select * from order,item where item.id = order.i_id,参与join的两张表是order和item,join key分别是item.id以及order.i_id。现在假设Join采用的是hash join算法,整个过程会经历三步:
1.确定Build Table以及Probe Table:这个概念比较重要,Build Table会被构建成以join key为key的hash table,而Probe Table使用join key在这张hash table表中寻找符合条件的行,然后进行join链接。Build表和Probe表是Spark决定的。通常情况下,小表会被作为Build Table,较大的表会被作为Probe Table。
2.构建Hash Table:依次读取Build Table(item)的数据,对于每一条数据根据Join Key(item.id)进行hash,hash到对应的bucket中(类似于HashMap的原理),最后会生成一张HashTable,HashTable会缓存在内存中,如果内存放不下会dump到磁盘中。
3.匹配:生成Hash Table后,在依次扫描Probe Table(order)的数据,使用相同的hash函数(在spark中,实际上就是要使用相同的partitioner)在Hash Table中寻找hash(join key)相同的值,如果匹配成功就将两者join在一起。
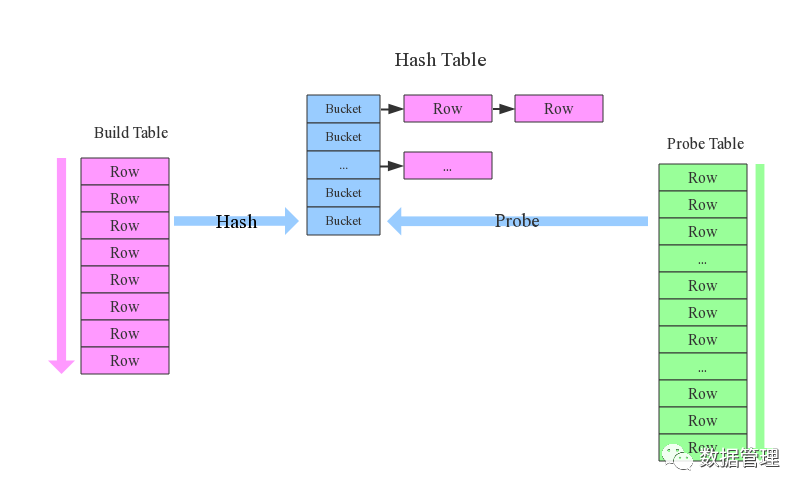
基础流程可以参考上图,这里有两个问题需要关注:
1.hash join性能如何?很显然,hash join基本都只扫描两表一次,可以认为O(a+b),较之最极端的是笛卡尔积运算O(a*b);
2.为什么Build Table选择小表?道理很简单,因为构建Hash Table时,最好可以把数据全部加载到内存中,因为这样效率才最高,这也决定了hash join只适合于较小的表,如果是两个较大的表的场景就不适用了。
上文说,hash join是传统数据库中的单机join算法,在分布式环境在需要经过一定的分布式改造,说到底就是尽可能利用分布式计算资源进行并行计算,提高总体效率,hash join分布式改造一般有以下两种方案:
1.broadcast hash join:将其中一张较小的表通过广播的方式,由driver发送到各个executor,大表正常被分成多个区,每个分区的数据和本地的广播变量进行join(相当于每个executor上都有一份小表的数据,并且这份数据是在内存中的,过来的分区中的数据和这份数据进行join)。broadcast适用于表很小,可以直接被广播的场景;
2.shuffle hash join:一旦小表比较大,此时就不适合使用broadcast hash join了。这种情况下,可以对两张表分别进行shuffle,将相同key的数据分到一个分区中,然后分区和分区之间进行join。相当于将两张表都分成了若干小份,小份和小份之间进行hash join,充分利用集群资源。
Broadcast Hash Join
大家都知道,在数据库的常见模型中(比如星型模型或者雪花模型),表一般分为两种:事实表和维度表,维度表一般指固定的、变动较少的表,例如联系人、物品种类,一般数据有限;而事实表一遍记录流水,比如销售清单等,通过随着时间的增长不断增长。
因为join操作是对两个表中key相同的记录进行连接,在SparkSQL中,对两个表做join的最直接的方式就是先根据key进行分区,再在每个分区中把key相同的记录拿出来做连接操作,但这样不可避免的涉及到shuffle,而shuffle是spark中比较耗时的操作,我们应该尽可能的设计spark应用使其避免大量的shuffle操作。
Broadcast Hash Join的条件有以下几个:
1.被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的信息,默认是10M;
2.基表不能被广播,比如left outer join时,只能广播右表。
看起来广播是一个比较理想的方案,但它有没有缺点呢?缺点也是很明显的,这个方案只能广播较小的表,否则数据的冗余传输就是远大于shuffle的开销;另外,广播时需要被广播的表collect到driver端,当频繁的广播出现时,对driver端的内存也是一个考验。
如下图所示,broadcast hash join可以分为两步:
1.broadcast阶段:将小表广播到所有的executor上,广播的算法有很多,最简单的是先发给driver,driver再统一分发给所有的executor,要不就是基于bittorrete的p2p思路;
2.hash join阶段:在每个executor上执行 hash join,小表构建为hash table,大表的分区数据匹配hash table中的数据;
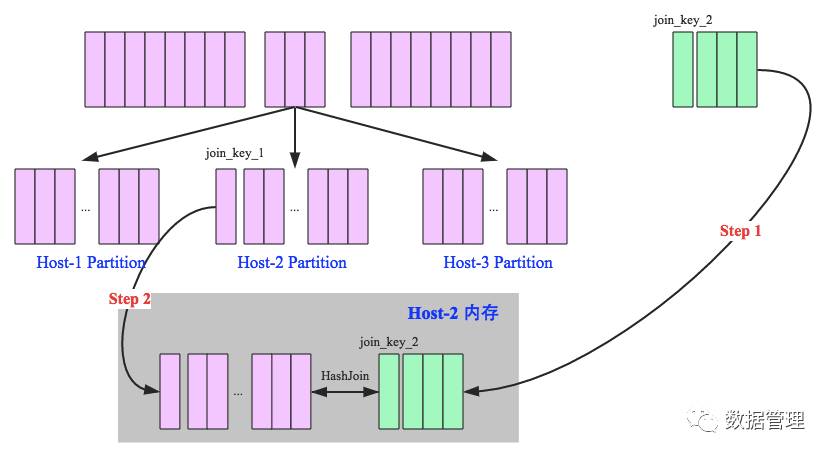
Shuffle Hash Join
当一侧的表比较小时,我们可以选择将其广播出去以避免shuffle,提高性能。但因为被广播的表首先被collect到driver端,然后被冗余的发送给各个executor上,所以当表比较大是,采用broadcast join会对driver端和executor端造成较大的压力。
我们可以通过将大表和小表都进行shuffle分区,然后对相同节点上的数据的分区应用hash join,即先将较小的表构建为hash table,然后遍历较大的表,在hash table中寻找可以匹配的hash值,匹配成功进行join连接。这样既在一定程度上减少了driver广播表的压力,也减少了executor端读取整张广播表的内存消耗。
Sshuffle Hash Join分为两步:
1.对两张表分别按照join key进行重分区(分区函数相同的时候,相同的相同分区中的key一定是相同的),即shuffle,目的是为了让相同join key的记录分到对应的分区中;
2.对对应分区中的数据进行join,此处先将小表分区构建为一个hash表,然后根据大表中记录的join key的hash值拿来进行匹配,即每个节点山单独执行hash算法。
Shuffle Hash Join的条件有以下几个:
1. 分区的平均大小不超过spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M
2. 基表不能被广播,比如left outer join时,只能广播右表
3. 一侧的表要明显小于另外一侧,小的一侧将被广播(明显小于的定义为3倍小,此处为经验值)
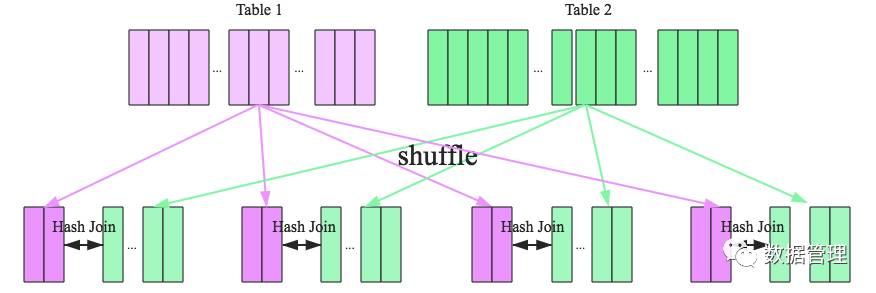
看到这里,可以初步总结出来如果两张小表join可以直接使用单机版hash join;如果一张大表join一张极小表,可以选择broadcast hash join算法;而如果是一张大表join一张小表,则可以选择shuffle hash join算法;那如果是两张大表进行join呢?
Sort Merge Join
上面介绍的方式只对于两张表有一张是小表的情况适用,而对于两张大表,但当两个表都非常大时,显然无论哪种都会对计算内存造成很大的压力。这是因为join时两者采取都是hash join,是将一侧的数据完全加载到内存中,使用hash code取join key相等的记录进行连接。
当两个表都非常大时,SparkSQL采用了一种全新的方案来对表进行Join,即Sort Merge Join。这种方式不用将一侧数据全部加载后再进行hash join,但需要在join前将数据进行排序。
首先将两张表按照join key进行重新shuffle,保证join key值相同的记录会被分在相应的分区,分区后对每个分区内的数据进行排序,排序后再对相应的分区内的记录进行连接。可以看出,无论分区有多大,Sort Merge Join都不用把一侧的数据全部加载到内存中,而是即用即丢;因为两个序列都有有序的,从头遍历,碰到key相同的就输出,如果不同,左边小就继续取左边,反之取右边。从而大大提高了大数据量下sql join的稳定性。
SparkSQL对两张大表join采用了全新的算法-sort-merge join,如下图所示,整个过程分为三个步骤:
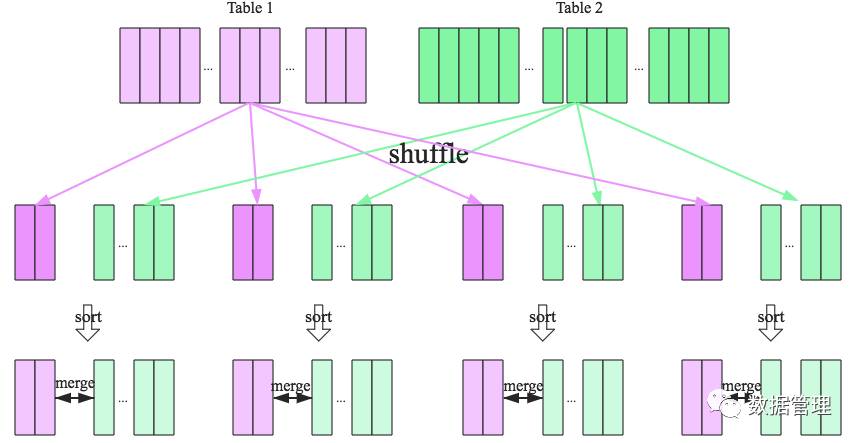
. shuffle阶段:将两张大表根据join key进行重新分区,两张表数据会分布到整个集群,以便分布式并行处理;
2. sort阶段:对单个分区节点的两表数据,分别进行排序;
3. merge阶段:对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边,见下图示意:
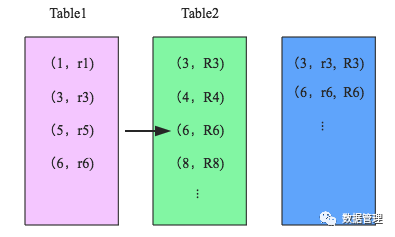
参考:
https://www.cnblogs.com/0xcafedaddy/p/7614299.html
Spark SQL join的三种实现方式的更多相关文章
- oracle Hash Join及三种连接方式
在Oracle中,确定连接操作类型是执行计划生成的重要方面.各种连接操作类型代表着不同的连接操作算法,不同的连接操作类型也适应于不同的数据量和数据分布情况. 无论是Nest Loop Join(嵌套循 ...
- SQL Join 的三种类型
1.Hash Match Join Hash运算(即散列算法) 和Hash表. Hash运算是一种编程技术,用来把数据转换为符号形式,使数据可以更容易更快速地被检索.例如,表中的一行数据,可以通过程序 ...
- hive join的三种优化方式
原网址:https://blog.csdn.net/liyaohhh/article/details/50697519 hive在实际的应用过程中,大部份分情况都会涉及到不同的表格的连接, 例如在进行 ...
- SQL Server的三种分页方式
直接上代码 --top not in方式 select top 条数 * from tablename where Id not in (select top 条数*页数 Id from tablen ...
- Linq to Sql : 三种事务处理方式
原文:Linq to Sql : 三种事务处理方式 Linq to SQL支持三种事务处理模型:显式本地事务.显式可分发事务.隐式事务.(from MSDN: 事务 (LINQ to SQL)).M ...
- Sort merge join、Nested loops、Hash join(三种连接类型)
目前为止,典型的连接类型有3种: Sort merge join(SMJ排序-合并连接):首先生产driving table需要的数据,然后对这些数据按照连接操作关联列进行排序:然后生产probed ...
- Asp.Net中的三种分页方式
Asp.Net中的三种分页方式 通常分页有3种方法,分别是asp.net自带的数据显示空间如GridView等自带的分页,第三方分页控件如aspnetpager,存储过程分页等. 第一种:使用Grid ...
- python笔记-20 django进阶 (model与form、modelform对比,三种ajax方式的对比,随机验证码,kindeditor)
一.model深入 1.model的功能 1.1 创建数据库表 1.2 操作数据库表 1.3 数据库的增删改查操作 2.创建数据库表的单表操作 2.1 定义表对象 class xxx(models.M ...
- mysql的三种连接方式
SQL的三种连接方式分为:左外连接.右外连接.内连接,专业术语分别为:LEFT JOIN.RIGHT JOING.INNER JOIN 内连接INNER JOIN:使用比较运算符来根据指定的连接的每个 ...
随机推荐
- Python函数汇总(陆续更新中...)
range的用法 函数原型:range(start, end, scan): 参数含义: start:计数从start开始.默认是从0开始.例如range(5)等价于range(0, 5); end: ...
- 深入理解C++中的初始化
C++经过这么多年的发展,已然成了一种文化和艺术,而这种艺术和文化并不是C++所固有的,是C++在各个方面的应用的总结和艺术化的结果.C++看起来比较复杂,但是深入其中你会发现C++是那么优美而富有哲 ...
- oracle表名、字段名大小写问题。
oracle 表名 .字段名 默认不区分大小写,除非建表语句中带双引号 如CREATE TABLE "TableName"("ID" number). CRE ...
- 加域(Netdom)
客户端运行: netdom.exe join %computername% /domain:testw.com /userd:testw\adadmin /passwordd:boc.123 /reb ...
- TMG阵列部署选择
如果用户环境中有多个网络出口,用EMS配置TMG是最佳选择.在这种情况下,可以使用EMS管理的阵列配置企业级访问规则.由于一个单一的策略适用于整个企业的所有阵列,因此管理成本将大大降低.用于EMS的服 ...
- HTML学习---基础知识学习
1.1. HTML 1.为什么要有HTML? "Hello" "<h1>Hello</h1>" - 浏览器渲染时使用一套HTML规则, ...
- 乘风破浪:LeetCode真题_011_Container With Most Water
乘风破浪:LeetCode真题_011_Container With Most Water 一.前言 下面我们继续进行编程练习,可以说对于实际问题的活学活用是非常重要的.比如我们这次的题目,就需要从中 ...
- 沉淀再出发:spring boot的理解
沉淀再出发:spring boot的理解 一.前言 关于spring boot,我们肯定听过了很多遍了,其实最本质的东西就是COC(convention over configuration),将各种 ...
- winform中webBrowser模拟网页操作中遇到的问题
我们通过网页上传一些特殊数据的时候,由于必填项众多,数量量大的时候,会发现工作相当繁琐,前段时间做了一个winform内嵌webBrowser模拟网页上传文档的小工具,发现了许多问题,总结一下: 先说 ...
- [EffectiveC++]item41:了解隐式接口和编译器多态
classes和templates都支持接口和多态,interfaces and polymorphism 对classes而言接口是显示的explicit,以函数签名为中心.多态则是通过virtua ...