深入Linux内核架构第一章笔记
1. Linux是多任务系统, 支持并发执行若干进程,系统同时真正运行的进程数目不超过CPU的数量,因此内核会按照时间间隔在不同进程之间切换。
2.确定那个进程运行多长时间的过程称为调度。
3.内核启动init进程作为第一个进程,该进程负责进一步的系统初始化操作,并显示登陆提示符或登陆界面。因此init是进程树的根,所有进程都直接或间接来源次进程。
4. 进程不是内核支持的唯一一种程序执行方式,除此以外,还有线程。
5. Linux将虚拟地址空间分为两部分,内核空间和用户空间。
6. Intel 将处理器分为4个特权状态,ring0 ~ ring3, 但是Linux只使用了两种状态:用户态和核心态。
7。用来将虚拟地址空间映射到物理地址空间的数据结构称为页表。
8。为了减少页表的大小并容许忽略不需要的区域,Linux将虚拟地址划分为多个部分,也就是多级页表。
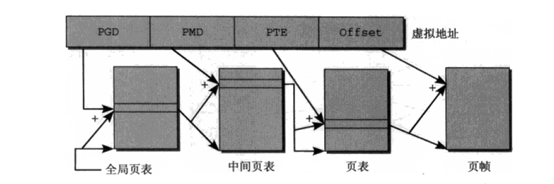
PGD (Page Global Directory) àPMD (Page Middle Directory)àPTE (Page Table Entry) àoffset
9. 多级页表节省了大量的内存,但是它的缺点是需要逐级访问多个数组才能将虚拟地址转换为物理地址,耗时较长。于是CPU通过MMU来优化访问操作及利用TLB(Translation lookaside buffer)来加速。
10. 内核很多时候需要分配连续页,为快速检测内存中的连续区域,一般情况下用伙伴系统,也就是空闲内存两两分组,每组中的两块内存称为伙伴。另外一种方法就是slab。
11.slab主要针对经常释放并分配的内存对象,需要对象时,可以快速分配。虽然slab的性能很好,但是对嵌入式系统而言,开销太大,于是有了一个 slab 模拟层,名为 SLOB。这个 slab 的替代品在小型嵌入式 Linux 系统中具有优势,但是即使它保存了 512KB 内存,依然存在碎片和难于扩展的问题。在禁用 CONFIG_SLAB 时,内核会回到这个 SLOB 分配器中
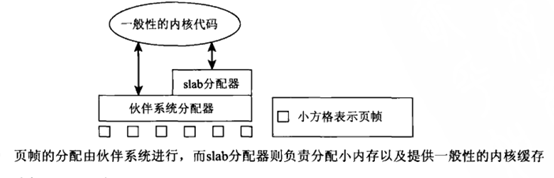
Linux 的slab 可有三种状态:
- 满的:slab 中的所有对象被标记为使用。
- 空的:slab 中的所有对象被标记为空闲。
- 部分:slab 中的对象有的被标记为使用,有的被标记为空闲。
与传统的内存管理模式相比, slab 缓存分配器提供了很多优点。
- 内核通常依赖于对小对象的分配,它们会在系统生命周期内进行无数次分配。
- slab 缓存分配器通过对类似大小的对象进行缓存而提供这种功能,从而避免了常见的碎片问题。
- slab 分配器还支持通用对象的初始化,从而避免了为同一目的而对一个对象重复进行初始化。
- slab 分配器还可以支持硬件缓存对齐和着色,这允许不同缓存中的对象占用相同的缓存行,从而提高缓存的利用率并获得更好的性能。
随着大规模多处理器系统和NUMA系统的广泛应用,slab分配器逐渐暴露出自身严重的不足:
- 较多复杂的队列管理。在slab分配器中存在众多的队列,例如针对处理器的本地缓存队列,slab中空闲队列,每个slab处于一个特定状态的队列之中。所以,管理太费劲了。
- slab管理数据和队列的存储开销比较大。每个slab需要一个struct slab数据结构和一个管理者kmem_bufctl_t型的数组。当对象体积较小时,该数组将造成较大的开销(比如对象大小为32字节时,将浪费1/8空间)。为了使得对象在硬件告诉缓存中对齐和使用着色策略,还必须浪费额外的内存。同时,缓冲区针对节点和处理器的队列也会浪费不少内存。测试表明在一个1000节点/处理器的大规模NUMA系统中,数GB内存被用来维护队列和对象引用。
- 缓冲区回收比较复杂。
- 对NUMA的支持非常复杂。slab对NUMA的支持基于物理页框分配器,无法细粒度的使用对象,因此不能保证处理器级的缓存来自同一节点(这个我暂时不太懂)。
- 冗余的partial队列。slab分配器针对每个节点都有一个partial队列,随着时间流逝,将有大量的partial slab产生,不利于内存的合理使用。
- 性能调优比较困难。针对每个slab可以调整的参数比较复杂,而且分配处理器本地缓存时,不得不使用自旋锁。
- 调试功能比较难于使用。
12. SLOB是slab在小型嵌入式系统上的一个模拟器,目的是为了降低资源开销。
13. 内存管理实际上是一种关于权衡的零和游戏。您可以开发一种使用少量内存进行管理的算法,但是要花费更多时间来管理可用内存。也可以开发一个算法来有效地管理内存,但却要使用更多的内存。最终,特定应用程序的需求将促使对这种权衡做出选择。
每个内存管理器都使用了一种基于堆的分配策略。在这种方法中,大块内存(称为 堆)用来为用户定义的目的提供内存。当用户需要一块内存时,就请求给自己分配一定大小的内存。堆管理器会查看可用内存的情况(使用特定算法)并返回一块内存。搜索过程中使用的一些算法有 first-fit(在堆中搜索到的第一个满足请求的内存块 )和 best-fit(使用堆中满足请求的最合适的内存块)。当用户使用完内存后,就将内存返回给堆。这种基于堆的分配策略的根本问题是碎片(fragmentation)。
14. 给出了 slab 结构的高层组织结构。在最高层是 cache_chain,这是一个 slab 缓存的链接列表。这对于 best-fit 算法非常有用,可以用来查找最适合所需要的分配大小的缓存(遍历列表)。cache_chain 的每个元素都是一个 kmem_cache 结构的引用(称为一个 cache)。它定义了一个要管理的给定大小的对象池。

15. proc 文件系统提供了一种简单的方法来监视系统中所有活动的 slab 缓存。这个文件称为 /proc/slabinfo,它除了提供一些可以从用户空间访问的可调整参数之外,还提供了有关所有 slab 缓存的详细信息。 
16. 全局变量jiffies用来记录自系统启动以来产生的节拍的总数。启动时,内核将该变量初始化为0,此后,每次时钟中断处理程序都会增加该变量的值。一秒内时钟中断的次数等于Hz,所以jiffies一秒内增加的值也就是Hz。 系统运行时间以秒为单位,等于jiffies/Hz。
注意,jiffies类型为无符号长整型(unsigned long),其他任何类型存放它都不正确。
Jiffies_64 是64为系统。
17.系统调用是用户进程和内核交互的经典方法。主要包括进程管理, 信号,文件,目录和文件系统,保护机制及定时器函数。
18.万物皆文件,外设包括字符设备,块设备及网络设备。
19.Linux支持的文件系统有:Ext2, Ext3, ResierFS,XFS, VFAT等。
Ext2基于inode, 也就是说每个文件都构造了一个单独的管理结构,称为inode。
VFS(Virtual File System or Virtual File Switch)将底层文件系的具体信息和应用层隔离开来。
20. 模块是个普通的程序,只不过运行在内核空间而不是用户空间。模块特性使得内核可以支持种类繁多的设备,而不会造成内核自身膨胀。
21.由于内核是基于页的内存映射来实现访问设备的,缓存也是按照页的组织缓存起来的,也就是页缓存。
22.内核提供的标准链表可以将任何类型的数据结构连接起来,当然这就意味着此链表不是类型安全的。此链表的机构存在于include/list.h下。
23. kobject是组成设备模型的基本结构。类似于java中的object类,是所有用来描述设备模型的数据结构的基类,它嵌入于所有的描述设备模型的容器对象中,例如bus,devices,drivers等。这些容器通过kobject链接起来,形成一个树状结构,这个树状结构与/sys中是一一对应的。需要注意的是,并不是说每一个kobject对象都需要在sysfs中表示,但是每一个被注册到系统中的kset都会被添加到sysfs文件系统中,一个kset对象就对应一个/sys中的一个目录,kset中的每一个kobject成员,都对应sysfs中一个文件或者一个目录。
目前为止,Kobject主要提供如下功能:
- 通过parent指针,可以将所有Kobject以层次结构的形式组合起来。
- 使用一个引用计数(reference count),来记录Kobject被引用的次数,并在引用次数变为0时把它释放(这是Kobject诞生时的唯一功能)。
- 和sysfs虚拟文件系统配合,将每一个Kobject及其特性,以文件的形式,开放到用户空间。
Kobject是基本数据类型,每个Kobject都会在"/sys/"文件系统中以目录的形式出现。
Ktype代表Kobject(严格地讲,是包含了Kobject的数据结构)的属性操作集合(由于通用性,多个Kobject可能共用同一个属性操作集,因此把Ktype独立出来了)。注3:在设备模型中,ktype的命名和解释,都非常抽象,理解起来非常困难,后面会详细说明。
Kset是一个特殊的Kobject(因此它也会在"/sys/"文件系统中以目录的形式出现),它用来集合相似的Kobject(这些Kobject可以是相同属性的,也可以不同属性的)。
Linux内核中有大量的驱动,而这些驱动往往具有类似的结构,根据面向对象的思想,我们就可以将这些共同的部分提取为父类,这个父类就是kobject,也就是驱动编程中使用的.ko文件的由来,下面这张图是我根据内核源码的kobject绘制的简单的UML图,从中可以看出,kobject包含了大量的设备必须的信息,而三大类设备驱动都需要包含这个kobject结构,也就是"继承"自kobject。一个kobject对象就对应sys目录中的一个设备。
内核源码中的kobject结构定义如下
//include/linux/kobject.h
struct kobject {
const char *name;
struct list_head entry;
struct kobject *parent;
struct kset *kset;
struct kobj_type *ktype;
struct kernfs_node *sd; /* sysfs directory entry */
struct kref kref;
#ifdef CONFIG_DEBUG_KOBJECT_RELEASE
struct delayed_work release;
#endif
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};
这个结构中,
struct kobject
name表示kobject对象的名字,对应sysfs下的一个目录。
entry是kobject中插入的head_list结构,
parent是指向当前kobject父对象的指针,体现在sys结构中就是包含当前kobject对象的目录对象,
kset表示当前kobject对象所属的集合,
ktype表示当前kobject的类型。
sd用于表示VFS文件系统的目录项,是设备与文件之间的桥梁,sysfs中的符号链接就是通过kernfs_node内的联合体实现的。
kref是对kobject的引用计数,当引用计数为0时,就回调之前注册的release方法释放该对象。
state_initialized:1初始化标志位,在对象初始化时被置位,表示对象是否已经被初始化。
state_in_sysfs:1表示kobject对象在sysfs中的状态,在对应目录中被创建则置1,否则为0。
state_add_uevent_sent:1是添加设备的uevent事件是否发送标志,添加设备时会向用户空间发送uevent事件,请求新增设备。
state_remove_uevent_sent:1是删除设备的uevent事件是否发送标志,删除设备时会向用户空间发送uevent事件,请求卸载设备
kobject,kset是Linux设备管理中的基本结构体,但在实际操作中我们几乎不会实际操作这些结构,因为他们本身并不具有针对某一个具体设备或驱动的信息,在Linux内核中,这两个结构都是被包含具体的设备结构中,比如cdev,gendisk等,从面向对象的角度考虑,就是每一类设备都可以看作这两个结构的子类。
通过上面的分析,我们可以看出这三者之间的关系,并画出下面的结构框图,sysfs中的上目录结构就是根据kset之间的数据组织方式进行呈现的。

总结,Ktype以及整个Kobject机制的理解。
Kobject的核心功能是:保持一个引用计数,当该计数减为0时,自动释放(由本文所讲的kobject模块负责) Kobject所占用的meomry空间。这就决定了Kobject必须是动态分配的(只有这样才能动态释放)。
而Kobject大多数的使用场景,是内嵌在大型的数据结构中(如Kset、device_driver等),因此这些大型的数据结构,也必须是动态分配、动态释放的。那么释放的时机是什么呢?是内嵌的Kobject释放时。但是Kobject的释放是由Kobject模块自动完成的(在引用计数为0时),那么怎么一并释放包含自己的大型数据结构呢?
这时Ktype就派上用场了。我们知道,Ktype中的release回调函数负责释放Kobject(甚至是包含Kobject的数据结构)的内存空间,那么Ktype及其内部函数,是由谁实现呢?是由上层数据结构所在的模块!因为只有它,才清楚Kobject嵌在哪个数据结构中,并通过Kobject指针以及自身的数据结构类型,找到需要释放的上层数据结构的指针,然后释放它。
所以,每一个内嵌Kobject的数据结构,例如kset、device、device_driver等等,都要实现一个Ktype,并定义其中的回调函数。同理,sysfs相关的操作也一样,必须经过ktype的中转,因为sysfs看到的是Kobject,而真正的文件操作的主体,是内嵌Kobject的上层数据结构!
Kobject是面向对象的思想在Linux kernel中的极致体现,但C语言的优势却不在这里,所以Linux kernel需要用比较巧妙(也很啰嗦)的手段去实现,
深入Linux内核架构第一章笔记的更多相关文章
- [Wolfgang Mauerer] 深入linux 内核架构 第一章 概述
作为Linux开发爱好者,从事linux 开发有两年多时间.做过bsp移植,熟悉u-boot代码执行流程:看过几遍<linux 设备驱动程序开发>,分析过kernel启动流程,写过驱动,分 ...
- Linux内核分析——第一章 Linux内核简介
第一章 Linux内核简介 一.Unix的历史 1.Unix系统成为一个强大.健壮和稳定的操作系统的根本原因: (1)简洁 (2)在Unix中,很多东西都被当做文件对待.这种抽象使对数据和对设备的 ...
- 《深入理解linux内核》第一章 序论
硬链接的限制
- [Wolfgang Mauerer] 深入linux 内核架构 第二章 进程管理与调度【未完】
作为Linux开发爱好者,从事linux 开发有三年多时间.做过bsp移植,熟悉u-boot代码执行流程:看过几遍<linux 设备驱动程序开发>,分析过kernel启动流程,写过驱动, ...
- 《Linux内核分析》读书笔记(四章)
<Linux内核分析>读书笔记(四章) 标签(空格分隔): 20135328陈都 第四章 进程调度 调度程序负责决定将哪个进程投入运行,何时运行以及运行多长时间,进程调度程序可看做在可运行 ...
- linux内核分析第一周学习笔记
linux内核分析第一周学习笔记 标签(空格分隔): 20135328陈都 陈都 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.co ...
- Linux内核设计与实现笔记_1_基本概念
Linux内核设计与实现笔记_1_基本概念 操作系统 系统这个词包含了操作系统和所有运行在它上面的应用程序.操作系统是指在整个系统中负责完成分最基本功能和系统管理的那些部分,这些部分应该包括: 内核, ...
- Linux内核设计第一周 ——从汇编语言出发理解计算机工作原理
Linux内核设计第一周 ——从汇编语言出发理解计算机工作原理 作者:宋宸宁(20135315) 一.实验过程 图1 编写songchenning5315.c文件 图2 将c文件汇编成32位机器语言 ...
- 十天学Linux内核之第一天---内核探索工具类
原文:十天学Linux内核之第一天---内核探索工具类 寒假闲下来了,可以尽情的做自己喜欢的事情,专心待在实验室里燥起来了,因为大二的时候接触过Linux,只是关于内核方面确实是不好懂,所以十天的时间 ...
随机推荐
- 一步步从Spring Framework装配掌握SpringBoot自动装配
目录 Spring Framework模式注解 Spring Framework@Enable模块装配 Spring Framework条件装配 SpringBoot 自动装配 本章总结 Spring ...
- 从零打造在线网盘系统之Struts2框架核心功能全解析
欢迎浏览Java工程师SSH教程从零打造在线网盘系统系列教程,本系列教程将会使用SSH(Struts2+Spring+Hibernate)打造一个在线网盘系统,本系列教程是从零开始,所以会详细以及着重 ...
- mysql客户端不能插入中文字符
问题:输入中文报错:Incorrect string value 步骤: 1.查看MySQL编码设置 show variables like '%character%'; 2.重新设置编码(注意:ut ...
- vscode 中使用 csscomb
我看中 csscomb 主要是用来给 css 属性排序用的,当然他也有格式化的作用: 1.安装不必说,但是装了之后,默认似乎没用: 2.点开 文件-首选项,搜下 csscomb 就知道了: 3.第一个 ...
- 07.Curator计数器
这一篇文章我们将学习使用Curator来实现计数器.顾名思义,计数器是用来计数的,利用ZooKeeper可以实现一个集群共享的计数器.只要使用相同的path就可以得到最新的计数器值,这是由Zo ...
- 修改bootstrap 的全局样式,bootstrap 3.0 是由html5和CSS 3组成的
方法一: 不建议使用 * {}选择器,因为在一些其他样式插件.特殊部分会有更好的字体样式设定,用*就会全部覆盖. 正常引入bootstrap的css样式后,记得将自定义的样式表放到其之后, <l ...
- CH1809匹配统计【KMP】
1809 匹配统计 0x18「基本数据结构」练习 描述 阿轩在纸上写了两个字符串,分别记为A和B.利用在数据结构与算法课上学到的知识,他很容易地求出了“字符串A从任意位置开始的后缀子串”与“字符串B” ...
- 修改Docker默认存储位置的方法
在日常使用中由于我们的根目录通常都比较小,如果想大量存储容器镜像的话很容易导致根目录写满 docker 默认的数据目录是/var/lib/docker 我们想要移动数据目录可以按照下面说明操作即可. ...
- 系统中同时有 python2和 python3,怎么让 ipython 选择不同的版本启动?
已经安装的情况下: > which ipython /usr/local/bin/ipython > cat /usr/local/bin/ipython #!/usr/local/op ...
- Python开发【模块】:CSV文件 数据可视化
CSV模块 1.CSV文件格式 要在文本文件中存储数据,最简单的方式是讲数据作为一系列逗号分隔的值(CSV)写入文件,这样的文件成为CSV文件,如下: AKDT,Max TemperatureF,Me ...