Spark MLib 基本统计汇总 1
1. 概括统计 summary statistics
MLlib支持RDD[Vector]列式的概括统计,它通过调用 Statistics 的 colStats方法实现。
colStats返回一个 MultivariateStatisticalSummary 对象,这个对象包含列式的最大值、最小值、均值、方差等等。
import org.apache.spark.mllib.linalg.Vector
import org.apache.spark.mllib.stat.{MultivariateStatisticalSummary, Statistics} val observations: RDD[Vector] = ... // define an RDD of Vectors
// Compute column summary statistics.
val summary: MultivariateStatisticalSummary = Statistics.colStats(observations)
println(summary.mean) // a dense vector containing the mean value for each column
println(summary.variance) // column-wise variance
println(summary.numNonzeros) // number of nonzeros in each column
2. 相关性 correlations
1) 基础回顾
协方差:两个变量总体误差的期望。
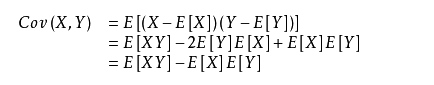
方差是一种特殊的协方差,即两个变量相等时。
所以方差 D(X)=E[X2]-(E(X))2
相关系数:用以反映变量之间相关关系密切程度的统计指标。

其中Cov(X,Y) 是X与Y的协方差,D(X),D(Y) 为其方差。
2)相关性系数的计算
计算两个数据集的相关性是统计中的常用操作,目前Mlib里面支持的有两种:皮尔森(Pearson)相关和斯皮尔曼(Spearman)相关。
Statistics 提供方法计算数据集的相关性。根据输入的类型,两个RDD[Double]或者一个RDD[Vector],输出将会是一个Double值或者相关性矩阵。
import org.apache.spark.SparkContext
import org.apache.spark.mllib.linalg._
import org.apache.spark.mllib.stat.Statistics
val sc: SparkContext = ...
val seriesX: RDD[Double] = ... // a series
val seriesY: RDD[Double] = ... // must have the same number of partitions and cardinality as seriesX
val correlation: Double = Statistics.corr(seriesX, seriesY, "pearson")
val data: RDD[Vector] = ... // note that each Vector is a row and not a column
val correlMatrix: Matrix = Statistics.corr(data, "pearson")
在上面输入 "pearson" 和"spearman" ,就会计算不同的系数。
3) Pearson 和Spearman相关系数
Pearson 就是我们平时学到的(是矩相关的一种)。
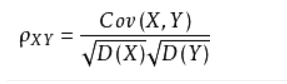
但有限制条件:
- 首先,必须假设数据是成对地从正态分布中取得的;
- 其次,数据至少在逻辑范围内是等距的。
Spearman相关系数,可以操作不服从正态分布的数据集。也就是秩相关(等级相关)的一种。
它是排序变量(ranked variables)之间的皮尔逊相关系数: 即对于大小为n的样本集,将原始的数据X_i和Y_i转换成排序变量rgX_i和rgY_i,再计算皮尔逊相关系数。
3. 分层取样
- 分层抽样法也叫类型抽样法。它是从一个可以分成不同子总体(或称为层)的总体中,按规定的比例从不同层中随机抽取样品(个体)的方法。
- 在
spark.mllib中,用key来分层。 - 分层采样方法
sampleByKey和sampleByKeyExact可以在key-value对的RDD上执行
sampleByKey :通过掷硬币的方式决定是否采样一个观察数据, 因此它需要我们传递(pass over)数据并且提供期望的数据大小(size)。
sampleByKeyExact :允许用户准确抽取f_k * n_k个样本, 这里f_k表示期望获取键为k的样本的比例,n_k表示键为k的键值对的数量。
比每层使用sampleByKey随机抽样需要更多的有意义的资源,但是它能使样本大小的准确性达到了99.99%。
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd.PairRDDFunctions val sc: SparkContext = ...
val data = ... // an RDD[(K, V)] of any key value pairs
val fractions: Map[K, Double] = ... // specify the exact fraction desired from each key // Get an exact sample from each stratum
val approxSample = data.sampleByKey(withReplacement = false, fractions)
val exactSample = data.sampleByKeyExact(withReplacement = false, fractions)
基础回顾:
泊松分布 Poission分布
 期望和方差均为 λ.
期望和方差均为 λ.
伯努利分布即二项分布
 期望是np,方差是np(1-p)
期望是np,方差是np(1-p)
当二项分布的n很大而p很小时,泊松分布可作为二项分布的近似,其中λ为np。通常当n≧10,p≦0.1时,就可以用泊松公式近似得计算。
重复抽样用泊松,不重复抽样用伯努利。
Spark MLib 基本统计汇总 1的更多相关文章
- Spark MLib 基本统计汇总 2
4. 假设检验 基础回顾: 假设检验,用于判断一个结果是否在统计上是显著的.这个结果是否有机会发生. 显著性检验 原假设与备择假设 常把一个要检验的假设记作 H0,称为原假设(或零假设) (null ...
- Spark MLib完整基础入门教程
Spark MLib 在Spark下进行机器学习,必然无法离开其提供的MLlib框架,所以接下来我们将以本框架为基础进行实际的讲解.首先我们需要了解其中最基本的结构类型,即转换器.估计器.评估器和流水 ...
- Spark MLib:梯度下降算法实现
声明:本文参考< 大数据:Spark mlib(三) GradientDescent梯度下降算法之Spark实现> 1. 什么是梯度下降? 梯度下降法(英语:Gradient descen ...
- Spark mlib的本地向量
Spark mlib的本地向量有两种: DenseVctor :稠密向量 其创建方式 Vector.dense(数据) SparseVector :稀疏向量 其创建方式有两种: 方法一:Vector. ...
- 利用Oracle内置分析函数进行高效统计汇总
分析函数是Oracle从8.1.6开始引入的一个新的概念,为我们分析数据提供了一种简单高效的处理方式.在分析函数出现以前,我们必须使用自联查询,子查询或者内联视图,甚至复杂的存储过程实现的语句,现 ...
- spark 省份次数统计实例
//统计access.log文件里面IP地址对应的省份,并把结果存入到mysql package access1 import java.sql.DriverManager import org.ap ...
- sql简单实用的统计汇总案例参考
USE [PM]GO/****** 对象: StoredProcedure [dbo].[LfangSatstics] 脚本日期: 08/24/2013 10:57:48 ******/SET ...
- Spark笔记——技术点汇总
目录 概况 手工搭建集群 引言 安装Scala 配置文件 启动与测试 应用部署 部署架构 应用程序部署 核心原理 RDD概念 RDD核心组成 RDD依赖关系 DAG图 RDD故障恢复机制 Standa ...
- Spark Streaming 002 统计单词的例子
1.准备 事先在hdfs上创建两个目录: 保存上传数据的目录:hdfs://alamps:9000/library/SparkStreaming/data checkpoint的目录:hdfs://a ...
随机推荐
- wk_04
函数 函数是对程序逻辑进行结构化或过程化的一直编程方法.能将整块代码巧妙的隔离成易于管理的小块,把重复代码放到函数中而不是进行大量的拷贝--这样既能节省空间,也有助于保持一致性,因为你只需要改变单个的 ...
- PL/SQL流程控制语句
PL/SQL流程控制语句介绍PL/SQL的流程控制语句, 包括如下三类:控制语句: IF 语句循环语句: LOOP语句, EXIT语句顺序语句: GOTO语句, NULL语句①if语句 IF < ...
- 返回标量CLR自定义函数
昨天有学习了返回表自定义函数<CLR Table-Valued函数>http://www.cnblogs.com/insus/p/4378354.html.今天学习另一个,实现返回标量(S ...
- Tomcat 内存溢出对应解决方式
1.Tomcat内存溢出的原因 生产环境中Tomcat内存设置不好很容易出现内存溢出.造成内存溢出是不一样的,当然处理方式也不一样. 这里根据平时遇到的情况和相关资料进行一个总结.常见的一般会有下面三 ...
- Android 开发1000问笔记
11.android使用全局变量 定义Data类继承Application 在manifest.xml中声明 http://blog.csdn.net/feiyangxiaomi/article/de ...
- closure!
总结一下闭包. 闭包的定义:当一个内部函数被其外部函数之外的变量所引用时,就形成了一个闭包. 一个最简单的闭包: function A(){ var count=0; return function( ...
- JSON返回DateTime/Date('123123123')/解决办法
Date.prototype.format = function (format) //author: meizz { var o = { "M+& ...
- 让计算机崩溃的python代码,求共同分析
在现在的异常机制处理的比较完善的编码系统里面,让计算机完全崩溃无法操作的代码还是不多的.今天就无意运行到这段python代码,运行完,计算机直接崩溃,任务管理器都无法调用,任何键都用不了,只能强行电源 ...
- Groovy与Gradle在Android中的应用
大家都知道, Android Studio 的编译构建,是基于Gradle的, 而Gradle又是基于Groovy, Groovy又是基于Java的 Android Studio 的gradle 本身 ...
- spring+mybaties+springMvc+slf4j所需jar包