Spark在Yarn上运行Wordcount程序
前提条件
1.CDH安装spark服务
2.下载IntelliJ IDEA编写WorkCount程序
3.上传到spark集群执行
一.下载IntellJ IDEA编写Java程序
1.下载IDEA
官网地址:http://www.jetbrains.com/idea/ 下载IntlliJ IDEA后,进行安装。
2.新建Java项目
1.点击File
2.点击New Project
3.点击Java
注意:Project SDK要选择本机安装的JDK的位置,由于我的JDK是1.7,所以下面的Java EE version我选择的是Java EE 7
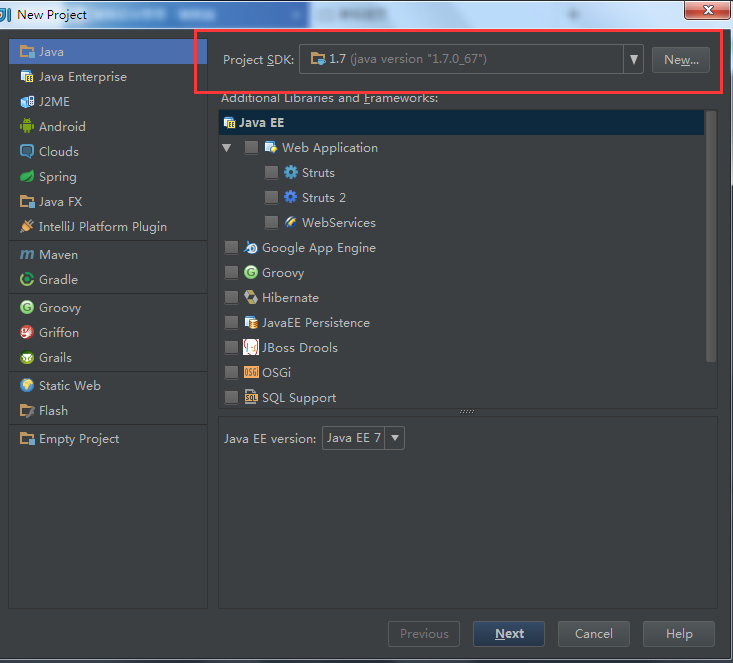
4.点击Next后,出现如下界面,勾选Create project from template,然后点击Next

5.点击Next,填写相应的项目名称,package等相关信息
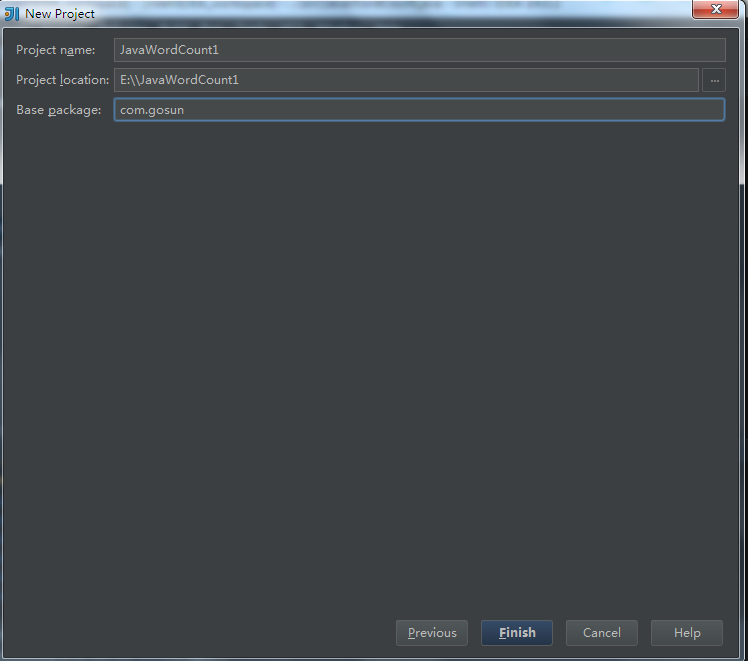
6.点击Finish,,出现如下界面,右键选择Refactor->Rename修改类名为自己想要的类名即可。

7.添加spark-assembly-1.3.0-cdh5.4.2-hadoop2.6.0-cdh5.4.2.jar到项目中
7.1创建名称为lib的目录

7.2将spark-assembly-1.3.0-cdh5.4.2-hadoop2.6.0-cdh5.4.2.jar (在spark集群的位置为:/usr/lib/spark/assembly/lib目录下)copy到lib目录下
然后右键点击jar包选择add Library,完成该动作后,在项目中就可以引用此jar包中的类了。
8.用Java实现WordCount功能
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2; import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern; public final class JavaWordCount { private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
if(args.length<1){
System.err.print("Usage:JavaWordCount<file>");
System.exit(1);
} SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext ctx = new JavaSparkContext(sparkConf);
JavaRDD<String> lines = ctx.textFile(args[0],1);
System.out.println(System.getenv("SPARK_HOME"));
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(SPACE.split(s));
}
}); JavaPairRDD<String,Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s,1);
}
}); JavaPairRDD<String,Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) throws Exception {
return i1+i2;
}
}); List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?, ?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
ctx.stop();
}
}
9.打成jar包
9.1点击File
9.2选择Project Structure
9.3选择Artifacts
可修改右边Name生成jar包的名称
9.4点击OK,完成生成jar包,可在对应的目录下找到刚才生成的jar包
10.将生成的jar包上传到spark某个目录下
11.spark-submit --master yarn-client --name JavaWordCount --class JavaWordCount --executor-memory 1G --total-executor-cores 2 /etc/spark/JavaWordCount.jar hdfs://master:8020/suajing/install.log
其中,红色标注部分根据实际的项目进行修改,
我的项目名称为JavaWordCount,则--name 为JavaWordCount,
我的Class没有pacakage,如果你的class是在某个pacakage底下,则需要将class修改成包+类名全路径,例如:com.gosun.JavaWordCount。
我的jar包放在/etc/spark/目录下,写成/etc/spark/JavaWordCount.jar
hdfs上的文件路径为上面所示。
12.执行结果:未报错就表示执行成功了,可以看到如下统计的结果

Spark在Yarn上运行Wordcount程序的更多相关文章
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- Hadoop 系列文章(三) 配置部署启动YARN及在YARN上运行MapReduce程序
这篇文章里我们将用配置 YARN,在 YARN 上运行 MapReduce. 1.修改 yarn-env.sh 环境变量里的 JAVA_HOME 路径 [bamboo@hadoop-senior ha ...
- Hadoop YARN上运行MapReduce程序
(1)配置集群 (a)配置hadoop-2.7.2/etc/hadoop/yarn-env.sh 配置一下JAVA_HOME export JAVA_HOME=/home/hadoop/bigdata ...
- 在Spark上运行WordCount程序
1.编写程序代码如下: Wordcount.scala package Wordcount import org.apache.spark.SparkConf import org.apache.sp ...
- Yarn上运行spark-1.6.0
目录 目录 1 1. 约定 1 2. 安装Scala 1 2.1. 下载 2 2.2. 安装 2 2.3. 设置环境变量 2 3. 安装Spark 2 3.1. 下载 2 3.2. 安装 2 3.3. ...
- 将java开发的wordcount程序提交到spark集群上运行
今天来分享下将java开发的wordcount程序提交到spark集群上运行的步骤. 第一个步骤之前,先上传文本文件,spark.txt,然用命令hadoop fs -put spark.txt /s ...
- Apache Spark源码走读之10 -- 在YARN上运行SparkPi
y欢迎转载,转载请注明出处,徽沪一郎. 概要 “spark已经比较头痛了,还要将其运行在yarn上,yarn是什么,我一点概念都没有哎,再怎么办啊.不要跟我讲什么原理了,能不能直接告诉我怎么将spar ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
- Spark standalone简介与运行wordcount(master、slave1和slave2)
前期博客 Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master.slave1和slave2) Spark运行模式概述 1. Stan ...
随机推荐
- IE下Array.prototype.slice.call(params,0)
i8 不支持 Array.prototype.slice.call(params,0) params可以是 HTMLCollection.类数组.string字符串
- Sqlserver自定义函数Function
一.FUNCTION: 在sqlserver2008中有3中自定义函数:标量函数/内联表值函数/多语句表值函数,首先总结下他们语法的异同点: 同点:1.创建定义是一样的: ...
- 类型“System.Windows.Markup.IQueryAmbient”在未被引用的程序集中定义
错误 1 类型"System.Windows.Markup.IQueryAmbient"在未被引用的程序集中定义.必须添加对程序集"System.Xaml, ...
- ural 1252. Sorting the Tombstones
1252. Sorting the Tombstones Time limit: 1.0 secondMemory limit: 64 MB There is time to throw stones ...
- 移动H5前端性能优化指南(转载)
移动H5前端性能优化指南 概述 1. PC优化手段在Mobile侧同样适用2. 在Mobile侧我们提出三秒种渲染完成首屏指标3. 基于第二点,首屏加载3秒完成或使用Loading4. 基于联通3G网 ...
- CodeForces - 241E Flights 题解
题目大意: 有一个有向无环图,n个点m条边,所有边权为1或2,求一组使所有从1到n的路径长度相同的边权的方案. 思路: 设从1到i的最短路为dist[i],若有一条从x到y的边,则1<=dist ...
- Android MuPDF 阅读PDF文件
MuPDF是一款轻量级的开源软件,可以用来阅读PDF文件.下载完源代码以后,想要运行成功,除了Android SDK之外,还需要Android NDK环境,因此有点麻烦. 但是一旦安装完必须的环境以后 ...
- android pcm
Android.media package里包含声音录放的两个类AudioRecord和AudioTrack.前者用来录制,后者用来播放. 配置 pcm: int channel = AudioFor ...
- Leetcode Word Break
Given a string s and a dictionary of words dict, determine if s can be segmented into a space-separa ...
- 如何在电脑上测试手机网站(补充)和phonegap
颜海镜 介绍了专业人士精准测试手机网站的经验 http://www.cnblogs.com/yanhaijing/p/3557261.html, 因为太专业了,稍显复杂和琐碎,这里我介绍下我一直关注的 ...