入门大数据---Kylin是什么?
一.Kylin是什么?
Apache Kylin是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
1.定义一个星形或雪花形数据模型
2.在定义的表上创建cube
3.使用标准的SQL通过ODBC,JDBC和Restful API即可在亚秒内查询到结果。
二.解决问题
任何技术的出现都不是偶然,往往都是应需求而生,Kylin也不例外。Kylin直接面对的问题,是针对大数据不同维度频繁查询问题,比如拉钩网,我们切换一个城市,它就要把当前城市的所有岗位显示出来,利用普通的Hive根本没法做到实时响应,所以就发明了Kylin。Kylin不仅仅提高了查询性能,而且大大降低了对硬件的要求。
三.OLTP与OLAP
数据处理可以大致分为两类:联机事务处理OLTP,联机分析处理OLAP。
3.1 OLTP
OLTP(On-Line Transaction Processing):联机事务处理,OLTP 是传统的关系型数据库的主要应用, 主要是基本的、日常的事务处理,例如银行交易。主要用于业务类系统,主要供基层人员使用,进行一线业务操作。OLTP 表示事务性非常高的系统,一般都是高可用的在线系统,以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的 Transaction 以及 Execute SQL的数量。在这样的系统中,单个数据库每秒处理的 Transaction 往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。典型的 OLTP 系统有电子商务系统、银行、证券等,如美国 eBay 的业务数据库,就是很典型的 OLTP 数据库。
3.2 OLAP
OLAP(On-Line Analytical Processing):联机分析处理,OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP 数据分析的目标是探索并挖掘数据价值,作为企业高层进行决策的参考。OLAP 分析处理是一种共享多维信息的快速分析技术;OLAP 利用多维数据库技术使用户从不同角度观察数据;OLAP 用于支持复杂的分析操作,侧重于对管理人员的决策支持,可以满足分析人员快速、灵活地进行大数据量的复杂查询的要求,并且以一种直观、易懂的形式呈现查询结果,辅助决策。
3.2.1 OLAP基本概念:
变量:度量的具体的值。比如身高,体重的值。
维度:不同的角度,比如身高,收入,家庭成员。
事实:组合维度求得的值,也就是 维度+变量组合。
3.2.2 OLAP基本操作:
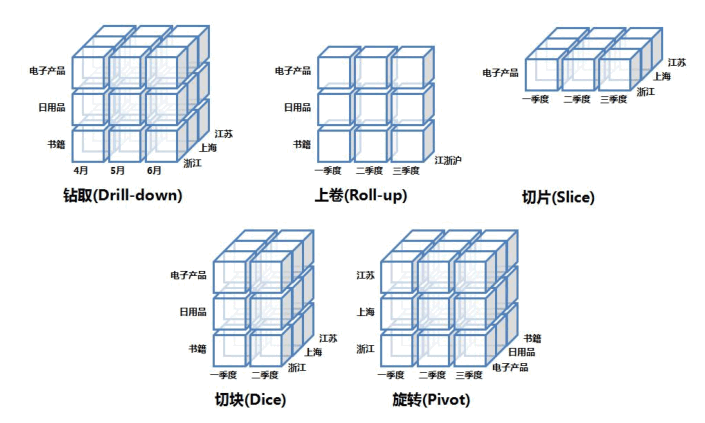
钻取(Drill-down ):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对第二季度的总销售数据进行钻取来查看第二季度 4、5、6 每个月的消费数据。
上卷(Roll-up ):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据。
切片(Slice ):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者第二季度的数据。
切块(Dice ):选择维中特定区间的数据或者某批特定值进行分析,比如选择第一季度到第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot ):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
3.2.3 OLTP和OLAP的关系
OLTP主要是企业给用户用的产品,OLAP是分析用户的行为,帮助企业决策,调整方向。
四.Kylin实现原理
kylin 的核心思想是预计算,kylin 对多维分析可能用到的度量进行预计算,将高维复杂的聚合计算,多表连接等操作转换成预计算结果,将计算好的结果保存成 Cube,存储于 Hbase 中,供查询时直接访问。预计算过程需要很长时间,但是一旦结果计算出来,再次查询只是获取结果集合的过程,不需要额外再次浪费集群资源进行长时间查询,这种以空间换取时间的处理数据模式决定了 Kylin 拥有很好的快速查询、高并发能力。
Kylin 是一个 MOLAP(多维联机数据分析)系统,最常用的是将 Hive 中的数据进行预计算,利用 Hadoop 的 Mapreduce 或者 Spark 分布式计算框架来实现。Kylin 获取的数据表是星型数据结构的,目前建模时,只支持一张事实表,多张维度表,假设业务需求比较复杂,可以考虑在 Hive 中进行预处理生成一张宽表来处理。
对于 Hive 中的维度表和事实表,根据我们指定的维度列来构建 cube,cube 是所有维度的组合,任一维度的组合称为 cuboid,即:cube 中包含所有的 cubeid。理论上来说,一个 N 维的 cube,会有 2 的 N 次方种维度组合(cuboid)。举例:假设一个 cube 包含 time、country、city、location 四个维度,那么就有 16 中 cuboid 组合。通过计算框架的计算将 OLAP 分析的 cube 数据存储在 Hbase 中,方便后期实现多维数据集的交互式快速查询。

上图中是 Kylin 整体架构原理图,其中:
REST Server:提供 Restful 接口,可以通过此接口来创建、构建、刷新、合并Cube 等相关操作。同时也可以通过 Restful 接口实现 SQL 查询。
Query Engine:目前 Kylin 使用开源的 Calcite 框架来实现 SQL 解析,用户发出SQL 查询之后,可以通过 Query Engine 来将 SQL Query 语句转换成 SQL 语法树,也就是逻辑计划。
Routing:负责将解析 SQL 生成的执行计划转换成 cube 缓存的查询,cube 是通过预计算缓存在 Hbase 中,这部分查询时可以在秒级甚至是毫秒级完成,除此之外,还有一些操作需要使用原始数据(存储在 HDFS 上)通过 Hive 查询,这部分查询的延迟比较高。
Metadata:Kylin 中有大量的元数据信息,包括 cube 的定义、星型模型的定义、job 和执行 job 的输出信息、模型的维度信息等等。Kylin 的元数据存储在 Hbase 中,存储的格式是 Json 字符串。
Cube Build Engine:立方体构建模块是所有模块的基础,主要负责 Kylin 预计算中创建 cube,创建的过程是首先通过 Hive 读取原始数据,然后通过 MR 或者 Spark 计算生成 Htable,最后将数据加载到 Hbase 表中。
入门大数据---Kylin是什么?的更多相关文章
- 入门大数据---Kylin搭建与应用
由于Kylin官网已经是中文的了,而且写的很详细,这里就不再重述. 学习右转即可. 这里说个遇到的问题,当在Kylin使用SQL关键字时,要加上双引号,并且里面的内容要大写,这个和MySql有点区别需 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
随机推荐
- jchdl - RTL
https://mp.weixin.qq.com/s/gNN2eiJnr9N02xdZVQceDQ 相较于GSL层对物理连接的建模,RTL层提高了一个抽象层次: 把物理的触发器提取为抽象 ...
- Chisel3 - Tutorial - Adder
https://mp.weixin.qq.com/s/SEcVjGRL1YloGlEPSoHr3A 位数为参数的加法器.通过FullAdder级联实现. 参考链接: https://githu ...
- Chisel3 - 字面量(literal)
https://mp.weixin.qq.com/s/uiW4k4DeguvYsG8LhHk2Ug 介绍Chisel3中基本数据类型的字面量的写法,及其背后的实现机制,也就是Scala隐式规则. ...
- CentOS 虚拟机 下载及 搭建
个人博客网:https://wushaopei.github.io/ (你想要这里多有) CentOS 虚拟机安装包下载 : 链接:https://pan.baidu.com/s/1JDIASm ...
- Java实现 LeetCode 803 打砖块 (DFS)
803. 打砖块 我们有一组包含1和0的网格:其中1表示砖块. 当且仅当一块砖直接连接到网格的顶部,或者它至少有一块相邻(4 个方向之一)砖块不会掉落时,它才不会落下. 我们会依次消除一些砖块.每当我 ...
- Java实现 蓝桥杯 算法训练 删除数组零元素
算法训练 删除数组零元素 时间限制:1.0s 内存限制:512.0MB 提交此题 从键盘读入n个整数放入数组中,编写函数CompactIntegers,删除数组中所有值为0的元素,其后元素向数组首端移 ...
- Java实现 LeetCode 367 有效的完全平方数
367. 有效的完全平方数 给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False. 说明:不要使用任何内置的库函数,如 sqrt. 示例 1: ...
- 一个Redis查询案例
1.远程登陆进服务器 使用ssh连接至Linux服务器中 2.接入redis集群 redis-cli -h 10.1.8.12 -p 29000 3.执行查询命令 根据userid查询用户的最近在线时 ...
- Grafana6.4.4 + zabbix 4.2
环境简介 OS:Centos 7.4 zabbix:4.2.6 Grafana:6.4.4 一.yum 直接安装的方式 官方推荐有几种安装方式我采用yum 直接安装的方式 官方doc: https:/ ...
- 对Activity启动模式的理解
对Activity启动模式的理解 应用场景 在已打开多个Activity应用B的前提下,应用A调用应用B后点击返回按钮,需要直接返回到A应用,而不是打开B应用的上一个Activity 一个Task可以 ...