hadoop的扩容
一、横向扩容(参见:https://www.cnblogs.com/yangy1/p/12362565.html)
现在在此基础上再添加一个节点
1、克隆一台主机hdp03(克隆hdp02)
修改ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR=192.168.0.43
修改主机名及添加主机映射
vim /etc/hostname hdp03
vim /etc/hosts 192.168.0.43 hdp03
删除tmp下的目录文件
cd /opt/software/hadoop-2.7./tmp rm -rf *
2、配置主(有namenode服务的主机)
添加主机映射
vim /etc/hosts 192.168.0.32 hdp01
192.168.0.42 hdp02
192.168.0.43 hdp03 //添加新的映射
配置slaves
vim /opt/software/hadoop-2.7./etc/hadoop/slaves hdp01
hdp02
hdp03 //添加新的主机名
3、启动hdp03的datanode
hadoop-daemon.sh start datanode //启动datanode
因为克隆的hdp02,所以和hdp02的私钥一样,不需要重新生成,hdp01可以直接访问
4、访问50070端口

可以看到节点添加上去了,变成了3个。
二、纵向扩容
纵向扩容在hdp01上添加一块新的硬盘
1、在虚拟机目录点击右键——>设置——>添加——>硬盘
然后用默认的配置一直点击下一步添加成功
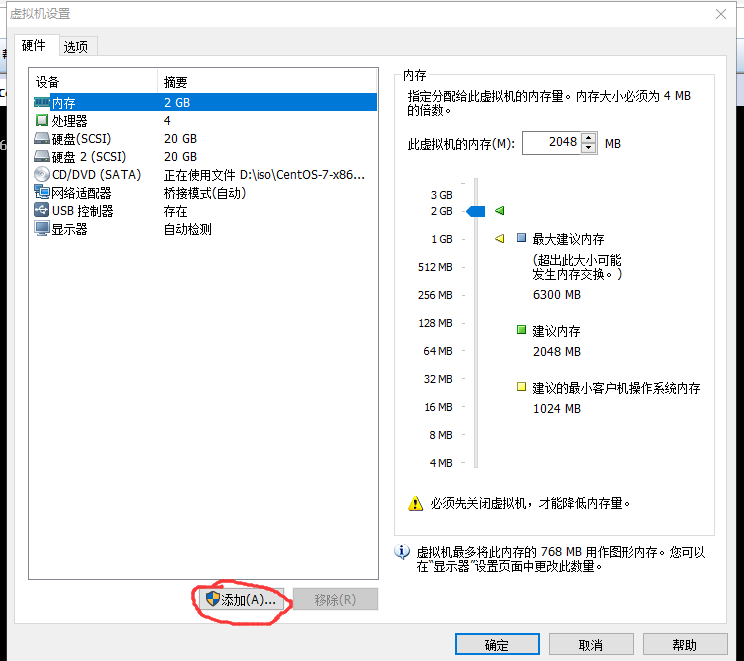
重启虚拟机
reboot
2、将硬盘分区并挂载
在/dev里可以看到新添加的硬盘sdb
cd /dev

分区
fdisk sdb m //查看帮助选项 n //添加分区 p //选择主分区 +10G //添加10G w //保存并退出
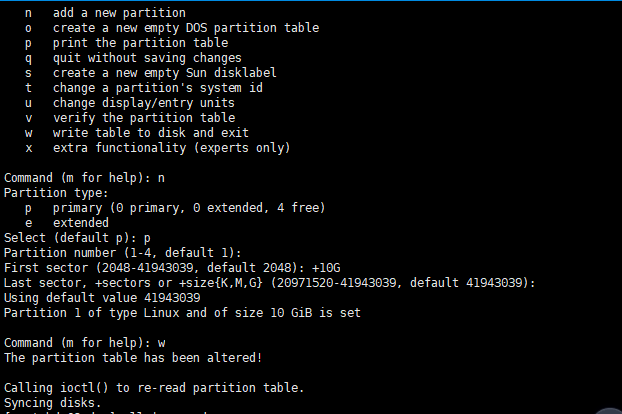
再次查看可以看到分区成功sdb1

挂载
先在根目录新建文件夹
cd /
mkdir sdb1 mount /dev/sdb1 /sdb1
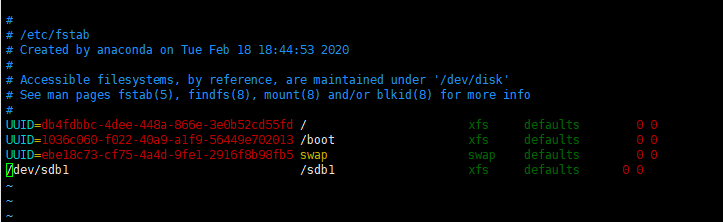
mount的挂载重启后就失效,要想永久挂载需要修改配置
vim /etc/fstab /dev/sdb1 /sdb1 xfs defaults 0 0 //添加配置
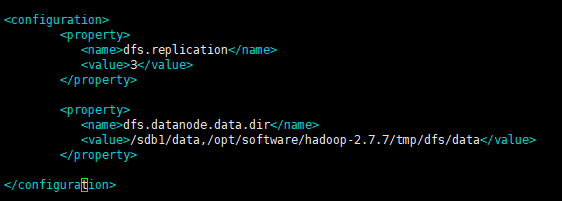
3、修改hdfs-site.xml
cd /opt/software/hadoop-2.7./etc/hadoop vim hdfs-site.xml
启动
start-dfs.sh
访问50070端口

可以看到hdp01的容量由原来的9.99GB扩容到19.98GB
hadoop的扩容的更多相关文章
- Hadoop 动态扩容 增加节点
基础准备 在基础准备部分,主要是设置hadoop运行的系统环境 修改系统hostname(通过hostname和/etc/sysconfig/network进行修改) 修改hosts文件,将集群所有节 ...
- hadoop HDFS扩容
1.纵向扩容(添加硬盘) 1.1 添加硬盘 确定完成添加,运行 lsblk 查看硬盘使用情况 1.2 硬盘分区 fdisk /dev/sdb #对新硬盘sdb进行分区 m 帮助 n 添加一个分区 p ...
- hadoop(1)入门
hadoop入门(一) 一.概述 1.什么是hadoop hadoop不仅是一个用于存储分布式文件系统,还是设计用来在有通用计算设备组成的大型集群上执行的分布式应用的基础框架. hadoop框架最 ...
- 小记---------Hadoop读、写文件步骤,HDFS架构理解
Hadoop 是一个开源框架,可编写和运行分布式应用处理大规模数据 Hadoop框架的核心是HDFS 和 MapReduce HDFS是分布式文件系统(存储) MapReduce是分布式数据处理模型和 ...
- 容器服务如何在企业客户落地?Rancher 解决之道分享
Docker 的优势和趋势我想不必再赘述,那么对于非互联网公司的传统企业客户,以及我们大量的围绕企业客户做集成.交付解决方案的服务提供商,需要考虑的一个问题就是怎么样把容器技术以高质量.低成本.易维护 ...
- Hadoop之HDFS扩容方法
HDFS就是用来存取数据的,那么当数据太多的时候存不下,我们必需扩充硬盘容量,或者换个更大的硬盘. 由于它是分布式文件系统,有两种扩充HDFS集群容量的方法:横向扩容和纵向扩容 横向扩容 横向扩容就是 ...
- 【hbase0.96】基于hadoop搭建hbase的心得
hbase是基于hadoop的hdfs框架做的分布式表格存储系统,所谓表格系统就是在k/v系统的基础上,对value部分支持column family和column,并支持多版本读写. hbase的工 ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
随机推荐
- 红黑树java代码实现
红黑树 思想源于:https://www.cnblogs.com/nananana/p/10434549.html有解释有图,很清晰(删除时需考虑根节点和兄弟节点的子节点是否存在) package t ...
- Vulnhub_DC7 记录
基本步骤 经验 & 总结 对信息还是不敏感,其实也是因为对Drupal这个CMS并不熟悉,不知道哪些地方是默认的那些地方是作者修改,比如这个"DC7USER". 对Drup ...
- js中的跨域
因为javascript的同源策略,导致它普通情况下不能跨域,直到现在,我还是不能完全理解js跨域的几种方法,没办法,只能慢慢学习,慢慢积累,这不,几天又在园里看到一篇博文,有所收获,贴上来看看; 原 ...
- opencv python:ROI 与 泛洪填充
提取ROI区域,处理然后放回去: 泛洪填充 测试代码:显示一张图像,鼠标点击之后,会从该点开始进行填充,显示填充后的结果图像 注:二值图像的填充需要使用选项:cv2.FLOODFILL_MASK_ON ...
- /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.15' not found的解决办法
#############################BEGIN############################# strings /usr/lib64/libstdc++.so.6.0. ...
- Nexus-配置vPC 实验一
配置vPC的步骤:1.配置vPC domain2.配置vPC之间的keepalive link3.配置vPC之间的peer link4.配置vPCs5.确认双方配置一致 拓扑及描述:DC1-N7K-5 ...
- 热部署简介及在eclipse安装插件JRebel进行热部署
一.热部署简介 1.热部署与热加载在应用运行的时候升级软件,无需重新启动的方式有两种,热部署和热加载.它们之间的区别是:(1).部署方式: 热部署在服务器运行时重新部署项目.热加载在运行时重新加载cl ...
- 修复GRUB引导故障!
故障原因:MBR中的GRUB引导程序遭到破坏,grub.conf文件丢失,引导配置有误 故障现象:系统引导停滞,显示“grub>”提示符 解决思路:若无MBR备份,进入急救模式,重新安装grub ...
- Flask - 底层原理和基本流程
一. flask依赖wsgi,实现wsgi的模块:wsgiref(django),werkzeug(flask),uwsgi 1. werkzeug示例 from werkzeug.wrappers ...
- CSS - 精灵Sprite
1. CSS精灵是一种处理网页背景图像的方式. 2. 它将一个页面涉及到的所有零星背景图像都集中到一张大图中去,然后将大图应用于网页,这样,当用户访问该页面时,只需向服务发送一次请求,网页中的背景图像 ...