Hadoop(二)搭建Hadoop
0.部署计划
本文使用的版本是
- red hat 6.8 -本来想用Centos7搭建的,但是工作需要还是换成这个了,不用红帽子用Centos 6系列的应该也可以
- JDK 1.8
- Hadoop 2.7.7
- 计划部署2台虚拟机,分别命名为node-1和node-2,4G内存和40G的硬盘
| 主机名字 | 内存 | 硬盘 | 启用结点 |
|---|---|---|---|
| node-1 | 4 | 40 | hdfs:NameNode, DataNode;yarn:NodeManager, ResoureceManager, |
| node-2 | 4 | 40 | hdfs:SecondaryNameNode,DataNode; yarn: NodeManager |
1.环境部署
node-1&2环境
以下内容两台机器都要配置
部署虚拟机(使用VMware傻瓜式操作,不再赘述)
挂载本地yum源(或者使用网络都行)
同步机组时间
#yum安装ntpdate
yum install ntpdate
#网络同步时间
ntpdate cn.pool.ntp.org配置主机名称
vim /etc/sysconfig/network
#修改为:
NETWORKING=yes
HOSTNAME=node-配置IP、主机名映射
vim /etc/hosts
#直接添加
192.168.98.129 node-
192.168.98.130 node-配置ssh免密登录
ssh-keygen -t rsa #再按四次回车
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
:::e0:d2::1d:0d:e4::2a:::1e:b7: root@node-
The key's randomart image is:
+--[ RSA ]----+
|.o. o+O*. |
|+. = B.E. |
|+ + B * |
| o . + . |
| S |
| |
| |
| |
| |
+-----------------+
#使用ssh-copy-id命令将公钥考培到要免密登录的目标机器上
ssh-copy-id node-1
ssh-copy-id node-2关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off如下图状态则说明防火墙已经关闭、防火墙开机不会自动启动

安装JDK
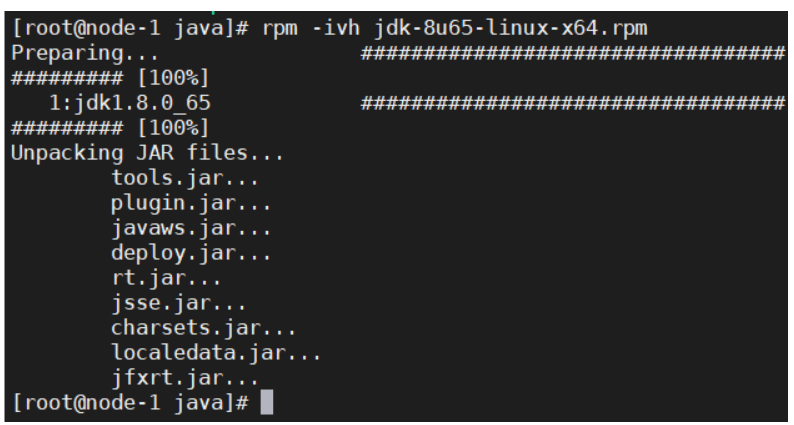
使用rpm格式文件安装
复制到/usr/java文件夹(没有则先创建文件夹)
#授予权限
chmod jdk-8u65-linux-x64.rpm
#安装
rpm -ivh jdk-8u65-linux-x64.rpm安装完成
9. 配置环境变量
#打开全局环境变量设置
vim /etc/profile
#在文档最下方添加配置
JAVA_HOME=/usr/java/jdk1..0_65
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
#生效配置
source /etc/profile
#测试配置
java -version
配置成功:

node-1配置Hadoop
以下操作只要在node1上操作
安装Hadoop
使用tar.gz格式安装
复制到/usr/hop,没路径自行创建
#授予权限
chmod hadoop-2.7..tar.gz
#解压到当前路径
[root@node- hop]# tar zxvf hadoop-2.7..tar.gz
配置Hadoop
配置目录:/usr/hop/hadoop-2.7.7/etc/hadoop
所有配置文件都在这里
我们一共需要配置:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
vim hadoop-env.sh
#在文件中找到JAVA_HOME,修改配置
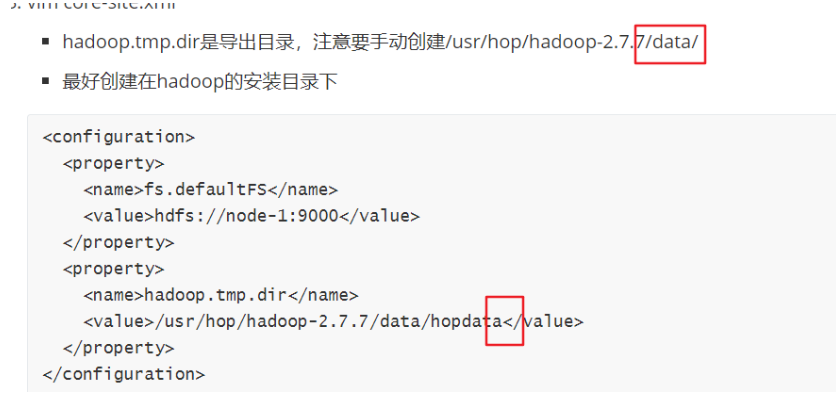
export JAVA_HOME=/usr/java/jdk1..0_65vim core-site.xml
hadoop.tmp.dir是导出目录,注意要手动创建/usr/hop/hadoop-2.7.7/data/
最好创建在hadoop的安装目录下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hop/hadoop-2.7./data/hopdata</value>
</property>
</configuration>注意不一样,别写错
vim hdfs-site.xml
dfs.replication是指默认备份的数量
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-:</value>
</property>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
mapred-site.xml
默认只有mapred-site.xml.template ,因此要改成mapred-site.xml
mv mapred-site.xml.template
vim mapred-site.xml
<!--指定mapreduce运行时框架,这里指定在yarn上,默认是local-->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6. vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<!--指定YARN的主机(ResourceManager)的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>node-</value>
</property>
<property>
<!--nodeManager上运行的附属服务,需要配置成maperduce_shuffle,才可用MapReduce程序-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
7. vim slaves
告诉hadoop有多少台机器
node-
node-
8. 配置Hadoop环境变量,和java的一样,配置以后整体如下
JAVA_HOME=/usr/java/jdk1..0_65
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
HADOOP_HOME=/usr/hop/hadoop-2.7.
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export PATH JAVA_HOME CLASSPATH HADOOP_HOME
生效环境变量
source /etc/profile
测试环境变量配置是否成功
hadoop version

9. 把Hadoop发送到其他机器上
scp -r /usr/hop/hadoop-2.7./ root@node-:/usr/hop
注意,如果导出目录没设置在Hadoop安装包里,其他机器上也要手动创建导出目录(最好把导出目录直接设置在hadoop文件夹里面。。)
10. 把环境变量发送到其他机器上
scp -r /etc/profile root@node-:/etc/
生效其他机器的环境变量
source /etc/profile
Hadoop集群启动
1.hdfs格式化
只有首次启动需要
格式化本质是进行文件系统初始化操作,创建一些自己所需要的文件
格式化之后,集群启动成功,后续不要再格式化
格式化的操作在hdfs集群的主角色(namenode)上操作
#以下两条命令都可以,只要执行1条!
#在node-1中执行
hdfs namenode –format
hadoop namenode –format
2.启动hdfs集群
定位到
/usr/hop/hadoop-2.7.7/sbin目录中有一堆执行文件,其中start-dfs.sh就是hdfs集群的启动文件

start-all.sh和stop-all.sh是Deprecated的,不建议使用
执行
start-dfs.sh发现报错(如果没报错就跳过)

配置完hadoop启动的时候出现如下警告信息:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
如何验证64bit还是32bit?
进入hadoop安装目录,用ldd命令查看依赖库
ldd libhadoop.so.1.0.0 会输出如下信息:
./libhadoop.so.1.0.: /lib64/libc.so.: version `GLIBC_2.' not found (required by ./libhadoop.so.1.0.0)
linux-vdso.so. => (0x00007fff369ff000)
libdl.so. => /lib64/libdl.so. (0x00007f3caa7ea000)
libc.so. => /lib64/libc.so. (0x00007f3caa455000)
/lib64/ld-linux-x86-.so. (0x00007f3caac1b000)
可以看到依赖的都是/lib64/的动态库,所以不是64位/32位问题。但是看到报错,GLIBC_2.14找不到,现在检查系统的glibc库, ldd --version即可检查。 输入命令:
ldd --version
#会输出如下信息:
ldd (GNU libc) 2.12
Copyright (C) Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
Written by Roland McGrath and Ulrich Drepper.
原来系统预装的glibc库是2.12版本,而hadoop期望是2.14版本,所以打印警告信息。
先回到Hadoop/sbin目录关闭hdfs
cd /usr/hop/hadoop-2.7./sbin/
stop-dfs.sh
到http://ftp.gnu.org/gnu/glibc/下载glibc-2.14.tar.xz
tar glibc-2.14.tar.gz
xz -d glibc-2.14.tar.xz
tar -xvf glibc-2.14.tar
cd glibc-2.14
mkdir build
cd build
../configure --prefix=/usr/local/glibc-2.14
make -j4
make install
看看现在libc.so.6在哪个位置,然后修改软链接
[root@binghe ~]# whereis libc.so.
libc.so: /lib64/libc.so. /usr/lib64/libc.so
[root@binghe ~]# rm -rf /lib64/libc.so.
###注意:删除/lib64/libc.so.6软链接之后,不要关闭当前会话,否则将登录不上系统,切记切记切记!
###直接执行以下代码
[root@binghe ~]# LD_PRELOAD=/usr/local/glibc-2.14/lib/libc-2.14.so ln -s /usr/local/glibc-2.14/lib/libc-2.14.so /lib64/libc.so.
———————————————— 版权声明:本文为CSDN博主「冰 河」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/l1028386804/article/details/51538611
再启动:不再报错了!

3.启动yarn集群
同理定位到安装目录的sbin,启动yarn,sh
cd /usr/hop/hadoop-2.7.7/sbin/
start-yarn.sh

4.全局输入jps检查
- 正常是这样的

如果发现node-1没有执行namenode

- 可以查看namenode启动日志,根据日志记录再去看怎么解决
#在安装目录下找到Logs文件夹
cd /usr/hop/hadoop-2.7./logs/
#打开hadoop-root-namenode-node-.log日志
vim hadoop-root-namenode-node-.log
5.如果想单节点启动,可以使用以下命令(一般不使用):
也要在sbin目录下执行
#在主节点上使用以下命令启动HDFS NameNode:
hadoop-daemon.sh start namenode
#在每个从节点上使用以下命令启动HDFS DataNode:
hadoop-daemon.sh start datanode
#在主节点上使用以下命令启动YARN ResourceManager:
yarn-daemon.sh start resourcemanager
#在每个从节点上使用以下命令启动YARN nodemanager:
yarn-daemon.sh start nodemanager
#以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要停止某个节点上某个角色,只需要把命令中的start改为stop即可。
6.登录web.ui
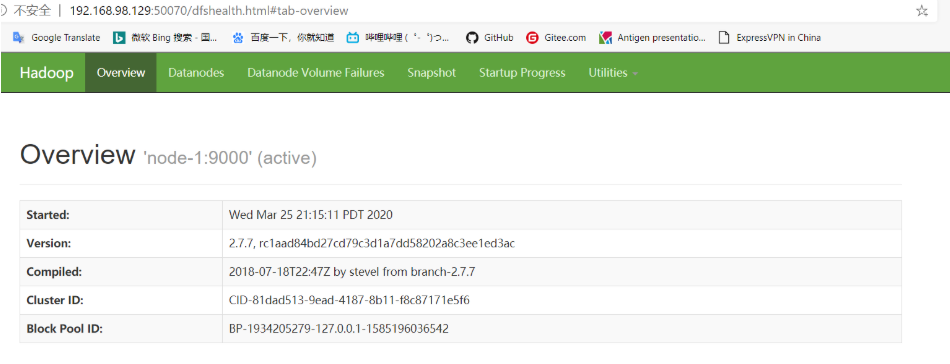
1.在浏览器输入 node-1:50070
该网址是hdfs集群的网络管理端口
如果这一步不行,检查namenode是否正确启动!
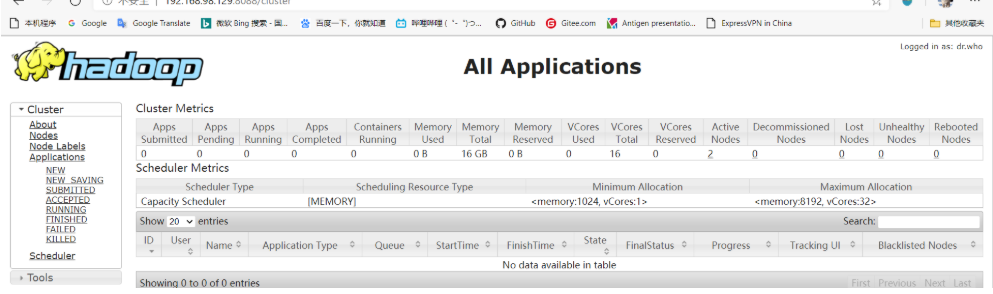
2.在浏览器输入 node-1:8088
打开yarn集群的管理端口
3.在浏览器输入node-2:50090。
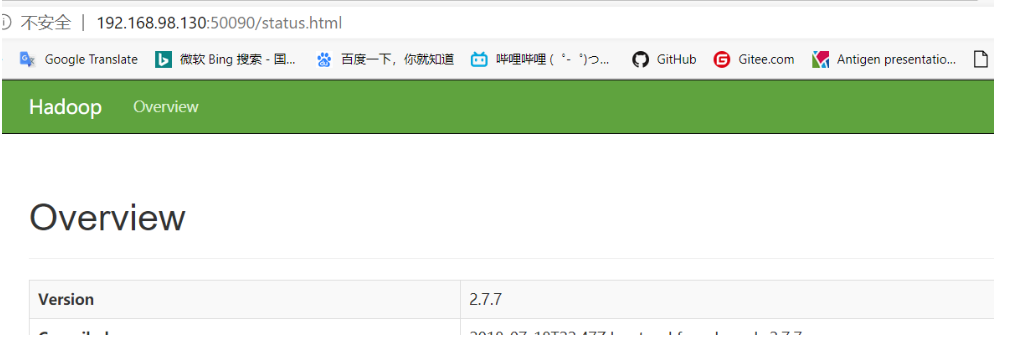
4.如果node-2:50090登录不上
在node-2查看node启动日志
#查看方式和上文node-1的一样,只是要再node-2机器上找,而且找的是node-2中执行的是SecondaryNameNode日志
#在安装目录下找到Logs文件夹
cd /usr/hop/hadoop-2.7./logs/
发现提示:
Call From node-/192.168.98.130 to node-:
failed on connection exception: java.net.ConnectException:
Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
说明主机9000端口登录不进去
回到主机检查
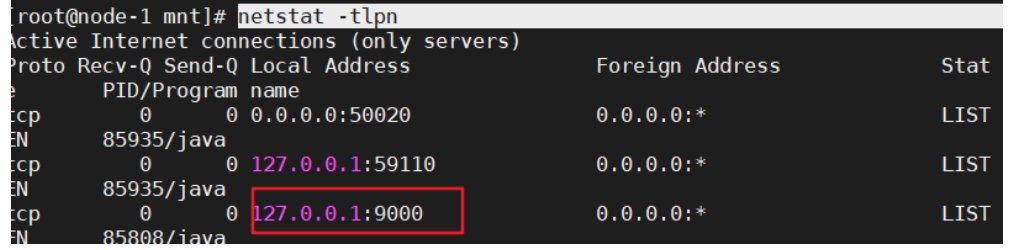
#查看端口
netstat -tlpn
发现9000端口是在127.0.0.1后面,说明此使其他机器访问不了,只能通过本机访问(如果是正确的,应该192.168.X.X)
验证是否连不上
#使用telnet命令验证
telnet node-
#发现确实连不上
Trying ::...
telnet: connect to address ::: Connection refused
Trying 127.0.0.1...
Connected to node-. #如果没有安装telnet,使用yum命令安装
yum install telnet-server
yum install telnet.*
修改/etc/hosts文件,发现原来是笔者修改别的错误时,错误的在前两行后面加上node-1,只要去掉如图就可以了。

关闭Hadoop集群,重启机器,打开Hadoop集群,登录成功了
Hadoop重要配置解析
基本信息
安装时,我们配置了
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
slaves
其中 xxx-site.xml文件,在官网目录最下方,可以找到响应的xxx-default.xml文件,如果用户没有更改,那么这里面的选项会生效
http://hadoop.apache.org/docs/r2.7.7/
site中配置了,就会覆盖了默认的配置选项
Deprecated Properties中写了过时的配置。
1.core-site.xml
集群全局参数,用于定义系统级别的参数,如HDFS URL、Hadoop的临时目录等
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hopdata</value>
</property>
</configuration>
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | fs.defaultFS | file:/// | 文件系统主机和端口 |
| 2 | io.file.buffer.size | 4096 | 流文件的缓冲区大小 |
| 3 | hadoop.tmp.dir | /tmp/hadoop-${user.name} | 临时文件夹 |
2.hdfs-site.xml
HDFS参数,如名称节点和数据节点的存放位置、文件副本的个数、文件读取权限等
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | dfs.namenode.secondary.http-address | 0.0.0.0:50090 | secondary namenode 所在主机的ip和端口,定义HDFS对应的HTTP服务器地址和端口 |
| 2 | dfs.namenode.name.dir | file://${hadoop.tmp.dir}/dfs/name | 定义DFS的名称节点在本地文件系统的位置 |
| 3 | dfs.datanode.data.dir | file://${hadoop.tmp.dir}/dfs/data | 定义DFS数据节点存储数据块时存储在本地文件系统的位置 |
| 4 | dfs.replication | 3 | 缺省的块复制数量 |
| 5 | dfs.webhdfs.enabled | true | 是否通过http协议读取hdfs文件,如果选是,则集群安全性较差 |
3.mapred-site.xml
Mapreduce参数,包括JobHistory Server和应用程序参数两部分,如reduce任务的默认个数、任务所能够使用内存的默认上下限等
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | mapreduce.framework.name | local | 取值local、classic或yarn其中之一,如果不是yarn,则不会使用YARN集群来实现资源的分配 |
| 2 | mapreduce.jobhistory.address | 0.0.0.0:10020 | 定义历史服务器的地址和端口,通过历史服务器查看已经运行完的Mapreduce作业记录 |
| 3 | mapreduce.jobhistory.webapp.address | 0.0.0.0:19888 | 定义历史服务器web应用访问的地址和端口 |
4.yarn-site.xml
集群资源管理系统参数,配置 ResourceManager,NodeManager 的通信端口,web监控端口等
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<!--指定YARN的主机(ResourceManager)的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>node-1</value>
</property>
<property>
<!--nodeManager上运行的附属服务,需要配置成maperduce_shuffle,才可用MapReduce程序-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
| 序号 | 参数名 | 默认值 | 参数解释 |
|---|---|---|---|
| 1 | yarn.resourcemanager.address | 0.0.0.0:8032 | YARN的主机(ResourceManager)的地址, ResourceManager 提供给客户端访问的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等 |
| 2 | yarn.resourcemanager.scheduler.address | 0.0.0.0:8030 | ResourceManager提供给ApplicationMaster的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等 |
| 3 | yarn.resourcemanager.resource-tracker.address | 0.0.0.0:8031 | ResourceManager 提供给NodeManager的地址。NodeManager通过该地址向RM汇报心跳,领取任务等 |
| 4 | yarn.resourcemanager.admin.address | 0.0.0.0:8033 | ResourceManager 提供给管理员的访问地址。管理员通过该地址向RM发送管理命令等。 |
| 5 | yarn.resourcemanager.webapp.address | 0.0.0.0:8088 | ResourceManager对web 服务提供地址。用户可通过该地址在浏览器中查看集群各类信息 |
| 6 | yarn.nodemanager.aux-services | 通过该配置项,用户可以自定义一些服务,例如Map-Reduce的shuffle功能就是采用这种方式实现的,这样就可以在NodeManager上扩展自己的服务。 |
Hadoop(二)搭建Hadoop的更多相关文章
- 从零单排Hadoop——1.搭建Hadoop开发环境
Hadoop环境准备:ubuntu 12.05.Hadoop 2.4 一.安装ssh 由于hadoop可以配置为集群运行,因此系统需要安装ssh工具保证集群中各节点可以互相访问. 获取ssh软件: s ...
- 学习hadoop,搭建hadoop遇到一些特殊问题
我执行下面步骤: 1. 动态增加DataNode节点和TaskTracker节点 以host9为例 在host9上执行: 指定主机名 vi /etc/hostname 指定主机名到IP地址的映射 ...
- 大数据时代之hadoop(二):hadoop脚本解析
“兵马未动,粮草先行”,要想深入的了解hadoop,我觉得启动或停止hadoop的脚本是必须要先了解的.说到底,hadoop就是一个分布式存储和计算框架,但是这个分布式环境是如何启动,管理的呢,我就带 ...
- 搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的 ...
- Hadoop(三)搭建Hadoop全分布式集群
原文地址:http://www.cnblogs.com/zhangyinhua/p/7652686.html 阅读目录(Content) 一.搭建Hadoop全分布式集群前提 1.1.网络 1.2.安 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 搭建Hadoop集群 (二)
前面的步骤请看 搭建Hadoop集群 (一) 安装Hadoop 解压安装 登录master, 下载解压hadoop 2.6.2压缩包到/home/hm/文件夹. (也可以从主机拖拽或者psftp压缩 ...
- Hadoop(二) HADOOP集群搭建
一.HADOOP集群搭建 1.集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 Na ...
- hadoop(二)hadoop集群的搭建
一.集群环境准备工作 1.修改主机名 在root 账户下 vi /etc/sysconfig/network 或者 sudo vi /etc/sysconfig/network 2.设置系统默认启 ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
随机推荐
- video标签加载视频有声音却黑屏
问题 昨天用户上传了一个视频文件,然而发现虽然有声音但是黑屏. 解释 因为原视频的编码是用 mp4v 格式的,它需要专用的解码器.而 chrome 并不支持,所以无法播放. 然后如果用转码功能转成用 ...
- 人见人爱A-B 题解
参加过上个月月赛的同学一定还记得其中的一个最简单的题目,就是{A}+{B},那个题目求的是两个集合的并集,今天我们这个A-B求的是两个集合的差,就是做集合的减法运算.(当然,大家都知道集合的定义,就是 ...
- STM32时钟配置方法
一.在STM32中,有五个时钟源,为HSI.HSE.LSI.LSE.PLL. ①HSI是高速内部时钟,RC振荡器,频率为8MHz. ②HSE是高速外部时钟,可接石英/陶瓷谐振器,或者接外部时钟源,频率 ...
- 聊一聊 React 中的 CSS 样式方案
和 Angular,Vue 不同,React 并没有如何在 React 中书写样式的官方方案,依靠的是社区众多的方案.社区中提供的方案有很多,例如 CSS Modules,styled-compone ...
- Tomcat 启动过滤器异常
严重 [RMI TCP Connection(2)-127.0.0.1] org.apache.catalina.core.StandardContext.filterStart 启动过滤器异常 ja ...
- [极客大挑战 2019]BabySQL 1
考点就是一系列的sql注入操作 和 replace函数过滤 进入页面如图 基础过滤测试 union .select .information_schema试试有没有被过滤 ?username=ad ...
- zabbix笔记_002
监控登录用户 监控图形配置 创建图形: 配置完成后查看图形: 创建触发器配置 创建完成后可以查看 监控磁盘IO I/O查看工具: istat 安装[需要epel源]: yum install -y s ...
- Github搜索技巧整理
Github官方网址:https://github.com/ 一.详细官方文档:https://help.github.com/en/github/searching-for-information- ...
- mysql-8.0.19-winx64下载
mysql-8.0.19-winx64 下载链接 提取码:m7qp
- vue基础指令学习
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...