【Hadoop】hdfs的秘密,namenode,datanode,yarn,安全模式,fsimage,edits...
1.bin/hdfs namenode -format
** 注意事项
1.在配置好了配置文件之后,首次启动之前,做初始化操作
2.在后续启动的时候,不需要再初始化
3.初始化的一些影响
一.初始化操作
@_为什么要初始化,它到底做了哪些事情?
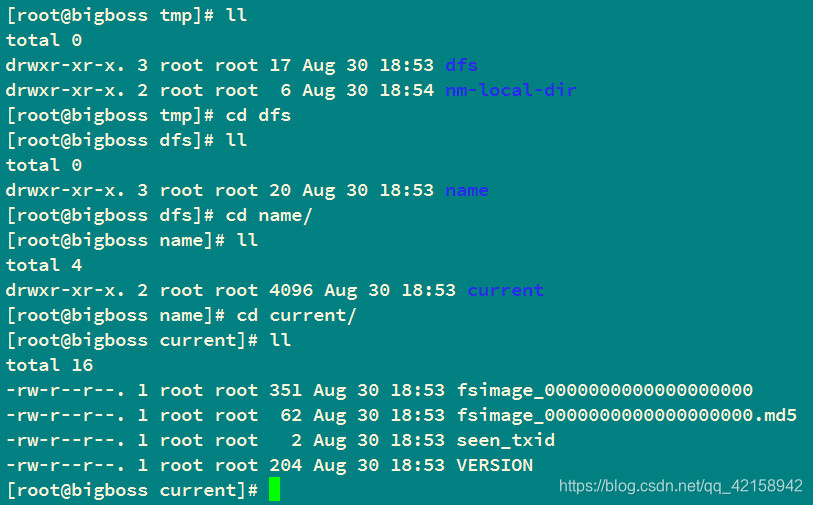
答:初始化的时候,会新建文件夹,dfs/name,文件夹的名字是dfs,在他下面会新建一个文件夹,名字是name
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
初始化之前,建议先把之前的版本信息全部删除
[root@bigboss hadoop-2.6.0]# rm -rf data/tmp/*[root@bigboss hadoop-2.6.0]# hdfs namenode -format
初始化成功:
Storage directory /opt/programs/hadoop-2.6.0/data/tmp/dfs/name has been successfully formatted.
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××
2.初始化的作用
1.生成namenode的文件目录结构
--------in_use.lock是在使用中才会生成
--------和edits相关的也是在开始使用之后,才会生成
2.确定了三个ID,namespaceID、clusterID、blockpoolID

3.生成了文件系统镜像fsimage_0000000000000000000
3.只启动namenode
$ sbin/hadoop-daemon.sh start namenode

1.会生成锁文件,in_use.lock
2.会生成edits相关文件edits_inprogress_0000000000000000001,
并且seen_txid会改变成和edits_inprogress文件后面的编号id一样
[root@bigboss current]# cat seen_txid1
4.启动datanode
$ sbin/hadoop-daemon.sh start datanode
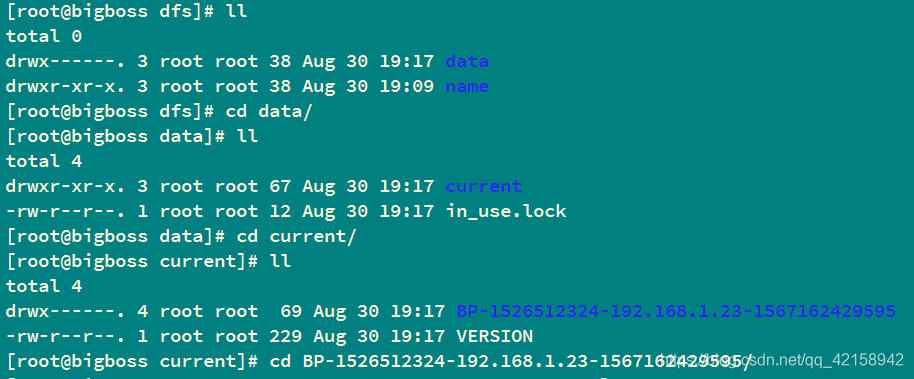
@_图中tmp/,finalized/,rbw/为空
1.会生成datanode的文件目录结构
current文件夹和锁文件in_user.lock是一起生成的
2.会生成块池id对应的文件夹和VERSION文件
为什么会自动配对?
答:slaves文件规定hadoop集群的所有从节点的主机,默认值是localhost,所以伪分布式可以配对成功
**hadoop的从节点类型不止一种
@hdfs的从节点 datanode
@yarn的从节点 nodemanager
为什么要这样设计?
3.三个配对id的位置
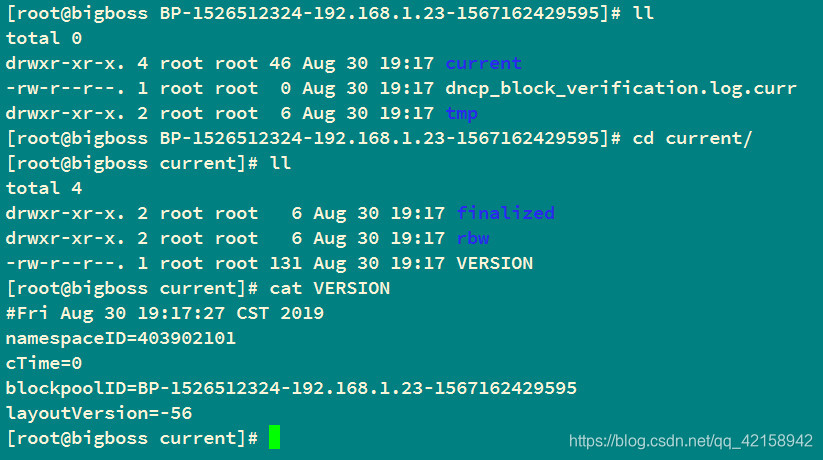
1.namespaceID在 BP…里面的current文件夹下的VERSION文件里面
2.blockpoolID 在BP…里面的current文件夹下的VERSION文件里面
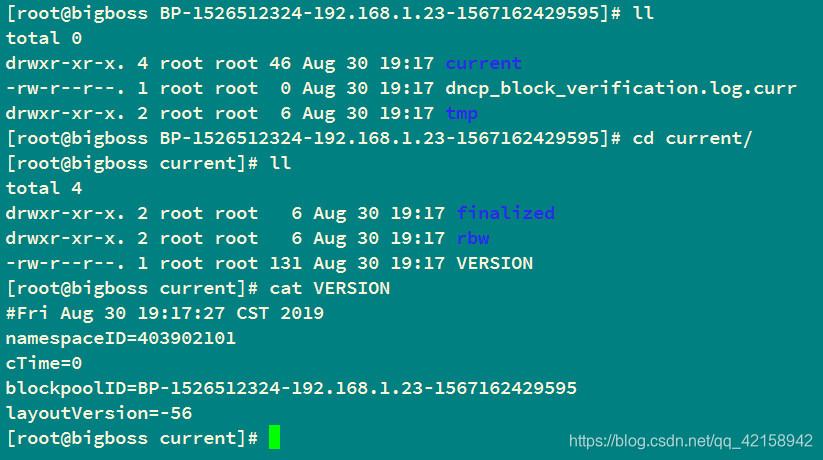
3.clusterID 在BP…同级的VERSION文件里面

5.没有操作任何的hdfs的时候
/opt/programs/hadoop-2.6.0/data/tmp/dfs/data/current/BP-1003710699-192.168.1.211-1567039419296/current/finalized
下是空的,跟hdfs上保存数据相关的所有内容,都保存在这个文件夹下
二.hadoop的配置
1.伪分布式
2.分布式配置
------在伪分布式的基础上
1.所有节点都要安装jdk,ssh免密登录
2.确定各个节点上运行的服务
1个namenode
3个datanode
1个secondarynamenode
1个resourcemanager
3个nodemanager
3.修改配置文件
core-site.xml:
<property><name>fs.defaultFS</name><value>hdfs://bigboss:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/programs/hadoop-2.6.0/data/tmp</value></property></configuration>
hdfs-site.xml:
<property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.secondary.http-address</name><value>bigboss_c:50090</value></property></configuration>
mapred-site.xml:
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>bigboss_b:19888</value></property><property><name>mapreduce.jobhistory.address</name><value>bigboss_b:10020</value></property>
yarn-site.xml:
注意
<value>192.168.1.24</value>写成<value>bigboss_b</value>可能会导致resourcemanager启动失败,原因未知,已确认ip与主机名映射的hosts文件无误,之前使用也没有任何问题,但是在这里出问题了。老师和其他同学用hadoop2主机名没有出现问题,我bigboss_b和同桌caixunkun2都出问题了。。。辣鸡玩意儿!!!
<name>yarn.resourcemanager.hostname</name><value>bigboss_b</value>
正文:
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>192.168.1.24</value></property><!-- 日志聚集功能开启 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 日志文件保存的时间,以秒为单位 --><property><name>yarn.log-aggregation.retain-seconds</name><value>640800</value></property>
4.把hadoop应用程序拷贝到其他节点
hadoop分布式系统,每个节点的配置要完全一样
5.删除data/tmp/*
6.启动服务
为什么不能用start-all.sh?
答:使用这个命令,需要hdfs和yarn的主节点都在当前节点上,才可以统一启动
使用start-dfs.sh和start-yarn.sh来代替它
start-dfs.sh 这个命令要在namenode所在的节点执行,才能正常启动hdfs服务
start-yarn.sh 这个命令要在resourcemanager所在的节点执行,才能正常启动yarn服务
7.测试是否能正常运行
1.webui
2.能使用服务的功能
1.hdfs上面新建文件夹
主要是集群内部的节点,都可以使用hdfs的shell命令
bin/hdfs dfs -mkdir /datanode
2.yarn的测试
配置好了hadoop的默认文件系统是hdfs之后,会把相关的操作都默认为是基于hdfs的操作
1.在hdfs上创建文件夹
2.上传文件
3.运行任务
8.添加配置项
上面配置文件中已经设置了~
日志聚集和任务历史服务
三.hdfs的细节
1.fsimage到底是干嘛的
文件系统镜像,把文件系统的某一时刻的状态持久化到磁盘
某一时刻的状态:namenode某一时刻内存中存在的hdfs相关的信息,元数据
secondarynamenode帮助namenode进行更新fsimage
2.edits是干嘛的
edits 编辑操作记录
根据操作记录,可以推断出namenode内存保存的元数据信息
四.fsimage里面保存的信息是完整的内存结构吗?
答:fsimage是内存信息镜像,包括所有的元数据信息,除了每个块所在的节点信息
所以每次启动之后,namenode再重构了元数据之后,他会接受每个datanode的汇报信息
汇报的信息就是自己上面有哪些块
需要时间把块和节点的映射补充完整,在补充完整之前,namenode不会对外提供服务,这一段时间就是安全模式
在安全模式下,只能做查询的操作,不能增删改
退出安全模式的条件:所有hdfs上的块的信息,跟主机的映射达到了99.999%之后会退出安全模式
五.安全模式
1.不是只有在启动的时候才可以有安全模式
可以手动开启或结束安全模式
2.一般手动进入安全模式的场景
不能提供服务,不会修改元数据,namenode直接保存元数据到磁盘,形成fsimage
3.下一次checkpoint的时候,sn会怎么做
1.会拷贝fsimage和edits
会造成sn上的edits的缺失
2.只会拷贝edits,会造成sn上面没有namenode紧急保存的fsimage
sn会造成fsimage的缺失
六.md5加密的必要性
在传输结束之后,验证文件的完整性和正确性
【Hadoop】hdfs的秘密,namenode,datanode,yarn,安全模式,fsimage,edits...的更多相关文章
- Hadoop 2.7.4 HDFS+YRAN HA删除datanode和nodemanager
当前集群 主机名称 IP地址 角色 统一安装目录 统一安装用户 sht-sgmhadoopnn-01 172.16.101.55 namenode,resourcemanager /usr/local ...
- FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool <registering> (Datanode Uuid unassigned) service to controller/192.168.1.183:9000. Exiting. java.io.IOExcep
2018-01-09 09:47:38,297 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed ...
- Hadoop问题:启动hadoop 2.6遇到的datanode启动不了
问题描述:第一次启动输入jps都有,第二次没有datanode 日志如下: 查看日志如下: -- ::, INFO org.mortbay.log: Started HttpServer2$Selec ...
- 启动hadoop 2.6遇到的datanode启动不了
转自 http://blog.csdn.net/zhangt85/article/details/42078347 查看日志如下: 2014-12-22 12:08:27,264 INFO org.m ...
- namenode datanode理解
HDFS是以NameNode和DataNode管理者和工作者模式运行的. NameNode管理着整个HDFS文件系统的元数据.从架构设计上看,元数据大致分成两个层次:Name ...
- 启动HDFS之后一直处于安全模式org.apache.hadoop.hdfs.server.namenode.SafeModeException: Log not rolled. Name node is in safe mode.
一.现象 三台机器 crxy99,crxy98,crxy97(crxy99是NameNode+DataNode,crxy98和crxy97是DataNode) 按正常命令启动HDFS之后,HDFS一直 ...
- Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图 NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.NameNode将 ...
- hadoop 的HDFS 的 standby namenode无法启动事故处理
standby namenode无法启动 现象:线上使用的2.5.0-cdh5.3.2版本Hadoop,开启了了NameNode HA,HA采用QJM方式.hadoop的集群的namenode的sta ...
- Apache Hadoop集群安装(NameNode HA + YARN HA + SPARK + 机架感知)
1.主机规划 序号 主机名 IP地址 角色 1 nn-1 192.168.9.21 NameNode.mr-jobhistory.zookeeper.JournalNode 2 nn-2 192.16 ...
随机推荐
- 使用Android studio过程中发现的几个解决R变红的办法
刚开始使用Android studio的时候,好几次碰见新建了一个xml文件,或者new了一个activity之后,Android studio莫名其妙的报错了,而显示红色的地方就是常用的(R.id. ...
- LeetCode--Array--Container With Most Water (Medium)
11. Container With Most Water (Medium)# Given n non-negative integers a1, a2, ..., an , where each r ...
- 简单服务发现协议(SSDP)编程指导
本文主要讲解如何使用ssdp进行编程,不涉及过多关于ssdp的理论知识 1. 前言 网上对ssdp理论介绍的一大把,缺乏从编程角度的一个指导,这里不会长篇大论ssdp理论,只是根据实际编码经验对用 ...
- shell bash终端中输出的颜色和格式详解(超详细)
文章目录 1) 格式 1.1 Set 1.2 Reset 2)8/16 Colors 2.1 前景(文字) 2.2 背景 3)88/256颜色 3.1 前景(文字) 3.2 背景色 4)组合属性 5) ...
- Windows系统目录
文件功能 编辑 ├—WINDOWS │ ├—system32(存放Windows的系统文件和硬件驱动程序) │ │ ├—config(用户配置信息和密码信息) │ │ │ └—systemprofil ...
- Asp.net Core 3.1 Razor视图模版动态渲染PDF
Asp.net Core 3.1 Razor视图模版动态渲染PDF 前言 最近的线上项目受理回执接入了电子签章,老项目一直是html打印,但是接入的电子签章是仅仅对PDF电子签章,目前还没有Html电 ...
- P1880 [NOI1995]石子合并 区间dp
P1880 [NOI1995]石子合并 #include <bits/stdc++.h> using namespace std; ; const int inf = 0x3f3f3f3f ...
- Centos7访问Win7/Win10系统中的共享文件
服务器挂在U盘: 1.先将U盘格式化为Fat格式或其他服务器能识别的格式. 2.使用fdisk -l,找到自己的U盘(根据盘大小) 3.新建一个文件夹(mkdir /mnt/usb)用于挂在数据 4. ...
- LightOJ1220
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1220 题目大意: 给你一个 x,请求出一个最大的 p 使得 np = x(n为 ...
- scipy.sparse的一些整理
一.scipy.sparse中七种稀疏矩阵类型 1.bsr_matrix:分块压缩稀疏行格式 介绍 BSR矩阵中的inptr列表的第i个元素与i+1个元素是储存第i行的数据的列索引以及数据的区间索引, ...